Superscalar and VLIW Architectures Miodrag Bolic CEG 3151

Superscalar and VLIW Architectures Miodrag Bolic CEG 3151

Outline • • Types of architectures Superscalar Differences between CISC, RISC and VLIW
![Parallel processing [2] Processing instructions in parallel requires three major tasks: 1. checking dependencies](http://slidetodoc.com/presentation_image_h/c16031006b4c427a8b266e05456a4015/image-3.jpg "Parallel processing [2] Processing instructions in parallel requires three major tasks: 1. checking dependencies")
Parallel processing [2] Processing instructions in parallel requires three major tasks: 1. checking dependencies between instructions to determine which instructions can be grouped together for parallel execution; 2. assigning instructions to the functional units on the hardware; 3. determining when instructions are initiated placed together into a single word.
![Major categories [2] VLIW – Very Long Instruction Word EPIC – Explicitly Parallel Instruction](http://slidetodoc.com/presentation_image_h/c16031006b4c427a8b266e05456a4015/image-4.jpg "Major categories [2] VLIW – Very Long Instruction Word EPIC – Explicitly Parallel Instruction")
Major categories [2] VLIW – Very Long Instruction Word EPIC – Explicitly Parallel Instruction Computing From Mark Smotherman, “Understanding EPIC Architectures and Implementations”
![Major categories [2] From Mark Smotherman, “Understanding EPIC Architectures and Implementations”](http://slidetodoc.com/presentation_image_h/c16031006b4c427a8b266e05456a4015/image-5.jpg "Major categories [2] From Mark Smotherman, “Understanding EPIC Architectures and Implementations”")
Major categories [2] From Mark Smotherman, “Understanding EPIC Architectures and Implementations”
![Superscalar Processors [1] • Superscalar processors are designed to exploit more instruction-level parallelism in](http://slidetodoc.com/presentation_image_h/c16031006b4c427a8b266e05456a4015/image-6.jpg "Superscalar Processors [1] • Superscalar processors are designed to exploit more instruction-level parallelism in")
Superscalar Processors [1] • Superscalar processors are designed to exploit more instruction-level parallelism in user programs. • Only independent instructions can be executed in parallel without causing a wait state. • The amount of instruction-level parallelism varies widely depending on the type of code being executed.
![Pipelining in Superscalar Processors [1] • In order to fully utilise a superscalar processor](http://slidetodoc.com/presentation_image_h/c16031006b4c427a8b266e05456a4015/image-7.jpg "Pipelining in Superscalar Processors [1] • In order to fully utilise a superscalar processor")
Pipelining in Superscalar Processors [1] • In order to fully utilise a superscalar processor of degree m, m instructions must be executable in parallel. This situation may not be true in all clock cycles. In that case, some of the pipelines may be stalling in a wait state. • In a superscalar processor, the simple operation latency should require only one cycle, as in the base scalar processor.
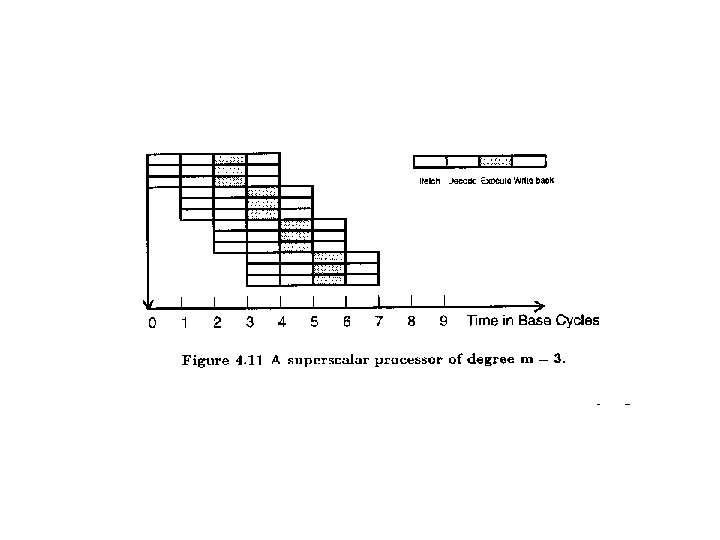

Superscalar Execution

Superscalar Implementation • Simultaneously fetch multiple instructions • Logic to determine true dependencies involving register values • Mechanisms to communicate these values • Mechanisms to initiate multiple instructions in parallel • Resources for parallel execution of multiple instructions • Mechanisms for committing process state in correct order

Some Architectures • Power. PC 604 – six independent execution units: • • Branch execution unit Load/Store unit 3 Integer units Floating-point unit – in-order issue – register renaming • Power PC 620 – provides in addition to the 604 out-of-order issue • Pentium – three independent execution units: • 2 Integer units • Floating point unit – in-order issue
![The VLIW Architecture [4] • A typical VLIW (very long instruction word) machine has](http://slidetodoc.com/presentation_image_h/c16031006b4c427a8b266e05456a4015/image-12.jpg "The VLIW Architecture [4] • A typical VLIW (very long instruction word) machine has")
The VLIW Architecture [4] • A typical VLIW (very long instruction word) machine has instruction words hundreds of bits in length. • Multiple functional units are used concurrently in a VLIW processor. • All functional units share the use of a common large register file.
![Comparison: CISC, RISC, VLIW [4]](http://slidetodoc.com/presentation_image_h/c16031006b4c427a8b266e05456a4015/image-13.jpg "Comparison: CISC, RISC, VLIW [4]")
Comparison: CISC, RISC, VLIW [4]
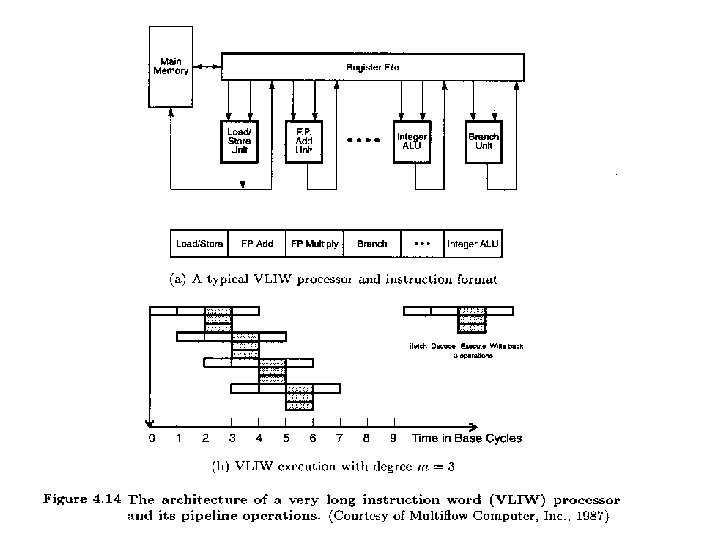

Advantages of VLIW Compiler prepares fixed packets of multiple operations that give the full "plan of execution" – – – dependencies are determined by compiler and used to schedule according to function unit latencies function units are assigned by compiler and correspond to the position within the instruction packet ("slotting") compiler produces fully-scheduled, hazard-free code => hardware doesn't have to "rediscover" dependencies or schedule

Disadvantages of VLIW Compatibility across implementations is a major problem – – VLIW code won't run properly with different number of function units or different latencies unscheduled events (e. g. , cache miss) stall entire processor Code density is another problem – – low slot utilization (mostly nops) reduce nops by compression ("flexible VLIW", "variable-length VLIW")

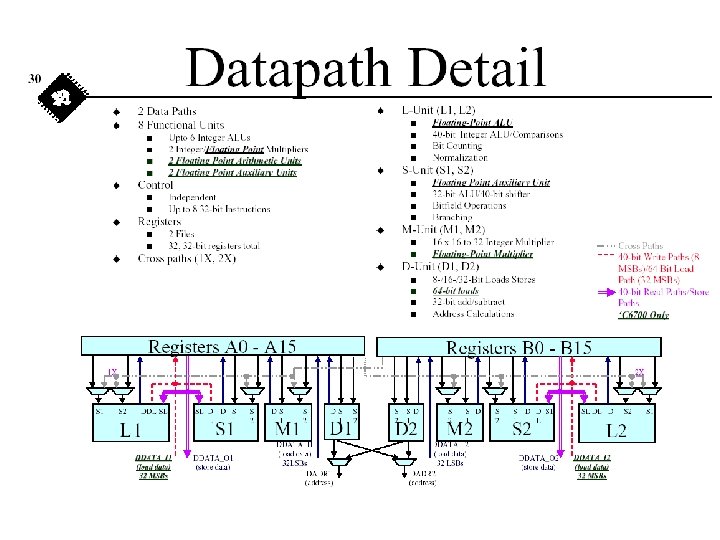

Example: Vector Dot Product • A vector dot product is common in filtering • Store a(n) and x(n) into an array of N elements • C 6 x peak performance: 8 RISC instructions/cycle – Peak RISC instructions per sample: 300, 000 for speech; 54, 421 for audio; and 290 for luminance NTSC video – Generally requires hand coding for peak performance • First dot product example will not be optimized
, A")
Example: Vector Dot Product • Prologue – Initialize pointers: A 5 for a(n), A 6 for x(n), and A 7 for Y – Move the number of times to loop (N) into A 2 – Set accumulator (A 4) to zero • Inner loop – Put a(n) into A 0 and x(n) into A 1 – Multiply a(n) and x(n) – Accumulate multiplication result into A 4 – Decrement loop counter (A 2) – Continue inner loop if counter is not zero • Epilogue – Store the result into Y
 Data x(n) Using A data path only ;")
Example: Vector Dot Product Coefficients a(n) Data x(n) Using A data path only ; clear A 4 MVK loop LDH MPY ADD SUB [A 2] B STH and initialize. S 1 40, A 2. D 1 *A 5++, A 0. D 1 *A 6++, A 1. M 1 A 0, A 1, A 3. L 1 A 3, A 4. L 1 A 2, 1, A 2. S 1 loop. D 1 A 4, *A 7 pointers A 5, A 6, and A 7 ; A 2 = 40 (loop counter) ; A 0 = a(n) ; A 1 = x(n) ; A 3 = a(n) * x(n) ; Y = Y + A 3 ; decrement loop counter ; if A 2 != 0, then branch ; *A 7 = Y

References 1. 2. 3. 4. 5. 6. 7. Advanced Computer Architectures, Parallelism, Scalability, Programmability, K. Hwang, 1993. M. Smotherman, "Understanding EPIC Architectures and Implementations" (pdf) http: //www. cs. clemson. edu/~mark/464/acmse_epic. pdf Lecture notes of Mark Smotherman, http: //www. cs. clemson. edu/~mark/464/hp 3 e 4. html An Introduction To Very-Long Instruction Word (VLIW) Computer Architecture, Philips Semiconductors, http: //www. semiconductors. philips. com/acrobat_download/other/vliwwp. pdf Lecture 6 and Lecture 7 by Paul Pop, http: //www. ida. liu. se/~TDTS 51/ Texas Instruments, Tutorial on TMS 320 C 6000 Veloci. TI Advanced VLIW Architecture. http: //www. acm. org/sigs/sigmicro/existing/micro 31/pdf/m 31_seshan. pdf Morgan Kaufmann Website: Companion Web Site for Computer Organization and Design
- Slides: 22