u internal sort replacement selection natural selection u



 – 대체")

 대체 선택 (replacement selection) u 런 생성 결과(m=5) 런 런 런 1 2")

 { // 레코드 하나를 런에")


![▶ 자연 선택 알고리즘 do { if (!end-of-file(input)) { read. From(Buffer[s], input); if (Buffer[s].](https://slidetodoc.com/presentation_image/0f5a13981230cd9262b4485d48ffb7ef/image-13.jpg "▶ 자연 선택 알고리즘 do { if (!end-of-file(input)) { read. From(Buffer[s], input); if (Buffer[s].")


 균형 합병(balanced")

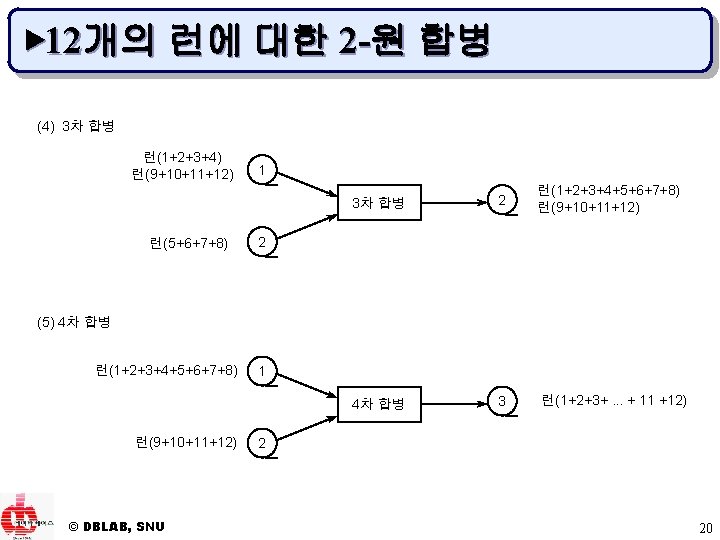

![// 화일을 배열에 재할당 FILE[1], . . . , FILE[m+1] ← FILE[1], .](https://slidetodoc.com/presentation_image/0f5a13981230cd9262b4485d48ffb7ef/image-23.jpg "// 화일을 배열에 재할당 FILE[1], . . . , FILE[m+1] ← FILE[1], .")

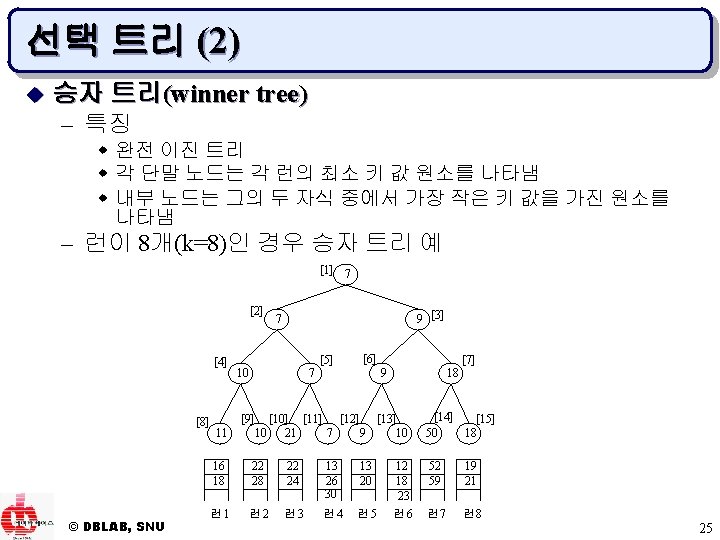

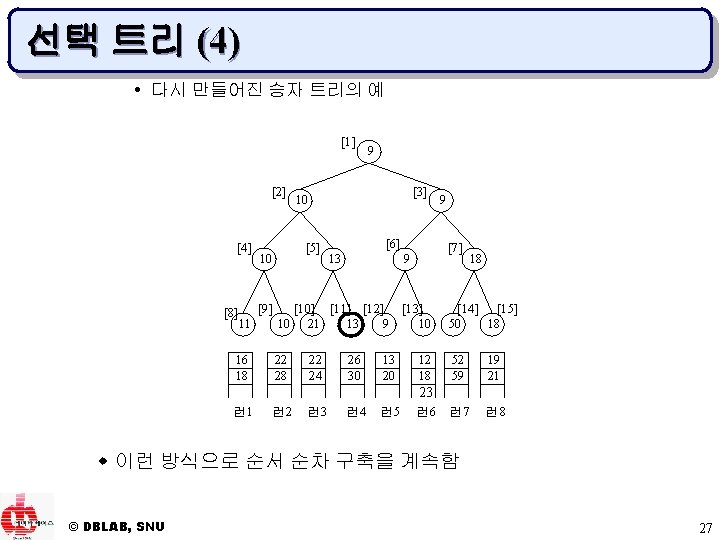

![선택 트리 (6) w 런이 8개(k=8)인 패자 트리의 예 [0] 7 [1] [2] [4]](https://slidetodoc.com/presentation_image/0f5a13981230cd9262b4485d48ffb7ef/image-29.jpg "선택 트리 (6) w 런이 8개(k=8)인 패자 트리의 예 [0] 7 [1] [2] [4]")


 // m-원 균형합병 알고리즘 // m :")





 // m-원 다단계 합병 알고리즘 // m")



")




- Slides: 54
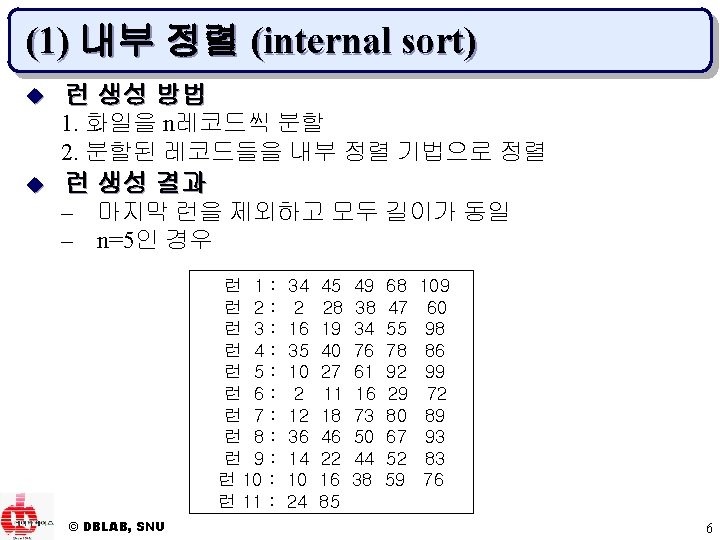
▶ 정렬 단계 u 런 생성 방법 – 내부 정렬 (internal sort) – 대체 선택 (replacement selection) – 자연 선택 (natural selection) u 입력 화일(레코드 키 값)의 예 109 98 29 83 49 78 16 44 © DBLAB, SNU 34 76 80 52 68 40 73 59 45 35 18 10 2 86 12 38 60 10 89 76 38 27 50 16 28 61 46 24 47 16 19 34 55 92 99 72 11 2 36 67 93 22 14 85 5
(2) 대체 선택 (replacement selection) u 런 생성 결과(m=5) 런 런 런 1 2 3 4 5 6 : : : © DBLAB, SNU 34 2 10 2 12 10 45 16 27 11 14 16 49 19 35 16 22 24 60 28 40 18 36 38 68 109 34 38 61 72 29 50 44 46 47 92 73 52 55 76 78 86 98 99 80 89 93 59 67 76 83 85 8
▶ 대체 선택 알고리즘 while (any unfrozen records remain) { // 레코드 하나를 런에 출력 select smallest unfrozen record Buffer[s]; append. To. Run(Buffer[s]); last. Key ← Buffer[s]. key; written[s] ← true; frozen[s] ← true; if (!end-of-file(input)) { read. From(Buffer[s], input); written[s] ← false; if (Buffer[s]. key > last. Key) frozen[s] ← false; } } } // 버퍼에 있는 나머지 레코드들을 출력 append. To. Run(unwritten Buffer[] records in ascending key order); end replacement. Selection() © DBLAB, SNU 10
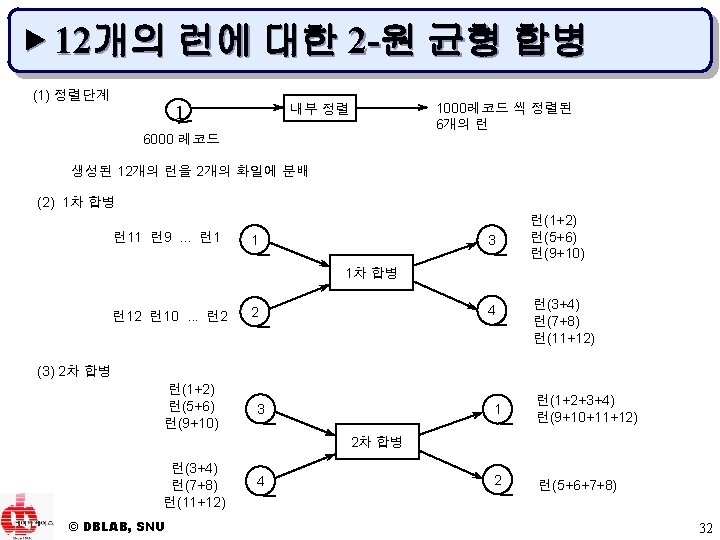
▶ 자연 선택 알고리즘 do { if (!end-of-file(input)) { read. From(Buffer[s], input); if (Buffer[s]. key ≥ last. Key) { written[s] ← false; } else { move Buffer[s] to reservoir; reservoir-count ← reservoir-count + 1; if (reservoir-count = m') space. Full← true; } } } while (written[s] && !space. Full && !end-of-file(input)); } while (!end-of-file(input) && !space. Full); append. To. Run(unwritten Buffer[] records in ascending key order); set. True(corresponding elements of written[]); // 다음 런을 생성하기 위해 버퍼 정리 if (reservoir-count >0) { res-records ← min(reservoir-count, m); for (i ← 0; i < res-records; i++) { move. To(a record from reservoir, Buffer[i]); written[i] ← false; reservoir-count ← reservoir-count - 1; } } if (Buffer[] not full && !end-of-file(input)) { fill. Buffer(with records from input); set. False(corresponding elements of written[]); } } while (unwritten records exist in Buffer[]); end natural. Selection() © DBLAB, SNU 13
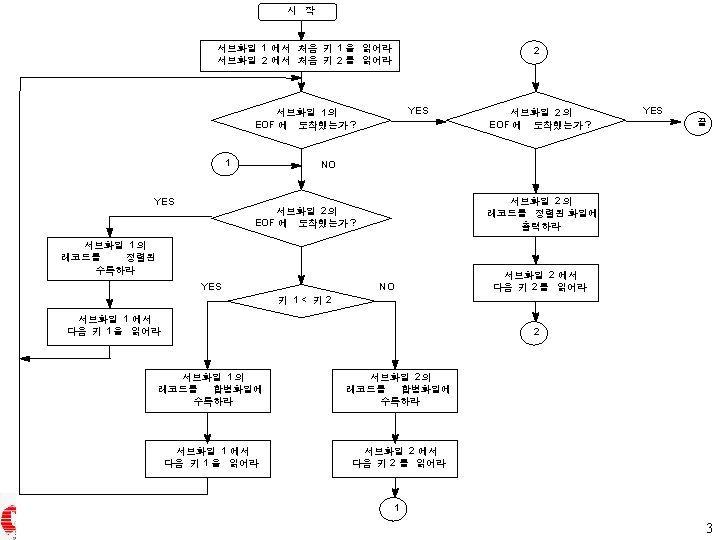
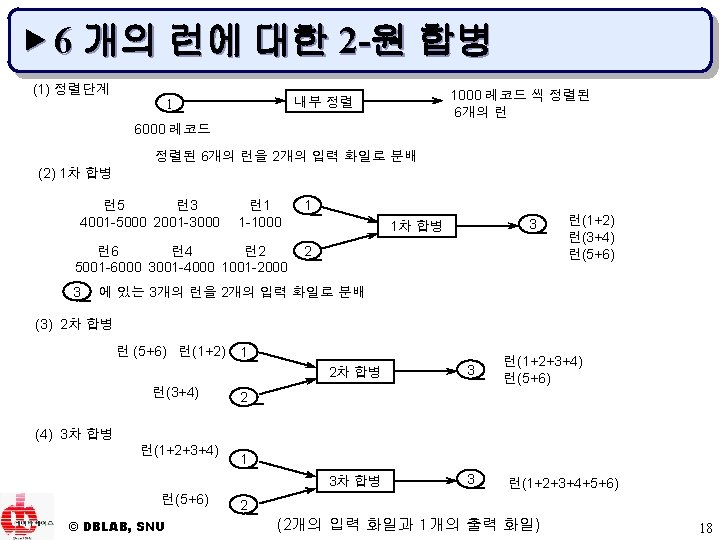
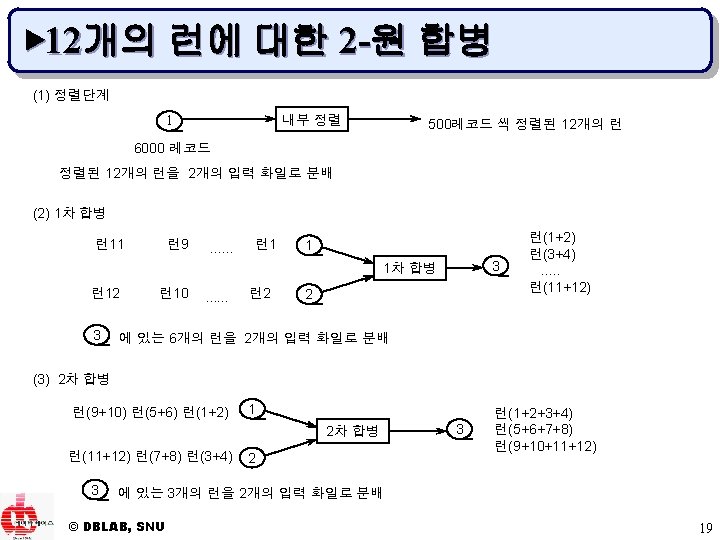
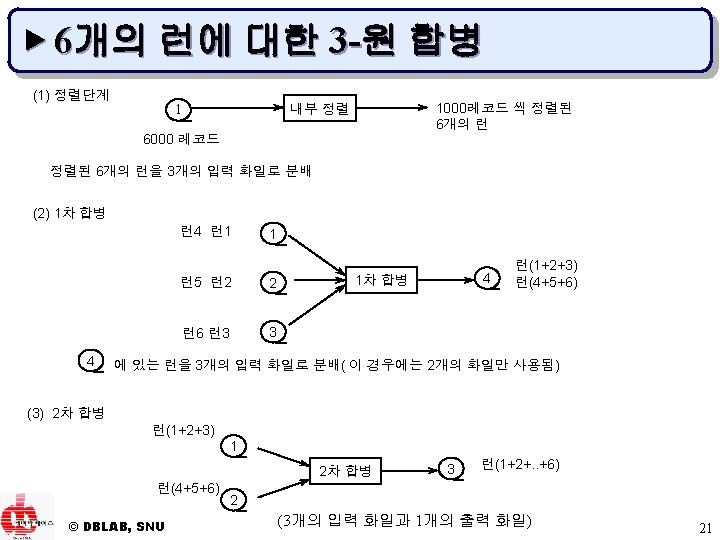
▶ 합병 단계 u 합병 수행 방법 – – m-원 합병(m-way merge) 균형 합병(balanced merge) 다단계 합병(polyphase merge) 계단식 합병(cascade merge) © DBLAB, SNU 16
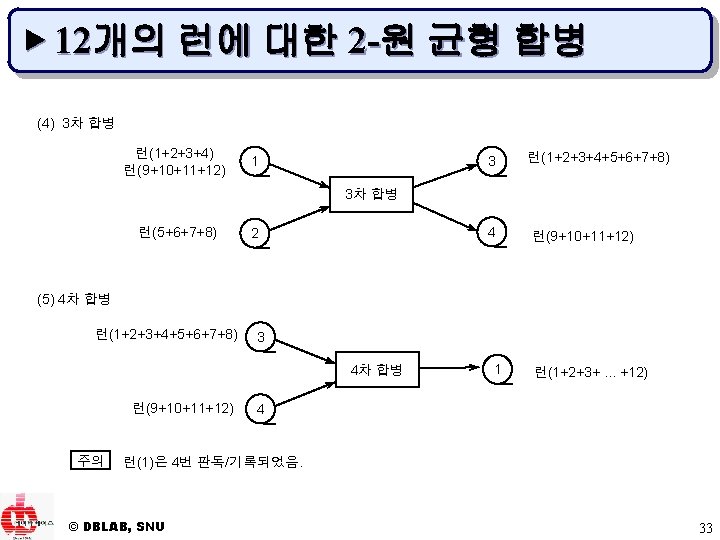
// 화일을 배열에 재할당 FILE[1], . . . , FILE[m+1] ← FILE[1], . . . , FILE[outfilenum-1], FILE[outfilenum+1], . . . , FILE[outfilenum]; close. File(FILE[1], . . . , FILE[m]); // 런들의 분산 단계 open. File(FILE[m]); // for reading open. File(FILE[1], . . . , FILE[m-1]); // for writing // FILE[1], . . . , FILE[m] 내의 런 수의 차이가 1 이하가 되도록 //�runcount/m�, �runcount/m�- 1, �runcount/m�- 2개씩의 런들을 배분 i ← 0; k ← m *�runcount/m�- runcount; do { i ← i + 1; if (k = 0) { if (end-of-file(FILE[i])) move(�runcount/m� runs, from FILE[m] to FILE[i]); else move ((�runcount/m�- 1) runs, from FILE[m] to FILE[i]); } else { k ← k - 1; if (end-of-file(FILE[i])) move((�runcount/m�- 1) runs, from FILE[m] to FILE[i]); else move ((�runcount/m�- 2) runs, from FILE[m] to FILE[i]); } } while (i ≠ m-1); } while (runcount ≠ 1); // 정렬된 최종 목표 화일은 FILE[m] end m. Way. Merge() © DBLAB, SNU 23
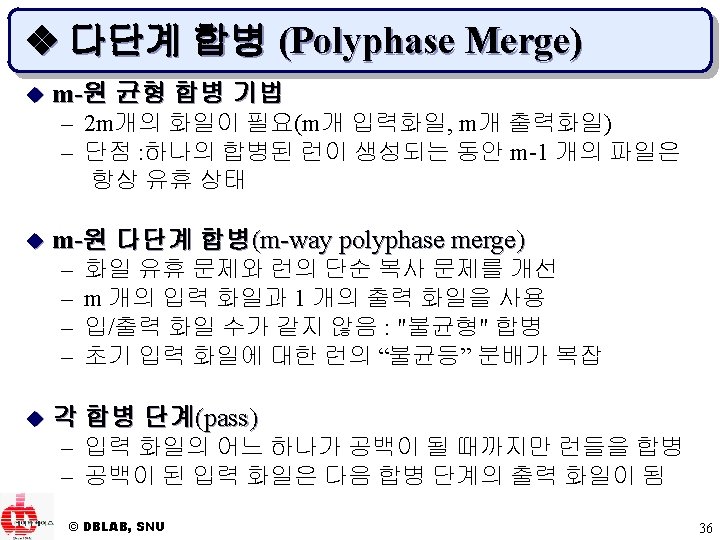
선택 트리 (6) w 런이 8개(k=8)인 패자 트리의 예 [0] 7 [1] [2] [4] [8] © DBLAB, SNU [3] [6] 21 18 [7] 10 50 [10] [11] [12] [13] 10 21 7 9 10 50 16 18 22 24 13 26 30 13 20 12 18 23 23 52 59 19 21 런 2 런 3 런 4 런 5 런 6 런 7 런 8 11 [9] 9 10 [5] 11 출력 [14] 18 [15] 29
▶ m-원 균형 합병 알고리즘 balanced. Merge() // m-원 균형합병 알고리즘 // m : 입력 화일 수(모두 2 m개의 화일 사용) // FILE[] : 화일 배열 // input-set-first : 현 단계에서 입력과 출력 세트를 구분하기 위한 플래그 // base : 출력 화일 세트의 첫 번째 화일 번호 // outfilenum : 현 단계의 출력 화일 번호 // runcount : 현 단계에서 생성된 런의 수 input-set-first ← false; do { if (input-set-first) { input-set-first ← false; open. File(FILE[1], . . . , FILE[m]); // for reading; open. File(FILE[m+1], . . . , FILE[2 m]); // for writing; base ← m + 1; } else { input-set-first ← true; open. File(FILE[1], . . . , FILE[m]); // for writing; open. File(FILE[m+1], . . . , FILE[2 m]); // for reading; base ← 1; } © DBLAB, SNU 34
▶ m-원 균형 합병 알고리즘 // 합병 단계의 수행 outfilenum ← 0; runcount ← 0; do { merge. Run(input files ⇒ FILE[base+outfilenum]); runcount ← runcount + 1; outfilenum ← (outfilenum + 1) % m; } while (!end-of-file on all input files); rewind(input files and output files); } while (runcount ≠ 1); // input-set-first가 true면 최종 정렬 화일은 m+1, // false면 최종 정렬 화일은 1 end balanced. Merge() © DBLAB, SNU 35
▶ 2 -원 다단계 합병의 예 50 110 95 15 100 30 150 40 120 60 70 130 20 140 80 화일 1 : 50 95 110 40 120 150 화일 2 : 15 30 100 60 70 130 화일 3 : 공백 20 80 140 화일 1 : 20 80 140 화일 2 : 공백 화일 3 : 15 30 50 95 100 110 (a) 정렬 단계 결과 40 60 70 120 130 150 (b) 1차 합병 결과 화일 1 : 공백 화일 1 : 15 20 30 40 50 60 70 80 95 100 110 120 130 140 150 화일 2 : 15 20 30 50 80 95 100 110 140 화일 2 : 공백 화일 3 : 40 60 70 120 130 150 화일 3 : 공백 (c) 2차 합병 결과 © DBLAB, SNU (d) 3차 합병 결과 37
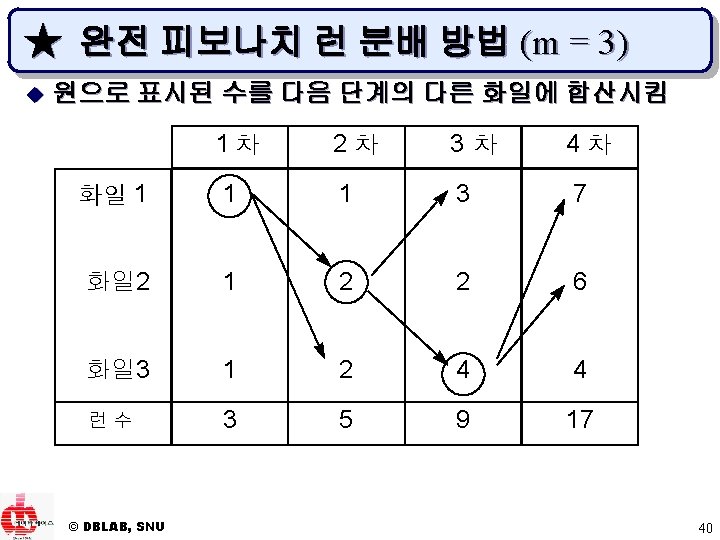
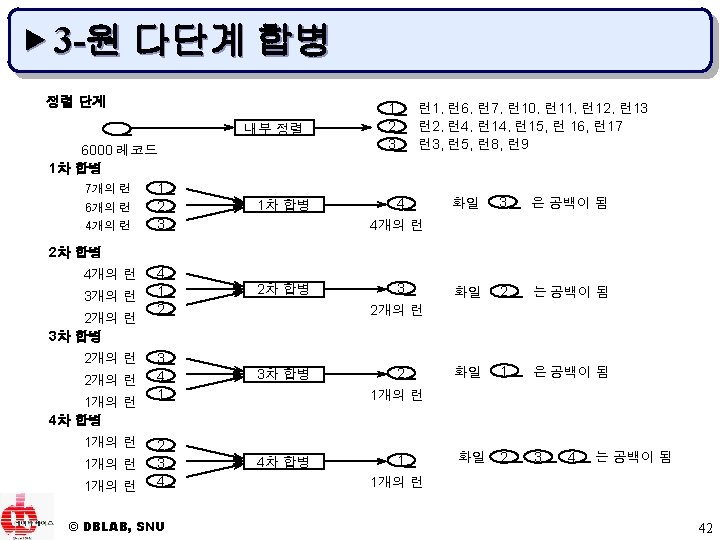
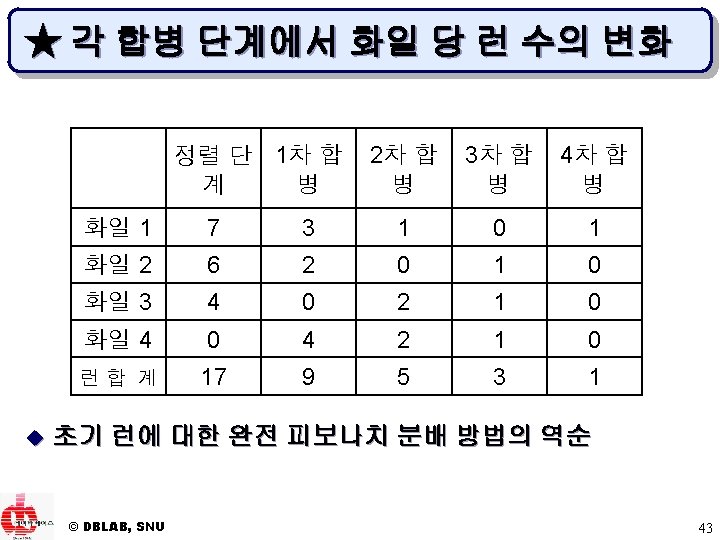
▶ 3 -원 다단계 합병의 예 50 110 95 15 100 30 150 40 120 60 70 130 20 140 80 화일 1 : 50 95 110 화일 2 : 15 30 100 화일 3 : 40 120 150 화일 1 : 60 70 130 20 80 140 화일 4 : 공백 공백 화일 2 : 60 70 130 화일 3 : 20 80 140 화일 4 : 15 30 40 50 95 100 110 120 150 (a) 정렬 단계 결과 (b) 1차 합병 결과 화일 1 : 15 20 30 40 50 60 70 80 95 100 110 120 130 140 150 화일 2 : 공백 화일 3 : 공백 화일 4 : 공백 (c) 2차 합병 결과 © DBLAB, SNU 44
▶ m-원 다단계 합병 알고리즘 polyphase. Merge() // m-원 다단계 합병 알고리즘 // m : 입력 화일의 수 // FILE[] : 화일 배열 // 입력 화일에는 피보나치 분배 방법으로 런들이 분배되었다고 가정 // 화일 준비 for (i ← 1; i ≤ m; i++) open. File(FILE[i]); // for reading; open. File(FILE[m+1]); // for writing; // 합병 단계 do { merge. Run(FILE[1], . . . , FILE[m] ⇒ FILE[m+1]); } while (!end-of-file(FILE[m])); rewind(FILE[m] and FILE[m+1]); close. File(FILE[m] and FILE[m+1]); open. File(FILE[m+1]); // for reading open. File(FILE[m]); // for writing // 화일을 배열에 재할당 FILE[1], FILE[2], . . . , FILE[m+1] ← FILE[m+1], FILE[1], . . . , FILE[m]; } while (!end-of-file on all files on FILE[2], . . . , FILE[m]); // 정렬된 최종 목표 화일은 FILE[1] end polyphase. Merge() © DBLAB, SNU 45
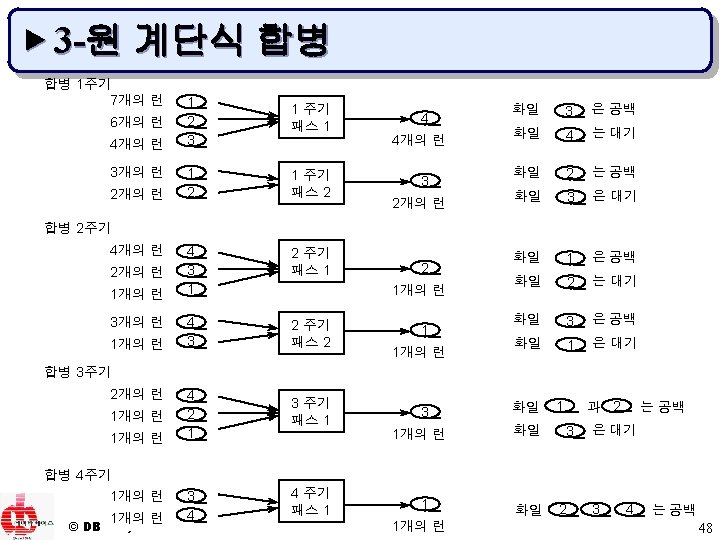
▶ 3 -원 계단식 합병 50 110 95 15 100 30 150 40 120 60 70 130 20 140 80 화일 1 : 50 110 95 화일 2 : 15 30 100 60 70 130 화일 2 : 60 70 130 화일 3 : 40 120 150 20 80 140 화일 3 : 20 80 140 화일 4 : 15 30 40 50 95 100 110 120 150 화일 1 : 공백 화일 4 : 공백 (a) 정렬 단계 결과 화일 1 : 20 60 70 80 130 140 (b) 합병 1주기 1차 합병 결과 화일 1 : 공백 화일 2 : 15 20 30 40 50 60 70 80 95 100 110 120 130 140 150 화일 3 : 공백 화일 3 : 공백 화일 4 : 15 30 40 50 95 100 110 120 150 화일 4 : 공백 (c) 합병 1주기 2차 합병 결과 © DBLAB, SNU (d) 합병 2주기 1차 합병 결과 47
▶ m-원 계단식 합병 알고리즘 © DBLAB, SNU while (empty-file && i < m-1) { if (end-of-file(FILE[m-i+1 -k])) { i ← i + 1; k ← k + 1; rewind(FILE[m-i+1 -k]); close. File(FILE[m-i+1 -k]); } else empty-file ← false; } // 다음 단계의 출력 화일 준비 open. File(FILE[m-i+1]); // for writing } while (i ≠ m-1); // 화일을 런 수의 내림차순으로 정렬한 후 배열에 재할당 reallocate. Files(FILE[1], . . . , FILE[m+1], run count of FILE[1] ≥ run count of FILE[2] ≥ . . . ≥ run count of FILE[m+1]); // 남은 화일 수의 재조정 no-more-empty ← false; do { if (end-of-file(FILE[k])) m ← m - 1; else no-more-empty ← true; } while (m ≠ 1 && !no-more-empty); } while (m ≠ 1); // 최종 정렬된 목표 화일은 FILE[1] end cascade. Merge() 50
▶ 유틸리티를 이용한 정렬/합병의 예 / / SORTNOW EXEC SORTMRG / / SORTIN DD DSN = name of input file, . . , / / DISP = (OLD, KEEP) / / SORTOUT DD DSN = name of output file, . . . , / / DISP = (NEW, KEEP) / / SYSIN DD * SORT FIELDS=(1, 4, CH, A, 20, 10, CH, D), FILEZ=E 2000 / * SORTMRG(input-filename, output-filename). . . SORT, VAR = POLY FILE, INPUT = name(CU), OUTPUT = name(R) FIELD, DEPT(1, 4, ASCII 6), SALEDATE(20, 10, ASCII 6) KEY, DEPT(A, ASCII 6), SALEDATE(D, ASCII 6) ★ job control command © DBLAB, SNU 53