Tag Helper SIDE Carolyn Penstein Ros Language Technologies


























 is used to create lists ¨ COLOR = ANY(red, yellow,")





















- Slides: 69
Tag. Helper & SIDE Carolyn Penstein Rosé Language Technologies Institute/ Human-Computer Interaction Institute
Tag. Helper Tools and SIDE Define Summaries Annotate Data Tag. Helper Tools uses text mining technology to automate annotation of conversational data Visualize Annotated Data SIDE facilitates rapid prototyping of reporting interfaces for group learning facilitators
Setting Up Your Data For Tag. Helper
Setting Up Your Data
How do you know when you have coded enough data? What distinguishes Questions and Statements? I versus You need you towords is code WH Not all questions not ainreliable enough avoid occur in questions end a to question predictorrules that learning mark. won’t work
Creating a Trained Model
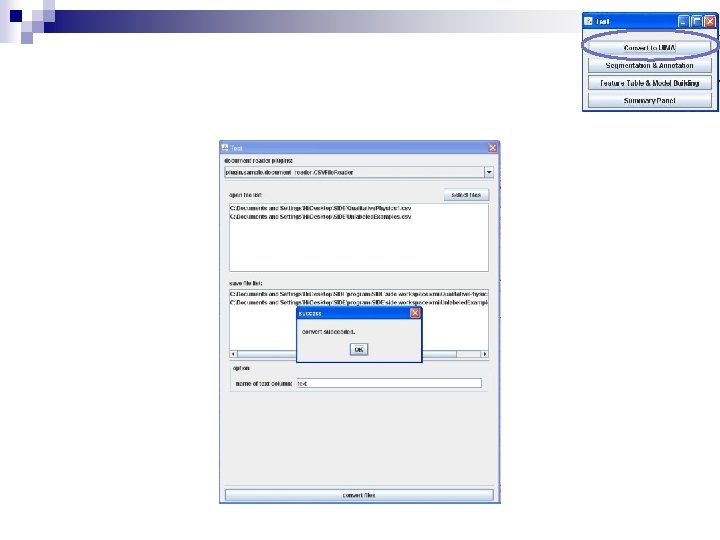
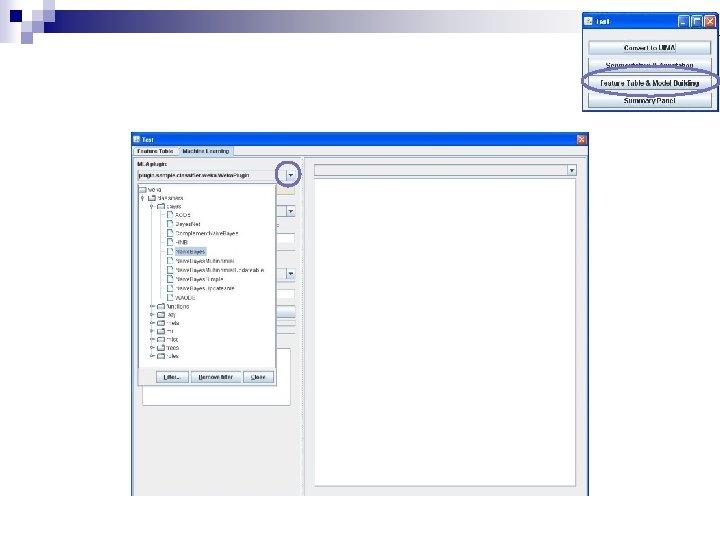
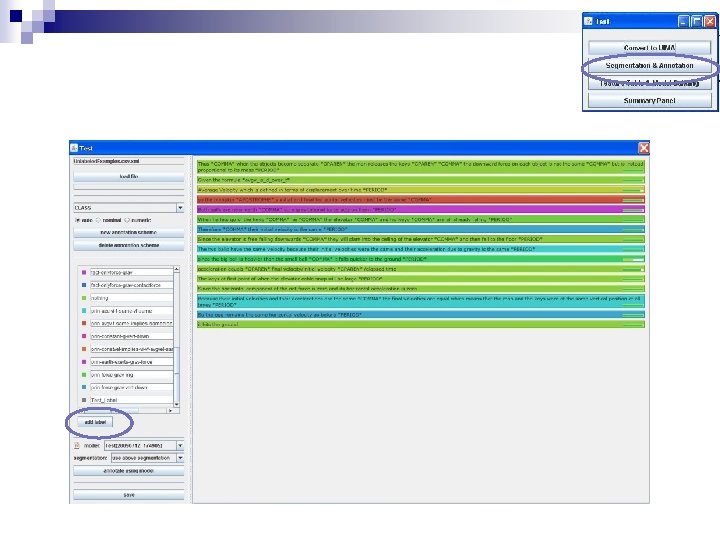
Training and Testing n n Start Tag. Helper tools by double clicking on the portal. bat icon in your Tag. Helper. Tools 2 folder You will then see the following tool pallet The idea is that you will train a prediction model on your coded data and then apply that model to uncoded data Click on Train New Models
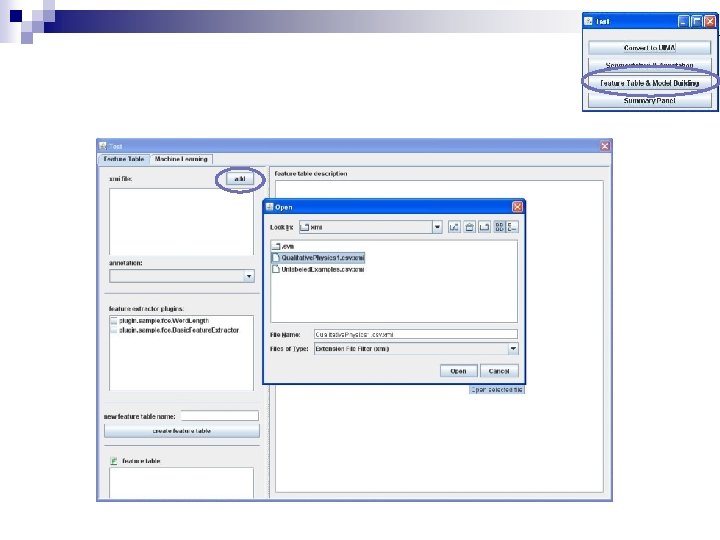
Loading a File First click on Add a File Then select a file
Simplest Usage Click “GO!” n Tag. Helper will use its default setting to train a model on your coded examples n It will use that model to assign codes to the uncoded examples n
More Advanced Usage The second option is to modify the default settings n You get to the options you can set by clicking on >> Options n After you finish that, click “GO!” n
Evaluating Performance
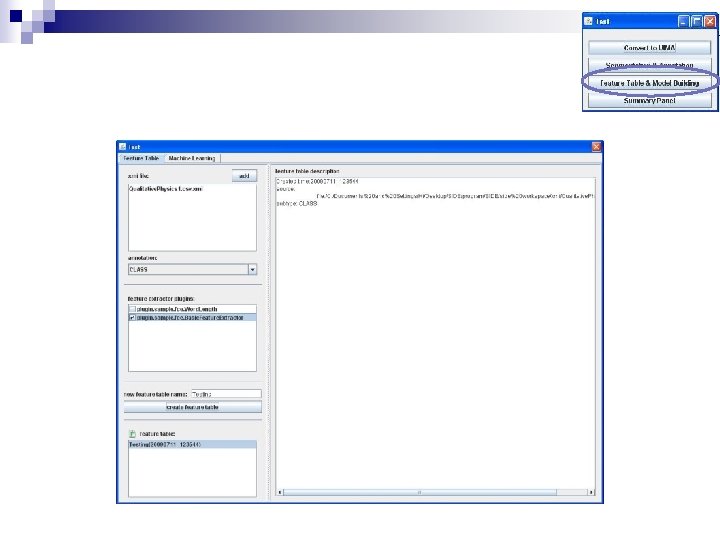
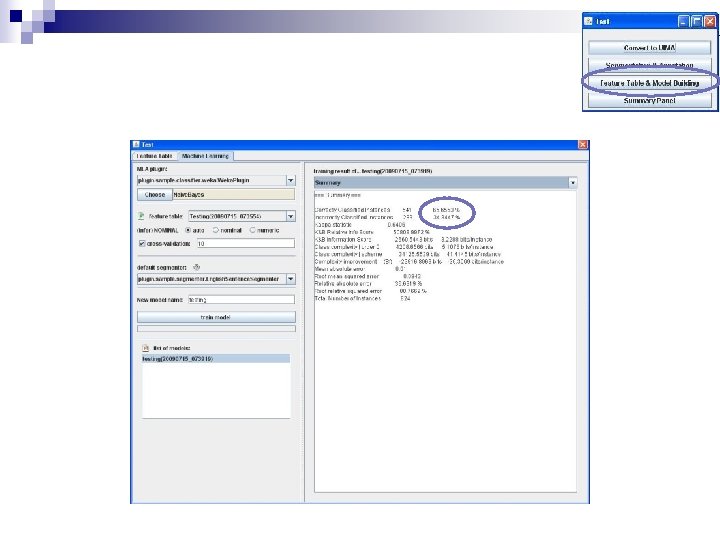
Performance report n The performance report tells you: ¨ What dataset was used ¨ What the customization settings were ¨ At the bottom of the file are reliability statistics and a confusion matrix that tells you which types of errors are being made
Output File n The output file contains ¨ The codes for each segment ¨ Note that the segments that were already coded will retain their original code ¨ The other segments will have their automatic predictions ¨ The prediction column indicates the confidence of the prediction
Overview of Basic Feature Extraction from Text
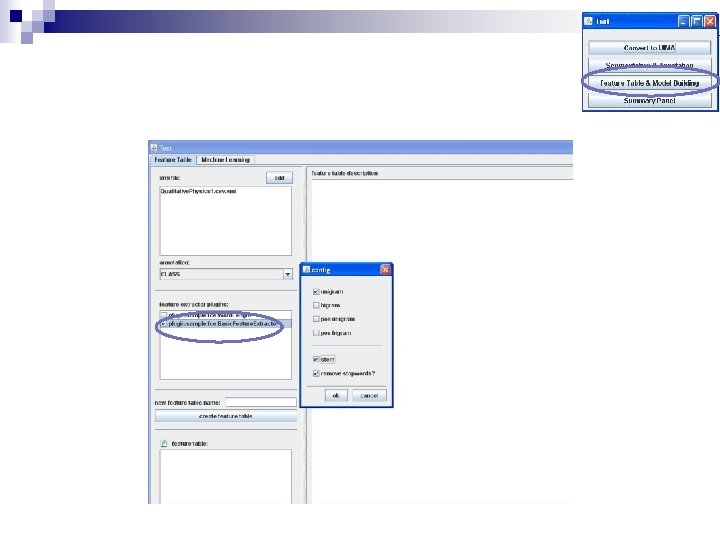
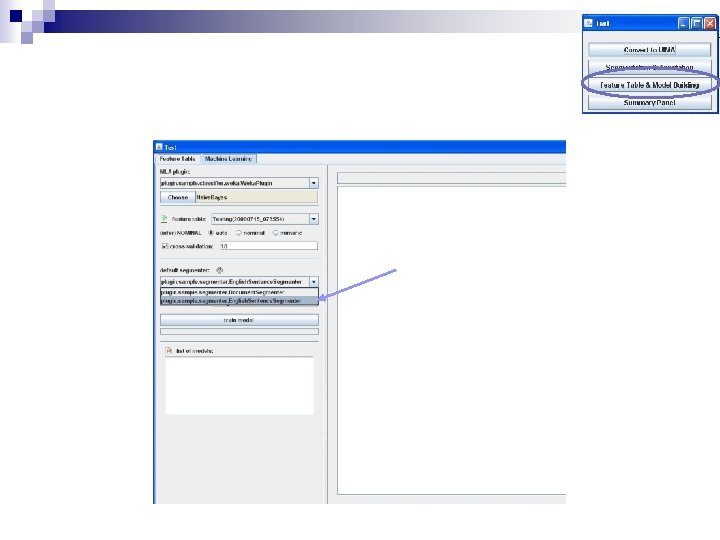
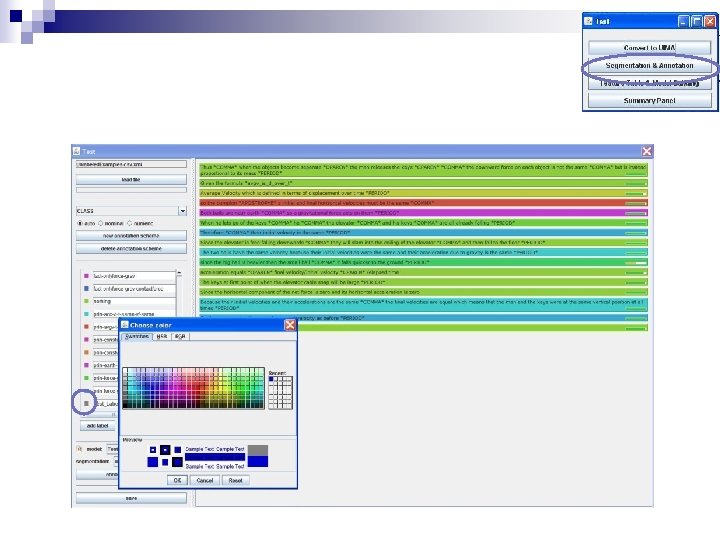
Customizations n To customize the settings: ¨ Select the file ¨ Click on Options
Classifier Options n Rules of thumb: ¨ SMO is state-of-the-art for text classification ¨ J 48* The is best smallof three with main types Classifiers feature setsare – also handles contingencies between Bayesian models (Naïve Bayes), features well functions (SMO), ¨ Naïve Bayes works well for and trees (J 48) models where decisions are made based on accumulating evidence rather than hard and fast rules
Basic Idea Represent text as a vector where each position corresponds to a term This is called the “bag of words” approach But same representation for “Cheese makes cows. ”! Cheese Cows Eggs Hens Lay Make n n Cows make cheese 110001 Hens lay eggs 001110
What can’t you conclude from “bag of words” representations? n Causality: “X caused Y” versus “Y caused X” n Roles and Mood: “Which person ate the food that I prepared this morning and drives the big car in front of my cat” versus “The person, which prepared food that my cat and I ate this morning, drives in front of the big car. ” ¨ Who’s food? driving, who’s eating, and who’s preparing
Basic Anatomy: Layers of Linguistic Analysis n Phonology: The sound structure of language ¨ n Morphology: The building blocks of words ¨ ¨ n n n Inflection: tense, number, gender Derivation: building words from other words, transforming part of speech Syntax: Structural and functional relationships between spans of text within a sentence ¨ n Basic sounds, syllables, rhythm, intonation Phrase and clause structure Semantics: Literal meaning, propositional content Pragmatics: Non-literal meaning, language use, language as action, social aspects of language (tone, politeness) Discourse Analysis: Language in practice, relationships between sentences, interaction structures, discourse markers, anaphora and ellipsis
Part of Speech Tagging http: //www. ldc. upenn. edu/Catalog/docs/treebank 2/cl 93. html 1. CC Coordinating conjunction 2. CD Cardinal number 3. DT Determiner 4. EX Existential there 5. FW Foreign word 6. IN Preposition/subord 7. JJ Adjective 8. JJR Adjective, comparative 9. JJS Adjective, superlative 10. LS List item marker 11. MD Modal 12. NN Noun, singular or mass 13. NNS Noun, plural 14. NNP Proper noun, singular 15. NNPS Proper noun, plural 16. PDT Predeterminer 17. POS Possessive ending 18. PRP Personal pronoun 19. PP Possessive pronoun 20. RB Adverb 21. RBR Adverb, comparative 22. RBS Adverb, superlative
Part of Speech Tagging http: //www. ldc. upenn. edu/Catalog/docs/treebank 2/cl 93. html 23. RP Particle 24. SYM Symbol 25. TO to 26. UH Interjection 27. VB Verb, base form 28. VBD Verb, past tense 29. VBG Verb, gerund/present participle 30. VBN Verb, past participle 31. VBP Verb, non-3 rd ps. sing. present 32. VBZ Verb, 3 rd ps. sing. present 33. WDT wh-determiner 34. WP wh-pronoun 35. WP Possessive whpronoun 36. WRB wh-adverb
Tag. Helper Customizations n Feature Space Design ¨ Think like a computer! ¨ Machine learning algorithms look for features that are good predictors, not features that are necessarily meaningful ¨ Look for approximations n n n If you want to find questions, you don’t need to do a complete syntactic analysis Look for question marks Look for wh-terms that occur immediately before an auxilliary verb
Tag. Helper Customizations n Feature Space Design ¨ Punctuation can be a “stand in” for mood n n ¨ Bigrams capture simple lexical patterns n ¨ “common denominator” versus “common multiple” POS bigrams capture syntactic or stylistic information n ¨ “you think the answer is 9? ” “you think the answer is 9. ” “the answer which is …” vs “which is the answer” Line length can be a proxy for explanation depth
Tag. Helper Customizations n Feature Space Design ¨ Contains non-stop word can be a predictor of whether a conversational contribution is contentful n “ok sure” versus “the common denominator” Remove stop words removes some distracting features ¨ Stemming allows some generalization ¨ Multiple, multiply, multiplication Removing rare features is a cheap form of feature selection n Features that only occur once or twice in the corpus won’t generalize, so they are a waste of time to include in the vector space
Created Features
Why create new features by hand? n Rules ¨ For simple rules, it might be easier and faster to write the rules by hand instead of learning them from examples n Features ¨ More likely to capture meaningful generalizations ¨ Build in knowledge so you can get by with less training data
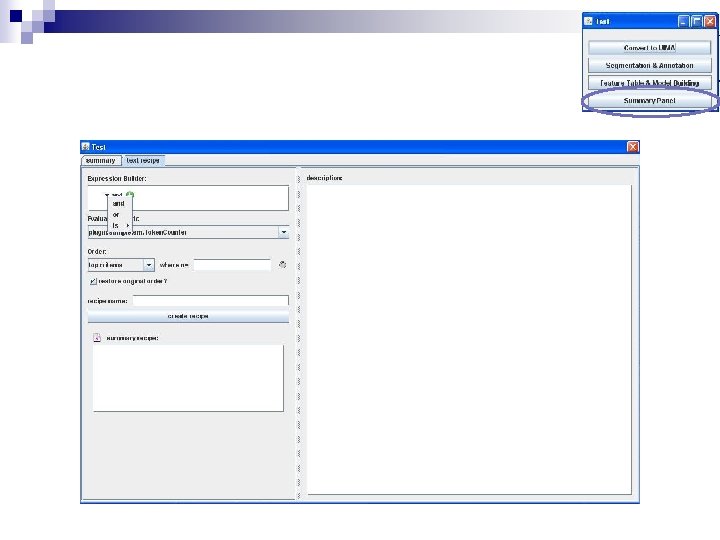
Rule Language n ANY() is used to create lists ¨ COLOR = ANY(red, yellow, green, blue, purple) ¨ FOOD = ANY(cake, pizza, hamburger, steak, bread) n ALL() is used to capture contingencies ¨ ALL(cake, presents) n More complex rules ¨ ALL(COLOR, FOOD) * Note that you may wish to use part-of-speech tags in your rules!
What can you do with this rule language? n You may want to generalize across sets of related words ¨ Color = {red, yellow, orange, green, blue} ¨ Food = {cake, pizza, hamburger, steak, bread} n You may want to detect contingencies ¨ The text must mention both cake and presents in order to count as a birthday party n You may want to combine these ¨ The text must include a Color and a Food
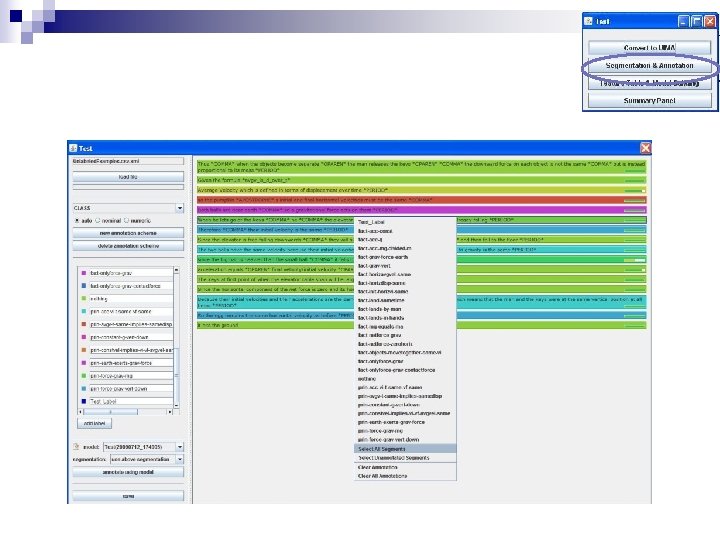
Advanced Feature Editing
Advanced Feature Editing * For small datasets, first deselect Remove rare features.
Advanced Feature Editing * Next, Click on Adv Feature Editing
Advanced Feature Editing * Now you may begin creating your own features.
Types of Basic Features n Primitive features inclulde unigrams, bigrams, and POS bigrams
Types of Basic Features n The Options change which primitive features show up in the Unigram, Bigram, and POS bigram lists ¨ You can choose to remove stopwords or not ¨ You can choose whether or not to strip endings off words with stemming ¨ You can choose how frequently a feature must appear in your data in order for it to show up in your lists
Types of Basic Features * Now let’s look at how to create new features.
Creating New Features * You can use the feature editor to create new features.
Creating New Features * First click on ANY
Creating New Features * Then click ALL
Creating New Features * Now fill in ‘tell’ and ‘me’
Creating New Features * Now fill in the rest of the pattern from the POS Bigram list
Creating New Features * Now change the name
Creating New Features * Click to add to feature list
Using the Display Option
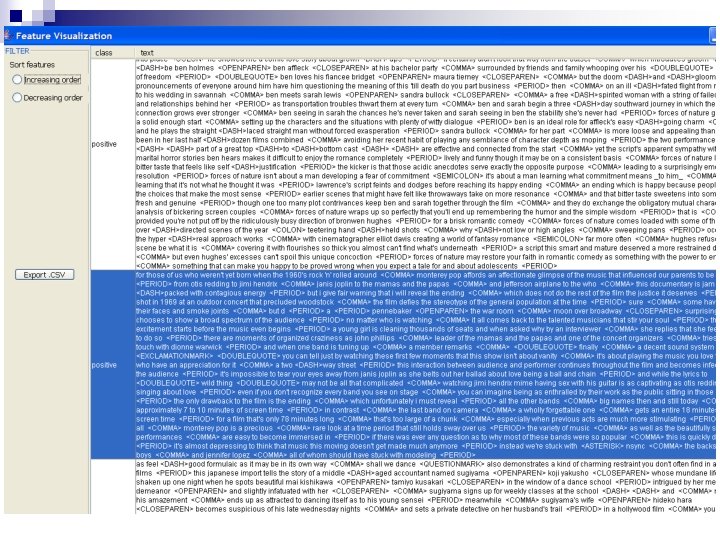
Viewing Created Features
Viewing Created Features
Viewing Created Features
Any Questions?