Troubleshooting Always On Availability Groups Chirag Shah Premier

Troubleshooting Always. On Availability Groups Chirag Shah Premier Field Engineer

Prerequisites: Familiarity with Setting up and Deploying Always. On Availability Groups This is NOT a beginner level session Legal disclaimer: content, ideas and opinions stated are my own and not my employer

Availability Groups: Various Logs Ø SQL Server error logs Ø Node Cluster logs Ø Cluster Event logs Ø SQL Server Failover Cluster Instance Diagnostic Logs (Xevent) Ø Always. On_health logs Ø System and application event logs

Cluster Diagnostic Logs i. e. sp_server_diagnostics results 10 files 100 MB each Files are stored in SQL Server LOG directory Stored on SQL Server hosting currant primary replica* XEVENT files that can be opened using management studio

Availability Groups: Troubleshooting Configuration and Setup

Error 35250 Failed to join database to the availability group Step: 1 Make sure database mirroring endpoint got created and started.

Error 35250 Failed to join database to the availability group Step: 2 Firewall NOT blocking inbound port on which Always. On Mirroring Endpoint is listening • By default when you create an AG it uses 5022 database mirroring endpoint. • Make sure Firewall or sometimes Antivirus not blocking on that endpoint

Error 35250 Failed to join database to the availability group Step: 3 SQL Server Service Startup Account has NOT be given connect permission on the endpoint • Make sure domain account is used as SQL Server service startup and it has connect permission on the endpoint on all the nodes participating in availability groups.
 does not have the")
Availability Group – Listener Creation Fails Cluster Name Object (CNO) does not have the "Create Computer object" permission in the computer container in Active Directory Users and Computers Active Directory or Windows Policy can prevent creation of new Computer Object. You cannot register the IP address in DNS because of certain problems that involve a duplicate or invalid IP address for listener.

Availability Group – Listener Creation Fails Failover Cluster Logs You can use Get-Cluster. Log Power. Shell Cmd. Let Windows System Event Logs Open Windows Event Viewer, under System Event Logs filter by source “Failover. Clustering”

Availability Group – Listener Creation Fails CNO was in different OU so issue was permission related in Active Directory.

Connection Timeout in Multi-subnet Availability Group Cause: Not using Multi. Subnet. Failover connection string attribute in multi-subnet environment Availability Group Listener has IP address in each of the subnet ALL listener IP addresses are registered in DNS Default is Register. All. Providers. IP=1 however at a time only one IP address is online.

Connection Timeout in Multi-subnet Availability Group Cause: Not using Multi. Subnet. Failover connection string attribute in multi-subnet environment Without the Multi. Subnet. Failover parameter, the client driver will try to connect sequentially to all IP addresses for the listener. Sequential connections may cause a long logon time or logon time-outs. If you use Multi. Subnet. Failover =True in connection string, client will try to connect to all listener IP address in parallel.

Connection Timeout in Multi-subnet Availability Group What if in a multi-subnet listener scenario, client cannot support “Multi. Subnet. Failover=true” attribute Change v HOSTRecord. TTL Reduce v Register. All. Provider. IP=0

Multi-subnet AG- Transparent. Network. IPResolution Starting with. NET 4. 6. 1 and also part of Microsoft ODBC Driver 13. 1 In case of DNS name returning multiple IP address an initial connection attempt to the first-returned IP address is made, but that attempt is timed-out after only 500 ms, and then connection attempts to all the IP addresses are attempted in parallel. By default, Transparent. Network. IPResolution property is set to true.

Always. On Common Customer Scenarios Why did my Availability Group Failover? OR Why didn’t my availability group failover?

Why did my Availability Group Failover? Lease Timeout Who initiates automatic failover? Health Check Timeout Windows Cluster Health Detection (Network Issues, Cluster Node Down) New in SQL 2016 Database Status <> ‘ONLINE’
 and SQL")
Automatic Failover Detection Lease Timeout: Signaling mechanism between resource DLL (HADRRES. DLL) and SQL Server. Default: 1/4 of Lease. Timeout settings in Cluster which is by default every 5 seconds. Health Check Timeout: The Always. On health DLL (HADRRES. DLL), running in RHS. EXE has a local ODBC connection to SQL Server and expects to receive sp_server_diagnostics results back within the availability group's HEALTH_CHECK_TIMEOUT property, by default, which is 30 seconds. 1 Cluster service sends Looks. Alive 2 sp_server_diagnostics results returned to Resource DLL 3 Resource DLL processes results, detects ERROR. Notify Cluster service. 4 Cluster service issues Offline to SQL Server 5 Execute sp_availability_group_command_internal takes databases offline

Concept of Lease Why? Server A Server C Server B HR DB AG_HR Primary Secondary When a partition happens on a 3 node majority cluster (say A, B, C); assume B and C form one partition and A alone is in one partition. B and C form a quorum set while there is no quorum for A. Since there is no quorum, Cluster calls Terminate for all the resources that are currently online on A and calls Online for these resources on either B or C. Cluster expects the Terminate call to succeed on A like before. In the case that it doesn’t succeed the availability group remains as primary on A and since cluster calls Online on either B or C, this leads to split brain scenario.

Availability Group “Lease” is maintained between Windows Cluster and Primary Replica hosting the availability group. Ensure SQL Server is responsive “Lease” provides additional protection mechanism to avoid split brain condition. If you have multiple AGs, is there a separate “lease” for each? Two way handshake Uses a preemptive thread which runs at priority (not a SQL Server worker thread)

Availability Group “Lease Timeout” Lease is renewed ¼ of Lease Timeout Interval ~ 5 seconds in a default configuration. If more than 20 seconds “Lease” is not renewed HADRRES. dll part of RHS. exe reports an error to windows cluster. Windows Cluster will proceed with taking a corrective action at that time. What causes Lease Timeout Overall System Performance Degradation e. g. Working Set Trim. SQL Server generating a memory dump i. e. Access Violation or Deadlock Schedulers 100 Percent CPU utilization for a sustain period of time.

Demo Availability Groups Lease Timeout

Error Message Cause Corrective Action 19407 The lease between availability group <ag> and the Windows Server Failover Cluster has expired. Generic Lease Timeout System Performance Message. Still accompanied Degradation by other messages SQL Server Dump Diagnostics 19419 The renewal of the lease between availability group '%. *ls' and the Windows Server Failover Cluster failed because the existing lease is no longer valid. The lease worker on the SQL Lease timeouts needs Server side did not get investigation on the SQL scheduled on time to Server side. process event signal from the cluster. 19421 The renewal of the lease between availability group '%. *ls' and the Windows Server Failover Cluster failed because renewal didn't happen within lease interval. The lease helper on the cluster side did not signal the SQL Server lease worker on time. Check corresponding availability group resource in WSFC cluster to see if it reported any error. 19422 The renewal of the lease between availability group '%. *ls' and the Windows Server Failover Cluster failed because of a windows error with Error code ('%d'). The lease worker on SQL Server side failed to renew the lease because of a windows error. Check windows error code and take the corrective action.

Lease Timeout: Default is 20 seconds so lease renewal occurs every ¼ of that timeout value. Health Check Timeout: Default value is 30 seconds so health detection through sp_server_diagnostics occurs every 1/3 of that timeout value. Failure Condition Level: Condition ranges from 1 to 5 where 1 is high level to 5 which is very granular. A given condition level encompasses all lower condition levels. So for e. g. default is 3 it will include both 1 and 2.

Flexible Failover Policy 5 – Failover or restart on any qualified failure conditions Query Processing errors 4 – Failover or restart on moderate SQL Server errors Resource errors - OOM 3 – Failover or restart on critical SQL Server errors System errors 2 – Failover or restart on server unresponsive sp_server_diagnostics failure or timeout 1 – Failover or restart on SQL service failure Service down

sp_server_diagnostics results Starting with SQL 2012 instead of using SELECT @@SERVERNAME Windows Cluster RHS. exe uses sp_server_diagnostics system stored procedure to capture diagnostic data and potential failover. The stored procedure exist in all SQL Server edition including standalone and clustered instances. it can detect SQL Server internal errors like worker thread exhaustion, persistent OOM condition in internal resource pool, orphaned spin-locks

Why Automatic Failover did not occur? One or more DB in AG not in Sync state Secondary not connected Exceeded failover threshold WSFC cannot connect to SQL Server AG set with manual failover or Async Replica

Why Automatic Failover did not occur? Maximum Failover Threshold Number of nodes in the cluster (n-1) In a two node cluster, a cluster resource (e. g. AG) can automatically failover 1 time every 6 hours.

Availability Group Related Wait Types

Troubleshooting : Wait Types HADR_SYNC_COMMIT WRITELOG HADR_SYNCHRONIZING_TH ROTTLE Wait type indicating a delay as transaction cannot commit on primary cause it is waiting to be hardened on synchronous secondary replica. A wait type with no direct relevance with Always. On. Typically indicates time it takes to hardened log block to transaction log. Investigation needed as it mostly indicates storage subsystem bottleneck. Wait related to synchronizing secondary database to catch up with the primary database in order to transition from synchronizing state to synchronized state. Primary puts an intentional delay so that secondary can catch up and become synchronized.

HADR waits and synchronization SYNCHRONIZED = HEALTHY SYNCHRONIZING = PARTIALLY_HEALTHY NOT SYNCHRONIZING = NOT_HEALTHY X We PULL Log blocks Primary Transactions These are usually ignored: HADR_LOGCAPTURE_WAIT HADR_WORK_QUEUE REDO_THREAD_PENDING_WORK (secondary) HADR_CLUSAPI_CALL Secondary wait_type WRITELOG and HADR_SYNC_COMMIT WRITELOG HADR_SYNCHRONIZING_THROTTLE post 31

Why Automatic Failover Occurs? Windows Cluster detects heartbeat issue between nodes and fails over the availability group 1135 System Event Log Event_NODE_DOWN Review the cluster log INFO [IM] got event: Remote endpoint xxx. x. xx: ~3343~ unreachable from xxx. x. xx: ~3343~ INFO [IM] Marking Route from xxx. x. xx: ~3343~ to xxx. x. xx: ~3343~ as down

Network Latency is causing slowness Here are the counters that need to be collected when log send queue is observed to grow. Primary SQLServer: Databases: Log Bytes Flushed/sec SQL Server: Availability Replica > Bytes Sent to Replica/sec

Availability Groups: If it is taking longer failover Original Primary had one or multiple long running transaction that transaction needed to be rolled back after the failover increasing recovery time. Cluster part of the failover is usually very quick REDO on secondary was behind so after failover it takes some time before REDO can caught up and recovery completes Most of the time is spent in database “recovery” High Number of VLFs Original Primary had slow Check. Point resulting in increased recovery after failover.

Before failover

Shared Redo Target for Replicas If one of the replicas REDO is behind, it will make other replica slow down Trace Flag: 9559 when enabled on the secondary ignores the redo target provided from the primary progress message and always set the redo target at the Max LSN value

SCENARIO: Quorum is lost – all nodes intact Communication problems between nodes All nodes are intact Recover original primary

Handling Quorum Loss Recover Primary 1. Start node hosting original primary with /Force. Quorum On Original Primary Force Quorum 2. Force Failover of availability group No data loss if run on primary
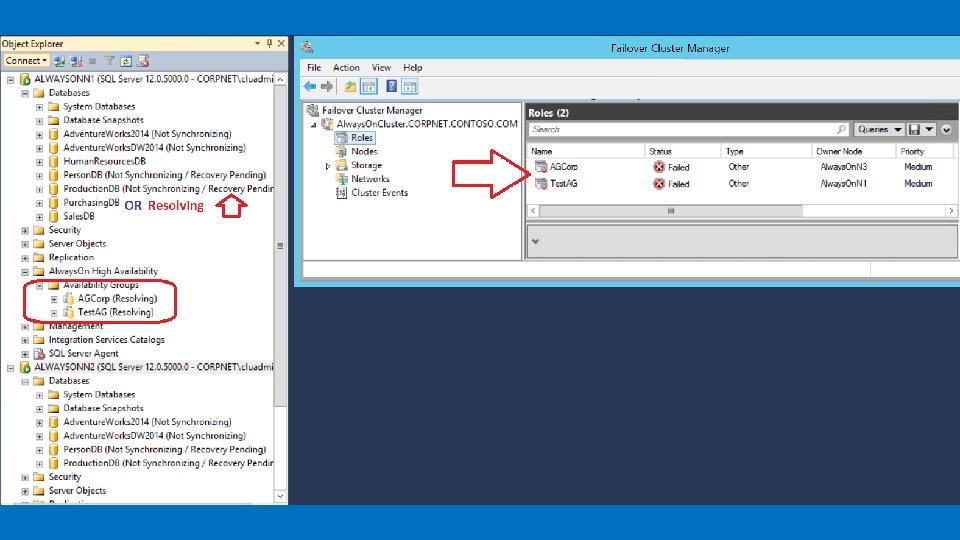

In Virtualized Environment if you find a high number of discarded packets VMWARE KB

Reference: Here are the counters that need to be collected when log send queue is observed to grow. Troubleshooting Always. On: https: //msdn. microsoft. com/en-us/library/dn 135328(v=sql. 110). aspx https: //blogs. msdn. microsoft. com/alwaysonpro/2014/11/26/diagnose-unexpected-failover-or-availability-group-in -resolving-state/
- Slides: 41