Supervised Learning Networks Supervised Learning Networks Linear perceptron


 multi-layer perceptrons. Two-Level: (b) Linear perceptron networks (c)")


 Divide-and-conquer principle: divide the task into modules and then integrate the")
 Modules: Each expert serves the function of (1) extracting local features and")







 A BP Multi-Layer Perceptron(MLP) possesses adaptive learning abilities to estimate sampled")


")






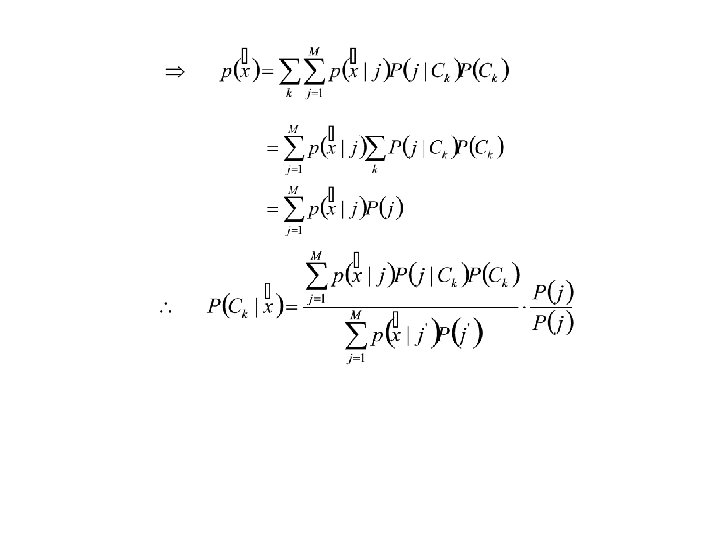





 Use the K-mean algorithm to find ci")





 RBF learning by gradient descent we have Apply")




- Slides: 43
Supervised Learning Networks
Supervised Learning Networks • Linear perceptron networks • Multi-layer perceptrons • Mixture of experts • Decision-based neural networks • Hierarchical neural networks
Hierarchical Neural Network Structures One-Level: (a) multi-layer perceptrons. Two-Level: (b) Linear perceptron networks (c) decision-based neural network. (d) mixture of experts network. Three-Level: (e) experts-in-class network. (f) classes-in-expert network.
Hierarchical Structure of NN • 1 -level hierarchy: BP • 2 -level hierarchy: MOE, DBNN • 3 -level hierarchy: PDBNN “Synergistic Modeling and Applications of Hierarchical Fuzzy Neural Networks”, by S. Y. Kung, et al. , Proceedings of the IEEE, Special Issue on Computational Intelligence, Sept. 1999
All Classes in One Net multi-layer perceptron
Modular Structures (two-level) Divide-and-conquer principle: divide the task into modules and then integrate the individual results into a collective decision. Two typical modular networks: (1) mixture-of-experts (MOE) which utilizes the expert-level modules, (2) decision-based neural networks (DBNN) based on the class-level modules.
Expert-level (Rule-level) Modules: Each expert serves the function of (1) extracting local features and (2) making local recommendations. The rules in the gating network are used to decide how to combine recommendations from several local experts, with corresponding degree of confidences.
mixture of experts network
Class-level modules: Class-level modules are natural basic partitioning units, where each module specializes in distinguishing its own class from the others. In contrast to expert-level partitioning, this OCON structure facilitates a global (or mutual) supervised training scheme. In global inter-class supervised learning, any dispute over a pattern region by (two or more) competing classes may be effectively resolved by resorting to the teacher's guidance.
Decision Based Neural Network
Three-level hierarchical structures: Apply the divide-and-conquer principle twice: one time on the expert-level and another on the class-level. Depending on the order used, two kinds of hierarchical networks: • one has an experts-in-class construct and • another a classes-in-expert Construct.
Classes-in-Expert Network
Experts-in-Class Network
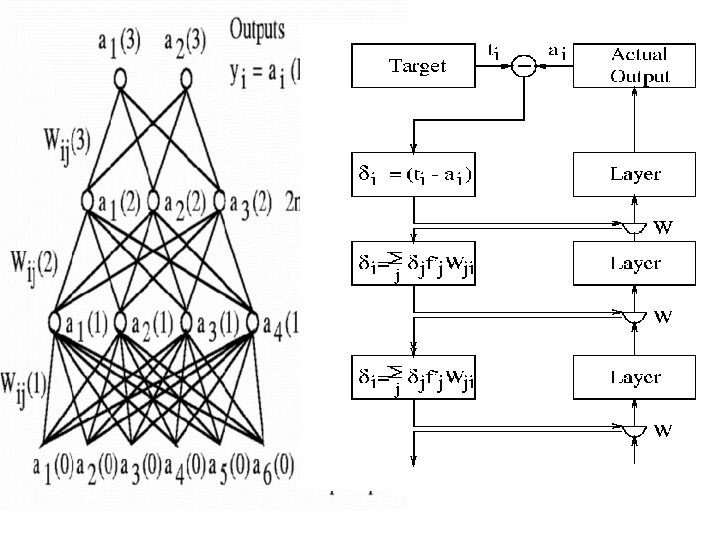
Multilayer Back-Propagation Networks
BP Multi-Layer Perceptron(MLP) A BP Multi-Layer Perceptron(MLP) possesses adaptive learning abilities to estimate sampled functions, represent these samples, encode structural knowledge, and inference inputs to outputs via association. Its main strength lies in its (sufficiently large number of ) hidden units, thus a large number of interconnections. The MLP neural networks enhance the ability to learn and generalize from training data. Namely, MLP can approximate almost any function.
A 3 -Layer Network
Neuron Units: Activation Function
Linear Basis Function (LBF)
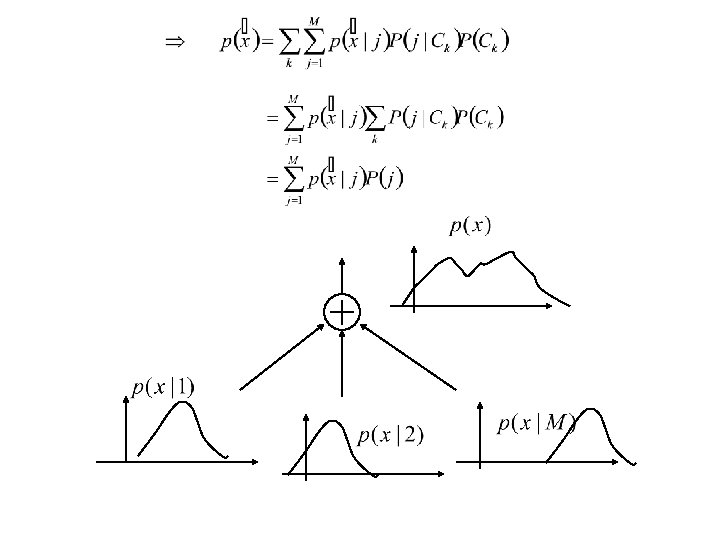
RBF NN is More Suitable for Probabilistic Pattern Classification Hyperplane MLP Kernel function RBF The probability density function (also called conditional density function or likelihood) of the k-th class is defined as
RBF BP Neural Network The centers and widths of the RBF Gaussian kernels are deterministic functions of the training data;
RBF Output as Probability Function • According to Bays’ theorem, the posterior prob. is where P(Ck) is the prior prob. and
l l MLPs are highly non-linear in the parameter space gradient descent local minima RBF networks solve this problem by dividing the learning into two independent processes. 1. 2. Use the K-mean algorithm to find ci and determine weights w using the least square method RBF learning by gradient descent
Comparison of RBF and MLP
l RBF learning process K-means ci A Basis Functions xp ci K-Nearest Neighbor i Linear Regression w
l RBF networks implement the function l wi i and ci can be determined separately Fast learning algorithm Basis function types l
Finding the RBF Parameters (1 ) Use the K-mean algorithm to find ci
Centers and widths found by K-means and K-NN
l Use K nearest neighbor rule to find the function width k-th nearest neighbor of ci l The objective is to cover the training points so that a smooth fit of the training samples can be achieved
l For Gaussian basis functions l Assume the variance across each dimension are equal
l To write in matrix form, let
l Determining weights w using the least square method where dp is the desired output for pattern p
(2) RBF learning by gradient descent we have Apply
we have the following update equations
Elliptical Basis Function networks : function centers : covariance matrix
EBF Vs. RBF networks RBFN with 4 centers EBFN with 4 centers
Mat. Lab Assignment #3: RBF BP Network to separate 2 classes ratio=2: 1 RBF BP with 4 hidden units EBF BP with 4 hidden units S S