The CIPRES Science Gateway Enabling HighImpact Science for

The CIPRES Science Gateway: Enabling High-Impact Science for Phylogenetics Researchers with Limited Resources Mark Miller, Wayne Pfeiffer, and Terri Schwartz San Diego Supercomputer Center

Phylogenetics is the study of the diversification of life on the planet Earth, both past and present, and the relationships among living things through time ?

Evolutionary relationships can be inferred from DNA sequence comparisons: 1. Align sequences to determine evolutionary equivalence: 2. Infer evolutionary relationships based on some set of assumptions:

Inferring Evolutionary relationships from DNA sequence comparisons is powerful: DNA sequences are determined by fully automated procedures. Sequence data can be gathered from many species at scales from gene to whole genome. The high speed and low cost of Nex. Gen Sequencing means new levels of sensitivity and resolution can be obtained. The speed of sequencing is still increasing, while the cost of sequencing is decreasing.

Inferring Evolutionary relationships from DNA sequence comparisons is powerful, BUT: Current analyses often involve 1000’s of species and 1000’s of characters, creating very large matrices. Sequence alignment and Tree inference are NP hard; even with heuristics, computational power often limits the analyses (already). The length of tree search analysis scales exponentially with number of taxa and with number of characters with codes in current use. There at least 107 species, each with 3000 - 30, 000 genes, so the need for computational power and new approaches will continue to grow.

Inferring Evolutionary relationships from DNA sequence comparisons is powerful, BUT: Current analyses often involve 1000’s of species and 1000’s of characters, creating very large matrices. Sequence alignment and Tree inference are NP hard; even with heuristics, computational power often limits the analyses (already). The length of tree search analysis scales exponentially with number of taxa and with number of characters with codes in current use. There at least 107 species, each with 3000 - 30, 000 genes, so the need for computational power and new approaches will continue to grow.

Inferring Evolutionary relationships from DNA sequence comparisons is powerful, BUT: Current analyses often involve 1000’s of species and 1000’s of characters, creating very large matrices. Sequence alignment and Tree inference are NP hard; even with heuristics, computational power often limits the analyses (already). The length of tree search analysis scales exponentially with number of taxa and with number of characters with codes in current use. There at least 107 species, each with 3000 - 30, 000 genes, so the need for computational power and new approaches will continue to grow.

Inferring Evolutionary relationships from DNA sequence comparisons is powerful, BUT: Current analyses often involve 1000’s of species and 1000’s of characters, creating very large matrices. Sequence alignment and Tree inference are NP hard; even with heuristics, computational power often limits the analyses (already). The length of tree search analysis scales exponentially with number of taxa and with number of characters with codes in current use. There at least 107 species, each with 3000 - 30, 000 genes, so the need for computational power and new approaches will continue to grow.

Inferring Evolutionary relationships from DNA sequence comparisons is powerful, BUT: Current analyses often involve 1000’s of species and 1000’s of characters, creating very large matrices. Sequence alignment and Tree inference are NP hard; even with heuristics, computational power often limits the analyses (already). The length of tree search analysis scales exponentially with number of taxa and with number of characters with codes in current use. There at least 107 species, each with 3000 - 30, 000 genes, so the need for computational power and new approaches will continue to grow.

In this new, DNA sequence-rich world, laptops and desktops are no longer adequate for phylogenetic analysis….

The CIPRES Portal was created to allow users to analyze large sequence data sets using popular community codes on a significant computational resource. The CIPRES Portal provided: • Login-protected personal user space for storing results indefinitely. • Access to most/all native command line options for each code. • Support for adding new tools and new versions as needed.

The CIPRES Portal was created to allow users to analyze large sequence data sets using popular community codes on a significant computational resource. The CIPRES Portal provided: • Login-protected personal user space for storing results indefinitely. • Access to most/all native command line options for each code. • Support for adding new tools and new versions as needed.

The CIPRES Portal was created to allow users to analyze large sequence data sets using popular community codes on a significant computational resource. The CIPRES Portal provided: • Login-protected personal user space for storing results indefinitely. • Access to most/all native command line options for each code. • Support for adding new tools and new versions as needed.

The CIPRES Portal was created to allow users to analyze large sequence data sets using popular community codes on a significant computational resource. The CIPRES Portal provided: • Login-protected personal user space for storing results indefinitely. • Access to most/all native command line options for each code. • Support for adding new tools and new versions as needed.

Workflow for the CIPRES Portal: CIPRES Portal Assemble Sequences Upload to Portal Store Run Alignment Run Tree Inference Post-Tree Analysis Download

Limitations of the original CIPRES Portal • all jobs were run serially (efficient, but no gain in wall time) • the cluster was modest (16 X 8 -way dual core nodes) • runs were limited to 72 hours • the cluster was at the end of its useful lifetime • funding for the project was ending • demand for job runs was increasing

The solution: make parallel versions of community codes available on scalable, sustainable resources via the Science Gateway Program CIPRES Cluster Workbench Framework

The solution: make parallel versions of community codes available on scalable, sustainable resources via the Science Gateway Program Tera. Grid/XSEDE Parallel codes Workbench Framework Serial codes Triton

Greater than 90% of all computational time was used for three tree inference codes: Mr. Bayes, RAx. ML, and GARLI. Deploy parallel versions of these codes on Tera. Grid Machines; initially using Globus/GRAM. Work with community developers to improve the speed-up available through the parallel codes offered by CSG. Add new parallel codes (e. g. MAFFT) as they appear in the community. Keep other serial codes on local SDSC resources that provide the project with fee-for-service cycles.

Parallel code profiles on Trestles 19 X 36 X

Use of the New Gateway exceeded all expectations…. ? !?

Use of the New Gateway exceeded all expectations…. ? !? Initial allocation

Use of the New Gateway exceeded all expectations…. ? !? The initial allocation was greater than the capacity of the original cluster! Initial allocation

Given the high level of consumption, how to make sure Resource Usage is efficient?

Job Attrition on the CIPRES Science Gateway* *March – August 2010

Error Impact analysis

Prevent Job Loss When Contact with the Resource is Lost To make the system robust to system outages, jobs in the DB are tracked in a “running jobs table. ” When a job completes, results are transferred to the DB, and the job is marked complete. Every 24 hours, a daemon looks for results for jobs that are incomplete, any results found are transferred to the DB, and the job is marked as complete. If there is a service interruption while the job is running, the job results will still be automatically delivered to the user.

Monitor Submissions/Usage to Track Efficiency Usage 12/2009 – 4/2012

SU/job increases Usage 12/2009 – 4/2012
 fail when Lustre file system is under load")
• Mr. Bayes jobs (20%) fail when Lustre file system is under load • Long running jobs fail even when there is no other traffic on the system. Users immediately resubmit, driving SU use up. • The failure is due to resource contention in the Lustre file system • As a result, the code cannot write output files, and jobs fail • Moving to a mounted ZFS system eliminated the problem

Move off Lustre Usage 12/2009 – 4/2012

With such high consumption, we must track usage by individuals* SUs % of Users % total SU 0 – 30 K 97 45 30 – 300, 000 K 3 55 *Reporting Period: Sept, 2010 – May, 2011

With such high consumption, we must track usage by individuals* SUs % of Users % total SU 0 – 30 K 97 45 30 – 300 K 3 55 *Reporting Period: Sept, 2010 – May, 2011 We need to monitor individual users, because we want all XSEDE users to be subject to the same level of peer review.

Establish a Fair Use Policy • Anyone, anywhere can sign up for an account. An account is not required to submit a job. • Users at US institutions are permitted to use 50, 000 SUs from the community allocation annually. • Users at institutions in other countries can use up to 30, 000 SUs annually. • Users can apply for a personal XSEDE allocation if they require more SUs.

Tools required to implement the CIPRES SG Fair Use Policy: • ability to halt submissions from a given user account • ability to monitor usage by each account automatically • ability for users to track their SU consumption • ability to forecast SU cost of a job for users • ability to charge to a user’s personal XSEDE allocation

Tools required to implement the CIPRES SG Fair Use Policy: • ability to halt submissions from a given user account • ability to monitor usage by each account automatically • ability for users to track their SU consumption • ability to forecast SU cost of a job for users • ability to charge to a user’s personal XSEDE allocation

Tools required to implement the CIPRES SG Fair Use Policy: • ability to halt submissions from a given user account • ability to monitor usage by each account automatically • ability for users to track their SU consumption • ability to forecast SU cost of a job for users • ability to charge to a user’s personal XSEDE allocation

XDB CDB job id, SU charge job id, user name Nightly usage reports Post to user’s work area User/management email notifications

Help users track their resource consumption: Notify users of their usage level

Tools required to implement the CIPRES SG Fair Use Policy: • ability to halt submissions from a given user account • ability to monitor usage by each account automatically • ability for users to track their SU consumption • ability of users to forecast SU cost of a job • ability to charge to a user’s personal XSEDE allocation

Create a conditional “warning” element in the interface XML

Tools required to implement the CIPRES SG Fair Use Policy: • ability to halt submissions from a given user account • ability to monitor usage by each account automatically • ability for users to track their SU consumption • ability to forecast SU cost of a job for users • ability to charge to a user’s personal XSEDE allocation

Steps required to use a personal allocation: • User receives personal allocation from XRAC • PI of allocation adds “cipres” user to their account • CSG staff changes the user profile to charge to the personal allocation account id

Steps required to use a personal allocation: • User receives personal allocation from XRAC • PI of allocation adds “cipres” user to their account • CSG staff changes the user profile to charge to the personal allocation account id 3 users have completed this process

Impact of Policy on Usage Dec 2009 – April 2012 When Lustre file system is not used, submissions and SU usage are linear. 29, 000 more SUs requested each month. Projected use for 2012 - 2013 is 13. 4 million SUs

Impact of Policy on Usage Dec 2009 – April 2012 12 more users submit 160 more jobs each month Growth in usage is driven by new users Feb J Apr Jun Aug Oct Dec Feb Apr

What works about Trestles: • The Trestles machine is managed to keep queue depth low. This is a key requirement for many of our users who run a lot of relatively short jobs, and for class instruction. • Run times of up to 334 hours are allowed. This is important because most of the CSG codes do not have restart capability and scalability is typically limited to 64 cores or less.

Impact on Scientific Productivity: Publications enabled by the CIPRES Science Gateway/CIPRES Portal: Year 2012* 2011 2010 2009 2008 Number 106 130 89 59 4 *As of June 1, 2012 Publications in the pipeline: : Status In preparation In review Number 91 25

Impact on Scientific Productivity: • In Q 1 2012, 29% of all XSEDE users who ran jobs ran them from the CSG • 50% of users said they had no access to local resources, nor funds to purchase access on cloud computing resources • Used for curriculum delivery by at least 68 instructors. • Jobs run for researchers in 23/29 EPSCOR states. • Routine submissions from Harvard, Berkeley, Stanford…. . • 76% of users are in the US or have a collaborator in the US

Impact on Scientific Productivity : “It is hard for me to imagine how I could work at a reasonable pace without this resource, especially when things like MS or grant submission deadlines loom…. ”

Impact on Education: “It is an easy-to-use cluster to run BEAST analyses in a short time. This allows students to run analyses that actually converge in a single class. ” “I found it is important to be able to let the student explore the analysis 'all the way', i. e. not just show the principle but actually let them run an entire Markov chain and let them evaluate the results. For that I found that having access to the CIPRES Science Gateway to be crucial. ”

Seven Success Strategies for Gateways: 1. Identify a user base that cannot do their work without HPC access 2. Focus on providing the key software elements users require 3. Provide scalable access to the best code versions available 4. Make efficient use of resources/user time/keystrokes 5. Provide easy access with adult supervision 6. Provide fast job turnaround on resources appropriate for the workflow 7. Relentless commitment to customer service

Seven Success Strategies for Gateways: 1. Identify a user base that cannot do their work without HPC access 2. Focus on providing the key software elements users require 3. Provide scalable access to the best code versions available 4. Make efficient use of resources/user time/keystrokes 5. Provide easy access with adult supervision 6. Provide fast job turnaround on resources appropriate for the workflow 7. Relentless commitment to customer service

Seven Success Strategies for Gateways: 1. Identify a user base that cannot do their work without HPC access 2. Focus on providing the key software elements users require 3. Provide scalable access to the best code versions available 4. Make efficient use of resources/user time/keystrokes 5. Provide easy access with adult supervision 6. Provide fast job turnaround on resources appropriate for the workflow 7. Relentless commitment to customer service

Seven Success Strategies for Gateways: 1. Identify a user base that cannot do their work without HPC access 2. Focus on providing the key software elements users require 3. Provide scalable access to the best code versions available 4. Make efficient use of resources/user time/keystrokes 5. Provide easy access with adult supervision 6. Provide fast job turnaround on resources appropriate for the workflow 7. Relentless commitment to customer service

Seven Success Strategies for Gateways: 1. Identify a user base that cannot do their work without HPC access 2. Focus on providing the key software elements users require 3. Provide scalable access to the best code versions available 4. Make efficient use of resources/user time/keystrokes 5. Provide easy access with adult supervision 6. Provide fast job turnaround on resources appropriate for the workflow 7. Relentless commitment to customer service

Seven Success Strategies for Gateways: 1. Identify a user base that cannot do their work without HPC access 2. Focus on providing the key software elements users require 3. Provide scalable access to the best code versions available 4. Make efficient use of resources/user time/keystrokes 5. Provide easy access with adult supervision 6. Provide fast job turnaround on resources appropriate for the workflow 7. Relentless commitment to customer service

Seven Success Strategies for Gateways: 1. Identify a user base that cannot do their work without HPC access 2. Focus on providing the key software elements users require 3. Provide scalable access to the best code versions available 4. Make efficient use of resources/user time/keystrokes 5. Provide easy access with adult supervision 6. Provide fast job turnaround on resources appropriate for the workflow 7. Relentless commitment to customer service

Seven Success Strategies for Gateways: 1. Identify a user base that cannot do their work without HPC access 2. Focus on providing the key software elements users require 3. Provide scalable access to the best code versions available 4. Make efficient use of resources/user time/keystrokes 5. Provide easy access with adult supervision 6. Provide fast job turnaround on resources appropriate for the workflow 7. Relentless commitment to customer service

Acknowledgements: CIPRES Science Gateway Terri Schwartz Hybrid Code Development Wayne Pfeiffer Alexandros Stamatakis XSEDE Implementation Support Nancy Wilkins-Diehr Doru Marcusiu Leo Carson XSEDE System Support Mahidhar Tatineni Rick Wagner Workbench Framework: ` Terri Schwartz Paul Hoover Lucie Chan Jeremy Carver


Next Steps: • Expand the accessibility of CIPRES functionalities by exposing Re. ST services. • Expand the number of parallel codes available. • Expand the number of computational resources available.

Next Steps: • Expand the accessibility of CIPRES functionalities by exposing Re. ST services. • Expand the number of parallel codes available. • Expand the number of computational resources available.

Next Steps: i. Plant as Prototype Partner for REST Services Data Base Access NGS Sequencing XSEDE Ancestral Character Estimation CSG Tree Reconciliation i. PDE Parallel codes i. PDB Taxonomic Name Resolution Phylogenetic Workflows

Next Steps: • Expand the accessibility of CIPRES functionalities by exposing Re. ST services. • Expand the number of parallel codes available. • Expand the number of computational resources available.

Next Steps: • Expand the accessibility of CIPRES functionalities by exposing Re. ST services. • Expand the number of parallel codes available. • Expand the number of computational resources available.

Workflow for the CIPRES Gateway: CIPRES Gateway Assemble Sequences Upload to Portal Store Run Alignment Run Tree Inference Post-Tree Analysis Download

Next Steps: REST Services will put CIPRES in many environments XSEDE CSG Parallel codes raxml. GUI

Next Steps: Expand the Number of Parallel Codes available • Mr. Bayes 3. 2: MPI Hybrid parallel code • Phylobayes: serial Parallel code • Ima/Ima 2: serial Parallel code • LAMARC: serial Parallel code

Next Steps: Expand the Resources for all users • At 10 million SUs, the CSG allocation amounts to only about 0. 7% of allocatable XSEDE resources.

Next Steps: Expand the Resources for all users • At 10 million SUs, the CSG allocation amounts to only about 0. 7% of allocatable XSEDE resources. • BUT……. .

Next Steps: Expand the Resources for all users Parallel Trestles CSG Serial Triton 10 million SUs on Trestles (2011/2012) = 16% of the allocatable Trestles Machine Projected growth to 21% of Trestles We need to expand to more machines!
 Gordon")
Next Steps: Expand the Resources for all users Parallel Stampede, Others Trestles (8%) Gordon (2%) CSG raxml. GUI Serial OSG

Next Steps: Expand the Resources for all users CSG raxml. GUI
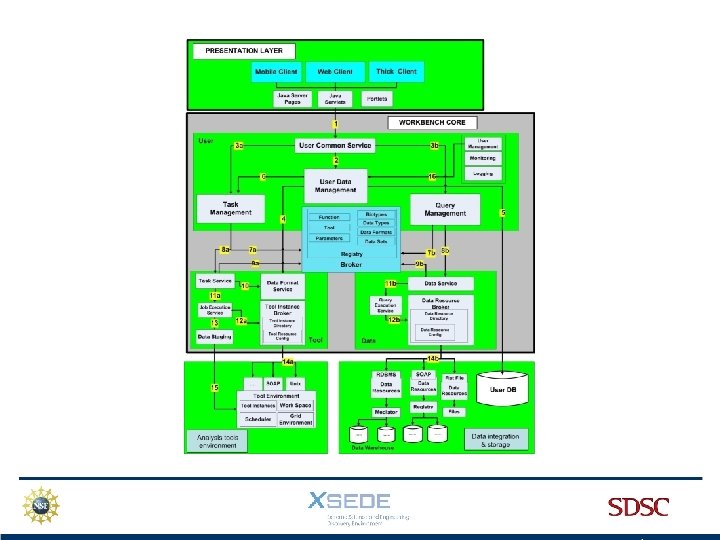

Presentation layer is based on Java Struts 2

Uses 2 Java classes to access the Core

We currently use only A web client
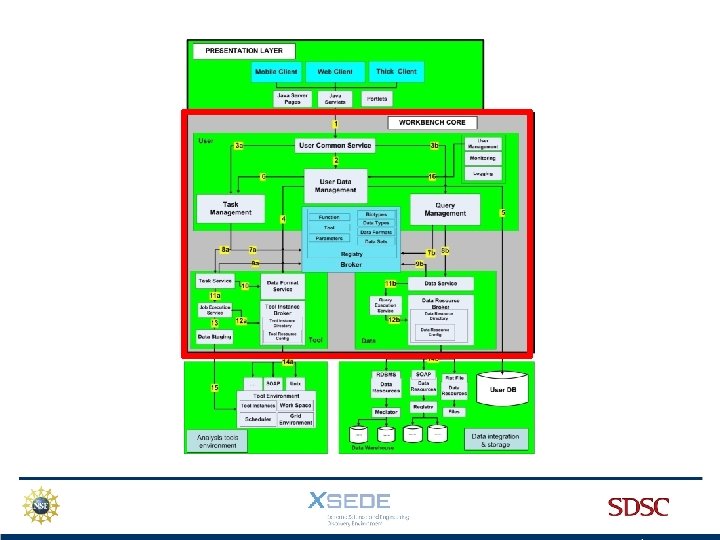
 deploys generic “tasks”….")
The Workbench Framework (Java) deploys generic “tasks”….

…. and queries generic DBs

Specific information is coded in a Central Registry

User information, data, and job runs are stored in a My. SQL database

Tasks and queries are sent to remote machines and DBs

An XML standard is used to create forms…. <? xml version="1. 0" encoding="ISO-8859 -1"? > <!DOCTYPE pise SYSTEM "http: //www. phylo. org/dev/rami/PARSER/pise. dtd"> <!-- the interface was modified by mamiller to accomodate submission of jobs to both trestles and abe --> <pise> <head> </head> <title>RAx. ML-HPC 2 on TG</title> <version>7. 2. 8</version> <description>Phylogenetic tree inference using maximum likelihood/rapid bootstrapping run on teragrid. (beta interface)</description> <authors>Alexandros Stamatakis</authors> <reference>Stamatakis A. RAx. ML-VI-HPC: maximum likelihood-based phylogenetic analyses with thousands of taxa and mixed models. Bioinformatics. 2006 Nov 1; 22(21): 2688 -90</reference> <category>Phylogeny / Alignment</category> <doclink>http: //icwww. epfl. ch/~stamatak/index-Dateien/count. Manual 7. 0. 0. php</doclink> <command>raxmlhpc 2_tgb</command> <parameters> <!-- Start -N < 50 --> <parameter ishidden="1" type="String"> <name>raxmlhpc_hybridlogic 2</name> <attributes> <format> <language>perl</language> <code>"raxml. HPC-HYBRID-7. 2. 8 -T 6"</code> </format> <precond> <!-- * If -N nnn is specified with nnn < 50, run the hybrid parallel version of RAx. ML on a single node of Trestles using

An XML standard is used to create forms…. <? xml version="1. 0" encoding="ISO-8859 -1"? > <!DOCTYPE pise SYSTEM "http: //www. phylo. org/dev/rami/PARSER/pise. dtd"> <!-- the interface was modified by mamiller to accomodate submission of jobs to both trestles and abe --> <pise> <head> </head> <title>RAx. ML-HPC 2 on TG</title> <version>7. 2. 8</version> <description>Phylogenetic tree inference using maximum likelihood/rapid bootstrapping run on teragrid. (beta interface)</description> <authors>Alexandros Stamatakis</authors> <reference>Stamatakis A. RAx. ML-VI-HPC: maximum likelihood-based phylogenetic analyses with thousands of taxa and mixed models. Bioinformatics. 2006 Nov 1; 22(21): 2688 -90</reference> <category>Phylogeny / Alignment</category> <doclink>http: //icwww. epfl. ch/~stamatak/index-Dateien/count. Manual 7. 0. 0. php</doclink> <command>raxmlhpc 2_tgb</command> <parameters> <!-- Start -N < 50 --> <parameter ishidden="1" type="String"> <name>raxmlhpc_hybridlogic 2</name> <attributes> <format> <language>perl</language> <code>"raxml. HPC-HYBRID-7. 2. 8 -T 6"</code> </format> <precond> <!-- * If -N nnn is specified with nnn < 50, run the hybrid parallel version of RAx. ML on a single node of Trestles using User-entered values are then rendered into command lines and delivered with input files to the compute resource file system….

LOCAL RESOURCE REMOTE RESOURCE GSISSH DRMAA GRAM My. SQL DB Remote Scheduler WF Tool Module Input Output Local File System PBS LSF SGE Local Scheduler Input Grid. FTP SFTP Output Remote File System

LOCAL RESOURCE Pluggable job submission and monitoring module distributes jobs to local and remote resources REMOTE RESOURCE GSISSH DRMAA GRAM My. SQL DB Remote Scheduler WF Tool Module Input Output Local File System PBS LSF SGE Local Scheduler Input Grid. FTP SFTP Output Remote File System
- Slides: 88