Testing and Verification Methods for ManyCore Concurrency Part



 Originally designed to accelerate graphics processing GPU has many parallel")
 All PEs share glob memory Many PEs Local memory Private")




 Used to synchronise threads When a thread reaches barrier() it waits")
")









; // A Run thread i from A")
; // A Run thread i from A to B Log")


 The encoding process turns a kernel K into a")








")




- Slides: 39
Testing and Verification Methods for Many-Core Concurrency Part 1: Verification of GPU kernels Halmstad Summer School on Testing, 2016 Alastair Donaldson, Imperial College London www. doc. ic. ac. uk/~afd
Many-core architectures
Agenda We will study two aspects of many-core software reliability: 1. Reliability of many-core programs 2. Reliability of many-core compilers I will provide an overview of two approaches my group has taken to verification and testing, addressing these problems: 1. Static verification of GPU kernels (GPUVerify) 2. Automated testing of many-core compilers Throughout I will give several demos, and I hope the tutorials can be interactive!
Graphics processing units (GPUs) Originally designed to accelerate graphics processing GPU has many parallel processing elements: graphics operations on sets of pixels are inherently parallel Early GPUs: limited functionality, tailored specifically towards graphics Recently GPUs have become more powerful and general purpose. Widely used in parallel programming to accelerate tasks including: Medical imaging Computational fluid dynamics Financial simulation Computer vision DNA sequence alignment …and many more
Graphics processing units (GPUs) All PEs share glob memory Many PEs Local memory Private memory Processing element (PE) Local memory PEs in same group share memory Local memory Global memory Organised into groups
GPU-accelerated systems Host PC copies data and code into GPU memory Code is a kernel function which is executed by each PE Host (multicore PC) GPU Invoke kernel Copy back results Host memory Copy data and kernel code
Data races in GPU kernels A data race occurs if: - two distinct threads access the same memory location - at least one of the accesses is a write - the accesses are not separated by a barrier synchronisation operation More on this later
Data races in GPU kernels Intra-group data race Inter-group data race Lead to all kinds of problems! Almost always accidental and unwanted: data races in GPU kernels are not usually benign
GPU kernel example Indicates that function is the kernel’s entry point Indicates that A is an array stored in group’s local memory kernel void add_neighbour(local int* A , int offset) { A[tid] = A[tid] + A[tid + offset]; } Read/write data race Built-in variable which contains thread’s id Syntax used here is (more or less) Open. CL, an industry standard for multicore computing All threads execute add_neighbour – host specifies how many threads should run
Barrier synchronisation barrier() Used to synchronise threads When a thread reaches barrier() it waits until all threads reach the barrier Note: all threads must reach the same barrier – illegal for threads to reach different barriers; this is barrier divergence When all threads have reached the barrier, the threads can proceed past the barrier Reads and writes before the barrier are guaranteed to have completed after the barrier
Using barrier to avoid a data race kernel void add_neighbour(local int* A, int offset) { int temp = A[tid + offset]; barrier(); Accesss cannot be A[tid] = A[tid] + temp; concurrent }
Barrier divergence
GPUVerify: a verifier for GPU kernels GPUVerify is a tool that analyses the source code of Open. CL and CUDA kernels, to check for: - Intra group data races - Inter group data races - Barrier divergence - Out-of-bounds array accesses - Violations of user-specified assertions
Demo! Let’s write some Open. CL, see some problems, and see whether GPUVerify can help (Live coding demo)
Verification technique We will now look at how GPUVerify works Essential idea: Transform massively parallel kernel K into a sequential program P such that correctness of P implies race- and divergence-freedom of K
Focussing data race analysis All threads are always executing in a region between two barriers: . . . barrier(); Barrier-free code region barrier(); . . . Race may be due to two threads executing statements within the region We cannot have a race caused by a statement in the region and a statement outside the region Data race analysis can be localised to focus on regions between barriers
Reducing thread schedules With n threads, roughly how many possible thread schedules are there between these barriers, assuming each statement is atomic? barrier(); S 1; S 2; . . . Sk barrier(); etc.
Reducing thread schedules Do we really need to consider all of these schedules to detect data races? No: actually is suffices to consider just one schedule, and it can be any schedule
Any schedule will do! For example: If data race exists it will be detected: abort No data races: chosen schedule equivalent to all others barrier(); // A Run thread 0 from A to B Log all accesses Run thread 1 from A to B Log all accesses Check against thread 0 Run thread 2 from A to B Log all accesses Check against threads 0 and 1. . . Abort on race Run thread N-1 from A to B Log all accesses Check against threads 0. . N-2 barrier(); // B Completely avoids reasoning about interleavings!
Reducing thread schedules This is good: it means we are back in the world of sequential program analysis But in practice it is quite normal for a GPU kernel to be executed by e. g. 1024 threads Leads to an intractably large sequential program Can we do better?
Yes: just two threads will do! barrier(); // A Run thread i from A to B Log all accesses Run thread j from A to B Check all accesses against thread i Abort on race barrier(); // B If data race exists it will be exposed for some choice of i and j. If we can prove data race freedom for arbitrary i and j then the region must be data race free
Is this sound? barrier(); // A Run thread i from A to B Log all accesses Run thread j from A to B Check all accesses against thread i Abort on race barrier(); // B Run thread i from B to C Log all accesses Run thread j from B to C Check all accesses against thread i Abort on race barrier(); // C No: it is as if only i and j exist, and other threads have no effect! Solution: make shared state abstract - simple idea: havoc the shared state at each barrier - even simpler: remove shared state completely
GPUVerify technique and tool Exploit: any schedule will do + two threads will do + shared state abstraction to compile massively parallel kernel K into sequential program P such that (roughly): P correct (no assertion failures) => K free from data races
Demo: encoding an Open. CL kernel into Boogie I will give intuition for how GPUVerify works under the hood by translating a simple kernel into the Boogie intermediate language, applying the two-thread abstraction.
Main theorem (formalised in papers) The encoding process turns a kernel K into a sequential program P such that we almost have: P is correct => K is free from data races and barrier divergence Actually we have something weaker: P is correct => Exercise: why? All terminating executions of K are free from data races and barrier divergence Another exercise: we might have P incorrect, but all terminating executions of K free from data races and barrier divergence. Why?
Lessons learned from the GPUVerify project We have learned a few things about building domainspecific analysis tools that I believe could be more generally relevant.
Lesson 1: Target a tractable problem GPUVerify analyzes GPU kernels not arbitrary C programs We exploit the simplicity of the GPU programming model GPUVerify aims to verify race-freedom not full functional correctness No specifications required We can focus on optimizing race checking
Lesson 1: Target a tractable problem Verification community: Small dent in intractably hard problem Intractably hard problem vs. Small dent in small, but practical problem Partially solved practical problem To get software verification in widespread use we need to solve some simple problems really well
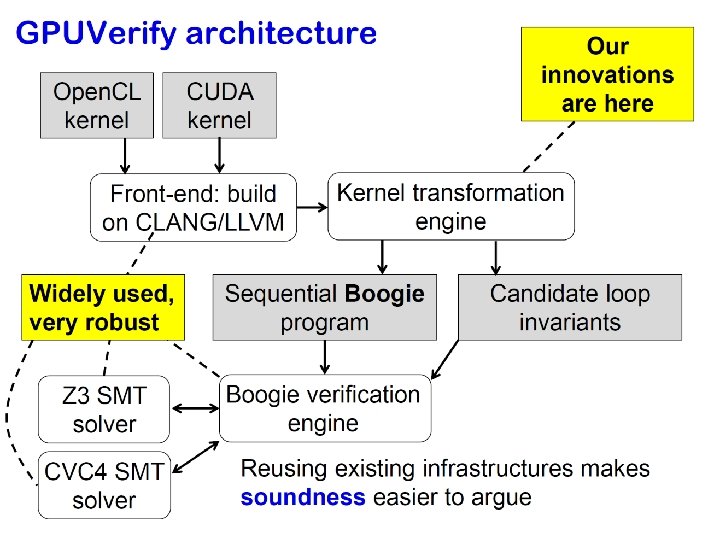
Lesson 2: Reuse infrastructure Open. CL kernel Front-end: built on CLANG/LLVM Widely used, very robust Z 3 SMT solver Our contributions are here CUDA kernel Kernel transformation engine Sequential Boogie program Candidate loop invariants Boogie verification engine Reusing existing infrastructures saved huge effort and made soundness much easier to argue
Lesson 3: Evolve front-end capabilities The front-end dilemma: “I have a cool idea for verifying language X …but I don’t have a front-end for X” “If the idea works, I want to evaluate it on hundreds of X programs …I can’t do that without an X front-end” “Designing a proper X front-end will take months …I don’t want to do that if my idea doesn’t work out!”
Lesson 3: Evolve front-end capabilities Our approach during the GPUVerify project August 2012 – November 2012 Hand-code GPU kernels in Boogie December 2012 – April 2013 Clang-based front-end for simple language subset May 2013 – present LLVM-to-Boogie translator, with comprehensive Open. CL and CUDA environment modelling
Lesson 4: Beware of outliers We evaluated four new optimizations to GPUVerify – O 1, O 2, O 3, O 4 – across 492 benchmarks Speedup over baseline Optimizations Best Worst Median Mean 0. 5 x 1. 0 x 1. 2 x 16 x O 1 0. 6 x 1. 0 x 1. 3 x 19 x O 1+O 2 0. 6 x 1. 1 x 1. 8 x 77 x O 1+O 2+O 3 0. 5 x 1. 1 x 2. 5 x O 1+O 2+O 3+O 4 87 x SMT solver: Z 3
Lesson 4: Beware of outliers We then tried the CVC 4 solver: Speedup over baseline Best Worst Median Mean Optimizations 0. 1 x 1. 2 x 1. 3 x 4 x O 1 0. 1 x 1. 3 x 4 x O 1+O 2 0. 1 x 1. 4 x 17 x O 1+O 2+O 3 0. 3 x 1. 2 x 1. 5 x O 1+O 2+O 3+O 4 17 x
CVC 4 vs Z 3 (all GPUVerify optimizations enabled)
Lesson 4: Beware of outliers Hard to draw conclusions about effectiveness of optimizations without a large set of benchmarks Hard to separate benefits of an optimization from quirks of a solver Verification tool evaluations require good benchmark sets SMT-based tools should report results for multiple solvers
Summary n n n GPU software is prone to data races and barrier divergence GPUVerify is our static analysis solution to this problem Key ideas: two-thread abstraction, translation to Boogie intermediate representation, SMT solving using Z 3/CVC 4
Open problems include: n n Functional verification Reasoning about floating-point (needed for many functional properties) Reasoning about fine-grained concurrency and weak memory Verification of integrated applications (GPUVerify focusses on just one kernel at a time)
Key papers Papers on GPUVerify include: n n n Alastair F. Donaldson. “The GPUVerify Method: a Tutorial Overview”. AVo. CS 2014. Adam Betts, Nathan Chong, Alastair F. Donaldson, Jeroen Ketema, Shaz Qadeer, Paul Thomson, John Wickerson. “The Design and Implementation of a Verification Technique for GPU Kernels”. ACM Transactions on Programming Languages and Systems, 2015. Ethel Bardsley, Adam Betts, Nathan Chong, Peter Collingbourne, Pantazis Deligiannis, Alastair F. Donaldson, Jeroen Ketema, Daniel Liew, Shaz Qadeer. “Engineering a Static Verification Tool for GPU Kernels”. CAV, 2014. Other papers on program analysis for GPU kernels include: n n n Stefan Blom, Marieke Huisman, Matej Mihelcic. “Specification and Verification of GPGPU Programs”. Science of Computer Programming, 2014. Guodong Li, Peng Li, Geoffrey Sawaya, Ganesh Gopalakrishnan, Indradeep Ghosh, Sreeranga P. Rajan. “GKLEE: Concolic Verification and Test Generation for GPUs”. PPo. PP, 2012. Alan Leung, Manish Gupta, Yuvraj Agarwal, Rajesh Gupta, Ranjit Jhala, Sorin Lerner. “Verifying GPU Kernels by Test Amplification”. PLDI, 2012.