The MultiLayer Perceptron nonlinear modelling by adaptive preprocessing

The Multi-Layer Perceptron non-linear modelling by adaptive pre-processing Rob Harrison AC&SE

target, z error, e pre-processing layer adaptive layer output, y input data, x

Adaptive Basis Functions • “linear” models – fixed pre-processing – parameters → cost “benign” – easy to optimize but – combinatorial – arbitrary choices what is best pre-processor to choose?

The Multi-Layer Perceptron • formulated from loose biological principles • popularized mid 1980 s – Rumelhart, Hinton & Williams 1986 • Werbos 1974, Ho 1964 • “learn” pre-processing stage from data • layered, feed-forward structure – sigmoidal pre-processing – task-specific output non-linear model

Generic MLP O U T P U T I N P U T L A Y E R HIDDEN LAYERS L A Y E R

Two-Layer MLP

A Sigmoidal Unit

Combinations of Sigmoids

In 2 -D from Pattern Classification, 2 e, by Duda, Hart & Stork, © 2001 John Wiley

Universal Approximation • linear combination of “enough” sigmoids – Cybenko, 1990 • single hidden layer adequate – more may be better • choose hidden parameters (w, b) optimally problem solved?

Pros • compactness – potential to obtain same veracity with much smaller model • c. f. sparsity/complexity control in linear models

Compactness of Model

& Cons • parameter → cost “malign” – optimization difficult – many solutions possible – effect of hidden weights in output non-linear

Multi-Modal Cost Surface gradient? global min local min
 – analytically intractable • step")
Heading Downhill • assume – minimization (e. g. SSE) – analytically intractable • step parameters downhill • wnew = wold + step in right direction • backpropagation (of error) – slow but efficient • conjugate gradients, Levenburg/Marquardt – for preference
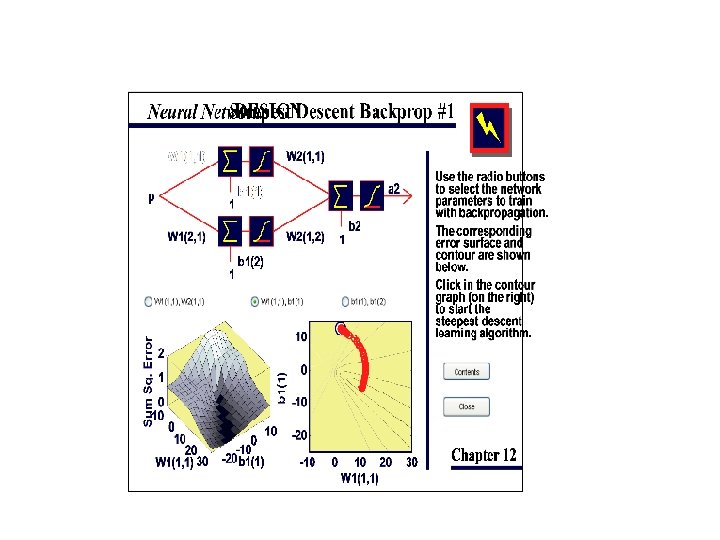
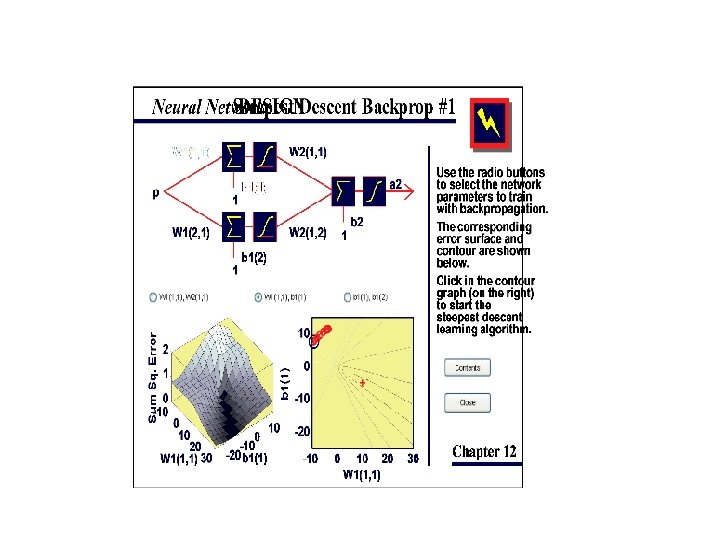

backprop conjugate gradients

Implications • correct structure can get “wrong” answer – dependency on initial conditions – might be good enough • train / test (cross-validation) required – is poor behaviour due to • network structure? • ICs? additional dimension in development

Is It a Problem? • pros seem to outweigh cons • good solutions often arrived at quickly • all previous issues apply – sample density – sample distribution – lack of prior knowledge

How to Use • to “generalize” a GLM – linear regression – curve-fitting • linear output + SSE – logistic regression – classification • logistic output + cross-entropy (deviance) • extend to multinomial, ordinal – e. g. softmax outptut + cross entropy – Poisson regression – count data

What is Learned? • the right thing – in a maximum likelihood sense theoretical • conditional mean of target data, E(z|x) – implies probability of class membership for classification P(Ci|x) estimated • if good estimate then y → E(z|x)

Simple 1 -D Function

More Complex 1 -D Example

Local Solutions

A Dichotomy data courtesy B Ripley

Class-Conditional Probabilities
 = P(C 2|x)")
Linear Decision Boundary induced by P(C 1|x) = P(C 2|x)

Class-Conditional Probabilities

Non-Linear Decision Boundary

Class-Conditional Probabilities

Over-fitted Decision Boundary

Invariances • e. g. scale, rotation, translation • augment training data • design regularizer – tangent propagation (Simmard et al, 1992) • build into MLP structure – convolutional networks (Le. Cun et al, 1989)

Multi-Modal Outputs • assumed distribution of outputs unimodal • sometimes not – e. g. inverse robot kinematics • E(z|x) not unique • use mixture model for output density • Mixture Density Networks (Bishop, 1996)
 • can use MLP as")
Bayesian MLPs • deterministic treatment • point estimates, E(z|x) • can use MLP as estimator in a Bayesian treatment – non-linearity → approximate solutions • approximate estimate of spread E((z-y)2|x)

NETTalk • • Introduced by T Sejnowski & C Rosenberg First realistic ANNs demo English text-to-speech non-phonetic Context sensitive – brave, gave, save, have (within word) – read, read (within sentence) • Mimicked DECTalk (rule-based)
 – 29 binary inputs")
Representing Text • 29 “letters” (a–z + space, comma, stop) – 29 binary inputs indicating letter • Context – local (within word) – global (sentence) • 7 letters at a time: middle → AFs – 3 each side give context, e. g. boundaries

Coding

NETTalk Performance • 1024 words continuous, informal speech • 1000 most common words • Best performing MLP • 26 o/p, 7 x 29 i/p, 80 hidden • 309 units, 18, 320 weights • 94% training accuracy • 85% testing accuracy
- Slides: 39