Teste de Hiptese Noes de Estatstica Descritiva Profa


















 é o conjunto de valores assumidos pela variável")



 mais comumente utilizados são 10%")



 • O grau de liberdade é igual ao número")
 4. Fixar o nível de significância do teste para")



- Slides: 34
Teste de Hipótese Noções de Estatística Descritiva Profa. Mariela I. Cortés 2019
Hipóteses • Uma hipótese é uma teoria ou suposição que pode explicar um determinado comportamento de interesse da pesquisa. – Um estudo experimental tem como objetivo colher dados, em um ambiente controlado, para confirmar ou rejeitar a hipótese.
Formulação de Hipóteses • As hipóteses devem ser formalmente descritas. • Os dados coletados durante a execução do estudo devem ser utilizados para colocar as hipóteses à prova. • Declaração de hipóteses: – Hipótese nula: deve ser rejeitada (refutada), caso contrário, afirma que não há tendência ou padrão real nos dados coletados pelo estudo experimental, e razões para diferenças na observação são apenas coincidências. – Hipótese alternativa: é a hipótese que pode ser colocada a prova quando a hipótese nula é rejeitada. • A verificação das hipóteses lida com risco de erro que possa acontecer na análise (Tipo I e Tipo II). – Rejeitar hipótese verdadeira – Aceitar hipótese falsa
Hipóteses e Variáveis • Hipóteses devem levar à definição de variáveis. • Variáveis independentes (ou fatores). – Referem-se à entrada do processo de experimentação, podendo ser controladas durante este processo. – Representam a causa que afeta o resultado do processo de experimentação (variáreis dependentes). Quando é possível seu controle, i. e. , os valores podem ser alterados, são chamados de "tratamentos“. • Variáveis dependentes. – Referem-se à saída do processo de experimentação, sendo afetadas pelo tratamento. – Representam o efeito da combinação dos valores das variáveis independentes (incluindo os fatores). Seus possíveis valores são chamados de "resultados“.
Variáveis e seus Valores • As variáveis de um estudo podem ser: – Qualitativas: os tratamentos representam tipos. – Quantitativas: os tratamentos representam níveis de aplicação da variável. • Os valores das variáveis são coletados em escalas: – Existem diversas escalas para coleta e representação de valores: nominal, ordinal, intervalar e razão. – As escalas determinam as operações que podem ser aplicadas sobre os valores das variáveis.
Valores e Escalas
Hipóteses, Variáveis e Escalas “Utilizando a técnica Y os desenvolvedores concluem a atividade de análise de requisitos em menos tempo e com um conjunto de requisitos mais completo do que utilizando a técnica X”. – Variáveis Independentes: • Técnica utilizada (tratamentos: Y e X) >> Escala nominal com dois tratamentos. • Caracterização do desenvolvedor e Caracterização da aplicação >> Escala nominal ou ordinal. – Variáveis Dependentes: • Tempo de execução da atividade >> Escala razão. • % de requisitos corretos encontrados >> Escala razão.
Estatística Descritiva • A estatística descritiva é utilizada para descrever características relevantes dos dados coletados. • Junto com a análise gráfica (diagramas), a estatística descritiva apoia a análise inicial dos dados, medindo as dependências e relacionamentos entre eles. • A estatística descritiva tem como meta passar uma visão geral de como o conjunto de dados está distribuído.
Medidas de Tendência Central Indicam “o meio” do conjunto de valores observados. • Média (aritmética): a média (µ) pode ser considerada como o centro de gravidade dos dados coletados. É calculada pelo somatório dos valores coletados, dividido pela quantidade de valores. • Mediana: valor que se encontra no meio de um conjunto de dados, ou seja, o número de valores coletados que está abaixo da mediana deve ser o mesmo que está acima. É calculada colocando os valores em ordem crescente ou decrescente e selecionando o elemento central. Em caso de número par de valores é calculada a média dos valores centrais. • Moda: representa o valor mais comum dentre o conjunto de valores coletados. É calculada pela contagem do número de ocorrências (frequência) de cada valor, selecionando o mais comum. Se dois ou mais valores ocorrem com maior frequência, os valores coletados possuem diversas modas. • Outras medidas de tendência: valor mínimo e máximo, percentil, quartil.
Medidas de Dispersão • Medem o quanto os valores coletados estão dispersos ou concentrados em torno de seu valor central. – Faixa: é a diferença entre o valor máximo e o valor mínimo dos valores coletados. – Variância (σ2): é a soma do quadrado da diferença entre cada valor e a média dos valores coletados, dividida pelo número de valores coletados menos 1. – Desvio Padrão (σ): é a raiz quadrada da variância, sendo a medida de dispersão mais comumente utilizada.
Distribuições de Frequência • Um conjunto de dados pode ser mapeado no domínio da frequência e apresentado na forma de histogramas. • Os histogramas permitem verificar se a distribuição dos dados segue uma distribuição clássica, como normal, uniforme, beta, entre outras. A distribuição normal, em particular, é importante para alguns testes estatísticos que exigem que os dados que serão analisados sigam uma distribuição normal.
Distribuições de Frequência A distribuição normal possui o formato de um sino, com as pontas se estendendo a direita e esquerda do centro. – A curva é simétrica em relação a sua média e a largura do sino é proporcional ao seu desvio padrão. – Assim, a curva pode ser descrita matematicamente apenas com base em sua média e variância ~N(µ, σ2).
Propriedades da Distribuição Normal • Se um conjunto de dados numéricos segue a distribuição normal, é possível afirmar que: – A área total sob a curva é igual a 1, e frequência total 100%. – 68% de todas as observações estão entre 1 desvio padrão a mais ou a menos da média. – 95, 5% de todas as observações estão entre 2 desvios padrão a mais ou a menos da média. – 99, 7% de todas as observações estão entre 3 desvios padrão a mais ou a menos da média.
Teste de Normalidade • Em estatística, os testes de normalidade são usados para determinar se um conjunto de dados de uma dada variável aleatória, é bem modelada por uma distribuição normal ou não, ou para calcular a probabilidade da variável aleatória subjacente estar normalmente distribuída. Exemplos de testes: D'Agostino's K-squared test Jarque-Bera test Anderson-Darling test Cramér-von-Mises criterion Lilliefors test for normality (que é uma adaptação do teste Kolmogorov-Smirnov) Shapiro-Wilk test Pearson's chi-square test Shapiro-Francia test for normality Métodos empíricos e gráficos (histograma)
Normalidade
Testes de Hipótese • Um estudo experimental tem como objetivo colher dados para confirmar ou rejeitar uma hipótese. • Em geral, são definidas duas hipóteses. – Hipótese nula (H 0): indica que não existe um relacionamento estatístico significativo em um dado conjunto de parâmetros. É a hipótese que o analista deseja rejeitar com a maior significância possível. A rejeição da hipótese nula em favor da alternativa implica que existe um relacionamento entre os dados observados. – Hipótese alternativa (H 1): é a hipótese inversa à hipótese nula, que será aceita caso a hipótese nula seja rejeitada. • Os testes estatísticos verificam se é possível rejeitar a hipótese nula em favor da alternativa, de acordo com um conjunto de dados observados (amostra) e suas propriedades estatísticas.
Exemplo 1 – Resistência Pinos Considere a compra de pinos de uma empresa cuja resistência média à ruptura é especificada em 60 kgf. A equipe técnica deseja verificar se um determinado lote atende às especificações. H 0: O lote atende as especificações H 1: O lote não atende as especificações Seja a variável aleatória X (resistência à ruptura) X ~N(µ= 60, σ2 = 25), tal que: H 0: µ = 60 H 1: µ ≠ 60 Suponha que a equipe técnica da indústria tenha decidido retirar uma amostra aleatória de tamanho n= 16, do lote recebido, medir a resistência de cada pino e calcular a resistência média da amostra. Se o lote está fora de especificação espera-se que a média amostral seja diferente (inferior ou superior) de 60 kgf.
Exemplo 1 – Resistência Pinos Suponha que equipe técnica da empresa tenha decidido adotar a seguinte regra: rejeitar Ho se for maior que 62. 5 kgf e ou menor que 57. 5 kgf.
Região Crítica Definição: Região crítica (Rc) é o conjunto de valores assumidos pela variável aleatória ou estatística de teste para os quais a hipótese nula é rejeitada. Porém sempre que trabalhamos com amostras (e não com a população completa) existem riscos de erro, ou seja de chegar numa conclusão errada!
Tipos de Erro no Teste de Hipóteses • Type-I-error: ocorre quando um teste estatístico indica um padrão ou relacionamento entre causa e efeito, que não existe. • Rejeitar H 0 quando de fato H 0 é verdadeira (Falso positivo*). • Type-II-error: ocorre quando um teste estatístico não indica um padrão ou relacionamento entre causa e efeito, mas o relacionamento existe. • Não rejeitar H 0 quando de fato H 0 é falsa (Falso negativo)
Tipos de Erro • Considere: – H 0: O lote atende as especificações (aceita lote). – H 1: O lote não atende as especificações (não aceita lote). • Erros a partir dos dados amostrais: – Tipo I: Não aceitar o lote sendo que está dentro das especificações. – Tipo II: Aceitar o lote sendo que está fora das – especificações. Qual a probabilidade desses erros acontecer?
Probabilidade de Erro α é chamado de nível de significância e indica a probabilidade de cometer um erro Tipo-I, ou seja rejeitar a H 0 quando é verdadeira.
Nível de Significância • Os níveis de significância (α) mais comumente utilizados são 10% (0, 1), 5% (0, 05), 1% (0, 01) e 0. 1% (0, 001), dependendo do problema. • Chamamos de p-value o menor nível de significância (limite) obtido a partir da amostra, com que se pode rejeitar a hipótese nula. • Dizemos que há significância estatística quando o pvalue é menor que o nível de significância adotado. – Por exemplo, quando p=0. 0001 pode-se dizer que o resultado é bastante significativo, pois este valor é muito inferior aos níveis de significância usuais. – Porém, se p=0. 048 pode haver dúvida pois, embora o valor seja inferior, ele está muito próximo ao nível usual de 5%.
Interpretando a significância dos resultados • Procedimento: 1. Formular as hipóteses. 2. Selecionar o teste estatístico adequado (usado para estimar do parâmetro que está sendo testado). 3. Usando as informações amostrais, aplicar o teste estatístico (2) selecionado para obter o valor da estatística (estimativa do parâmetro) e o p-value. 4. Fixar o nível de significância do teste para o caso. 5. A partir do nível de significância determinar a região crítica (limite tolerado para rejeitar a hipótese nula). 6. Se valor da estatística pertencer à região crítica ou p-value for menor que o nível de significância adotado, rejeita-se a hipótese nula, aceitando-se a hipótese alternativa. 7. Caso contrário (não se rejeita a hipótese nula), ou seja nada pode se dizer a respeito da hipótese alternativa.
Exemplo módulos software O número de módulos em 15 sistemas de software são mostrados na tabela a seguir. Queremos concluir que em média, o número de módulos na amostra que foi derivada é diferente de 12.
Exemplo módulos software 1. Formular as hipóteses. 2. Selecionar o teste estatístico adequado. No exemplo preciso determinar se a média da amostra é igual ou diferente de um valor hipotético. No caso os dados possuem uma distribuição normal. Portanto posso aplicar o t-test. 3. Obter o valor da estatística (estimativa do parâmetro) e o p-value. Para isso preciso calcular a média da amostra (19. 933) e o desvio padrão (8. 172). Para uma amostra t-test, o valor de t é calculado:
Exemplo módulos software (cont. ) • O grau de liberdade é igual ao número de variáveis -1, portanto 15 (softwares) – 1 = 14. P-value = 0. 002 • t = 3. 76.
Exemplo módulos software (cont. ) 4. Fixar o nível de significância do teste para o caso. Definimos o limite ou α value < 0. 01 (limite para a probabilidade de erro de tipo 1). 5. Derivar conclusões. O p-value obtido de 0, 002 é significativamente menor que o α value 0, 01, a hipótese nula pode ser rejeitada, em favor da alternativa e portanto concluímos que a quantidade média de módulos do software é diferente de 12 (com significância estatística). • Um p-value muito baixo significa que a probabilidade de obter um valor da estatística de teste como o observado (no caso quantidade de módulos =12) é muito improvável, levando à rejeição da hipótese nula.
Tipos de Estudo Experimental • A escolha pelo tipo de teste para avaliar a hipótese nula depende de diversos fatores, entre eles: – Tipo de distribuição. – Tamanho da amostra. – Quantidade de variáveis independentes. – Tipo de variáveis.
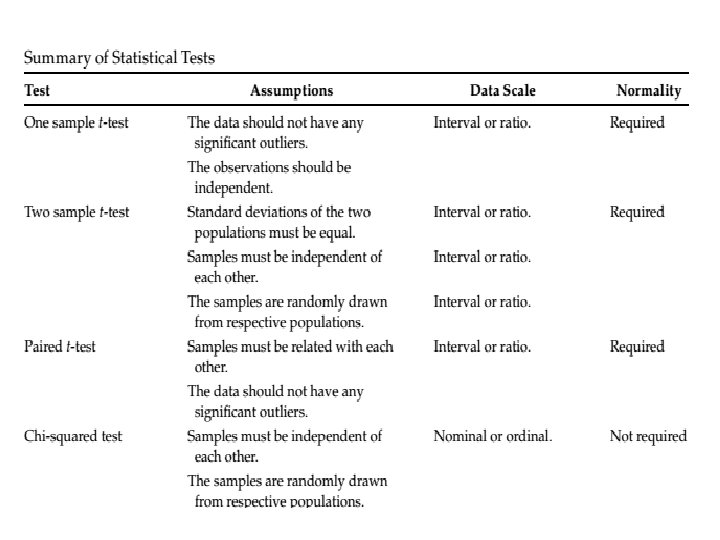
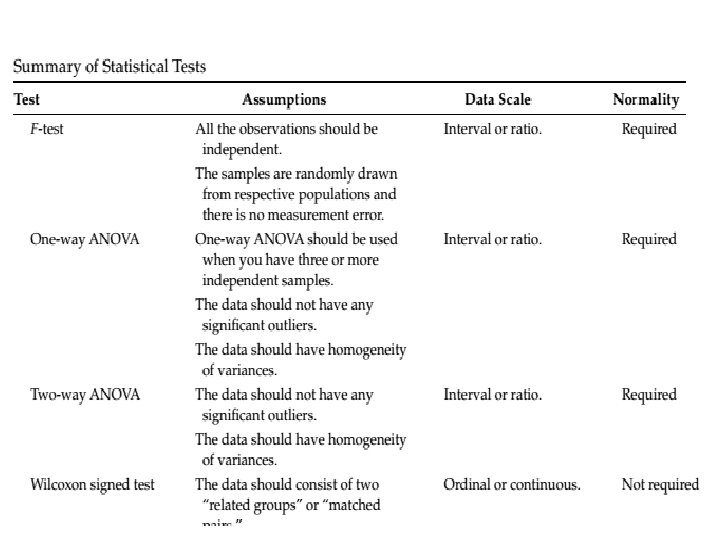
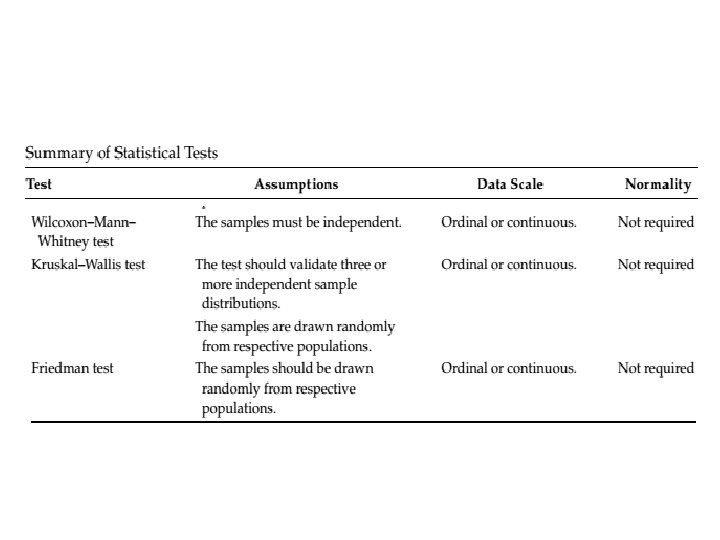
Tipos de Teste de Hipóteses • Testes Paramétricos – Utilizam fórmulas fechadas, derivadas de propriedades de distribuições de frequência conhecidas (tais como equação da curva, da curva acumulada, simetria, . . . ). – Por conta disso, exigem algumas premissas sobre os dados que serão testados: Normalidade; Homocedasticidade. • Testes Não-Paramétricos – Devem ser utilizados quando os dados coletados não atendem aos pressupostos esperados pelos testes paramétricos. – São menos poderosos que os testes paramétricos, mas não presumem distribuições de probabilidade nos dados. – Utilizam rankings dos valores observados ao invés dos valores propriamente ditos.
Referências Wohlin Capítulo 10 Malhotra Capítulo 6