THE STRUCTURE OF THE GENETIC MATERIAL DNA is




, Cytosine (C), Guanine")
 Cytosine (C) Pyrimidines Guanine (G) Adenine (A) Purines")
, Cytosine (C),")






















 – The RNA formed from transcription,")















- Slides: 47
THE STRUCTURE OF THE GENETIC MATERIAL
DNA is a Double-Stranded Helix § In 1953, James D. Watson and Francis Crick deduced the structure of DNA, using X-ray crystallography data of DNA from the work of Rosalind Franklin and Maurice Wilkins and Chargaff’s observation that in DNA the amount of adenine was equal to the amount of thymine and the amount of guanine was equal to that of cytosine.
DNA is a Double-Stranded Helix § Watson and Crick reported that DNA consisted of two polynucleotide strands wrapped into a double helix. – The sugar-phosphate backbone is on the outside. – The nitrogenous bases are perpendicular to the backbone in the interior. – Specific pairs of bases give the helix a uniform shape. – A pairs with T, with two hydrogen bonds – G pairs with C, with three hydrogen bonds
DNA and RNA are Polymers of Nucleotides § DNA and RNA are nucleic acids composed of long chains of nucleotides § A nucleotide contains a nitrogenous base, five-carbon sugar, and phosphate group § Nucleotides are joined to one another by a sugar-phosphate backbone. © 2012 Pearson Educaton, Inc.
§ Each DNA nucleotide has a different nitrogenous base: Adenine (A), Cytosine (C), Guanine (G) or Thymine (T) Nitrogenous base (A, G, C, or T) Thymine (T) Phosphate group Sugar (deoxyribose) DNA nucleotide
Nitrogenous Bases of DNA Thymine (T) Cytosine (C) Pyrimidines Guanine (G) Adenine (A) Purines
§ Each RNA nucleotide also has a different nitrogenous base: Adenine (A), Cytosine (C), Guanine (G) or Uracil (U) Nitrogenous base (A, C, G, or U) Sugar (ribose)
The DNA Molecule is Antiparallel § The polynucleotide strands of DNA run in opposite directions or, are antiparallel § DNA has 5’ (prime) and 3’ (prime) ends § The sugar on the 3’ end is attached to a hydroxyl group § The sugar on the 5’end is attached to a phosphate group
Phosphate group on 5’ end Hydrogen bonds G T C A A C T G Partial chemical structure Hydroxyl group on 3’ end
DNA REPLICATION
DNA Replication Depends on Specific Base Pairing Rules § DNA replication follows a Semiconservative Model § DNA strands separate and serve as templates for new DNA § Enzymes read parental strands and link nucleotides (according to base pairing rules) forming complementary strands § DNA replication follows a Semiconservative Model of replication because half of the parental molecule is kept (conserved) in each new DNA helix § DNA replication ensures that all somatic cells in a multicellular organism carry the same genetic information
A T G A A T Parental DNA molecule T A G C Daughter strand T C G T C A G C C Parental strand G C G G T C C T A G T A C C T A T G A T A A C A T G T Daughter DNA molecules
DNA Replication Proceeds in Two Directions at Many Sites Simultaneously § DNA replication begins at the origins of replication where, – DNA unwinds producing a replication bubble – Replication proceeds in both directions from the origin – Replication ends when products (new DNA) from the bubbles merge
Parental DNA molecule Origin of replication “Bubble” Two daughter DNA molecules Parental strand Daughter strand
Daughter Strand Synthesis in DNA Replication § Both daughter strands are synthesized 5’ to 3’; new nucleotides are only added to the 3’ end of a growing strand – The daughter strand that is synthesized toward the replication fork in one continuous piece is the leading strand – The daughter strand synthesized away from the replication fork in (Okazaki) fragments is the lagging strand – Lagging strand synthesis is due to the antiparallel nature of DNA
Daughter Strand Synthesis in DNA Replication
DNA polymerase molecule 5 3 3 5 Leading Strand Parental DNA Replication fork Lagging Strand 3 5 5 3 DNA ligase Overall direction of replication
DNA Replication Requires a Host of Enzymes § Important Enzymes are involved in DNA replication 1. Helicase-breaks H-bonds, unwinding (separating) the DNA double helix 2. Primase-lays down an RNA primer to provide a 3 prime end 3. DNA polymerase reads template strand adds nucleotides to a growing chain, proofreads and corrects improper base pairings 4. DNA ligase joins Okazaki fragments into a continuous DNA strand *DNA polymerases and DNA ligase also repair damaged DNA*
DNA Replication
THE FLOW OF GENETIC INFORMATION FROM DNA TO RNA TO PROTEIN
The DNA Genotype is Expressed as Proteins, Which Provide the Molecular Basis for Phenotypic Traits § Connections between genes and proteins: – In the 1940’s Beadle and Tatum hypothesized that one gene codes for one enzyme by doing studying inherited metabolic diseases – Their hypothesis is still accepted but with important changes: – The hypothesis includes all proteins and that one gene codes for one polypeptide
The DNA Genotype is Expressed as Proteins, Which Provide the Molecular Basis for Phenotypic Traits § DNA specifies traits by determining the sequence of amino acids in a protein; proteins give us our phenotype so genotype determines phenotype § The molecular chain of command is from DNA to RNA to protein § Transcription is the synthesis of RNA using DNA as a template. § Translation is the synthesis of proteins using RNA as a template.
DNA Transcription RNA NUCLEUS Translation Protein CYTOPLASM
Genetic Information in DNA is written in m. RNA as Codons §Instructions for an amino acid sequence of a polypeptide is written in DNA as three base sequences called triplets A A A C C G G C A A Transcription U U U G G C C G U U §In transcription triplets in DNA are copied into complementary three base sequences in m. RNA called codons §Each codon determines the amino acid to be added to a growing polypeptide chain – 64 codons are possible Translation Polypeptide amino acid 1 amino acid 2 amino acid 3 amino acid 4
Third base First base Second base
Transcription § RNA polymerase oversees transcription by – Unwinding DNA, reading DNA bases, and joining appropriate RNA nucleotides together § Transcription occurs in Three Phases: § Initiation - RNA pol. binds the promoter § Elongation - m. RNA strand grows longer § Termination –RNA pol. reaches the terminator sequence and detaches from m. RNA and the gene
RNA polymerase DNA of gene Promoter DNA 1 Initiation Terminator DNA
2 Elongation Area shown in Figure 10. 9 A Growing RNA
3 Completed RNA Termination Growing RNA polymerase
Eukaryotic m. RNA § Messenger RNA (m. RNA) – The RNA formed from transcription, carrying information to build a protein is called m. RNA – m. RNA carries the message from DNA (nucleus) to ribosomes (cytoplasm) – In prokaryotes transcription and translation occur at the same place and time – In eukaryotes, m. RNA exits nucleus via nuclear pores – Eukaryotic m. RNA has introns or interrupting sequences that separate exons or coding regions
Eukaryotic RNA is Processed Before Leaving the Nucleus § m. RNA processing : – Occurs in nucleus of eukaryotic cells – Involves the addition of extra nucleotides to the ends of m. RNA. A 5’ guanine cap and 3’ poly A tail helps to: – facilitate export of m. RNA from nucleus – protect m. RNA from attack by cellular enzymes – help ribosomes bind m. RNA § RNA splicing removes introns and joins exons to produce a continuous coding sequence.
Exon Intron Exon DNA Cap RNA transcript with cap and tail Transcription Addition of cap and tail Introns removed Tail Exons spliced together m. RNA Coding sequence NUCLEUS CYTOPLASM
The Genetic Code Dictates How Codons are Translated into Amino Acids § Translation involves switching from nucleotide “language” to amino acid “language” § t. RNA’s act as interpreters Amino acid attachment site § Transfer RNA (t. RNA) molecules read codons in m. RNA to help synthesize a polypeptide chain § Each t. RNA has a three base sequence or anticodon it uses to read an m. RNA codon Anticodon
Strand to be transcribed DNA T A C T T C A A T A T G A A G T T T C T A G Transcription RNA A U G A A G U U A G Translation Start codon Polypeptide Met Stop codon Lys Phe
The Genetic Code Dictates How Codons are Translated into Amino Acids § Characteristics of the Genetic Code § Three RNA nucleotides (one codon) specify one amino acid § AUG = the start codon signals the ribosome to start translating; AUG also codes for methionine § There are 3 “stop” codons that signal the ribosome to stop translating § The Genetic Code is: § Redundant, there is more than one codon for the same amino acid § Unambiguous, any codon for an amino acid does not code for any other amino acid § Nearly universal, the genetic code is shared by organisms from the simplest bacteria to the most complex plants and animals
Ribosomes Build Polypeptides With the Help of t. RNA’s § Translation occurs on the surface of a Ribosome. – Ribosomes have binding sites for m. RNA and t. RNA to coordinate protein synthesis – Ribosomes have small and large subunits composed of ribosomal RNA (r. RNA) and proteins Growing polypeptide The next amino acid to be added to the polypeptide t. RNA Codons m. RNA
Translation § Translation occurs in Three Phases § Initiation § An m. RNA molecule binds to a small ribosomal subunit and the first t. RNA binds to m. RNA at the start codon § The first t. RNA has the anticodon UAC § The large ribosomal subunit joins the small subunit, forming a functional ribosome § The first t. RNA occupies the P site, which will hold the growing polypeptide chain § The A site is available to receive the next t. RNA
Met Large ribosomal subunit Initiator t. RNA P site m. RNA U A C A U G Start codon 1 Small ribosomal subunit 2 U A C A U G A site
Translation § Elongation involves the addition of amino acids to the polypeptide chain. Each cycle of elongation has three steps. 1. Codon recognition: The anticodon of an incoming t. RNA molecule, (w/ its amino acid), pairs with the m. RNA codon in the A site of the ribosome. 2. Peptide bond formation: The new amino acid is joined to the chain held by t. RNA in A site. 3. Translocation: the P site t. RNA now lacking an amino acid leaves ribosome; the ribosome moves t. RNA (holding the polypeptide) from the A site to the P site.
Polypeptide P site m. RNA Amino acid A site Anticodon Codons 1 Codon recognition m. RNA movement Stop codon 2 New peptide bond 3 Translocation Peptide bond formation
Translation § Termination § The Ribosome reaches a stop codon § The completed polypeptide is freed from the last t. RNA § The ribosome splits into separate subunits
Protein Synthesis
Mutations Can Change the Meaning of Genes § A mutation is any change in the nucleotide sequence of DNA. § Mutations can be caused by – spontaneous errors that occur during DNA replication or crossing over – mutagens, like high-energy radiation (X-rays), UV light and chemicals, viruses
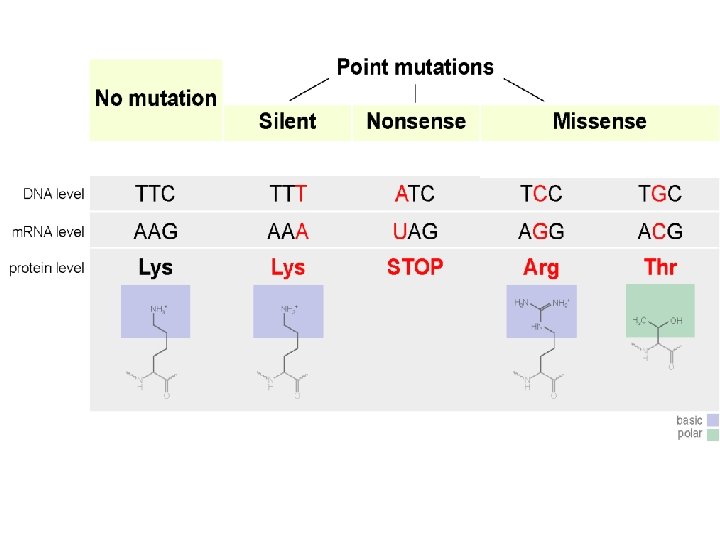
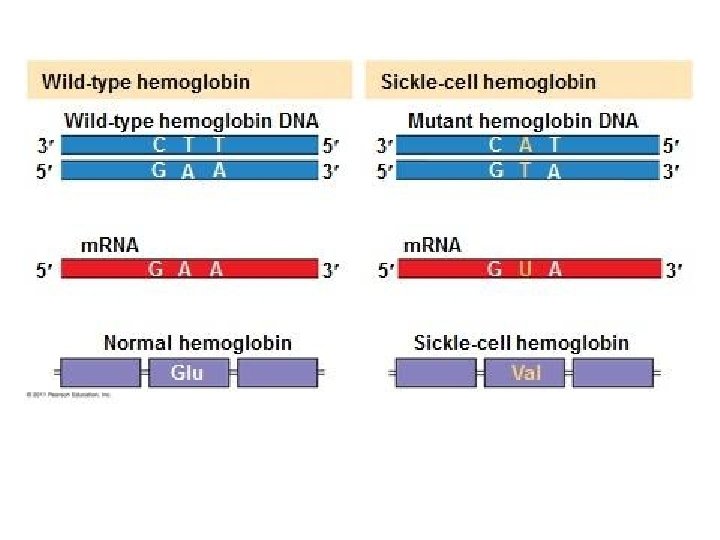
Mutations Can Change the Meaning of Genes § Mutations within a gene can be divided into two general categories. 1. Base substitutions involve the replacement of one nucleotide and its base pairing partner. Base substitutions may – Produce a silent mutation there is no effect on the polypeptide because the right amino acid is still added – Produce a missense mutation where the mutation causes the wrong amino acid to be added to the polypeptide – Produce a nonsense mutation where the mutation produces a stop codon in the m. RNA instead of an amino acid.
Mutations Can Change the Meaning of Genes 2. Mutations can result in deletions or insertions that may – Cause frame shift mutations that alter the reading frame (triplet grouping) of the m. RNA – This typically produces a nonfunctional polypeptide