Temu Balik Informasi Model Anggota Kelompok 1 Lingga

Temu Balik Informasi Model
 2. Kabul Agus")
Anggota Kelompok ? : 1. Lingga Catur Putra (15. 11. 0117) 2. Kabul Agus Purwanto (14. 11. 0152) 3. Adimas Dwi Nur H. (15. 11. 0062) 4. Faizal Aji Ramadhan (15. 11. 0107) 5. Damar Nur Sasongko (15. 11. 0102) 6. Fahrul Rosi (15. 11. 0108)
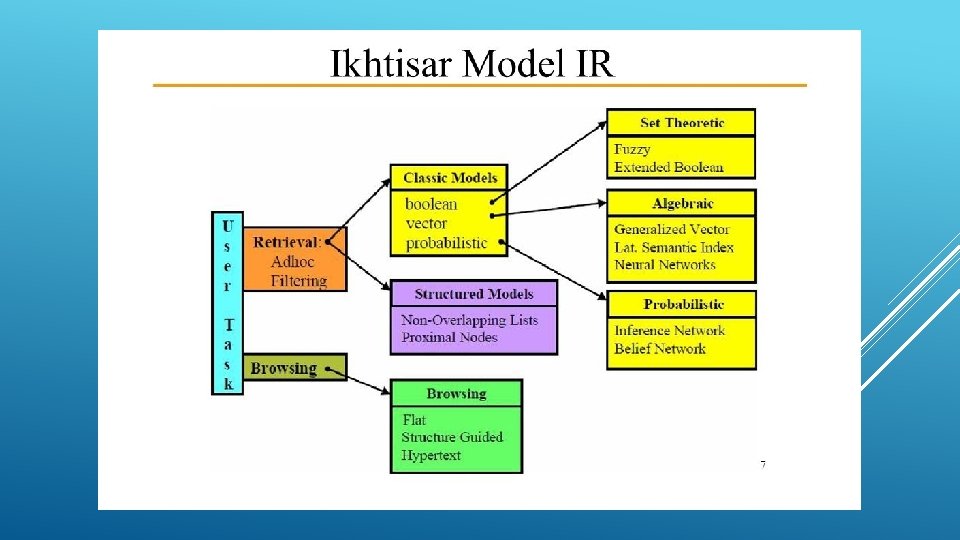

Model Temu Balik Informasi

3 Model Klasik A. Model Boolean merupakan model yang paling sederhana. Model ini berdasarkan teori himpunan dan aljabar Boolean. odel ini menggunakan operator boolean. Istilah (term) dalam sebuah kueri dihubungkan dengan menggunakan operator AND, OR atau NOT. Metode ini merupakan metode yang paling sering digunakan pada`mesin penelusur (search engine) karena kecepatannya.

Teori Himpunan ?

Keuntungan Model Boolean • Model Boolean merupakan model sederhana yang menggunakan teori dasar himpunan sehingga mudah diimplementasikan. • Model Boolean dapat diperluas dengan menggunakan proximity operator dan wildcard operator. • Adanya pertimbangan biaya untuk mengubah software dan struktur database, terutama pada sistem komersil.

Kerugian Model Boolean • Model Boolean tidak menggunakan peringkat dokumen yang terambil. Dokumen yang terambil hanya dokumen yang benar-benar sesuai dengan pernyataan boolean/kueri yang diberikan Sehingga dokumen yang terambil bisa sangat banyak atau bisa sedikit. Akibatnya ada kesulitan dalam mengambil keputusan. • Teori himpunan memang mudah, namun tidak demikian halnya dengan pernyataan Boolean yang bisa kompleks. Akibatnya pengguna harus memiliki pengetahuan banyak mengenai kueri dengan boolean agar pencarian menjadi efisien. • Tidak bisa menyelesaikan partial matching pada kueri

B. Model Ruang Vector Berbeda dengan model boolean yang menggunakan nilai biner sebagai bobot index term, VSM melakukan pembobotan berdasarkan term yang sering muncul dalam dokumen atau dikenal dengan sebutan term frequency (tf) dan jumlah kemunculannya dalam koleksi dokumen yang disebut inverse document frequency(idf) (Manning dkk, 2009). Beberapa karakteristik dari Model vektor dalam sistem temu kembali adalah • Model vektor berdasarkan keyterm • Model vektor mendukung partial matching dan penentuan peringkat dokumen • Prinsip dasar vektor model adalah sebagaii berikut : 1. Dokumen direpresentasikan dengan menggunkan vektor keyterm 2. Ruang dimensi ditentukan oleh keyterms 3. Kueri direpresentasikan dengan menggunakan vektor keyterm 4. Kesamaan document-keyterm dihitung berdasarkan jarak vektor

Keuntungan Kerugian • Efisien • Mudah dalam representasi • Dapat diimplementasikan document-matching • Teoritical Frameworknya tidak jelas • Menghasilkan index yang berdekatan • Asusmsi yang digunakan adalah independensi index term pada

C. Model Probabilitas • model probabilistik mengasumsikan bahwa setiap dokumen dideskripsikan lewat “ada” atau “tidak ada”nya term indeks • Menggunakan pendugaan probabilistik untuk menentukan dokumen yang relevan dengan keyterm yang diberikan • Cukup kompleks • Kinerjanya lebih efisien dibandingkan dengan model ruang vektor � Probability : Menggunakan semantik

2. Model Terstruktur • Model Non Overlapping Sistem yang menggunakan model ini akan membagi-bagi dokumen sebagai wilayah teks tertentu misalnya dengan mengikuti stuktur dokumen (bab, sub-bab, judul, sub-judul, gambar, foto, tabel dan seterusnya) kemudian untuk masing-masing wilayah ini dilakukan pengindeksan yang tidak saling menindih (non overlapping) • Model Proximal nodes Model IR ini menggunakan beberapa struktur indeks yang memiliki hirarki independen terhapap sebuah dokumen. Masing-masing dari indeks ini merujuk ke struktur dokumen (bab, sub-bab, judul, sub judul, gambar, foto tabel dan seterusnya)yang dinamakan nodes. Pada masing-masing node inilah ada rujukan ke bagian dari dokumen yang mengandung teks tertentu.

Referensi Sumber Fadhil Aidil Purnama, Sistem Temu Kembali Informasi dengan Menerapkan Metode Probabilistik Binary Independence Model (BIM), Fakultas UIN Riau Pekanbaru : 2012. (Diakses pada 10 April 2018) https: //www. google. co. id/url? url=http: //www. hirupmotekar. com/wp-content/uploads/2017/04/4. -MODELTBIE_3. pdf&rct=j&sa=U&ved=2 ah. UKEwity 5 jio 7 ba. Ah. VEs 48 KHa. F 3 COk. QFj. AAeg. QIBx. AB&q=model+temu +balik+informasi+pdf&usg=AOv. Vaw 2 ug. Lof. IEb 64 UE 6 q 8 u. Dy. Tg. C (Diakses pada 10 April 2018) https: //computernet-news. blogspot. co. id/2017/04/metode-dan-model-sistem-temu-balik. html (diakses pada 17 April 2018) http: //zero-fisip. web. unair. ac. id/artikel_detail-68838 -Digilib: %20 Sistem%20 Temu%20 Kembali%20 Informasi. html (Diakses pada 17 April 2018)
- Slides: 13