Type Research Paper Experimental evaluation Authors Ahmed Eldawy
 Authors: Ahmed Eldawy, Louai Alarabi, Mohamed F. Mokbel Presented")










: are stored pre-computed results, which used to facilitate")

: Efficiently cleans a sample of rows from a stale")
















![Data Placement Hy. Per [23] ERIS [17] Task Scheduling Hy. Per [23] NUMA-aware](https://slidetodoc.com/presentation_image_h/166152fcc5d12d979c678b95af9eace3/image-32.jpg "Data Placement Hy. Per [23] ERIS [17] Task Scheduling Hy. Per [23] NUMA-aware")

















. Papadias improved")












- Slides: 62
Type: Research Paper (Experimental evaluation) Authors: Ahmed Eldawy, Louai Alarabi, Mohamed F. Mokbel Presented by: Siddhant Kulkarni Term: Fall 2015
Spatial Hadoop is extended Map. Reduce framework that supports global indexing Experiment with four new partitioning techniques
Two of their own papers A Demonstration of Spatial. Hadoop: An Efficient Map. Reduce framework for Spatial data (2013) Spatial. Hadoop: A Map. Reduce framework for spatial data (2015) These demonstrated Spatial. Hadoop along with indexing techniques (used to implement grid, R tree, R+ tree)
Main contribution of this paper is Experimentation and evaluation of performance of Range Queries Join Queries It also explains the three steps used by Spatial Hadoop (compute, sample, partition) for partitioning and different partitioning techniques in short one liners
There are two main conclusions drawn in this paper Quad. Tree technique outperformed Z-curve, Hilbert Curve and K-d Tree 1% sample is enough to produce high quality partitions
Type: Demo Authors: Majed Sahli, Essam Mansour, Panos Kalnis Presented by: Siddhant Kulkarni Term: Fall 2015
Increasing use of Strings and Applications that use strings Need for the ability to query String data
S. Tata, W. Lang, and J. M. Patel. Periscope/SQ: Interactive exploration of biological sequence databases. In Proc. of VLDB, 2007 Extended version of Postgre. SQL for biological sequences Two of their own papers that describe the data structures and parallel string algorithms
Major Contributions: Data Query Language Query Optimization Large scale parallelism And experimentation with some very high configuration systems
Presented by: Omar Alqahtani Fall 2015
Sanjay Krishnan, Jiannan Wang, Michael J. Franklin, Ken Goldberg, Tim Kraska VLDB Endowment, Vol. 8, No. 12 - 2015
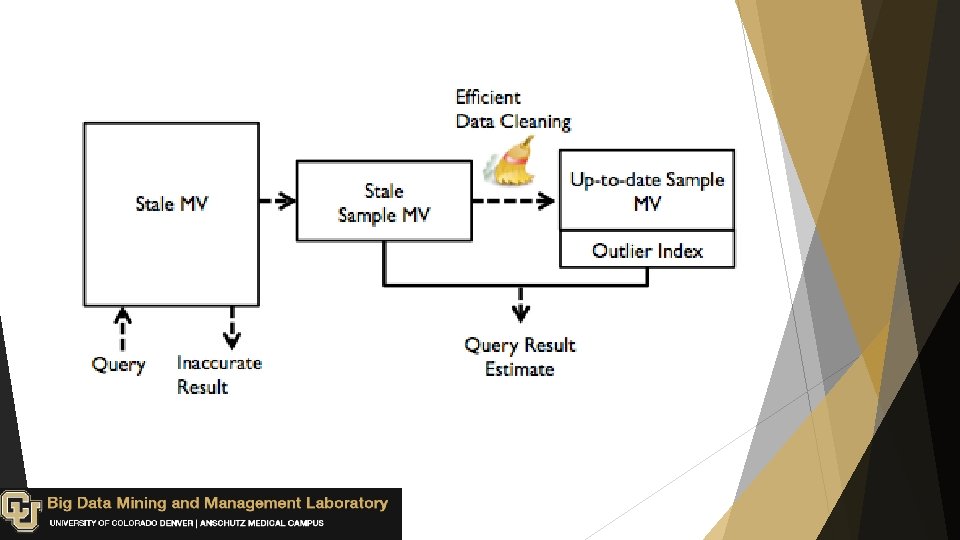
Materialized Views ( MV ): are stored pre-computed results, which used to facilitate fast queries on large datasets.
How to update MVs: Updating all affected MVs, but it reduces the available transaction throughput. Batching updates, but it leads to stale MVs.
Stale View Cleaning (SVC): Efficiently cleans a sample of rows from a stale MV, and use the clean sample to estimate aggregate query results. Provides an outlier indexing technique to reduce sensitivity to skewed datasets Gives tight bounds on approximate results.
Presented by: Ranjan Yadav Fall 2015
Selective parsing, transformation and loading into a new structure as data curation Accurate Reliable Ad-hoc approach(High-quality information) Datasets : Product data, Credit data, Real Estate data etc.
Schema matching and entity resolution De-duplication Information extraction and inference Information integration Ontology construction Efficiently ranking potential data curation tasks.
The problem of incomplete data arises frequently in distributed systems where no failure are common. Prioritizing curation tasks is quite closely related to Stochastic Boolean Function Evaluation (SBFE) Deshpande et al designed a 3 -approximation algorithm for linear threshold formulas, and Allen et al developed exact and approximate solution for monotone K-term DNF formulas
On-demand ETL enables composable non-deterministic data processing operators called Lenses that provide the illusion of fully cleaned relational data that can be queried using standard SQL. q Paygo: which generalizes task-specific on-demand curation solution( Schema matching and entity resolution) q Future work the effectiveness of on-demand ETL and CPIbased heuristics. q
Presented by: Shahab Helmi VLDB 2015 Paper Review Series Fall 2015
Authors: Foteini Alvanaki, Centrum Wiskunde & Informatica Romulo Goncalves, NLe. SC Amsterdam Milena Ivanovaa , Nuo. DB Cambridge MA Martin Kersten, Centrum Wiskunde & Informatica Kostis Kyzirakos, Centrum Wiskunde & Informatica Publication: VLDB 2015 Type: Demonstration
Earth observation sciences, astronomy, and seismology have large data sets which have inherently rich spatial and geospatial information. In combination with large collections of semantically rich objects which have a large number of domain properties, they form a new source of knowledge for urban planning, smart cities and natural resource management. These properties and the relationship between then are usually modeled as relational databases. In this paper column store used to query a 640 billion point dataset. The production of point cloud data sets have increased in size over the past years to Terabyte scale due to its easy collection using airborne laser scanning. Lightweight and cache conscious secondary index called Imprints Results are visualized in real time using QGIS.
Processing point cloud data: Known DMBSs with point cloud extension such as Oracle and Postgre. SQL. They use the data type POINT to store point cloud data. Points are assigned to blocks and the blocks are stored in tables. It helps to reduce the space requirements and speeds up the query. File-based solutions: work directly with the standard LAS format. Such solutions are now encountering scalability problems. Column-stores: Monet. DB is a modern in-memory column-store database system, designed in the late 90's. It’s free and open source. has recently been extended with a novel lightweight secondary indexing scheme called column imprints. Imprint is used during query evaluation to limit data access, and thus minimize memory traffic.
Indexing for point cloud data: Space filling curves: reduces the dimensionality of the data by mapping for example the X and Y coordinates in one dimension. Used by spatial DBMSs, such as Oracle spatial, and files systems. Octrees
The point cloud id is stored in a flat table and it’s XYZ coordinate + other 23 properties are stored in a column. Using a flat table needs more memory. However, we will be able to use compression techniques for column-store such as run length encoding.
In most of the systems, the dominant part of loading stems from the conversion of the LAZ files into CSV format and the subsequent parsing of the CSV records by the database engine. In this system: The loader takes as input a LAS/LAZ files and for each property it generates a new file that is the binary dump of a C-array containing the values of the property for all points. Then, the generated files are appended to each column of the at table using the bulk loading operator COPY BINARY. load and index the full AHN 2 dataset that consists of approximately 640 billion points in less than one day. For Postgre. SQL it takes a week!
Monet. DB has an SQL interface to the Simple Features Access standard of the Open Geospatial Consortium(OGC). 1. Filtering step: the majority of points that do not satisfy the spatial predicate for a given geometry G are identied and disregarded using a fast approximation of the predicate. Monet. DB performs the faltering using the column imprints. Refinements step: During this step, the spatial predicate is evaluated against the precise geometry G. When the geometry is complex, it is not possible to evaluate every single point -> Monet. DB, creates a regular grid over the point geometries selected in the filtering step and assigns each geometry to a grid cell. Then it evaluates grids against the predicates.
Presented by: Ashkan Malekloo Fall 2015
Type: Research paper Authors: Iraklis Psaroudakis, Tobias Scheuer, Norman May, Abdelkader Sellami, Anastasia Ailamaki International conference on Very Large Data Bases.
Non-Uniform Memory Access The Efficient Usage of NUMA Architecture Depends on: Data placement Scheduling strategy of the column store
Data Placement Hy. Per [23] ERIS [17] Task Scheduling Hy. Per [23] NUMA-aware Operators Albutiu et al [6] Yinan et al [25] Black-box Approach Giceva et al [15]
Presenting a partitioning scheme for dictionary encoded columns Investigating the effect of partitioning Presenting a design that can adapt the task scheduling and data placement
Presented by: Ashkan Malekloo Fall 2015
Type: Industry paper Authors: Eric Boutin, Paul Brett, Xiaoyu Chen, Jaliya Ekanayake Tao Guan, Anna Korsun, Zhicheng Yin, Nan Zhang, Jingren Zhou International conference on Very Large Data Bases.
Reliability, Scalability and low latency are the main capabilities of a cloud scale data analytics. Alongside these, an effective fault tolerance and efficient recovery are very important in distributed environments.
A cloud scale interactive query processing system Developed at Microsoft Delivers massive scalability and high performance In order to achieve low latency Various access methods Optimizes delivering first row Maximizes network efficiency Maximizes scheduling efficiency Offers a fine-grained fault tolerance mechanism which is able to efficiently detect and mitigate failure without significantly impacting the query latency and user experience
Presented by: Dardan Xhymshiti Fall 2015
Type: Research paper Authors: Yoonjar Park Seoul National University Seoul, Kores yjpark@kdd. snu. ac. kr Jun-Ki Min Korea Univ. of Tech. & Edu Cheonan, Korea jkmin@kut. ac. kr International conference on Very Large Data Bases. Kyuseok Shim Seoul National University Seoul, Korea shim@kdd. snu. ac. kr
Map. Reduce: is a programming model and implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster. Skyline operator: The Skyline operator is used in a query and performs a filtering of results from a database so that it keeps only those objects that are not worse than any other.
Applications that produce large volumes of uncertain data: Social networks, Data integration Sensor data management Uncertain data sources? Data randomness, Data incompleteness, Limitation of measuring equipments.
Need of advanced analysis queries such as the skyline for big uncertain data.
The skyline probability of an instance is the probability that it appears in a possible world an is not dominated by every instance of the other objects in the possible world. The skyline probability of an objects is the sum of the skyline probabilities of its all instances. Similarly for the continuous model, we define the skyline probability of an object by using its uncertainty region and pdf.
Propose parallel algorithms using Map. Reduce to process the probabilistic skyline queries for uncertain data modeled by both discrete and continuous models. 3 filtering methods to identify probabilistic non-skyline objects in advance. Development of a single Map. Reduce phase algorithm PS-QP-MR. Enhances algorithm PS-QPF-MR by applying the three filtering methods additionally. Presents brute-force algorithms PS-BR-MR and PS-BRF-MR with partitioning randomly and applying the filtering methods.
Several algorithms have been proposed for skyline queries: Nearest Neighbor (Kossman). Papadias improved NN algorithm by using the branch-and-bound strategy. Have been proposed techniques for processing uncertain queries such as probabilistic top-K. The serial algorithms for probabilistic skyline processing over uncertain data have been introduced.
Foteini Katsarou Nikos Ntarmos Peter Triantafillou Presented by: Zohreh Raghebi
One of the main problems addressed by Graph data management systems is subgraph query processing; The naive method for processing such queries is to perform a subgraph isomorphism test against each graph in the dataset Filter-and-verification methods have been proposed to alleviate the problem Solutions utilize an index based on features (i. e. , substructures) of the graphs to filter out the graphs that definitely do not contain q
we identify a set of key factors-parameters, that influence the performance of related index methods: ü the number of nodes per graph ü the graph density ü the number of distinct labels ü the number of graphs in the dataset ü the query graph size
Most related works are tested against the AIDS antiviral dataset and synthetic datasets These sets are not adequate to provide definitive conclusions Grapes alone used several real datasets; , the authors did not evaluate scalability The i. Graph comparison framework [10], which implements several such techniques, compared the performance of older algorithms (up to 2010). Since then, several, more efficient algorithms have been proposed
a linear increase in the number of nodes results in a quadratic increase in the number of edges; As the number of features is superlinear to the size of a graph, the increase of the above two factors leads to a detrimental increase in the indexing time
The increase in the number of distinct labels leads to an easier dataset to index It results in fewer occurrences of any given feature and thus a decrease in the false positive ratio of the various algorithms Our findings give rise to the following adage: “Keep It Simple and Smart” the simpler the feature structure and extraction process: the faster the indexing and query processing algorithm
Respect to the type of graph features indexed (i. e. , paths, trees, cycles, subgraphs) and the method for generating graph features (i. e. , based on frequency mining or exhaustive enumeration of graph features) We choose six well established indexing methods, namely: Grapes, CT-Index, Graph. Grep. SX, g. Index, Tree+∆, and g. Code For query processing time and lowest indexing time, the approaches using exhaustive enumeration (Grapes, GGSX, CT-Index) are the clear winners, with those indexing simple features (paths; i. e. , Grapes, GGSX) having the edge over those with more complex features (trees, cycles; i. e. , CT-Index). Frequent mining approaches (g. Index, Tree+∆) are usually an order of magnitude slower frequent mining approaches (g. Index, Tree+∆) are competitive only for small/sparse datasets, but their indexing times grow very high very fast. In contrast to i. Graph’s conclusion, our study reveals 2 methods, GGSX and Grapes always the clear winner for query processing time and scalability
Industrial paper Avery Ching Sergey Edunov Maja Kabiljo Presented by: Zohreh Raghebi
Analyzing the real world graphs at the scale of hundreds of billions or even a trillion edges is very difficult graph processing engines tend to have additional challenges in scaling to larger graphs
Apache Giraph is a graph processing system designed to scale to hundreds or thousands of machines and process trillions of edges. It is currently used at Facebook to analyze the social graph formed by users and their connections Giraph was inspired by Pregel, the graph processing architecture developed at Google. While Giraph did not scale to our needs at Facebook with over 1. 39 B users and hundreds of billions of social connections we improved the platform in a variety of ways to support our workloads
Giraph’s graph input model was only vertex centric Parallelizing Giraph infrastructure relied completely on Map. Reduce’s task level parallelism did not have multithreading support Giraph’s flexible types and computing model were initially implemented using native Java objects consumed excessive memory and garbage collection time The aggregator framework was inefficiently implemented in Zoo. Keeper we needed to support very large aggregators
we modified Giraph to allow loading vertex data and edges from separate sources Parallelization support: Adding more workers per machine. Use multithreading to take advantage of additional CPU cores. memory optimization : by default we serialize the edges of every vertex into a byte array rather than instantiating them as native Java objects sharded aggregator architecture: each aggregator is now randomly assigned to one of the workers The assigned worker is in charge of gathering the values of its aggregators, performing the aggregation, and distributing the final values to the master and other workers