The Original Google File System GFS Paper from









 • Single master controls multiple chunkservers • Each file divided into fixed-size")












- Justification • 64 MB is large – think of typical size")










 – Ceph monitor (cluster)")



- Slides: 39
The Original Google File System GFS Paper from 2003 Some slides from Michael Raines
• During the lecture, you should identify problems with GFS design decisions
Common Goals of GFS and most Distributed File Systems • Performance • Reliability • Scalability • Availability
GFS Design Considerations • Component failures are the norm rather than the exception. • File System consists of hundreds or even thousands of storage machines built from inexpensive commodity parts. • Files are Huge. Multi-GB Files are common. • Each file typically contains many application objects such as web documents. • Append, Append. • Most files are mutated by appending new data rather than overwriting existing data. • Co-Designing • Co-designing applications and file system API benefits overall system by increasing flexibility
GFS • Why assume hardware failure is the norm? • The amount of layers in a distributed system (network, disk, memory, physical connections, power, OS, application) mean failure on any could contribute to data corruption. • It is cheaper to assume common failure on poor hardware and account for it, rather than invest in expensive hardware and still experience occasional failure.
Initial Google Assumptions • System built from inexpensive commodity components that fail • Modest number of files – expect few million and 100 MB or larger. Didn’t optimize for smaller files • 2 kinds of reads – large streaming read (1 MB), small random reads (batch and sort) • Well-defined semantics: – Master/slave, producer/ consumer and many-way merge. 1 producer per machine append to file. – Atomic RW • High sustained bandwidth chosen over low latency (difference? )
High bandwidth versus low latency • Amount of data vs delay • Example: – An airplane flying across the country filled with backup tapes has very high bandwidth because it gets all data at destination faster than any existing network – However – each individual piece of data had high latency
Interface • GFS – familiar file system interface • Hierarchical organization in directories, path names • Create, delete, open, close, read, write • Snapshot and record append (allows multiple clients to append simultaneously) – This means atomic read/writes – not transactions!
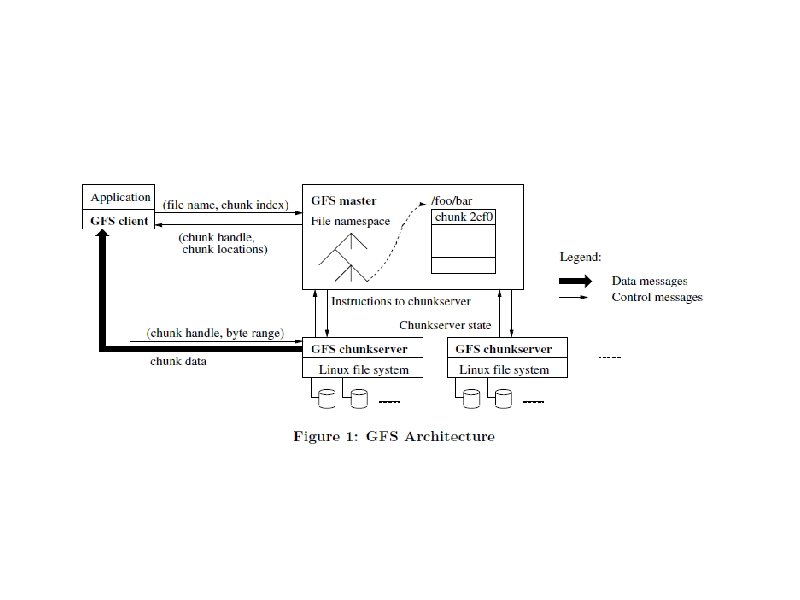
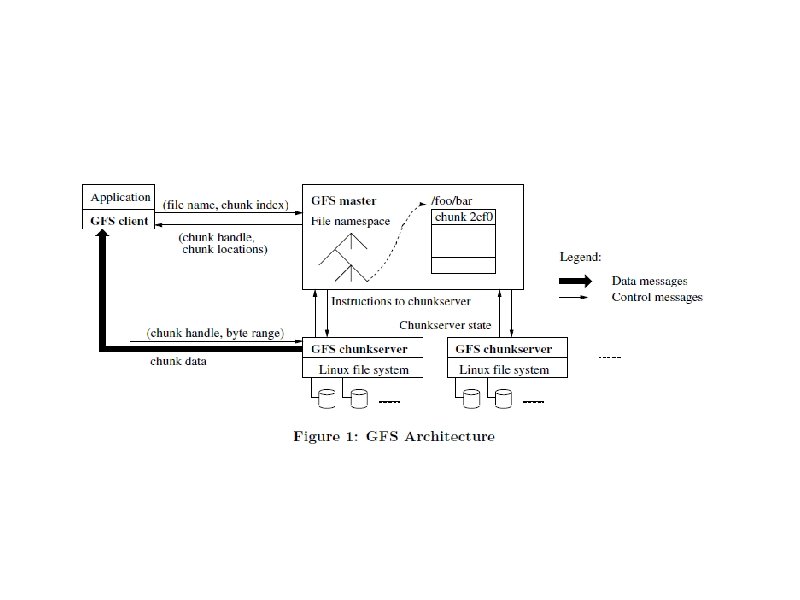
Master/Servers (Slaves) • Single master controls multiple chunkservers • Each file divided into fixed-size chunks of 64 MB – Chunks stored by chunkservers on local disks as Linux files – Immutable and globally unique 64 bit chunk handle (name or number) assigned at creation
Master/Servers – R or W chunk data specified by: • chunk handle • byte range – Each chunk replicated on multiple chunkservers – default is 3
Master/Servers • Master maintains all file system metadata in memory – Namespace, access control info, mapping from files to chunks, location of chunks – Controls garbage collection of chunks – Communicates with each chunkserver through Heart. Beat messages – Clients interact with master for metadata, chunksevers do the rest, e. g. R/W on behalf of applications – No caching – • For client working sets too large, simplified coherence • For chunkserver – chunks already stored as local files, Linux caches MFU in memory
Heartbeats • What do we gain from Heartbeats? • Not only do we get the new state of a remote system, this also updates the master regarding failures. • Any system that fails to respond to a Heartbeat message is assumed dead. This information allows the master to update his metadata accordingly. • This also queues the Master to create more replicas of the lost data.
Client • • Client translates offset in file into chunk index within file Send master request with file name/chunk index Master replies with chunk handle and location of replicas Client caches info using file name/chunk index as key Client sends request to one of the replicas (closest) Further reads of same chunk require no interaction Can ask for multiple chunks in same request
Master Operations Master executes all namespace operations Manages chunk replicas Makes placement decision Creates new chunks (and replicas) Coordinates various system-wide activities to keep chunks fully replicated • Balance load • Reclaim unused storage • • •
• Do you see any problems? • Do you question any design decisions? • What do you think their justifications are? • Single master • Chunk size • In Master’s memory metadata
Master - Justification • Single Master – – Simplifies design – Placement, replication decisions made with global knowledge – Doesn’t R/W, so not a bottleneck – Client asks master which chunkservers to contact
Chunk Size - Justification 64 MB, larger than typical Replica stored as plain Linux file, extended as needed Lazy space allocation Reduces interaction of client with master – R/W on same chunk only 1 request to master – Mostly R/W large sequential files • Likely to perform many operations on given chunk (keep persistent TCP connection) • Reduces size of metadata stored on master • •
Chunk problems • But – – If small file – one chunk may be hot spot – Can fix this with replication, stagger batch application start times
Metadata • 3 types: – File and chunk namespaces – Mapping from files to chunks – Location of each chunk’s replicas • All metadata in memory • First two types stored in logs for persistence (on master local disk and replicated remotely)
Metadata • Instead of keeping track of chunk location info – Poll – which chunkserver has which replica – Master controls all chunk placement – Disks may go bad, chunkserver errors, etc.
Metadata - Justification • In memory –fast – Periodically scans state • garbage collect • Re-replication if chunkserver failure • Migration to load balance – Master maintains < 64 B data for each 64 MB chunk • File namespace < 64 B
Chunk size (again)- Justification • 64 MB is large – think of typical size of email • Why Large Files? o METADATA! • Every file in the system adds to the total overhead metadata that the system must store. • More individual data means more data about the data is needed.
Shadow Master • Master Replication – Replicated for reliability – Not mirrors, so may lag primary slightly (fractions of second) – Shadow master read replica of operation log, applies same sequence of changes to data structures as the primary does
Shadow Master • If Master fails: – Start shadow instantly – Read-only access to file systems even when primary master down – If machine or disk mails, monitor outside GFS starts new master with replicated log – Clients only use canonical name of master
Creation, Re-replication, Rebalancing • Master creates chunk – Place replicas on chunkservers with below-average disk utilization – Limit number of recent creates per chunkserver • New chunks may be hot – Spread replicas across racks • Re-replicate – When number of replicas falls below goal • Chunkserver unavailable, corrupted, etc. • Replicate based on priority (fewest replicas) – Master limits number of active clone ops
Creation, Re-replication, Rebalancing • Rebalance – Periodically moves replicas for better disk space and load balancing – Gradually fills up new chunkserver – Removes replicas from chunkservers with belowaverage free space
Consistency Model • Why Append Only? • Overwriting existing data is not state safe. o We cannot read data while it is being modified. • A customized ("Atomized") append is implemented by the system that allows for concurrent read/write, write/write, and read/write events.
Consistency • Relaxed consistency can be accommodated – relying on appends instead of overwrites • Appending more efficient/resilient to failure than random writes • Checkpointing allows restart incrementally and no processing of incomplete successfully written data
Conclusions • GFS – qualities essential for large-scale data processing on commodity hardware • Component failures the norm rather than exception • Optimize for huge files appended to • Fault tolerance by constant monitoring, replication, fast/automatic recovery • High aggregate throughput – Separate file system control – Large file size
Ceph Storage
• Free-software storage platform • Implements object storage on a single distributed cluster • Interfaces for object, block, file level storage • Completely distributed – no single point of failure • Replicates data so fault tolerant • Assumes commodity hardware with no specific HW support • Can use Ceph instead of Swift in Open. Stack
• 2 types of daemons (run as background processes) – Ceph monitor (cluster) M • Keep track of active and failed cluster nodes – Ceph OSD deamon • Stores the contents of files • Services clients directly
• Block devices – snapshots, cloning, supports kernel and QEMU hypervisor • Object storage – RESTful APIs interfaces compatible with S 3 and Swift • Filesystem – POSIX compliant file systems
Stores data as objects in the file system Which are stored on an object storage device Ceph nodes run on commodity hardware and Ceph storage cluster accommodate large number of nodes • Nodes based on RADOS • • – Librados, Radosgw, RBD, Ceph. FS
• Placement depends on – Ownership/access – Number of placement groups – CRUSH ruleset – Uses the CRUSH algorithm to • Allows user to specify on same/different rack, etc.