TIMBER A Native XML Database The Overview of

TIMBER A Native XML Database The Overview of the TIMBER System in University of Michigan Xiali He

Outline Introduction Motivations and Related Work System Architecture Tree Algebra Query Evaluation Query Optimization Updates Issue

Introduction Why Native XML Database? Ø Mapping between XML data and existing database has some problems due to the flexible nature of XML ü Results in an unnormalized relational representation ü Results in large number of tables Challenges in TIMBER system: Ø Ø Start from scratch Retain XML data’s natural structures and flexibility and heterogeneity Efficient processing on tree structures Updates

Reuse the existing database technologies Ø Ø Ø Transaction Management Facilities Declarative Querying Set-at-a-time Processing Redesign and tailor certain components for the XML domain Ø Ø Ø Bulk Algebra – TAX Query Evaluation Query Optimization

Outline Introduction Motivations and Related Work System Architecture Tree Algebra Query Evaluation Query Optimization Updates Issue

Motivations and Related Work Mapping techniques between tree-based XML data to flat relational schema Problems: Ø Ø XML has very rich tree structure. Relational has rigid table structure. A simple tree schema produces complex relational schema with many tables. A simple XML query get translated into expensive sequences of joins in relational database.

Other Direct XML data management systems: Ø Ø Ø Implementation Procedural Tuple-at-a-time Poor Performance On Top of object-oriented database and semi-structure database

Outline Introduction Motivations and Related Work System Architecture Tree Algebra Query Evaluation Query Optimization Updates Issue System Study

System Architecture TIMBER- An efficient XML database engine Data Storage Index Storage Metadata Storage Query Processing

System Architecture Data Storage Nodes in Timber System: Ø Ø Ø Node for each element Child node for each sub-element Child node for all attributes of an element Child node for content of an element node Child node for all processing instructions, comments. ( in future) Node Identifier in Timber System: (S, E, L) – Start label, End Label, Level Label Physical Storage Order: Sorted nodes by the value of start Labels.

System Architecture Index Storage Indices in Timber System: Ø Ø Ø On attribute values On element content On tag name Index structure return lists of (S, E, L) labels

System Architecture Metadata Storage Use histograms for cost estimation Timber is independent of XML schema Query Processing

Outline Introduction Motivations and Related Work System Architecture Tree Algebra Query Evaluation Query Optimization Updates Issue System Study

Tree Algebra - TAX Timber System develop a suite of operators suited to manipulating trees instead of tuples: Selection Projection Ordering Grouping Product Set Union Set Difference Renaming
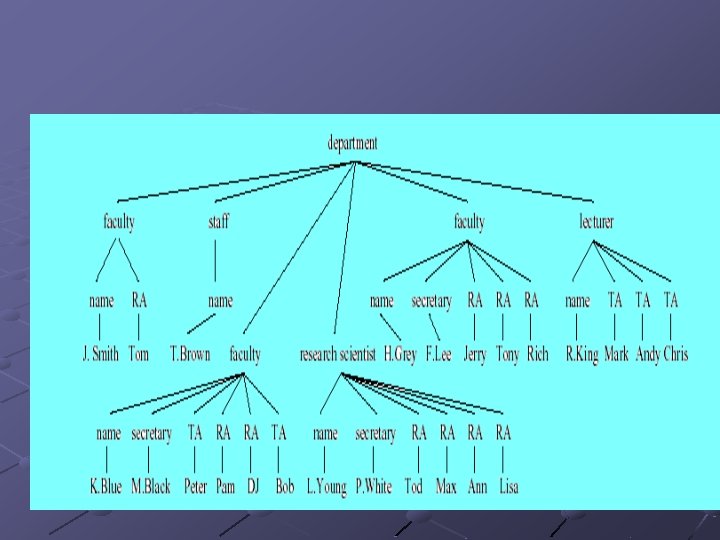

Pattern Tree XML: Algebra - TAX Can not reference the component of the tree by position or name! Solution: Pattern trees to specify homogeneous tuples of node binding. Witness tree is produced for each combination of node bindings that matches the pattern. Pattern tree can bind as many variables as there are nodes in the pattern tree. While XPath binds only one variable. Pattern Tree Witness Tree

Pattern tree can also associate element content etc – another example

Tree Algebra - TAX ü Selection More than just filter! Order is preserved! C - Collection P - pattern SL – Selection List (Lists nodes from P for which not just the nodes themselves, but all descendants, are to be returned in the output) Output: is the witness tree induced by some embedding of P into C, modified as possibly prescribed in SL.

Tree Algebra - TAX ü Projection C - Collection P - pattern PL – Projection List (A list of node labels from P, possible with *) Output: Could be zero, one or more output trees in a projection.

Example - Projection $1. tag = faculty & $1 pc pc $2. tag = RA & $2 $3 $3. tag = name Pattern Tree PL: $1, $3 faculty pc pc RA name pc projection TA name faculty pc pc name TA projection no match

Tree Algebra - TAX ü Ordering Timber system specify pattern trees to be unordered except where ordering constraints are explicitly specified!

Tree Algebra - TAX ü Grouping With the use of grouping, we can produce a simpler and mode efficient execution! Grouping may not induce a partitioning P - pattern C - Collection OL - Ordering List (compose an order direction and an element or element attribute, with values drawn from an ordered domain) GB - Grouping basis (lists elements by label in P, whose value are used to partition the set W of witness tree of P against the collection C) Output: Output tree Si corresponding each group Wi (witness tree) is showed in the next page.

Output tree: Si tax_group_root tax_grouping_basis one child for each element In the grouping basis tax_group_subroots of the input tree in C that corresponding to Wi

How to make FLWR execution more efficient by using grouping operator? FOR $a IN distint-value(document(“bib. xml”)//author) RETURN <authorpubs> {$a} { FOR $b IN document(“bib. xml”)//article WHERE $a = $b/author RETURN $b/title } </authorpubs>

1. Algorithm: Construct an initial pattern tree from the “inner” FLWR statement and consisting of bound variables and their paths from the document root. $1 $1. tag = doc_root & pc $2. tag = article $2 2. Construct the input for the GROUPBY operator $1 $1. tag = article & pc $2 $2. tag = author

3. Apply the GROUPBY operator on the collection of trees generated from step 1. TAX group root TAX group subroot TAX group basis author article title year author

4. A projection is necessary to extract from intermediate grouping nodes necessary for the outcome. $1. tag = TAX Group root & $1 $2. tag = TAX. Grouping basis & $2 $3 $3. tag = TAX group subroot & $4. tag = author & $4 $5. tag = article & $5 $6. tag = title $6 PL: $1, $4*, $6* 5. Use rename operator to change the dummy root to the tag specified in the return clause.

Outline Introduction Motivations and Related Work System Architecture Tree Algebra Query Evaluation Query Optimization Updates Issue

Query Evaluation Physical Algebra Ø Ø Ø Separation of physical algebra and logical algebra Pattern Tree Reuse Node Materialization Structural Joins in Pattern Tree Matching Group. By

Query Evaluation Physical Algebra Pattern Tree Reuse $1 $1. tag = department& $2. tag = faculty & $2 $3 $1 $3. tag = RA & $4 $4. tag = name Isroot($1) & $2. tag = secretary $2 Selection projection Find out the secretary for each faculty? $1 $1. tag = PID 1 WID 2 & $2. tag = secretary $2

Node Materialization Timber system has materialization in the physical algebra, which takes a node identifier(s) as input and returns a set of XML tree(s) that correspond. Partial materialization is needed to minimize the size of the intermediate results being manipulated.

Query Evaluation Structural Joins in Pattern Tree Matching For performance reason, full database scan is not be able to find all the matches in a single pass. Locate one node in each pattern match by indices and scan part of database is good but still expensive. Timber!- Use all available indices and independently locate candidates for as many nodes in pattern tree.

Q: Seeking a faculty who has a secretary reporting to them

§ Whole Stack-Tree Family of Structural Join Algorithm. 10 7 4 2 1 Push AList 9 8 6 5 3 merge DList 1 2 3 4 5 6 7 x stack
 Tree structure")
Query Evaluation Group. By RDBMS implement grouping rely on sorting (or hashing) Tree structure grouping not necessarily partition the set. So timber system use pattern tree to identify group list node and thus produce all possible tuples of bindings. Sorting (hashing) then can be performed by using them.

Query Optimization Structural Join Order Selection § In relational query processing, it is almost good idea to evaluate selections first. § Not in XML! Since structural join may sometimes be more selective than selection predicate; Also, structural joins can be computed with node identifier alone, while selection predicate may require access to the actual data. § Finding the best fully pipelined evaluation plan by using algorithm FP-Optimization.

Result Size Estimation § Need an accurate estimate of the cardinality of the final query as well as each intermediate result for each query plan! § Position Histogram Y- 5(faculty) * 3(TA) = 15 END Upper bound of number of matches = 2*2+1*3 = 7 faculty 0 2 1 TA 0 3 2 XSTART

Outline Introduction Motivations and Related Work System Architecture Tree Algebra Query Evaluation Query Optimization Updates Issue
 Changes in the sizes and numbers")
Update Issue Start and End label? (floating number) Changes in the sizes and numbers of elements could cause pages to overflow or underflow. Space management!

DISCUSSIONS Thank You!
- Slides: 41