TUJUAN 1 1 Mahasiswa dapat menjelaskan Ilmu Pengolahan

 1. Mahasiswa dapat menjelaskan Ilmu Pengolahan Text dan Informasi. (C 2) 2.")
 1. Mahasiswa dapat menjelaskan Konsep Linguistic. (C 2) 2. Mahasiswa dapat menjelaskan")


 ataupun tambahan tugas")

 • Boolean • Vector • Probabilistic")
 • Model Terstruktur (Non overlapping lists &")



 POS tagging Lemmatization Stemming Semantic")





 Pencarian dengan kata kunci, judul, penulis, dll. Text-based")






 dan Kent")
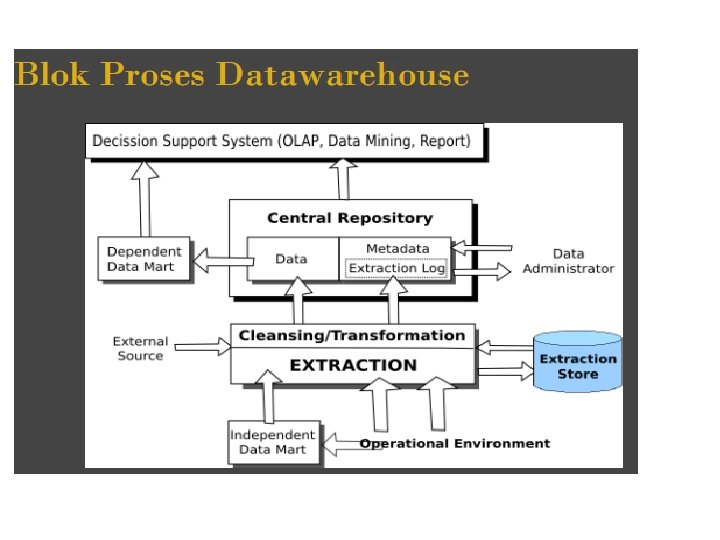
 Sistem Temu Balik Informasi terdiri dari")

 melihat Sistem Temu Balik Informasi sebagai suatu proses yang terdiri")
 dan")

 baik secara langsung")





 • Secara teknis: indexing (pembuatan index) dan retrieval (pencarian keterangan) dokumen")
 berurusan dengan structured data yang mempunyai")

 Pencarian dengan kata kunci, judul, penulis, dll. Text-based")

 subyektif dan dapat didasarkan pada: – topik yang tepat.")

































- Slides: 83
TUJUAN (1) 1. Mahasiswa dapat menjelaskan Ilmu Pengolahan Text dan Informasi. (C 2) 2. Mahasiswa dapat menjelaskan Model-model Sistem Temu Balik Informasi. (C 2) 3. Mahasiswa dapat menjelaskan Evaluasi pada Sistem Temu Balik Informasi. (C 2) 4. Mahasiswa dapat menjelaskan Query Languages. (C 2) 5. Mahasiswa dapat menjelaskan Operasi Text. (C 2)
TUJUAN (2) 1. Mahasiswa dapat menjelaskan Konsep Linguistic. (C 2) 2. Mahasiswa dapat menjelaskan Index dan Search. (C 2) 3. Mahasiswa dapat menjelaskan Web Search. 4. Mahasiswa dapat menggunakan Sistem Temu Balik Informasi. (C 3)
REFERENSI 1. Baeza-Yates & Ribeiro, Modern Information Retrieval. 2. Christopher D. Manning, Prabhakar Raghavan & Hinrich Schütze, An Introduction to Information Retrieval, Cambridge University Press. 3. Peter Ingwersen, Information Retrieval Interaction.
Kuliah UTS 1. Buat kelompok terdiri dari : 2 -3 mhsw 2. Kode program diunggah di github. 3. Program diimplementasikan di situs online 1. Membuat mesin pencari dokumen perundang-undangan. 4. Presentasi di unggah di youtube. com (2 x, tiap 3 minggu ada presentasi yang diunggah di youtube. com) 5. Kontak : email : eri 299@gmail. com 6. Kontak fb : Eri Zuliarso 7. Materi ada : kungfumas. wordpress. com
ATURAN PERKULIAHAN 1. Tidak ada ujian perbaikan (kecuali ada surat dokter) ataupun tambahan tugas untuk memberikan nilai tambahan 2. Tidak ada UTS dan UAS susulan (Kecuali ada surat dokter) 3. Keterlambatan mahasiswa maksimal 15 menit. Bila dosen belum datang selama 15 menit, maka kuliah ditiadakan diganti hari lain sesuai kesepakatan di kelas.
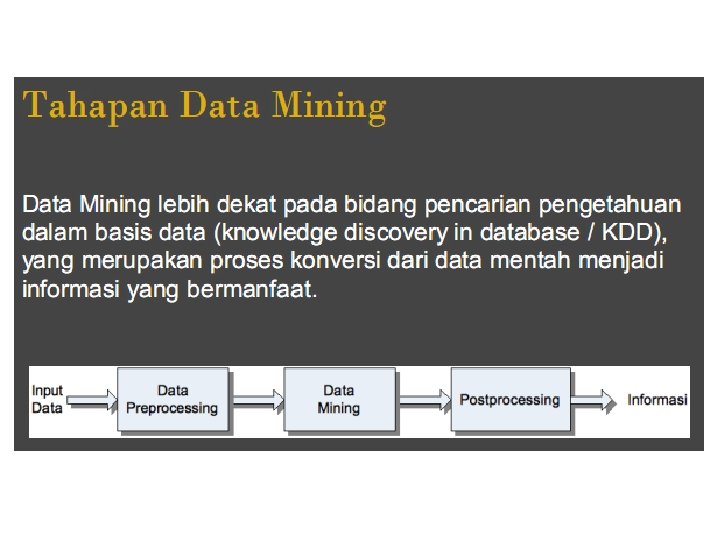
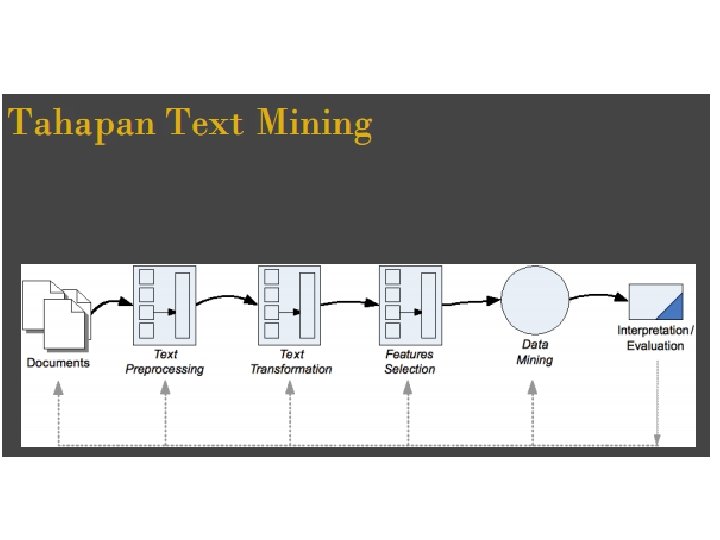
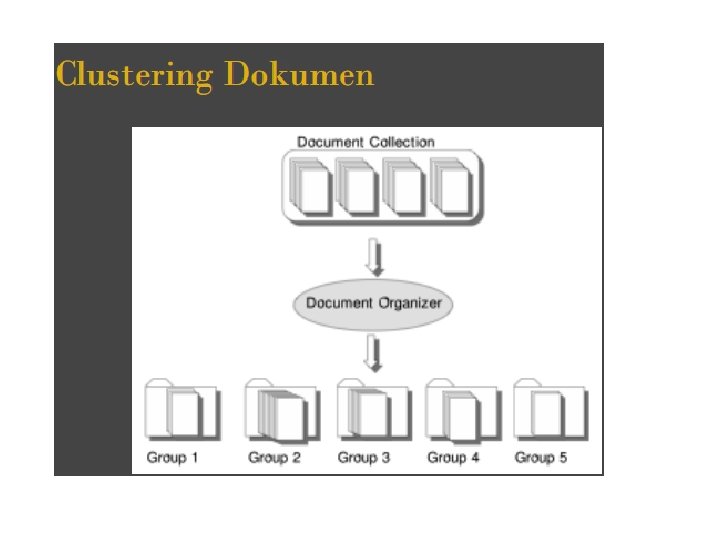
PENGANTAR PENGOLAHAN TEXT 1. 2. 3. 4. 5. Document Collections Knowledge & Document Retrieval. Text Mining. Ontologies
Model-model sistem Temu Balik Informasi (Model Klasik) • Boolean • Vector • Probabilistic
Model-model sistem Temu Balik Informasi (Terstruktur, Browsing) • Model Terstruktur (Non overlapping lists & Proximal Nodes). • Model Browsing (Flat, Structure guided, Hypertext).
• • Evaluasi Sistem Temu Balik Informasi Relevansi Retrieved Recall Precision
Query Languages • Keyword Based Querying • Pattern Matching • Structured Queries
Text Operations General Doc Preprocessing Lexical analysis Parts-of-speech tagging Stopwords Stemming/lemmatization Index terms Thesaurus Query Preprocessing Phrasing Anti-phrasing
Pengantar Liguistic Morphology Lexical categories Morphological processes Parts-of-speech (POS) POS tagging Lemmatization Stemming Semantic relations Word. Net
Indexing & Searching • Indexing • Searching
Searching The Web • • Characterizing the Web: Search Engines: Browsing Future of search engines
KONSEP DASAR SISTEM TEMU BALIK INFORMASI • Tipe Sistem Informasi • Sistem Temu Balik Informasi (Information Retrieval System - IRS) merupakan salah satu tipe sistem informasi. Selain Sistem Temu Balik Informasi, kita kenal beberapa sistem informasi yang lain seperti Sistem Manajemen Basis Data (Data Base Management System DBMS), Sistem Informasi Manajemen (Management Information System – MIS), Sistem Pendukung Keputusan (Decision Support System - DSS) dan Sistem Kecerdasan Buatan (Artificial Intelligent System - AI).
A. Sistem Temu Balik Informasi • Sistem Temu Balik Informasi merupakan sistem yang berfungsi untuk menemukan informasi yang relevan dengan kebutuhan pemakai. Salah satu hal yang perlu diingat adalah bahwa informasi yang diproses terkandung dalam sebuah dokumen yang bersifat tekstual. Dalam konteks ini, temu Balik informasi berkaitan dengan representasi, penyimpanan, dan akses terhadap dokumen representasi dokumen. Dokumen yang ditemukan tidak dapat dipastikan apakah relevan dengan kebutuhan informasi pengguna yang dinyatakan dalam query. Pengguna Sistem Temu Balik informasi sangat bervariasi dengan kebutuhan informasi yang berbeda-beda.
Contoh Sistem IR Conventional (katalog perpustakaan) Pencarian dengan kata kunci, judul, penulis, dll. Text-based (Google, Yahoo, ASK). Pencarian dengan kata kunci (keyword). Pencarian terbatas menggunakan query dalam bahasa alami. Multimedia (QBIC, Web. Seek, Sa. Fe) Pencarian dengan penampilan visual (bentuk, warna, …) Sistem jawaban pertanyaan (Ask. Jeeves, Answerbus) Pencarian dalam bahasa alami (terbatas) Lainnya: IR lintas-bahasa, music retrieval
B. Sistem Manajemen Basis Data • Sistem Manajemen Basis Data merupakan sistem yang didisain untuk memanipulasi dan mengurus basis data. Data yang tersimpan dalam basis data dinyatakan dalam bentuk unsur data yang spesifik dan tersimpan dalam tabel-tabel. Setiap satuan data, atau disebut record (cantuman) terdiri dari ruas-ruas (fields) yang berisi nilai yang menunjukkan karakteristik yang spesifik atau atribut yang mengidentifikasikan satuan data yang dimaksud. Proses yang berkaitan dengan manajemen basis data meliputi penyimpanan, temu Balik, updating atau deletion, proteksi dari kerusakan, dan kadang-kadang mencakup transimi data. Output dapat mengandung record individual, sebagian record, tabel, atau bentuk susunan data yang lain dari basis data. Informasi yang ditemukan berisi cantuman-cantuman yang pasti sesuai dengan permintaan.
C. Sistem Informasi Manajemen • Sistem Informasi Manajemen adalah sistem yang didisain untuk kebutuhan manajemen untuk mendukung fungsi-fungsi dan aktivitas manajemen pada suatu organisasi. Oleh karena itu, jenis data dan fungsi-fungsi operasi disesuaikan dengan kebutuhan manajemen.
D. Sistem Pendukung Keputusan • Sistem Pendukung Keputusan menggambarkan operasi-operasi spesifik dalam satuan-satuan informasi yang homogen.
E. Sistem Kecerdasan Buatan • Tabel 1 memberikan perbandingan antara Sistem Temu Balik Informasi, Sistem Manajemen Basis Data dan Artificial Intelligent seperti yang dikemukakan oleh Frakes dan Baeza-Yates (1992).
Tujuan dan Fungsi Sistem Temu Balik Informasi • Sistem Temu Balik Informasi didisain untuk menemukan dokumen atau informasi yang diperlukan oleh masyarakat pengguna. Sistem Temu Balik Informasi bertujuan untuk menjembatani kebutuhan informasi pengguna dengan sumber informasi yang tersedia dalam situasi seperti dikemukakan oleh Belkin (1980) sebagai berikut: 1. Penulis mempresentasikan sekumpulan ide dalam sebuah dokumen menggunakan sekumpulan konsep. 2. Terdapat beberapa pengguna yang memerlukan ide yang dikemukakan oleh penulis tersebut, tapi mereka tidak dapat mengidentifikasikan dan menemukannya dengan baik.
3. Sistem temu Balik informasi bertujuan untuk mempertemukan ide yang dikemukakan oleh penulis dalam dokumen dengan kebutuhan informasi pengguna yang dinyatakan dalam bentuk pertanyaan (query). Berkaitan dengan sumber informasi di satu sisi dan kebutuhan informasi pengguna di sisi yang lain, Sistem Temu Balik Informasi berperan untuk: 1. Menganalisis isi sumber informasi dan pertanyaan pengguna. 2. Mempertemukan pertanyaan pengguna dengan sumber informasi untuk mendapatkan dokumen yang relevan.
Adapun fungsi utama Sistem Temu Balik Informasi seperti dikemukakan oleh Lancaster (1979) dan Kent (1971) adalah sebagai berikut: a. Mengidentifikasi sumber informasi yang relevan dengan minat masyarakat pengguna yang ditargetkan. b. Menganalisis isi sumber informasi (dokumen) c. Merepresentasikan isi sumber informasi dengan cara tertentu yang memungkinkan untuk dipertemukan dengan pertanyaan (query) pengguna. d. Merepresentasikan pertanyaan (query) pengguna dengan cara tertentu yang memungkinkan untuk dipertemukan sumber informasi yang terdapat dalam basis data. e. Mempertemukan pernyataan pencarian dengan data yang tersimpan dalam basis data. f. Menemu-Balikkan informasi yang relevan. g. Menyempurnakan unjuk kerja sistem berdasarkan umpan balik yang diberikan oleh pengguna.
Komponen Sistem Temu Balik Informasi Menurut Lancaster (1979) Sistem Temu Balik Informasi terdiri dari 6 (enam) subsistem, yaitu: 1. Subsistem dokumen 2. Subsistem pengindeksan 3. Subsistem kosa kata 4. Subsistem pencarian 5. Subsistem antarmuka pengguna-sistem 6. Subsistem penyesuaian.
Gambar 1. Outline Sistem Temu Balik Informasi
Sementara itu Tague-Sutcliffe (1996) melihat Sistem Temu Balik Informasi sebagai suatu proses yang terdiri dari 6 (enam) komponen utama yaitu: 1. Kumpulan dokumen 2. Pengindeksan 3. Kebutuhan informasi pemakai 4. Strategi pencarian 5. Kumpulan dokumen yang ditemukan 6. Penilaian relevansi
Bila diperhatikan dengan seksama, perbedaan komponen Sistem Temu Balik Informasi menurut Lancaster (1979) dan menurut Tague-Sutcliffe (1996) terletak pada penilaian relevansi, yaitu suatu tahap dalam temu Balik untuk menentukan dokumen yang relevan dengan kebutuhan informasi pemakai. Secara garis besar komponen Sistem Temu Balik menurut Tague. Sutcliffe (1996) dapat diilustrasikan seperti pada Gambar 2
Gambar 2. Komponen Sistem Temu-Kembali Informasi
Dalam proses pencarian informasi terjadi interaksi antara pengguna dengan sistem (mesin) baik secara langsung maupun tidak langsung. Secara umum interaksi antara pengguna dengan sistem dalam proses pencarian informasi dapat dinyatakan seperti pada Gambar 3.
Data retrieval – Dokumen mana yang mengandung himpunan keyword? – Semantik didefinisikan dengan baik – Error dari suatu obyek mengakibatkan kegagalan! Information retrieval – Informasi mengenai suatu subyek atau topik – Semantik dapat bersifat lepas (longgar) – Error kecil ditoleransi
IR di tengah pertunjukan – IR dalam 20 tahun terakhir: • Klasifikasi dan kategorisasi • Sistem dan bahasa • Antarmuka pengguna dan visualisasi – Masih, area dilihat sebagai bidang yang sempit – Web mengubah persepsi ini • Repository pengetahuan universal • Akses universal gratis (biaya rendah) • Volume raksasa dari informasi tanpa editorial board terpusat Meskipun banyak masalah: IR merupakan kunci untuk menemukan solusi!
Sistem IR 1. Menerima query pengguna yang mewakili kebutuhan informasi 2. Mencari dan menginterpretasikan content (isi) dari item-item informasi 3. Membangkitkan suatu ranking yang mencerminkan relevansi terhadap kebutuhan informasi tersebut 4. Ide mengenai relevansi adalah sangat penting
Kebutuhan IR WWW: lebih 25 milyar halaman web, 1. 3 milyar gambar dan lebih 1 milyar pesan Usenet yang diindeks pada Google (2006) Berbagai kebutuhan informasi: – Mencari dokumen yang masuk dalam topik tertentu – Mencari suatu informasi spesifik – Mencari jawaban dari suatu pertanyaan – Mencari informasi dalam bahasa berbeda –. . .
Penjualan Software Text Retrieval
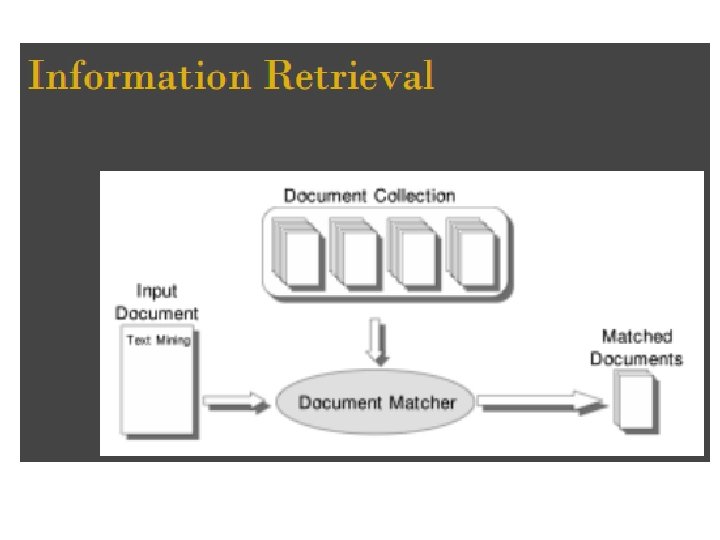
Information Retrieval (IR) • Secara teknis: indexing (pembuatan index) dan retrieval (pencarian keterangan) dokumen textual. • Pencarian halaman pada WWW adalah aplikasi paling “ngetop” saat ini • Fokus pertama: meretrieve dokumen yang relevan dengan query. • Fokus kedua: meretrieve himpunan besar dokumen secara efisien.
Informationvs Data Retrieval Sistem data retrieval (seperti database) berurusan dengan structured data yang mempunyai semantik terdefinisi dengan baik dan kebutuhan meretrieve hasil yang pasti (exact) Sistem IR berurusan dengan dokumen bahasa alami (natural language) dan error kecil dapat diabaikan. Sistem IR harus menginterpretasikan content kemudian meranking daftar content sesuai dengan tingkat relevansinya. Tujuan: Meretrieve semua dokumen yang relevan sekaligus meretrieve sesedikit mungkin dokumen yang tidak relevan
Sistem IR
Contoh Sistem IR Conventional (katalog perpustakaan) Pencarian dengan kata kunci, judul, penulis, dll. Text-based (Google, Yahoo, ASK). Pencarian dengan kata kunci (keyword). Pencarian terbatas menggunakan query dalam bahasa alami. Multimedia (QBIC, Web. Seek, Sa. Fe) Pencarian dengan penampilan visual (bentuk, warna, …) Sistem jawaban pertanyaan (Ask. Jeeves, Answerbus) Pencarian dalam bahasa alami (terbatas) Lainnya: IR lintas-bahasa, music retrieval
Sistem IR di Web 1. Pencarian halaman web http: //www. google. com 2. Pencarian gambar http: //images. google. com 3. Pencarian isi (content) gambar http: //wang. ist. psu. edu/IMAGE/ 4. Pencarian jawaban pertanyaan http: //www. askjeeves. com 5. Pencarian musik? Hati-hati, jangan melanggar hukum.
Relevansi merupakan suatu judgment (keputusan) subyektif dan dapat didasarkan pada: – topik yang tepat. – waktu (informasi terbaru). – otoritatif (dari suatu sumber terpercaya). – kebutuhan informasi dari pengguna. Kriteria relevansi utama: suatu sistem IR sebaiknya (harus) memenuhi kebutuhan informasi pengguna.
Pencarian Keyword Ide paling sederhana dari relevansi: apakah string query ada di dalam dokumen (kata demi kata, verbatim)? Ide yang lebih fleksibel: Berapa sering kata -kata di dalam query muncul di dalam dokumen, tanpa melihat urutannya (bag of words)?
Masalah dengan Keyword Mungkin tidak meretrieve dokumen relevan menyertakan synonymous terms. – “restaurant” vs. “café” – “NDHU” vs. “National Dong Hwa University” Mungkin meretrieve dokumen tak-relevan menyertakan ambiguous terms. – “bat” (baseball vs. mamalia) – “Apple” (perusahaan vs. buah-buahan) – “bit” (unit data vs. perilaku menggigit) yang
Bukan Sekedar Keyword Kita akan mendiskusikan dasar-dasar IR berbasis keyword, tetapi… – Fokus pada perluasan dan pengembangan terakhir untuk mendapatkan hasil terbaik. Kita akan membahas dasar-dasar pembangunan sistem IR yang efisien, tetapi… – Fokus pada algoritma dan kemampuan dasar, bukan masalah sistem yang memungkinkan pengembangan ke database ukuran industri.
IR Cerdas Memanfaatkan pengertian atau makna dari kata yang digunakan. Melibatkan urutan kata di dalam query. Beradaptasi dengan pengguna berdasarkan pada feedback, langsung atau tidak langsung. Memperluas pencarian dengan term terkait. Mengerjakan pemeriksaan ejaaan/perbaikan tanda pengenal otomatis. Memanfaatkan Otoritas dari sumber informasi.
Indeks Sistem IR jarang mencari koleksi dokumen secara langsung. Berdasarkan pada koleksi dokumen, dibangun sebuah index. Pengguna mencari index tersebut.
Indexing Otomatis Tujuan dari automatic indexing adalah membangun index dan meretrieve informasi tanpa intervensi manusia. Ketika informasi yang dicari adalah teks, metode automatic indexing akan sangat efektif. Penelitian automatic indexing fundamental dimulai oleh Gerald Salton, Professor of Computer Science di Cornell & mahasiswa Pasca-Sarjananya (Sistem SMART).
IR dari Koleksi Besar Information retrieval dari koleksi sangat besar bersandar pada: – Jumlah computer power yang besar untuk mengerjakan algoritma sederhana terhadap jumlah data yang sangat banyak. komputasi kinerja-tinggi – Pemahaman pengguna terhadap informasi dan kemampuan dari sistem. Interaksi manusia - komputer Machine-learning banyak digunakan untuk mendapatkan kinerja terbaik.
Searching & Browsing • Orang dalam perulangan
IR dari Koleksi Dokumen Teks Kategori utama dari metode: – Ranking kemiripan terhadap query (vector space model). – Pencocokan exact (Boolean). – Ranking berdasarkan tingkat kepentingan dokumen (Page. Rank) – Kombinasi beberapa metode Contoh: Web search engine, seperti Google & Yahoo, menggunakan metode kombinasi, berdasarkan pada pendekatan pertama dan ketiga, dengan kombinasi exact dipilih menggunakan machine learning
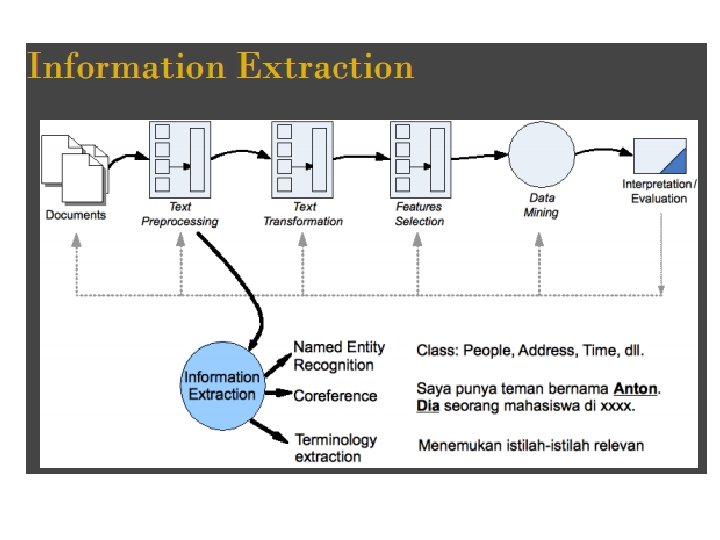
Istilah Penting Information retrieval: sub-bidang ilmu komputer yang berurusan dengan penemuan kembali dokumen (khususnya teks) terotomatis berdasarkan pada content dan contextnya. Searching: Pencarian informasi spesifik di dalam badan informasi. Hasilnya adalah sehimpunan hit. Browsing: Eksplorasi tak-terstruktur dari badan informasi. Linking: Berpindah dari satu item ke item lain mengikuti link (sambungan) seperti rujukan (referensi).
. . . Istilah Query: Suatu string teks, menggambarkan informasi yang sedang dicari pengguna. Setiap kata dari query dinamakan search term. Query dapat berupa search term tunggal, string dari term, frase atau ekspresi tertentu menggunakan simbol khusus, misalnya regular expression. Pencarian Full text: Metode yang membandingkan query dengan setiap kata di dalam teks, tanpa membedakan fungsi dari berbagai kata. Pencarian Bidang : Metode pencarian pada bidang struktural atau bibliografis spesifik, seperti penulis atau judul.
. . . Istilah Corpus: Koleksi dokumen yang diindeks dan dijadikan target pencarian. Daftar kata: Himpunan semua term yang digunakan dalam indeks untuk suatu corpus (dikenal sebagai vocabulary file). Pada pencarian full text, word list adalah semua term di dalam corpus, stop words dihapus. Term- term terkait dikombinasi dengan stemming. Controlled vocabulary: Metode indexing dimana word list bersifat tetap. Term-term dari vocabulary tersebut dipilih untuk mendeskripsikan setiap dokumen. Keyword: Nama untuk term-term dalam word list, terutama dengan controlled vocabulary
Mengurutan & Ranking Hit Ketika pengguna men-submit suatu query ke sistem IR, sistem mengembalikan sehimpunan hit. Pada koleksi dokumen besar, himpunan hit akan sangat besar. Nilai untuk pengguna sering tergantung pada urutan hit ditampilkan. Tiga metode utama: – Mengurutkan hit, misal berdasarkan tanggal – Meranking hit berdasarkan kemiripan antara query dan dokumen – Meranking hit berdasarkan kepentingan dari dokumen
IR Berbasis Teks Sebagian besar metode ranking didasarkan pada model ruang vektor (vector space model). Sebagian besar metode pencocokan (matching) didasarkan ada operator Boolean. Metode Web search mengkombinasikan model ruang vektor dengan ranking berdasarkan pada tingkat kepentingan dokumen. Banyak sistem (dalam praktek) menggabungkan fitur- fitur dari beberapa pendekatan. Pada bentuk dasar, semua pendekatan menganggap kata sebagai token terpisah, dengan usaha minimal untuk memahami kata secara linguistik.
Frekuensi Kata Observasi: Beberapa kata lebih umum daripada yang lain. Statistika: Koleksi sangat besar dari dokumen teks tak-terstruktur mempunyai karakteristik statistik serupa. Statistik ini: – Mempengaruhi efektifitas dan efisiensi dari struktur data yang digunakan untuk mengindeks dokumen – Banyak model retrieval memanfaatkannya
. . . Frekuensi Kata Contoh: Contoh berikut ini diambil dari : – Jamie Callan, Characteristics of Text, 1997 – 19 Juta kata sampel – Slide berikut memperlihatkan 50 kata yang paling umum, diranking (r) berdasarkan frekuensinya (f).
. . . Frekuensi Kata
Distribusi Ranking Frekuensi Untuk semua kata di dalam suatu dokumen, untuk setiap kata w – f adalah frekuensi munculnya w – r ranking dari w disusun menurut frekuensi. (kata yang paling umum muncul mempunyai rank =1)
Contoh Frekuensi Rank Slide berikut memperlihatkan kata-kata di dalam data Callan yang telah dinormalisasi. Dalam contoh ini: – r adalah ranking dari kata w dalam sampel. – f adalah frekuensi kata w di dalam sampel. – n adalah jumlah total kemunculan kata di dalam sampel.
. . . Contoh Ranking Frekuensi