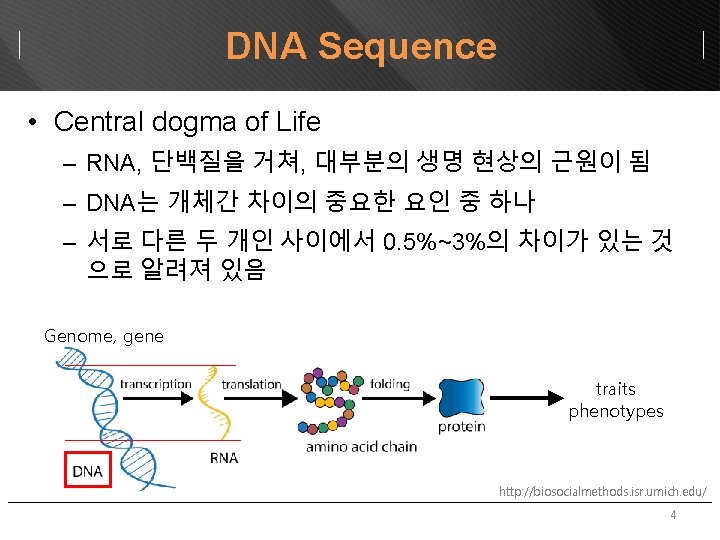
Table of Contents DNA sequence Genomic variations Genomic


Table of Contents • DNA sequence의 특징과 생성 • Genomic variations의 수집 • Genomic variations의 활용 2
의 서열 – 세포의 핵 내에 염색사 또는 염색체")
DNA Sequence • DNA ≈ 염기(Nucleotide)의 서열 – 세포의 핵 내에 염색사 또는 염색체 형태로 존재 – Adenine, Thymine, Guanine, Cytosine로 구성 – A, T, G, C 4개의 문자로 구성된 문자열 데이터로 간주 가능 …CAATTGATGGGTATCTATG… …GTTAACTACCCATAGATAC… …CAATTGATGGGTATCTATG… http: //study. zum. com/book/12698 3
할")
How to get DNA sequence • 문제: 전체 genome sequence를 한 번에 해독 (sequencing)할 수 있는 기술이 없음 – DNA sequencing을 길게 할 수록 정확도가 감소 – 일반적으로 신뢰 가능한 sequence 조각(read)의 길이 • Sanger sequencing (500~1000 base pair) • Next-Generation Sequencing (illumina社: 50~300 bp) • Human genome project (1984~2003) – 3 G 크기의 human genome을 sequencing 6

How to get DNA sequence • Sequence assembly – 밑그림이 없는 Jigsaw puzzle – DNA를 random fragmentation하고 sequence read를 대량 으로 생산한 다음, – Sequence read 간의 overlap에 근거하여 더 긴 조각으로 연결 – 대량의 sequence reads, computation power가 필요 http: //rosalind. info/problems/long/ 7

How to get DNA sequence • Sequence alignment – 밑그림이 있는 Jigsaw puzzle – Reference genome에 다른 individual에서 생성된 read를 align해서, 차이점을 찾아 내는 것 – Assembly에 비해 훨씬 적은 비용 소모 • 더 많은 대상에 적용할 수 있음 Sequence alignment 8

Data format for DNA sequence • FASTA format + 별도의 quality file • FASTQ format Sequence Quality (ASCII code) 9

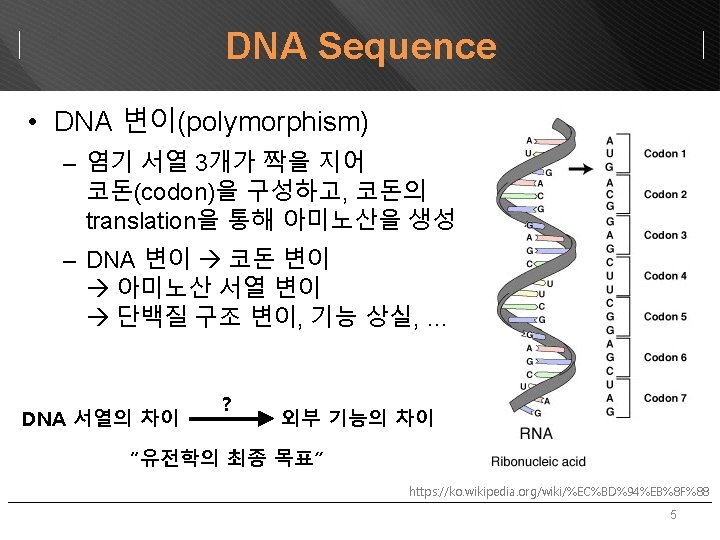
Genomic variations • Sequence alignment를 활용해 DNA 변이의 여러 사 례를 연구할 수 있음 • 유전체 변이(variation, polymorphism)의 표현 – SNP (Single Nucleotide Polymorphism) • 전체 집단에서 1% 이상 나타나는 것을 데이터베이스화 – CNV (Copy Number Variation) • 1 kbp 이상의 loss, gain 10
 Identifier Reference")
SNP example • 2형 당뇨병과 연관된 SNP (http: //www. snpedia. com/index. php/SNPedia) Identifier Reference papers Genotype & annotation 11
 – Genotype(SNP)과 phenotype과의 연관성")
How to construct SNP database • GWAS (Genome-Wide Association Study) – Genotype(SNP)과 phenotype과의 연관성 – 여러 명의 genotype 정보와 phenotype 정보를 수집, 통계 적으로 유의미한 SNP-phenotype을 추정 (with p-value) – 분자유전학적 설명력은 다소 낮음. GWAS Catalog https: //www. ebi. ac. uk/gwas/ 12
 G C Case 2104")
How to construct SNP database • GWAS (Genome-Wide Association Study) G C Case 2104 1896 4000 Control 2676 3324 6000 4780 5220 10000 Expected = 1912 D. of F = (2 -1)*(2 -1)=1 Observed= 2104 X 2 = (E-O)2/E = 19. xxx p-value 계산 13
 – the most detailed")
How to construct SNP database • 1000 genomes project (2008~2015) – the most detailed catalogue of human genetic variation – 다양한 인종, 지역을 대상으로 1000명의 genomic variation을 연구 • 1% 정도로 희귀하게 발견되는 SNP을 정의할 수 있음. – 2012년, 1, 092명의 genomes이 보고되었음 – http: //www. 1000 genomes. org/ 14
 – http: //samtools. github.")
Data format for representing SNP • VCF (Variant Calling Format) – http: //samtools. github. io/hts-specs/VCFv 4. 2. pdf – 위치 정보 및 식별자: CHROM, POS, ID – 염기서열: REF, ALT – Sample별 genotype 및 quality, depth: GT, GQ, DP 15


Prediction of Disease Risk • Prediction algorithm by Ashley – 문헌으로부터 genotype – case – control 정보 수집 AA Aa aa case a b c control d e f 인종의 유병률 * genotype의 연관성 17
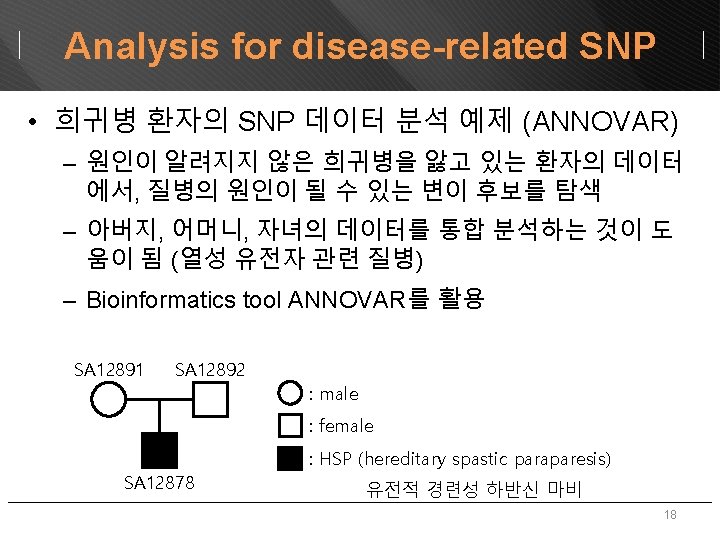


Analysis for disease-related SNP • Recessive disease의 요인 분석 – Homozygous: 부모세대에서는 heterozygous state였으나 자식세대에 서 homozygous state로 변경된 경우 • 해당 유전자의 변이가 사라짐으로써, 질병이 억제되지 않은 경우일 수 있음 – Compound heterozygous: 부모 및 자식 세대에서 모두 hetero • 다른 희귀 변이와 함께 질병의 원인이 될 수 있음 – De novo mutation: 부모에게서 없는 변이가 발견 • 해당 유전자의 변이가 곧 질병의 원인이 될 수 있음 Father Mother Child State VWA 3 B O X X Homozygous CGREF 1 X O X Homozygous BMPR 2 X O O Compound heterozygous KIF 1 A X X O De novo mutation 20


Thank you
- Slides: 22