Support Vector Machines and Beyond Email xushistic ac

Support Vector Machines and Beyond 徐硕 Email: xush@istic. ac. cn 信息技术支持中心 数据挖掘研究室 @中信所419会议室 2014年 11月28日
 v Kernel Functions v Multi-Classification v")
Outline v Background v Support Vector Machines (SVMs) v Kernel Functions v Multi-Classification v Probabilistic Output v Relevance Vector Machines (RVMs) v Least-Square SVMs (LS-SVMs) v Multi-Task Learning (MTL) § Multi-Label Learning § Multi-Output Learning 2014年 11月28日

Categorization/Classification v Given: § A description of an instance, x , where is the instance language or instance space. • E. g: how to represent text documents. § A fixed set of categories = {c 1, c 2, …, cn} v Determine: § The category of x: c(x) , where c(x) is a categorization function whose domain is and whose range is . 2014年 11月28日

Text Classification: Graphical View Graphics NLP Arch. Theory AI 2014年 11月28日

Text Classification: Examples v LABELS=BINARY § “spam” / “not spam” v LABELS=TOPICS § “finance” / “sports” / “military” v LABELS=OPINION § “like” / “hate” / “neutral” v LABELS=AUTHOR § “Shakespeare” / “Marlowe” / “Ben Jonson” v Part-of-Speech (POS) § “Noun” / “Verb” / “Adjective”/… v… 2014年 11月28日
 v Manual classification § § Used by Yahoo!, Looksmart, about. com, ODP,")
Methods (1/2) v Manual classification § § Used by Yahoo!, Looksmart, about. com, ODP, Medline very accurate when job is done by experts consistent when the problem size and team is small difficult and expensive to scale v Automatic document classification § Hand-coded rule-based systems • Reuters, CIA, Verity, … • Commercial systems have complex query languages (everything in IR query languages + accumulators) 2014年 11月28日
 v Supervised learning of document-label assignment function: § § § Naïve Bayes")
Methods (2/2) v Supervised learning of document-label assignment function: § § § Naïve Bayes (simple, common method) k-Nearest Neighbors (simple, powerful) Support-vector machines (new, more powerful) … plus many other methods No free lunch: requires hand-classified training data But can be built (and refined) by amateurs 2014年 11月28日
 v Kernel Functions v Multi-Classification v")
Outline v Background v Support Vector Machines (SVMs) v Kernel Functions v Multi-Classification v Probabilistic Output v Relevance Vector Machines (RVMs) v Least-Square SVMs (LS-SVMs) v Multi-Task Learning (MTL) § Multi-Label Learning § Multi-Output Learning 2014年 11月28日
 x denotes +1 f w x + b>0 yest f(x, w,")
Linear Classifier (1/4) x denotes +1 f w x + b>0 yest f(x, w, b) = sgn(w x + b) w x + b= 0 denotes -1 How would you classify this data? w x + b<0 2014年 11月28日
 x denotes +1 f yest f(x, w, b) = sgn(w x")
Linear Classifier (2/4) x denotes +1 f yest f(x, w, b) = sgn(w x + b) denotes -1 How would you classify this data? 2014年 11月28日
 x denotes +1 f yest f(x, w, b) = sgn(w x")
Linear Classifier (2/4) x denotes +1 f yest f(x, w, b) = sgn(w x + b) denotes -1 How would you classify this data? 2014年 11月28日
 x denotes +1 f yest f(x, w, b) = sgn(w x")
Linear Classifier (3/4) x denotes +1 f yest f(x, w, b) = sgn(w x + b) denotes -1 Any of these would be fine. . but which is best? 2014年 11月28日
 x f denotes +1 yest f(x, w, b) = sgn(w x")
Linear Classifier (4/4) x f denotes +1 yest f(x, w, b) = sgn(w x + b) denotes -1 Any of these would be fine. . but which is best? Misclassified to +1 class 2014年 11月28日
 x denotes +1 f yest f(x, w, b) = sgn(w x")
Classifier Margin (1/2) x denotes +1 f yest f(x, w, b) = sgn(w x + b) denotes -1 Define the margin of a linear classifier as the width that the boundary could be increased by before hitting a datapoint. 2014年 11月28日
 1. x 2. 3. Empirically it works very well. Thevery maximum")
Classifier Margin (2/2) 1. x 2. 3. Empirically it works very well. Thevery maximum denotes +1 denotes -1 Maximizing the margin is good according to intuition and PAC theory Implies that only support vectors are est important; other training examples are ignorable. f(x, w, b) = sgn(w x + b) f y margin linear classifier is the linear classifier with the, um, maximum margin. Support Vectors are those datapoints that the margin pushes up against This is the simplest kind of SVM (Called an LSVM) Linear SVM 2014年 11月28日
 e x+ on z ” ct i d e “Pr")
Linear Classifier Mathematically (1/2) e x+ on z ” ct i d e “Pr +1 = ss x- =1 b x+ w 0 b= + wx =-1 b + wx M=Margin Width Cla ed r P “ 1 = ss one z ” la C ict v What we know: v wx+ + b = +1 v wx- + b = -1 v w(x+-x-) = 2 2014年 11月28日
 v Goal: 1) Correctly classify all training data if yi")
Linear Classifier Mathematically (2/2) v Goal: 1) Correctly classify all training data if yi = +1 if yi = -1 for all i 2) Maximize the Margin same as minimize v We can formulate a Quadratic Optimization Problem and solve for w and b Minimize subject to 2014年 11月28日
 =½ w. Tw")
Solving the Optimization Problem Find w and b such that J(w) =½ w. Tw is minimized; and for all {(xi , yi)}: yi (w. Txi + b) ≥ 1 v Need to optimize a quadratic function subject to linear constraints. v Quadratic optimization problems are a well-known class of mathematical programming problems, and many (rather intricate) algorithms exist for solving them. v The solution involves constructing a dual problem where a Lagrange multiplier i is associated with every constraint in the primary problem: Find 1… N such that J( ) = i - ½ i jyiyjxi. Txj is maximized and (1) iyi = 0 (2) i 0 for all i 2014年 11月28日

The Optimization Problem Solution v The solution has the form: w = iyixi b= yk- w. Txk for any xk such that k 0 v Each non-zero i indicates that corresponding xi is a support vector. v Then the classifying function will have the form: f(x) = iyixi. Tx + b v Notice that it relies on an inner product between the test point x and the support vectors xi – we will return to this later. v Also keep in mind that solving the optimization problem involved computing the inner products xi. Txj between all pairs of training points. 2014年 11月28日

Dataset with noise denotes +1 v Hard Margin: So far we require all denotes -1 data points be classified correctly - No training error v What if the training set is noisy? - Solution 1: use very powerful kernels OVERFITTING! 2014年 11月28日

Soft Margin Classification Slack variables i can be added to allow misclassification of difficult or noisy examples. 11 2 1 b= 0 b= + wx -1 b= + wx What should our quadratic optimization criterion be? Minimize 7 2014年 11月28日

Hard Margin vs Soft Margin v The old formulation: Find w and b such that J(w) =½ w. Tw is minimized and for all {(xi, yi)} yi (w. Txi + b) ≥ 1 v The new formulation incorporating slack variables: Find w and b such that J(w) =½ w. Tw + C 2 i is minimized and for all {(xi, yi)} yi (w. Txi + b) 1 - i and i ≥ 0 for all i v Parameter C can be viewed as a way to control overfitting. 2014年 11月28日

Linear Classifier: Summary v The classifier is a separating hyperplane. v Most “important” training points are support vectors; they define the hyperplane. v Quadratic optimization algorithms can identify which training points xi are support vectors with non-zero Lagrangian multipliers i. v Both in the dual formulation of the problem and in the solution training points appear only inside dot products: Find 1, …, N such that J( ) = i - ½ i jyiyjxi. Txj is maximized and (1) iyi = 0 (2) 0 ≤ i ≤ C for all i f(x) = iyixi. Tx + b 2014年 11月28日

Non-linear SVMs v Datasets that are linearly separable with some noise work out great: x 0 v But what are we going to do if the dataset is just too hard? x 0 v How about… mapping data to a higher-dimensional space: x 2 0 x 2014年 11月28日

Non-linear SVMs: Feature spaces v General idea: the original input space can always be mapped to some higher-dimensional feature space where the training set is separable: : x → (x) 2014年 11月28日
 v The linear classifier relies on dot product between vectors (xi,")
Kernel Trick (1/2) v The linear classifier relies on dot product between vectors (xi, xj)=xi. Txj v If every data point is mapped into high-dimensional space via some transformation : x → (x), the dot product becomes: (xi, xj)= (xi) T (xj) v A kernel function is some function that corresponds to an inner product in some expanded feature space. 2014年 11月28日
![Kernel Trick (2/2) v 2 -dimensional vectors x=[x 1, x 2]; let (xi, xj)=(1](http://slidetodoc.com/presentation_image_h/02d7727e3c77acd37ae3f4055774964b/image-27.jpg "Kernel Trick (2/2) v 2 -dimensional vectors x=[x 1, x 2]; let (xi, xj)=(1")
Kernel Trick (2/2) v 2 -dimensional vectors x=[x 1, x 2]; let (xi, xj)=(1 + xi. Txj)2, Need to show that (xi, xj)= (xi) T (xj): where 2014年 11月28日
 checking that (xi, xj)=")
What Functions are Kernels? v For some functions (xi, xj) checking that (xi, xj)= (xi)T (xj) can be cumbersome. v Mercer’s theorem: Every semi-positive definite symmetric function is a kernel v Semi-positive definite symmetric functions correspond to a semipositive definite symmetric Gram matrix: K= (x 1, x 1) (x 1, x 2) (x 1, x 3) (x 2, x 1) (x 2, x 2) (x 2, x 3) … (x. N, x 1) … (x. N, x 2) … (x. N, x 3) … (x 1, x. N) (x 2, x. N) … … … (x. N, x. N) 2014年 11月28日

Non-linear SVMs Mathematically v Dual problem formulation: Find 1, …, N such that J( ) = i - ½ i jyiyj (xi, xj) is maximized and (1) iyi = 0 (2) i 0 for all i v The solution is: f(x) = iyi (xi, xj)+ b v Optimization techniques for finding i’s remain the same! 2014年 11月28日

Training Algorithms v Quadratic Convex Optimization v Chunking v Osuna’s Algorithm v Sequential Minimal Optimization (SMO) (Platt, 1999) 2014年 11月28日
 v. SVM locates a separating hyperplane in the feature space")
Non-linear SVMs: Summary (1/2) v. SVM locates a separating hyperplane in the feature space and classify points in that space v. It does not need to represent the space explicitly, simply by defining a kernel function v. The kernel function plays the role of the dot product in the feature space. 2014年 11月28日
 v Flexibility in choosing a similarity function v Sparseness of")
Non-linear SVMs: Summary (2/2) v Flexibility in choosing a similarity function v Sparseness of solution when dealing with large data sets § only support vectors are used to specify the separating hyperplane v Ability to handle large feature spaces § complexity does not depend on the dimensionality of the feature space Overfitting can be controlled by soft margin approach v v Nice math property: § a simple convex optimization problem which is guaranteed to converge to a single global solution 2014年 11月28日
 v Kernel Functions v Multi-Classification v")
Outline v Background v Support Vector Machines (SVMs) v Kernel Functions v Multi-Classification v Probabilistic Output v Relevance Vector Machines (RVMs) v Least-Square SVMs (LS-SVMs) v Multi-Task Learning (MTL) § Multi-Label Learning § Multi-Output Learning 2014年 11月28日
= xi. Txj v Polynomial of power p: (xi,")
Classic Examples v Linear: (xi, xj)= xi. Txj v Polynomial of power p: (xi, xj)= (1+ xi. Txj)p v Gaussian (radial-basis function network): v Sigmoid: (xi, xj)= tanh( 0 xi. Txj + 1) 2014年 11月28日
=(tf(t 1, d), tf(t 2, d), …, tf(t. N,")
Vector Space Kernel : d (d)=(tf(t 1, d), tf(t 2, d), …, tf(t. N, d))T D= tf(t 1, d 1) tf(t 2, d 1) tf(t 3, d 1) tf(t 1, d 2) tf(t 2, d 2) tf(t 3, d 2) … tf(t 1, d. M) … tf(t 2, d. M) … tf(t 3, d. M) … tf(t. N, d 1) tf(t. N, d 2) … … … tf(t. N, d. M) K = DDT (d 1, d 2) = (d 1)T (d 2)= tf(tn, d 1) * tf(tn, d 2) 2014年 11月28日

p-Spectrum Kernel vp = 2 ar at ba ca K bar bat car cat bar 1 0 bar 2 1 1 0 bat 0 1 1 0 bat 1 2 0 1 car 1 0 2 1 cat 0 1 1 2 2014年 11月28日

All-Subsequences Kernel 2014年 11月28日
 = 4 v Normalized Kernel: 2014年")
Gap-Weighted Subsequences Kernel v Un-normalized Kernel: UN(“cat”, “car”) = 4 v Normalized Kernel: 2014年 11月28日

Tree Kernel v To measure the similarity between two noun phrases: “a dog” and “a cat” on the basis of their respective parse trees v As 3 structures (out of 6) are completely identical the similarity is equal to 3. 2014年 11月28日
 2014年 11月28日")
Term Relation Extraction (1/2) 2014年 11月28日
 <�元�构�> ARG 1 Radon_exposure is the second leading ARG 1")
Term Relation Extraction (2/2) <�元�构�> ARG 1 Radon_exposure is the second leading ARG 1 cause ARG 1 of ARG 1 lung_cancer ARG 1 in ARG 2 the general population ARG 1 ARG 2 Radon_exposure is the second leading cause of lung_cancer in the general population. Term pair <PAS模式> Radon_exposure is cause of lung_cancer ARG 1 ARG 2 verb_arg 12 prep_arg 12 Radon_exposure is cause of lung_cancer 2014年 11月28日
 v Kernel Functions v Multi-Classification v")
Outline v Background v Support Vector Machines (SVMs) v Kernel Functions v Multi-Classification v Probabilistic Output v Relevance Vector Machines (RVMs) v Least-Square SVMs (LS-SVMs) v Multi-Task Learning (MTL) § Multi-Label Learning § Multi-Output Learning 2014年 11月28日
 v One vs. Others v One vs. One v Directed Acyclic")
Multiclass Classification (1/2) v One vs. Others v One vs. One v Directed Acyclic Graph SVM (DAGSVM) v Error-Correcting Output Codes v… 2014年 11月28日
 ◆Chih-Wei Hsu and Chih-Jen Lin, 2002. A Comparison of Methods for")
Multiclass Classification (2/2) ◆Chih-Wei Hsu and Chih-Jen Lin, 2002. A Comparison of Methods for Multiclass Support Vector Machines. IEEE Transactions on Neural Networks, Vol. 13, No. 2, pp. 415 -425. . 2014年 11月28日
 v Kernel Functions v Multi-Classification v")
Outline v Background v Support Vector Machines (SVMs) v Kernel Functions v Multi-Classification v Probabilistic Output v Relevance Vector Machines (RVMs) v Least-Square SVMs (LS-SVMs) v Multi-Task Learning (MTL) § Multi-Label Learning § Multi-Output Learning 2014年 11月28日

Probabilistic Output v Instead of predicting the label, many applications requires a posterior class probability p(y = 1 | x). v Platt (2000) proposes to approximate p(y = 1 | x) by a sigmoid function ◆J. Platt, 2000. Probabilistic Outputs for Support Vector Machines and Comparison to Regularized Likelihood Methods. Advances in Large Margin Classifiers, Cambridge, MA: MIT Press. ◆Hsuan-Tien Lin, Chih-Jen Lin, & Ruby C. Weng, 2007. A Note on Platt’s Probabilistic Outputs for Support Vector Machines. Machine Learning, Vol. 68, pp. 267 -276. 2014年 11月28日
 ◆吴琳琳, 徐硕, 2010. 基于SVM的蛋白质二级结构预测. 生物信息学, Vol. 8, No. 3, pp. 187")
Experimental Results (1/2) ◆吴琳琳, 徐硕, 2010. 基于SVM的蛋白质二级结构预测. 生物信息学, Vol. 8, No. 3, pp. 187 -190. 2014年 11月28日
 ◆吴琳琳, 徐硕, 2010. 基于SVM的蛋白质二级结构预测. 生物信息学, Vol. 8, No. 3, pp. 187")
Experimental Results (2/2) ◆吴琳琳, 徐硕, 2010. 基于SVM的蛋白质二级结构预测. 生物信息学, Vol. 8, No. 3, pp. 187 -190. 2014年 11月28日
 v Kernel Functions v Multi-Classification v")
Outline v Background v Support Vector Machines (SVMs) v Kernel Functions v Multi-Classification v Probabilistic Output v Relevance Vector Machines (RVMs) v Least-Square SVMs (LS-SVMs) v Multi-Task Learning (MTL) § Multi-Label Learning § Multi-Output Learning 2014年 11月28日
 v RVM (Tipping, 1999): Bayesian alternative to support vector machine")
Relevance Vector Machines (1/4) v RVM (Tipping, 1999): Bayesian alternative to support vector machine (SVM) v Limitations of the SVM: § § § two classes large number of kernels (in spite of sparsity) kernels must satisfy Mercer criterion cross-validation to set parameters C (and ε) decisions at outputs instead of probabilities 2014年 11月28日
 v Linear model as for SVM v Input vectors v")
Relevance Vector Machines (2/4) v Linear model as for SVM v Input vectors v Regression and targets v Classification 2014年 11月28日
 v Gaussian prior for with hyper-parameters v Hyper-priors over (and")
Relevance Vector Machines (3/4) v Gaussian prior for with hyper-parameters v Hyper-priors over (and if regression) v A high proportion of are driven to large values in the posterior distribution, and corresponding are driven to zero, giving a sparse model 2014年 11月28日
 v Graphical model representation (regression) v For classification use sigmoid")
Relevance Vector Machines (4/4) v Graphical model representation (regression) v For classification use sigmoid (or softmax for multi -class) outputs and omit noise node 2014年 11月28日

Relevance Vector Machine: Regression 2014年 11月28日

Relevance Vector Machine: Classification SVM RVM 2014年 11月28日

Relevance Vector Machines: Summary v comparable error rates to SVM on new data v no cross-validation to set complexity parameters v applicable to wide choice of basis function v multi-classification v probabilistic outputs v dramatically fewer kernels (by an order of magnitude) v but, slower to train than SVM 2014年 11月28日
 v Kernel Functions v Multi-Classification v")
Outline v Background v Support Vector Machines (SVMs) v Kernel Functions v Multi-Classification v Probabilistic Output v Relevance Vector Machines (RVMs) v Least-Square SVMs (LS-SVMs) v Multi-Task Learning (MTL) § Multi-Label Learning § Multi-Output Learning 2014年 11月28日
 v Primal Problem: SVM Find w and b such that J(w)")
Least-Squares SVM (1/2) v Primal Problem: SVM Find w and b such that J(w) =½ w. Tw + C 2 i is minimized and for all {(xi, yi)} yi (w. Txi + b) 1 - i and i ≥ 0 for all i v Primal Problem: LS-SVM Find w and b such that J(w) =½ w. Tw + ½ 2 i is minimized and for all {(xi, yi)} yi (w. Txi + b) = 1 - i and i ≥ 0 for all i 2014年 11月28日
 v Dual Problem § convex quadratic progamming convex linear system v")
Least-Squares SVM (2/2) v Dual Problem § convex quadratic progamming convex linear system v where i, j = yiyj (xi, xj) and y = (y 1, y 2, …, y. N)T. 2014年 11月28日

SMO Algorithm for LS-SVM ◆S. S. Keerthi and S. K. Shevade, 2003. SMO Algorithm for Least-Squares SVM Formulations. Neural Computation, Vol. 15, No. 2, pp. 487 -507. 2014年 11月28日
 v Kernel Functions v Multi-Classification v")
Outline v Background v Support Vector Machines (SVMs) v Kernel Functions v Multi-Classification v Probabilistic Output v Relevance Vector Machines (RVMs) v Least-Square SVMs (LS-SVMs) v Multi-Task Learning (MTL) § Multi-Label Learning § Multi-Output Learning 2014年 11月28日

Multi-Task Learning v Learning many related tasks simultaneously § Tasks have commonality § Each tasks have their specialty v Why multi-task learning (my understanding) § Obtain a better estimation of common part of the tasks § Acquire better understanding of the problems and their underlying model v Application § Knowledge Extraction (classification problem) § … 2014年 11月28日

An Example 2014年 11月28日

Another Example 2014年 11月28日
 v Learn T tasks together, each task corresponds to an LS-SVM")
Multi-Task LS-SVMs (1/2) v Learn T tasks together, each task corresponds to an LS-SVM classifier wt = w 0 + vt, t = 1, 2, …, T v w 0 carrys information of the commonality v vt carrys information of the specialty v Regularizing between commonality and specialty when solving the problem ◆Shuo Xu, Xin An, Xiaodong Qiao, & Lijun Zhu, 2014. Multi-Task Least-Squares Support Vector Machines. Multimedia Tools and Applications, Vol. 71, No. 2, pp. 699 -715. 2014年 11月28日
 v Classification Problem v Regression Problem ◆Shuo Xu, Xin An, Xiaodong")
Multi-Task LS-SVMs (2/2) v Classification Problem v Regression Problem ◆Shuo Xu, Xin An, Xiaodong Qiao, & Lijun Zhu, 2014. Multi-Task Least-Squares Support Vector Machines. Multimedia Tools and Applications, Vol. 71, No. 2, pp. 699 -715. 2014年 11月28日
 ◆Shuo Xu, Xin An, Xiaodong Qiao, & Lijun Zhu, 2014. Multi-Task")
Experimental Results (1/2) ◆Shuo Xu, Xin An, Xiaodong Qiao, & Lijun Zhu, 2014. Multi-Task Least-Squares Support Vector Machines. Multimedia Tools and Applications, Vol. 71, No. 2, pp. 699 -715. 2014年 11月28日
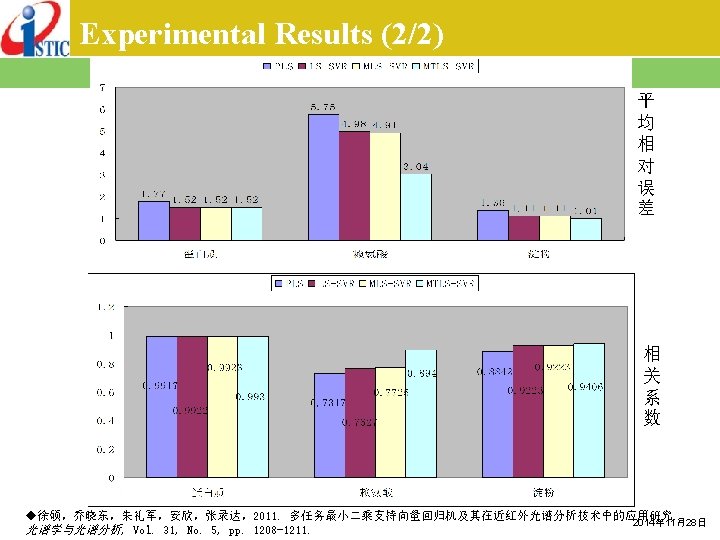
 v Kernel Functions v Multi-Classification v")
Outline v Background v Support Vector Machines (SVMs) v Kernel Functions v Multi-Classification v Probabilistic Output v Relevance Vector Machines (RVMs) v Least-Square SVMs (LS-SVMs) v Multi-Task Learning (MTL) § Multi-Label Learning § Multi-Output Learning 2014年 11月28日

Multi-Label Learning v Single-Label Classification Tree Winter § The classes are exclusive: if an example belongs to one class, it can’t be belongs to others v Multi-label Classification § A picture, video, article may belong to several compatible categories § A gene can control several biological functions Park Ice Lake 2014年 11月28日
 § Problem Transformation •")
Existing Methods v Two Strategies (Tsoumakas & Katakis , 2007) § Problem Transformation • Transfer Multi-Label Classification Problem to Single. Label Classification Problem § Algorithm Adaptation • Adapt Single-label Classifiers to Solve the Multi-label Classification Problem • With high complexity 2014年 11月28日
 2014年 11月28日")
Example (1/2) 2014年 11月28日
 2014年 11月28日")
Example (2/2) 2014年 11月28日
 2014年 11月28日")
Two Benchmark Datasets (1/2) 2014年 11月28日
 2014年 11月28日")
Two Benchmark Datasets (2/2) 2014年 11月28日
 cross relatedness among different labels.")
Shared Characteristics v There exists some underling (potentially nonlinear) cross relatedness among different labels. v The number of samples for different labels is not nearly even. v Therefore, it may be advantageous to learn all labels simultaneously while considering unbalanced phenomenon 2014年 11月28日

Multi-Label LS-SVMs ◆Shuo Xu, Lijun Zhu, Chongde Shi, Hongqi Han, Zhaofeng Zhang, & Ying Li. Multi-Label Least-Squares Support Vetor Machine for Multi-Label Classification. Pattern Recogniton Letters. (Submitted) 2014年 11月28日
 2014年 11月28日")
Experimental Results (1/2) 2014年 11月28日
 2014年 11月28日")
Experimental Results (2/2) 2014年 11月28日
 v Kernel Functions v Multi-Classification v")
Outline v Background v Support Vector Machines (SVMs) v Kernel Functions v Multi-Classification v Probabilistic Output v Relevance Vector Machines (RVMs) v Least-Square SVMs (LS-SVMs) v Multi-Task Learning (MTL) § Multi-Label Learning § Multi-Output Learning 2014年 11月28日

Multi-Output Learning: Example 2014年 11月28日

Multi-Output LS-SVM ◆Shuo Xu, Xin An, Xiaodong Qiao, Lijun Zhu, and Lin Li, 2013. Multi-Output Least-Squares Support Vector Regression Machines. Pattern Recognition Letters, Vol. 34, No. 9, pp. 1078 -1084. 2014年 11月28日
 2014年 11月28日")
Experimental Results (1/3) 2014年 11月28日
 2014年 11月28日")
Experimental Results (2/3) 2014年 11月28日
 2014年 11月28日")
Experimental Results (3/3) 2014年 11月28日

谢谢大家 徐硕 Email: xush@istic. ac. cn或pzczxs@gmail. com 电话: 010 -58882447 -8006 微信:pzczxs 腾讯QQ: 89245452 个人主页: http: //168. 160. 18. 213/dmwiki/index. php? id=zh: people: xush 2014年 11月28日
- Slides: 86