Under Guidance of Dr D B Kulkarni Performance

Under Guidance of Dr. D. B. Kulkarni Performance issues in Parallel & Scalable (using GPGPU) Facial Expression Recognition. (To achieve speed & Accuracy. ) Progress. . . (presentation) A Research proposal by - Chavan Umesh B. Asst. Professor – Walchand COE – Sangli.

Components of the FER system Image Preprocessing Feature Extraction Feature Selection CLASSIFICATION Anger Disgust Fear Happy Sad Surprise December 2, 2013 Prepared by : Prof. U B Chavan -WCE 2
 Publication Work status Future Work Result &")
AGENDA Overview of system Related Work (survey) Publication Work status Future Work Result & Analysis December 2, 2013 Prepared by : Prof. U B Chavan -WCE 3

Overview Basic structure of system December 2, 2013 Prepared by : Prof. U B Chavan -WCE 4
/Ph. D/final-synopsis-gpu-scrutiny-9 -dec 13. doc")
SYNOPSIS : /media/CHAVAN U B/UBChavan(IT)/Ph. D/final-synopsis-gpu-scrutiny-9 -dec 13. doc
 • Face Detection -CPU & GPU. (Open. CV &CUDA) • Facial")
6 Related Work(staus) • Face Detection -CPU & GPU. (Open. CV &CUDA) • Facial keypoint (features) Detection -(C Code) • Feature Extraction (in MATLAB) • Deep Learning framework (Python-Theano, Cafee, cu. DNN) • GPU MATLAB framework.

Referance Feature Extraction Classifier Database Sample size Performance Important Points Tian et al. , 2001[10] Permanent features: Optical Flow, Gabor Wavelets & Multistate Models. Transient features: Canny edge detection 2 ANNs, one for upper face and one for lower face Cohn-Kanade and Ekman. Hager Facial Action Exemplars Upper Face: 50 sample sequences from 14 subjects performing 7 AUs Lower Face: 63 sample sequences from 32 subjects performing 11 AUs Recognition of Upper Face AUs: 96. 4% Recognition of Lower Face AUs: 93. 3% when generelized to independant Databasses Recognizes posed expressions. Real-time system. Automatic Face detection. Head motion is handled invarient to scaling. Uses facial feature tracker to reduce processing time Pardas and Bonafonte 2002 MPEG-4 FAPs extracted using an improved Active Contour algorithm and motion estimation HMM Cohn-Kanade Use the whole DB Overall efficiency of 84% (across 6 prototypic expressions) Experiments with: joy, surprise and anger: 98%, joy, surprise and sadness: 95% Automatic extraction of MPEG-4 FAPs Proves that FAPs convey the necessary information that is required to extract the emotions Bartlett et al. , 2003 Gabor Wavelets SVM, Ada. SVM (SVM with Ada. Boost) Cohn-Kanade 313 sequences from 90 subjects. First and last frame used as training image SVM with linear kernal: Automatic face detection: 84. 8%; Manual Alignment: 85. 3%. SVM with RBF kernal: Automatic face detection: 87. 5%; Manual alignment: 87. 6% Fully automatic system. Real-time recognition at high level of accuracy. Successfully deployed on Sony's Aibo pet robot, ATR's Robo. Vie and CU Animator Pantic and Patras, 2005 Tracking a set of 20 facial fiducial points Temporal rules Cohn-Kanade and MMI Cohn-Kanade: 90 Images MMI: 45 images Overall an average recognition of 90% Recognizes 27 AUs. Invarient to oclusions like glasses and facial hair. Shown to give better performance tha AFA system. Zheng et al. , 2006 34 landmark points converted into a Lebeled Graph(LG) using Gaboe Wavelet transform. Then a semantic expression vector built for training face. KCCA used to learn the correlation between LG vectoe and semantic vector. The correlation that is learnt is used to estimate semantic expression vector which is then used for classification. JAFFE and Ekman's Pictures of affect JAFFE: 183 images Ekman's: 96 images Neutral Expression were not chosen from either Database Using semantic info: On JAFFE DB: with Leave one image out(LOIO) cross validation: 85. 79%, with Leave one subject out(LOSO) cross validation: 74. 32, On Ekman's DB: 81. 25% Using class label info: On JAFFE DB: with LOIO: 98. 36%, with LOSO : 77. 05%, On Ekman's DB: 78. 13% Used KCCA to recognize facial expressions. The singularity prolem of the Gram matrix has been tackled using an improved KCCA algorithm Pantic and Patras, 2006 Mid level parameters generated by tracking 15 facial point using particle filteing Rule based classifier MMI 1500 samples of both static and profile views(single and multiple AU activations) 86. 6% on 96 test profiles sequences Automatic segmentation of input video into facial expressions. Recognization of temporal segments of AUs occuring alone or in combination. Automatic recognition of AUs from profile images Kotsia and Geomatric Multiclass SVM : for Cohn-Kanade Whole DB 99. 7% for facial Recognizes either the six basic facial

Referance Feature Extraction Classifier Database Sample size Performance Important Points Dornaika and Davoine, 2008 Candide face model used to track features First head pose is determined using online appearance models and then expressions are recognized using a shochastic approach Created own data Used several video sequences. Also created a challenge 1600 frame test video, where subjects were allowed to diaplsy any epressions in any order for any duration Results have beed spread across diffrent graphs and chars. Inrested readers can refer [24] to view the same Proposes a framework for simulteneous face tracking and expression recognition. 2 AR models per expression gave better mouth tracking and in turn better performance. The video sequences content posed expressions. Cichosz and Ślot, 2003 emotions are extracted at each node, based on an assessment of feature triplets. binary-tree based classifier Berlin Database 240 sentences with six different categories of emotional load: anger, fear, sadness, boredom, joy and no emotion Polish Speaker dependent: 76. 30% , Speaker independent: 64. 18% German Speaker dependent: 74. 39%, Speaker independent: 72. 04% The presented method of emotional speech classification through dichotomy-based decision-trees has been proved to produce very promising results. Schuller et al. , 2004 The 14 dimensional input feature vector consists of the 7 confidences of each the acoustic, and linguistic analysis Kmeans , k. NN , GMM, MLP , SVM – MLP , ML–SVM -- 2829 acted emotional samples used for the training and evaluation in the prosodic and linguistic analysis. Error, % : Acoustic Information: 25. 8 Language Information: 40. 4 Fusion by means: 16. 9 Fusion by MLP : 8. 0 We believe that this contribution shows important results considering the combination of acoustic and linguistic information in speech emotion recognition as a solid model was introduced and a significant gain was achieved reducing error rates up to 8. 0%. Karpathy et al. , 2014 CNN - spatio-temporal features multilayer neural network with Rectified Linear Units followed by a Softmax classifier Sports-1 M , UCF -101. 1 million You. Tube videos belonging to 487 classes. assigning 70% of the videos to the training set, 10% to a validation set and 20% to a test set. Model 3 -fold Accuracy Feature Histograms + Neural Net: 59. 0%, Train from scratch: 41. 3% , Fine-tune top layer: 64. 1%, Finetune top 3 layers: 65. 4% , Finetune all layers: 62. 2% while the performance is not particularly sensitive to the architectural details of the connectivity in time, a Slow Fusion model consistently per -forms better than the early and late fusion alternatives.

9 Publications Sr. No Title Publication Date 1. Facial Expression Recognition IJLTET VOL. 3, Issue 1, Sep 2013 ISSN 2278 -621 X 2. STUDY OF 1 BAR PROBLEM BY FEM ON PARALLEL ARCHITECURE IJSR VOL. 4, Issue 6, June 2015, ISSN: 2319 -7064 3 Review: Parsing cloths by giving weak supervision using pose estimation on Fashion Photographs IJSR VOL. 4, Issue 7, Jully 2015, IISN: 2319 -7064 4 Tehniques in Facial Expression Recognition IJCTA VOL. 7, Issue 3, May 2016 ISSN: 2229 -6093 5 A survey of power saving techniques in HPC IOSR ISJERT

1 0 Viola and Jones Haar Feature Selection Integral Image Calculation Ada. Boost Training Cascading Classifiers Face Detect

1 1 Face Detection • Voila and Jones is the most commonly used algorithm for face detection • Detects face in real-time • Requires upright and straight face

1 2 Face Detection • Voila and Jones is the most commonly used algorithm for face detection • Detects face in real-time • Requires upright and straight face

1 3 CPU Face Detection

1 4 GPU Face Detection

1 5 Face Detection
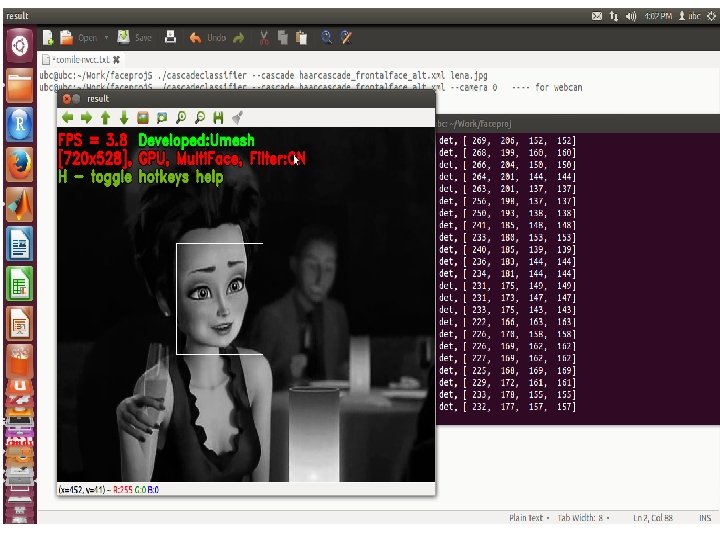

1 7 CPU vs. GPU face detection
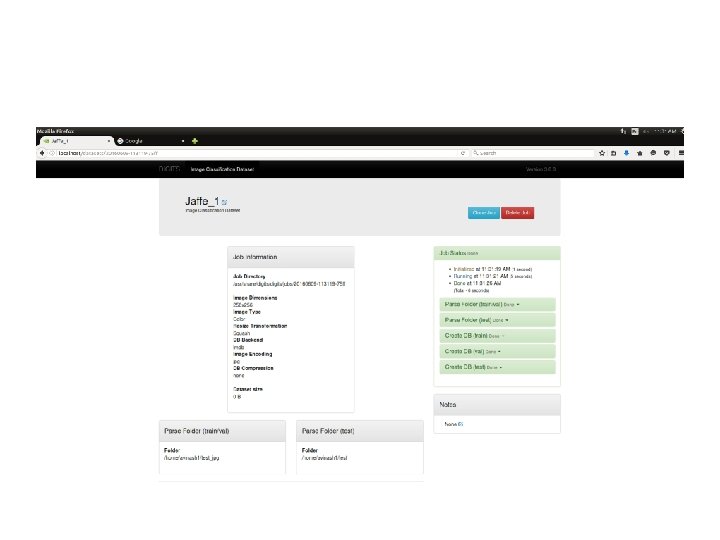
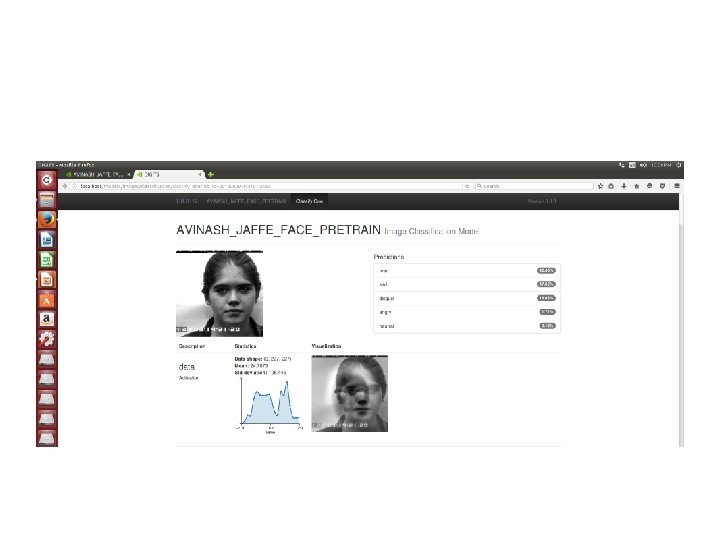
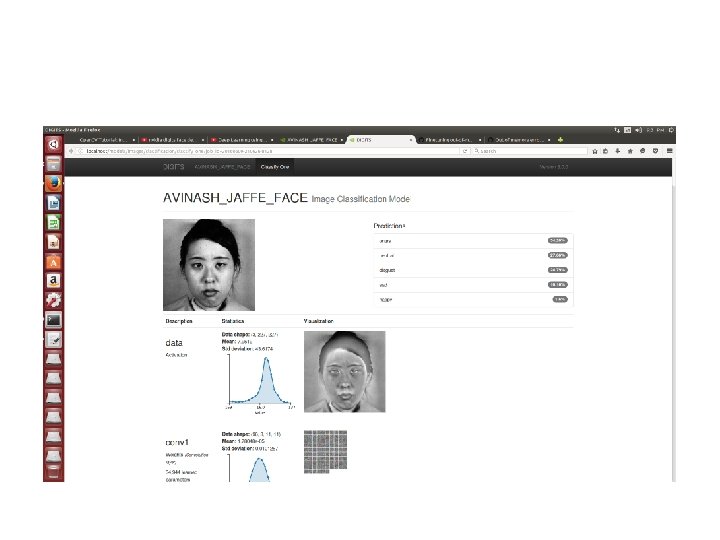
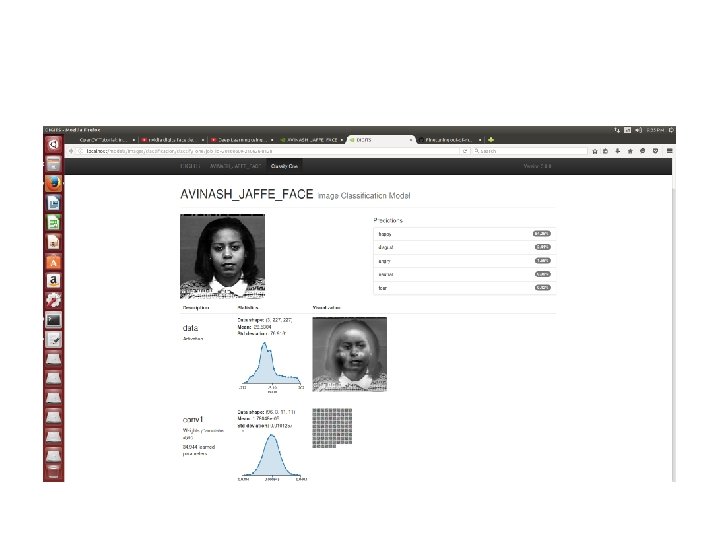
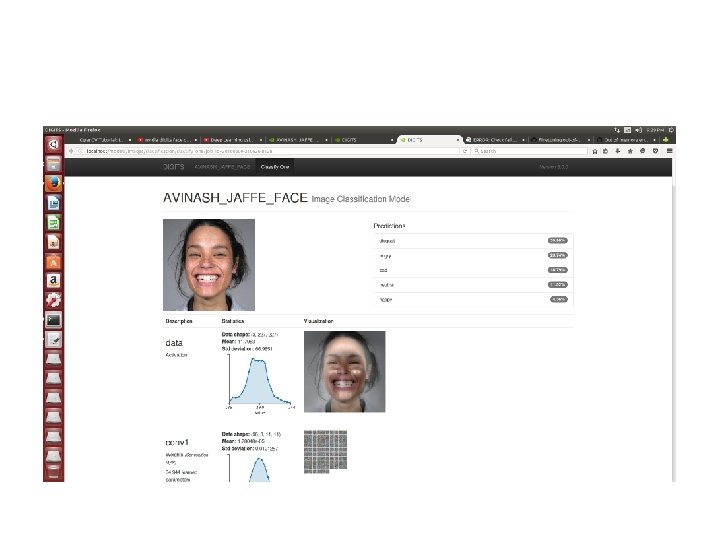
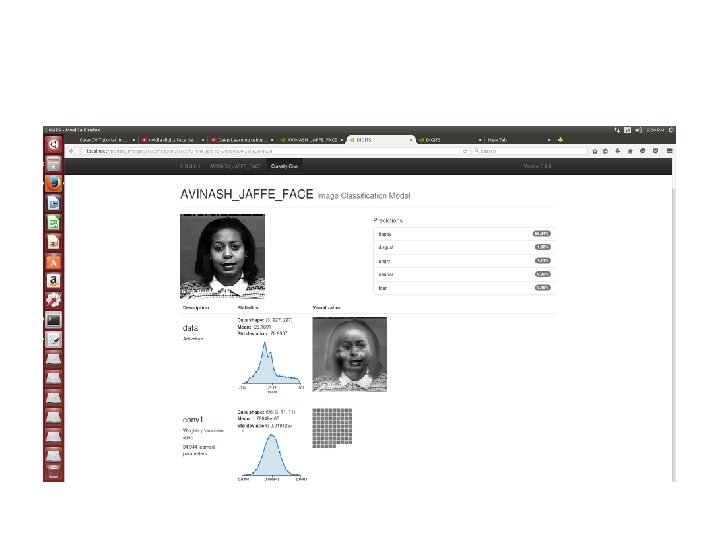
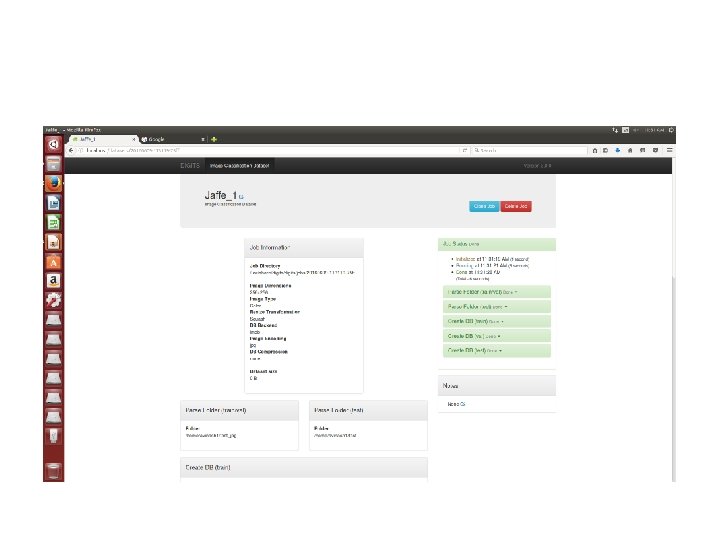

Neural Network Training DIGIT

TRAINING 2

TRAINING PERFORMANCE

EPOCH 30

EPOCH 60

GRAPH

DIGI NN TRAING

NVIDIA DIGITS TRAINING

PRE TRAINING

3 4 Serial Detection

3 5 Parallel Detection

3 6 Feature Extraction using Gabor Filter
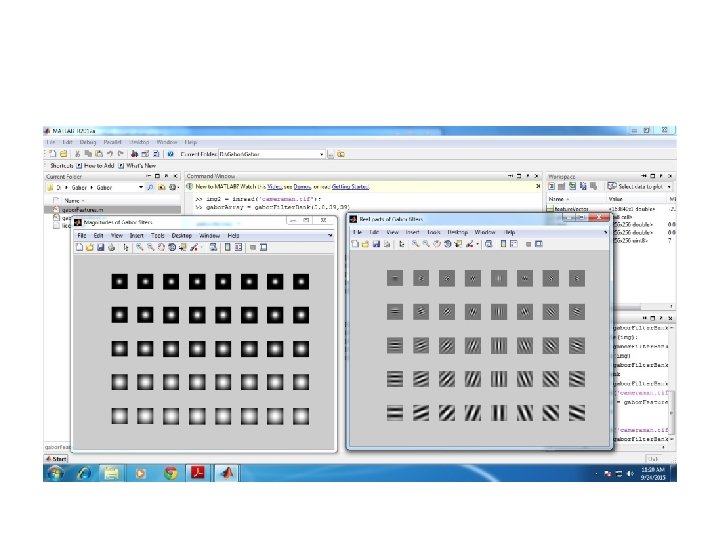

Paremeters of Gabor Wavelets Parameter Symbol Values Orientation θ {0, π/8, 2π/8, 3π/8, 4π/8, 5π/8, 6π/8, 7π/8} Wavelength λ {4, 4√ 2, 8, 8√ 2, 16} Phase ψ {0, π/2} Guassian Radius σ σ=λ Aspect Ratio γ 1


4 1 Future Work • DEEP -Deep Learning NN. • Classification model in CAFFE & Theono • Experimintation with different parameters. • Analysis
")
GPU IMAGE CONVOLUTION (GABOR FILTERING)

FUTURE TASK:

4 4 Conclusion • GPU implementation gives considerable improvement in performance • New platfoem will offer more efficiency and flexibility. • Parallelization can further carried out for feature extraction and classification
- Slides: 44