suffix array Bentley Sedgewick 97 Manber Myers 93

とは • 関連研究 – Bentley, Sedgewick 97 – Manber, Myers 93")
内容 • suffix array(接尾辞配列)とは • 関連研究 – Bentley, Sedgewick 97 – Manber, Myers 93 • Larsson, Sadakaneのアルゴリズム – 計算量 – 実装 – メモリ • disk上での構成アルゴリズム • Application (proximity search) 2

 X suffix array 0 BANa. Na 1 ANa. Na")
suffix array ・文字列の全てのsuffixのポインタを辞書順 にソートした配列 ・省スペース(文字列自身と配列1つ) X suffix array 0 BANa. Na 1 ANa. Na 2 Na. Na 3 a. Na 4 Na 5 a ソート I 1 0 4 2 5 3 ANa. Na BANa. Na Na Na. Na a a. Na 4


関連研究 • Bentley, Sedgewick 97 • Manber, Myers 93 6


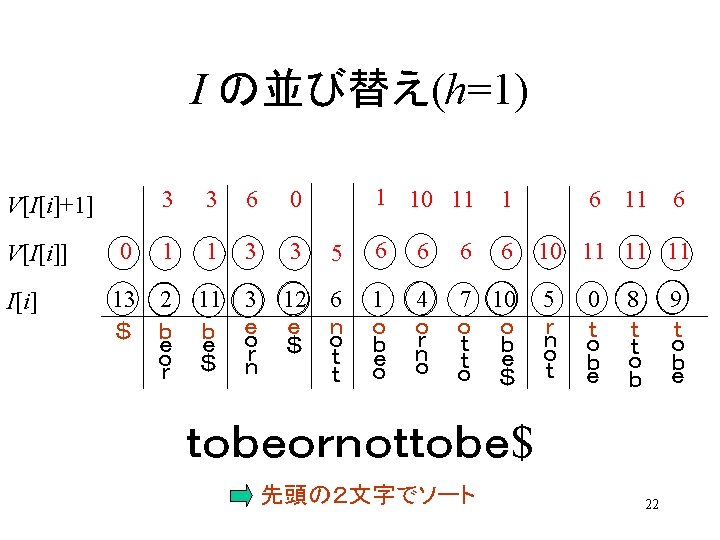
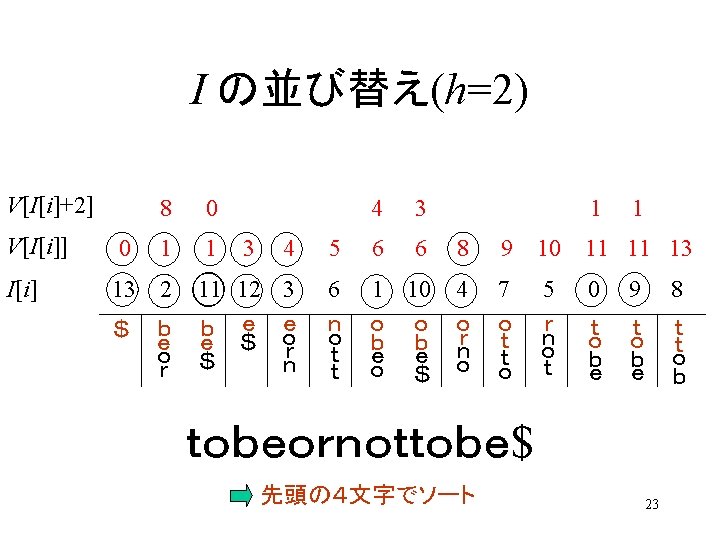
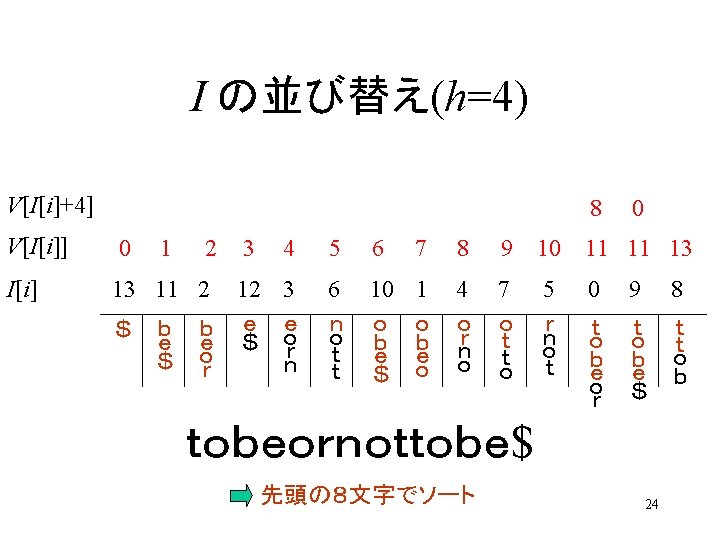
t obeor not t o b e $ 0 1 2 3 4 5 6 7 8 9101112 2 3 6 11 12 2 11 b 2 11 0589 6 r t 5 089 1 10 7 t b r 1 10 4 7 e 1 10 12 e $ o 2 11 12 3 $ o 1 4 7 10 n e 3 12 6 5 11 o 11 2 $ 8 o t 09 8 b 09 e 09 10 o 10 1 h=1 $ 9 o 9 0 h=2 h=3 h=4 8 h=5
 時間 実際は遅い 9")
Manber, Myers • • doubling techniqueを用いる Radixソート O(n log n) 時間 実際は遅い 9
![doubling technique [Karp, Miller, Rosenberg 72] • 長さ 1, 2, 4, 8, . .](http://slidetodoc.com/presentation_image/1463bb730db964831277321436a20ace/image-10.jpg "doubling technique [Karp, Miller, Rosenberg 72] • 長さ 1, 2, 4, 8, . .")
doubling technique [Karp, Miller, Rosenberg 72] • 長さ 1, 2, 4, 8, . . . の部分文字列に番号を割り当てる t obeor not t o b e $ 64124534664 1 2 0 h=1 9 5 1 3 6 8 4 710 9 5 1 2 0 h=2 11 7 2 4 8105 912116 1 3 0 h=4 12 7 2 4 8105 913116 1 3 0 h=8 10

Manber, Myers t 0 13 0 o b 1 2 211 1 1 e o 3 4 312 3 3 13 21112 0 1 1 3 1311 212 0 1 2 3 3 4 r 5 6 5 n 6 1 6 o 7 4 6 6 5 110 6 6 110 6 7 t t o b e $ 8 910111213 710 5 0 8 9 6 610111111 4 8 7 5 0 9 8 810111113 7 5 0 9 8 910111113 1311 212 3 6 110 4 7 5 9 0 8 0 1 2 3 4 5 6 7 8 910111213 h=1 h=2 h=4 h=8 11


ソートされた部分のスキップ t 0 13 o b e o 1 2 3 4 211 312 1 1 3 3 21112 3 1 1 3 4 1311 212 3 1 2 1311 212 3 r 5 6 n o 6 7 1 4 6 6 110 6 7 6 110 t t o b e $ 8 910111213 710 5 0 8 9 6 610111111 4 7 5 0 9 8 8 8 111113 4 7 5 0 9 8 8 9 1111 4 7 5 9 0 8 1112 h=1 h=2 h=4 h=8 13

Larsson, Sadakaneの方法 • 2つの方法を組合わせる – Bentley, Sedgewick – doubling technique 14
 時間(s) 7000 6000 新聞記事(109 M) 特許 (89 M)")
実験結果 Ultra 60 (メモリ 2 GB) 時間(s) 7000 6000 新聞記事(109 M) 特許 (89 M) Reuters (27 M) html (125 M) 5000 4000 3000 2000 1000 0 Larsson Sadakane B&S M&M Kurtz 15

t obeor not t o b e $ 0 1 2 3 4 5 6 7 8 9101112 0589 2 3 6 11 12 2 11 b 2 11 1 1 0 11 6 o e n 3 12 6 3 3 5 12 3 0 6 2 11 12 3 1 1 3 4 8 10 1 4 7 10 666 6 5 r 5 0 8 9 10 111111 1 10 7 1 10 11 1 10 4 7 6 6 8 9 4 3 11 2 10 1 6 7 t 0 h=1 6 8 0 9 11 1111 8 1 13 09 1111 9 8 h=2 9 0 11 12 16 h=4 h=8







Lの更新 X t o I 0 1 L 1 2 V 0 1 L-11 V 0 1 L-14 V 0 1 b e o 2 3 4 2 1 3 3 -3 1 3 4 r 5 1 5 n 6 4 6 2 5 6 o t t o b e $ 7 8 910111213 h=1 1 3 6 6 610111111 2 1 h=2 6 8 810111113 2 1 h=4 2 3 4 5 6 7 8 910111113 h=8 2 3 4 5 6 7 8 910111213 26



t obeor not t o b e $ 0 1 2 3 4 5 6 7 8 9101112 2 3 6 11 12 2 11 b 2 11 1 1 0 11 0589 6 o e n 3 12 6 3 3 5 12 3 0 6 2 11 12 3 1 1 3 4 8 10 1 4 7 10 666 6 5 r 5 0 8 9 10 111111 1 10 7 1 10 11 1 10 4 7 6 6 8 9 4 3 11 2 10 1 6 7 t 0 h=1 6 8 0 9 11 1111 8 1 13 09 1111 9 8 h=2 9 0 11 12 29 h=4 h=8


t o b e o r 0 1 2 3 4 5 I-1 211 312 -1 V 0 2 2 4 4 5 -1 211 -3 0 2 2 3 4 5 -11 0 1 2 3 4 5 -14 0 1 2 3 4 5 n o 6 7 1 4 9 9 110 7 7 t t o b e $ 8 910111213 710 -1 0 8 9 9 910131313 4 7 -1 0 9 -1 9 910121213 0 9 -1 6 7 8 910121213 h=1 h=2 h=4 h=8 6 7 8 910111213 31


")
必要メモリ • • Bentley, Sedgewick Manber, Myers Larsson, Sadakane Kurtz 5 n (8 n) 8 n 8 n >13 n 34

Suffix arrayのディスク上での構成 • Gonnet, Baeza-Yates, Snider 92 – diskはsequential accessのみ I/O (M: メモリサイズ, B: ページサイズ) • Crauser, Ferragina 98 – doubling algorithm + discarding I/O 35




![参考文献 [1] N. J. Larsson and K. Sadakane. Faster Suffix Sorting. Technical Report LU-CS-TR:](http://slidetodoc.com/presentation_image/1463bb730db964831277321436a20ace/image-40.jpg "参考文献 [1] N. J. Larsson and K. Sadakane. Faster Suffix Sorting. Technical Report LU-CS-TR:")
参考文献 [1] N. J. Larsson and K. Sadakane. Faster Suffix Sorting. Technical Report LU-CS-TR: 99 -214, LUNDFD 6/(NFCS 3140)/1 -20/(1999), Department of Computer Science, Lund University, Sweden, May 1999. http: //www. cs. lth. se/home/Jesper_Larsson/ [2] 伊東秀夫. 大規模テキストに対する Suffix Array の効率 的な構成法. SIGNL-129 -5, IPSJ, January 1999. 40
- Slides: 40