Substring Statistics Kyoji Umemura Kenneth Church Goal Words

Substring Statistics Kyoji Umemura Kenneth Church
")
Goal: Words Substrings (Anything you can do with words, we can do with substrings) • Haven’t achieved this goal Sound Bite – But we can do more with substrings than you might have thought • Review: – Using Suffix Arrays to compute Term Frequency and Document Frequency for All Substrings in a Corpus (Yamamoto & Church) – Tri-grams Million-grams Sound Bite • Tutorial: Make substring statistics look easy – Previous treatments are (a bit) inaccessible • Generalization: – Document Frequency (df) dfk (adaptation) • Applications – Word Breaking (Japanese & Chinese) – Term Extraction for Information Retrieval
 The chance of Two Noriegas is Closer to")
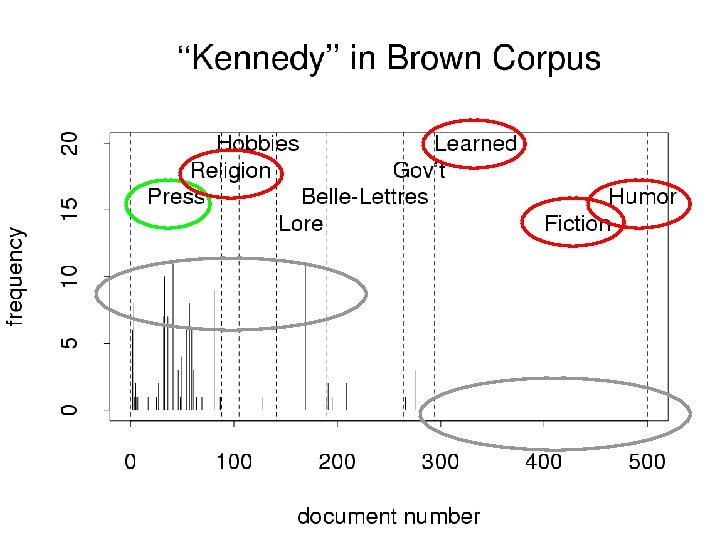
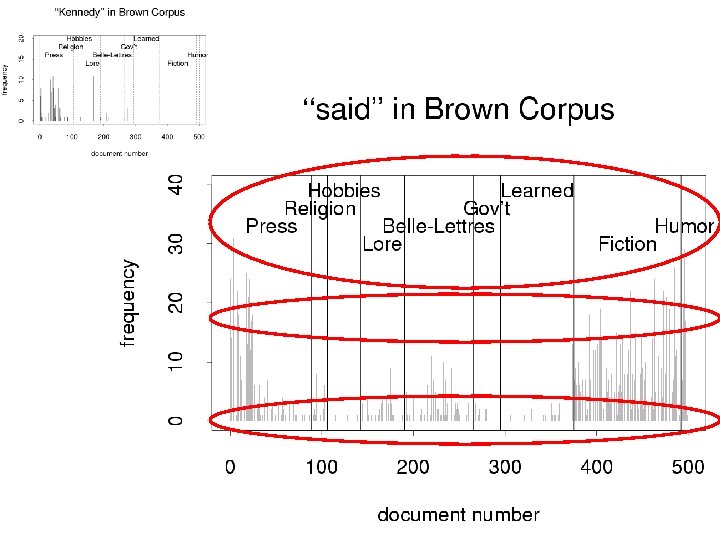
Motivation & Background: Unigrams Substrings (ngrams) The chance of Two Noriegas is Closer to p/2 than p 2: Implications for Language Modeling, Information Retrieval and Gzip • Standard indep models (Binomial, Multinomial, Poisson): – Chance of 1 st Noriega is p – Chance of 2 nd is also p • Repetition is very common – Ngrams/words (and their variant forms) appear in bursts – Noriega appears several times in a doc, or not at all. • Adaptation & Contagious probability distributions • Discourse structure (e. g. , text cohesion, given/new): – 1 st Noriega in a document is marked (more surprising) – 2 nd is unmarked (less surprising) • Empirically, we find first Noriega is surprising (p≈6/1000) – But chance of two is not surprising (closer to p/2 than p 2) • Finding a rare word like Noriega is like lightning – We might not expect lightning to strike twice in a doc – But it happens all the time, especially for good keywords • Documents ≠ Random Bags of Words
|")
Three Applications & Independence Assumptions: No Quantity Discounts • Compression: Huffman Coding – |encoding(s)| = ceil(−log 2 Pr(s)) – Two Noriegas consume twice as much space as one • |encoding(s s)| = |encoding(s)| + |encoding(s)| – No quantity discount • Indep is the worst case: any dependencies less H (space) • Information Retrieval – Score(query, doc) = ∑term in doc tf(term, doc) idf(term) • idf(term): inverse doc freq: −log 2 Pr(term) = −log 2 df(term)/D • tf(term, doc): number of instances of term in doc – Two Noriegas are twice as surprising as one (2 idf v. idf) – No quantity discount: any dependencies less surprise • Speech Recognition, OCR, Spelling Correction – I Noisy Channel O – Pr(I) Pr(O|I) – Pr(I) = Pr(w 1, w 2 … wn) ≈ ∏k Pr(wk|wk-2, wk-1) Log tf smoothing
 – Not bad")
Interestingness Metrics: Deviations from Independence • Poisson (and other indep assumptions) – Not bad for meaningless random strings • Deviations from Poisson are clues for hidden variables – Meaning, content, genre, topic, author, etc. • Analogous to mutual information (Hanks) – Pr(doctor…nurse) >> Pr(doctor) Pr(nurse)
 • Then")
• If we had a good description of the distribution: Pr(k) • Then we could compute any summary statistic – Moments: mean, var – Entropy: – Adaptation: Pr(k≥ 2|k ≥ 1)

Poisson Mixtures: More Poissons Better Fit (Interpretation: Each Poisson is conditional on hidden variables: meaning, content, genre, topic, author, etc. )

Adaptation: Three Approaches 1. Cache-based adaptation 2. Parametric Models – Poisson, Two Poisson, Mixtures (neg binomial) 3. Non-parametric – Pr(+adapt 1) ≡ Pr(test|hist) – Pr(+adapt 2) ≡ Pr(k≥ 2|k ≥ 1)

Positive & Negative Adaptation • Adaptation: – How do probabilities change as we read a doc? • Intuition: If a word w has been seen recently 1. +adapt: prob of w (and its friends) goes way up 2. −adapt: prob of many other words goes down a little • Pr(+adapt) >> Pr(prior) > Pr(−adapt)

Adaptation: Method 1 • Split each document into two equal pieces: – Hist: 1 st half of doc – Test: 2 nd half of doc Documents containing hostages in 1990 AP News • Task: – Given hist – Predict test • Compute contingency table for each word test hist 638 505 557 76, 787
 – df = a+b+c")
Adaptation: Method 1 • Notation – D = a+b+c+d (library) – df = a+b+c (doc freq) • Prior: • +adapt test hist a c d Documents containing hostages in 1990 AP News Pr(+adapt) >> Pr(prior) > Pr(−adapt) +adapt prior • −adapt b −adapt source 0. 56 0. 014 0. 0069 AP 1987 0. 56 0. 015 0. 0072 AP 1990 0. 59 0. 013 0. 0057 AP 1991 0. 39 0. 004 0. 0030 AP 1993

Priming, Neighborhoods and Query Expansion • Priming: doctor/nurse – Doctor in hist Pr(Nurse in test) ↑ • Find docs near hist (IR sense) – Neighborhood ≡ set of words in docs near hist (query expansion) • Partition vocabulary into three sets: 1. Hist: Word in hist 2. Near: Word in neighborhood − hist 3. Other: None of the above • Prior: • +adapt • Near • Other test hist a b c d test hist a near e b f other g h

Adaptation: Hist >> Near >> Prior • Magnitude is huge – p/2 >> p 2 – Two Noriegas are not much more surprising than one – Huge quantity discounts • Shape: Given/new – 1 st mention: marked • Surprising (low prob) • Depends on freq – 2 nd: unmarked • Less surprising • Independent of freq – Priming: • “a little bit” marked
 –")
Adaptation is Lexical • Lexical: adaptation is – Stronger for good keywords (Kennedy) – Than random strings, function words (except), etc. • Content ≠ low frequency +adapt prior −adapt source word 0. 27 0. 012 0. 0091 AP 90 Kennedy 0. 40 0. 015 0. 0084 AP 91 Kennedy 0. 32 0. 014 0. 0094 AP 93 Kennedy 0. 049 0. 016 AP 90 except 0. 048 0. 014 AP 91 except 0. 048 0. 012 AP 93 except
 • dfk(w) ≡ number of documents that –")
Adaptation: Method 2 • Pr(+adapt 2) • dfk(w) ≡ number of documents that – mention word w – at least k times • df 1(w) ≡ standard def of document freq (df)
 ≈ Pr(+adapt 2) Within factors of 2 -3 (as opposed to 10")
Pr(+adapt 1) ≈ Pr(+adapt 2) Within factors of 2 -3 (as opposed to 10 -1000) 3 rd mention Priming

Adaptation helps more than it hurts Hist is a great clue • Examples of big winners (Boilerplate) – Lists of major cities and their temperatures – Lists of major currencies and their prices – Lists of commodities and their prices – Lists of senators and how they voted • Examples of big losers Hist is misleading – Summary articles – Articles that were garbled in transmission
 • Applications: Japanese Morphology (text words) – Standard methods:")
Recent Work (with Kyoji Umemura) • Applications: Japanese Morphology (text words) – Standard methods: dictionary-based – Challenge: OOV (out of vocabulary) – Good keywords (OOV) adapt more than meaningless fragments • Poisson model: not bad for meaningless random strings • Adaptation (deviations from Poisson): great clues for hidden variables – OOV, good keywords, technical terminology, meaning, content, genre, author, etc. – Extend dictionary method to also look for substrings that adapt a lot • Practical procedure for counting dfk(s) for all substrings s in a large corpus (trigrams million grams) – Suffix array: standard method for computing freq and loc for all s – Yamamoto & Church (2001): count df for all s in large corpus • df (and many other ngram stats) for million-grams • Although there are too many substrings s to work with (n 2) – They can be grouped into a manageable number of equiv classes (n) – Where all substrings in a class share the same stats – Umemura (unpublished): generalize method for dfk • Adaptation for million-grams Today’s Talk
 – big quantity discounts 2.")
Adaptation Conclusions 1. Large magnitude (p/2 >> p 2) – big quantity discounts 2. Distinctive shape – – – 1 st mention depends on freq 2 nd does not Priming: between 1 st mention and 2 nd 3. Lexical: – – Independence assumptions aren’t bad for meaningless random strings, function words, common first names, etc. More adaptation for content words (good keywords, OOV)
")
We are here Substring Statistics Outline • Goal: Substring Statistics – Words Substrings (Ngrams) – Anything we do with words, • we should be able to do with substrings (ngrams)… – Stats • freq(str) and location (sufconc), • df(str), dfk(str), jdf(str 1, str 2) • and combinations thereof • Suffix Arrays & LCP • Classes: One str All strs – substrings N classes – Class(<i, j>) = { str | str starts every suffix in interval and no others } – Compute stats over classes N 2 • DFS Traversal of Class Tree • Cumulative Document frequency (cdfk) – freq = cdf 1 Sound – df. Bite k = cdfk – cdfk+1 • Neighbors • Cross Validation • Joint Document Freq – Sketches • Apps

Suffix Arrays: Text Freq & loc of all ngrams • Input: text, an array of N tokens – Null terminated – Tokens: words, bytes, Asian chars • Output: s, an array of N ints, sorted “lexicographically” • s[i] denotes a semi-infinite string – Text starting at position s[i] and continuing to end • s[i] ≡ substr(text, s[i]) ≡ text+s[i] • Simple Practical Procedure – Initialize for(i=0; i<N; i++) s[i] = i; – Sort “lexicographically” qsort(s, N, sizeof(*s), sufcmp); int sufcmp(int *a, int *b) { return strcmp(text + *a, text + *b); } Text
 • Sufconc(pattern) outputs")
Frequency & Location of All Ngrams (Unigrams, Bigrams, Trigrams & Million-grams) • Sufconc(pattern) outputs a concordance – – – Two binary searches → <i, j> i = first suffix in suffix array that starts with pattern j = last suffix in suffix array that starts with pattern Freq(<i, j>) = j – i + 1 Output j – i + 1 concordance lines, one for each suffix in <i, j> . /sufconc -l 10 -r 40 /cygdrive/d/temp 2/AP/AP 8912 'Manuel Noriega' | head 17913368 13789741 3966027 4938894 16718522 18568442 14794912 14434223 14237714 19901786 s[i] 5441: 4193: 1218: 1503: 5098: 5635: 4497: 4380: 4321: 6061: osed Gen. apprehend nian Gen. ed rulern to force oust Gen. that Gen. . ''n `` nian Gen. doc(s[i]) ^ ^ ^ ^ ^ Manuel Manuel Manuel Norieganin Panama _ their wives Noriegan The situation in Pana Noriega an$300, 000 present, and Noriega andnothers laundered $50 Noriega continue to evade U. S. fo Noriega fromnpower. n Further Noriega from power, the zoo's dir Noriega had been killed. n Mary Noriega had explicitly declared w Noriega in the hands of a special
 Time & O(N) Space •")
Suffix Arrays: Computational Complexity Bottom Line: O(N log N) Time & O(N) Space • Simple Practical Procedure – Initialize for(i=0; i<N; i++) s[i] = i; – Sort “lexicographically” qsort(s, N, sizeof(*s), sufcmp); int sufcmp(int *a, int *b) { return strcmp(text + *a, text + *b); } • You might think this takes O(N log N) time • But unfortunately, sufcmp is not O(1) – so the sort is O(N 2 log N) • Fortunately, there is an O(N log N) alg – See http: //www. cs. dartmouth. edu/~doug/ for excellent tutorial • But in practice, the simple procedure is often just as good – (if not slightly better)

Same as before, but tokens are now bytes rather than words


 • Peak ≈ 10 bytes (roughly word bigrams)")
Distribution of LCPs (1989 AP News) • Peak ≈ 10 bytes (roughly word bigrams) • Long tail (boilerplate & duplicate docs)
 – Anything we")
Substring Statistics Outline • Goal: Substring Statistics – Words Substrings (Ngrams) – Anything we do with words, • we should be able to do with substrings (ngrams)… – Stats • freq(str) and location (sufconc), • df(str), dfk(str), jdf(str 1, str 2) • and combinations thereof • Suffix Arrays & LCP • Classes: One str All strs – N 2 substrings N classes – Class(<i, j>) = { str | str starts every suffix in interval and no others } – Compute stats over classes We are here • Cumulative Document frequency (cdfk) • freq = cdf 1 • dfk = cdfk – cdfk+1 – Neighbors – Depth-First Traversal of Class Tree • Cross Validation • Joint Document Freq – Sketches • Apps

Distributional Equivalence • sufconc – Frequency and location for one substring – Impressive: trigrams million-grams • Challenge: One substring All substrings – Too many substrings: N 2 • Solution: group substrings into equiv classes – N 2 substrings N classes – str 1 = str 2 iff • Every suffix that starts with str 1 also starts with str 2 – Example: “to be or not to be” • “to” = “to be” – Class(<i, j>) = { str | str starts every suffix in interval and no others } – Compute stats over N classes • Rather than over N 2 substrings
")
Grouping Substrings into Classes • • Interval on Suffix Array: <i, j> Class(<i, j>) is a set of substrings that – Start every suffix within the interval • • – Class(<6, 7>) = {“b”, “be”} – Class(<17, 18>) = {“to”, “to_b”, “to_be”} – str 1 R str 2 ↔ str 1 & str 2 in same class Interpretation: distributional equivalence – “to” R “to be” → “to” and “to be” appear in exactly the same places in corpus And no suffixes outside the interval Examples: Classes form an equivalence relation R • R partitions the set of all substrings: – Every substring appears in one and only one class • R is reflexive, symmetric and transitive
, they can be")
Although there are too many substrings to work with (≈N 2), they can be grouped into a manageable number of classes Description Quantity Text the Corpus N tokens Suffix Array substr(text, i) N suffixes or less Substring substr(text, i, j) N 2 or less Interval on Suffix Array <i, j> ≡ { substr(text, k) | i≤k≤j } N 2 or less Class(<i, j>) { substrings str | str starts every suffix in <i, j>, and no others } N 2 or less Valid Class(<i, j>) ≠ { } 2 N or less Trivial Class i = j freq(<i, i>) = 1 N or less Interesting (Non-Trivial Valid) Class(<i, j>) ≠ { } & j > i N or less

171 Substrings 8 Non-Trivial Classes • Corpus: – N = 18 – to_be_or_not_to_be • Substrings: – Theory: • N ∙(N+1)/2 = 171 – 150 observed • 135 with freq=1 (yellow) • 15 with freq>1 (green) • Classes: – Theory: • 2 N = 36 (N trivial + N non-trivial) – 21 observed • 13 trivial (yellow) • 8 non-trivial (green)

Motivation for Grouping Substrings into Equivalence Classes • Computational Issues: – N is more manageable than N 2 • Statistics can be computed over classes – Because all substrings in a class have the same stats • for many popular stats: freq, dfk, joint df & contingency tables, and combinations thereof • Examples: (corpus = “to_be_or_not_to_be”) – Class(<6, 7>) = {“b”, “be”} • freq(“b”) = freq(“be”) = 7 -6+1 = 2 – Class(<17, 18>) = {“to”, “to_b”, “to_be”} • freq(“to”) = freq(“to_b”) = freq(“to_be”) = 18 -17+1 =2 – Class(<11, 14>) = {“o”} • freq(“o”) = 14 -11+1 = 4
 – Anything we")
Substring Statistics Outline • Goal: Substring Statistics – Words Substrings (Ngrams) – Anything we do with words, • we should be able to do with substrings (ngrams)… – Stats • freq(str) and location (sufconc), • df(str), dfk(str), jdf(str 1, str 2) • and combinations thereof • Suffix Arrays & LCP • Classes: One str All strs – substrings N classes – Class(<i, j>) = { str | str starts every suffix in interval and no others } – Compute stats over classes N 2 We are here • DFS Traversal of Class Tree • Cumulative Document frequency (cdfk) – freq = cdf 1 – dfk = cdfk – cdfk+1 • Neighbors • Cross Validation • Joint Document Freq – Sketches • Apps

Class Tree: Nesting of Valid Intervals

SIL = Shortest Interior LCP =1 LBL = Longest Bounding LCP =0 • Class(<i, j>) = {str | str starts every suffix within interval, and no others } = {substr(text + s[i], 1, k)} where LBL < k ≤ SIL • LCP[i] = Longest Common Prefix of s[i] & s[i+1] – SIL(<i, j>) = Shortest Interior LCP = MINi≤k<j { LCP[k] } – LBL(<i, j>) = Longest Bounding LCP = max(LCP[i], LCP[j]) • Class(<1, 5>) = {substr(“_be”, 1, k)} for 0 < k ≤ 1

Enumerating Classes • A class is uniquely determined by – Two endpoints: <i, j>, or – SIL & witness: i ≤ w ≤ j • To enumerate classes: – Enumerate 0≤w<N & LCP[w] – Remove duplicate classes • Two witnesses and their LCPs might specify the same class • Alternatively, depth first traversal of class tree – Output: <i, j> and SIL(<i, j>) struct stackframe { int i, j, SIL } *stack; int sp = 0; /* stack pointer */ stack[sp]. i = 0; stack[sp]. SIL = -1; for(w=0; w<N; w++) { if(LCP[w] > stack[sp]. SIL) { sp++; Push stack[sp]. i = w; stack[sp]. SIL = LCP[w]; } while(LCP[w] < stack[sp]. SIL) { stack[sp]. j = w; output(&stack[sp]); if(LCP[w] <= stack[sp-1]. SIL) sp--; else stack[sp]. SIL = LCP[w]; }} Pop
 Sorted first by j (increasing")
Depth-first traversal 1 Outputs <i, j> and SIL(<i, j>) Sorted first by j (increasing order) and then by i (decreasing order) 2 3 struct stackframe { int i, j, SIL } *stack; int sp = 0; /* stack pointer */ stack[sp]. i = 0; stack[sp]. SIL = -1; 4 5 6 7 6 8 8 2 3 1 4 5 7 for(w=0; w<N; w++) { if(LCP[w] > stack[sp]. SIL) { sp++; stack[sp]. i = w; stack[sp]. SIL = LCP[w]; } while(LCP[w] < stack[sp]. SIL) { stack[sp]. j = w; output(&stack[sp]); if(LCP[w] <= stack[sp-1]. SIL) sp--; else stack[sp]. SIL = LCP[w]; }}
 – Output: <i, j>,")
Find Class • Input: pattern (a substring such as “Norieg”) – Output: <i, j>, LBL, SIL, stats, Class(<i, j>) • Method: – Two binary searches into suffix array to find first (i) and last (j) suffix starting with input pattern – Third binary search into classes to find class and associated (precomputed) stats • Takes advantage of ordering on classes • (sorted first by j and then by i) Computed from i and j (first two binary searches) – LBL(<i, j>) = max(LCP[i], LCP[j]) Computed from class (third binary search) – SIL – dfk: # of documents that contain input pattern at least k times – Class(<i, j>) = { substr(text + s[i], i, k)} for LBL < k ≤ SIL
 – Anything we")
Substring Statistics Outline • Goal: Substring Statistics – Words Substrings (Ngrams) – Anything we do with words, • we should be able to do with substrings (ngrams)… – Stats • freq(str) and location (sufconc), • df(str), dfk(str), jdf(str 1, str 2) • and combinations thereof • Suffix Arrays & LCP • Classes: One str All strs – substrings N classes – Class(<i, j>) = { str | str starts every suffix in interval and no others } – Compute stats over classes N 2 • DFS Traversal of Class Tree • Cumulative Document frequency (cdfk) We are – freq = cdf 1 – dfk = cdfk – cdfk+1 • Neighbors • Cross Validation • Joint Document Freq – Sketches • Apps here
: 1. Hi_Ho_Hi_Ho 2. Hi_Ho 3. Hi Need a few docs to")
Corpus (3 docs): 1. Hi_Ho_Hi_Ho 2. Hi_Ho 3. Hi Need a few docs to talk about df
 • Document Frequency (df) – Number of documents that mention")
Cumulative Document Frequency (cdf) • Document Frequency (df) – Number of documents that mention str at least once – dfk ≡ number of documents that mention str at k times • Adaptation = Pr(k≥ 2 | k≥ 1) = df 2 / df 1 • Cumulative Document Frequency (cdf) cdfk ≡ cumulative doc freq = Σi≥k dfi • Can recover freq & dfk from cdfk freq = cdf 1 = j – i + 1 dfk = cdfk – cdfk+1 • A (simple but slow) method for computing cdfk cdf 1(<i, j>)=Σi≤w≤j 1 cdf 2(<i, j>)=Σi≤w≤j neighbor[w] ≥ i cdfk(<i, j>)=Σi≤w≤j neighbork-1[w] ≥ i
![Neighbors • doc(s) 1: D – (using binary search) • Neighbors[s 2] = s](http://slidetodoc.com/presentation_image_h2/673c16c6a6af91d854d70e12c9faba53/image-45.jpg "Neighbors • doc(s) 1: D – (using binary search) • Neighbors[s 2] = s")
Neighbors • doc(s) 1: D – (using binary search) • Neighbors[s 2] = s 1 – where doc(s 1) = doc(s 2) = d – and s 1 and s 2 are adjacent suffix s 3 such that doc(s 3) = d and s 1<s 3< s 2 – Neighbors[s 2] = NA if s 2 is first suffix in doc suffix s 1 such that doc(s 1) = doc(s 2) and s 1< s 2 • Neighbork[s] = Neighbork-1[Neighbor[s]], for k>1 • Neighbor 0[s] = s (identity)
![Simple (but slow) code for cdfk(<i, j>)=Σi≤w≤j neighbork-1[w] ≥ i struct class { int](http://slidetodoc.com/presentation_image_h2/673c16c6a6af91d854d70e12c9faba53/image-46.jpg "Simple (but slow) code for cdfk(<i, j>)=Σi≤w≤j neighbork-1[w] ≥ i struct class { int")
Simple (but slow) code for cdfk(<i, j>)=Σi≤w≤j neighbork-1[w] ≥ i struct class { int start, end, SIL }; struct class c; while(fread(&c, sizeof(c), 1, stdin)) { int cdfk = 0; for(w=c. start; w<=c. end; w++) /* returns neighbor^k(suf) or -1 if NA*/ int kth_neighbor(int suf, int k) if(kth_neighbor(w, K-1) >= c. start) cdfk++; { if(suf >= 0 || k >1) return kth_neighbor( neighbors[suf], k-1); else return suf; } putw(cdfk, out); /* report */ } Neighbork[s] = Neighbork-1[Neighbor[s]], for k>1
![Same as before (but folded into Depth-First Search) cdfk(<i, j>)=Σi≤w≤j neighbork-1[w] ≥ i struct](http://slidetodoc.com/presentation_image_h2/673c16c6a6af91d854d70e12c9faba53/image-47.jpg "Same as before (but folded into Depth-First Search) cdfk(<i, j>)=Σi≤w≤j neighbork-1[w] ≥ i struct")
Same as before (but folded into Depth-First Search) cdfk(<i, j>)=Σi≤w≤j neighbork-1[w] ≥ i struct stackframe { int start, SIL, cdfk } *stack; Neighbork[s] = Neighbork-1[Neighbor[s]], for k>1 for(sp 1=0; sp 1<=sp; sp 1++) { if(kth_neighbor(w, K-1) >= stack[sp 1]. start) stack[sp 1]. cdfk++; } while(LCP[w] < stack[sp]. SIL) { putw(stack[sp]. cdfk, out); Report /* returns neighbor^k(suf) or -1 if NA*/ int kth_neighbor(int suf, int k) { if(suf >= 0 || k >1) return kth_neighbor( neighbors[suf], k-1); else return suf; } for(w=0; w<N; w++) { if(LCP[w]> stack[sp]. SIL) { sp++; stack[sp]. start = w; stack[sp]. SIL = LCP[w]; stack[sp]. cdfk = 0; } if(LCP[w] <= stack[sp-1]. SIL) sp--; else stack[sp]. SIL = LCP[w]; }}

Results cdfk ≡ cum df = Σi≥k dfi freq = cdf 1 = j – i + 1 dfk = cdfk – cdfk+1 cdf 1(<i, j>)= Σi≤w≤j 1 = j – i + 1 cdf 2(<i, j>)= Σi≤w≤j neighbor[w] ≥ i cdfk(<i, j>)= Σi≤w≤j neighbork-1[w] ≥ i dfk ≥ dfk+1 and cdfk ≥ cdfk+1
![• Monotonicity 1. dfk ≥ dfk+1 2. cdfk ≥ cdfk+1 3. cdfk[mother] ≥](http://slidetodoc.com/presentation_image_h2/673c16c6a6af91d854d70e12c9faba53/image-49.jpg "• Monotonicity 1. dfk ≥ dfk+1 2. cdfk ≥ cdfk+1 3. cdfk[mother] ≥")
• Monotonicity 1. dfk ≥ dfk+1 2. cdfk ≥ cdfk+1 3. cdfk[mother] ≥ d daughters cdfk[d] Opportunity for speedup: Propagate counts up class tree
) code for cdfk struct stackframe { int start, SIL,")
Faster O(N max(k, log max(LCP)) code for cdfk struct stackframe { int start, SIL, cdfk } *stack; /* returns neighbor^k(suffix) or -1 if NA*/ int kth_neighbor(int suffix, int k) { int i, result = suffix; for(i=0; i < k && result >= 0; i++) result = neighbors[result]; return result; } /* return first stack frame not before suffix */ /* binary search works because stack is sorted */ Propagate counts up class tree N k int prev = kth_neighbor(w, K-1); if(prev >= 0) stack[find(prev)]. cdfk++; while(LCP[w] < stack[sp]. SIL) { putw(stack[sp]. cdfk, out); /* report */ if(LCP[w] <= stack[sp-1]. SIL) { stack[sp-1]. cdfk += stack[sp]. cdfk; sp--; } else stack[sp]. SIL = LCP[w]; }} log max(LCP) int find(int suffix) { int low = 0; int high = sp; while(low + 1 < high) { int mid = (low + high) / 2; if(stack[mid]. start <= suffix) low = mid; else high = mid; } if(stack[high]. start <= suffix) return high; if(stack[low]. start <= suffix) return low; fatal("can't get here"); } for(w=0; w<N; w++) { if(LCP[w]> stack[sp]. SIL) { sp++; stack[sp]. start = w; stack[sp]. SIL = LCP[w]; stack[sp]. cdfk = 0; }
 – Anything we")
Substring Statistics Outline • Goal: Substring Statistics – Words Substrings (Ngrams) – Anything we do with words, • we should be able to do with substrings (ngrams)… – Stats • freq(str) and location (sufconc), • df(str), dfk(str), jdf(str 1, str 2) • and combinations thereof • Suffix Arrays & LCP • Classes: One str All strs – N 2 substrings N classes – Class(<i, j>) = { str | str starts every suffix in interval and no others } – Compute stats over classes • DFS Traversal of Class Tree • Cumulative Document frequency (cdfk) – freq = cdf 1 – dfk = cdfk – cdfk+1 • Neighbors • Cross Validation • Joint Document Freq – Sketches • Apps We are here
![for(w=0; w<N; w++) { int half = (suffix[w] > N/2) ? 1 : 0;](http://slidetodoc.com/presentation_image_h2/673c16c6a6af91d854d70e12c9faba53/image-52.jpg "for(w=0; w<N; w++) { int half = (suffix[w] > N/2) ? 1 : 0;")
for(w=0; w<N; w++) { int half = (suffix[w] > N/2) ? 1 : 0; if(LCP[w]> stack[sp]. SIL) { sp++; stack[sp]. start = w; stack[sp]. SIL = LCP[w]; stack[sp]. cdfk = 0; } int prev = kth_neighbor(w, K-1); if(prev >= 0) stack[find(prev)]. cdfk[half]++; while(LCP[w] < stack[sp]. SIL) { putw(stack[sp]. cdfk[0], out[0]); putw(stack[sp]. cdfk[1], out[1]); if(LCP[w] <= stack[sp-1]. SIL) { stack[sp-1]. cdfk[0] += stack[sp]. cdfk[0]; stack[sp-1]. cdfk[1] += stack[sp]. cdfk[1]; sp--; } else stack[sp]. SIL = LCP[w]; }} Cross Validation • Code can be modified to compute cdfk for all substrings in two samples (1 st half and 2 nd half) • Let freq & dfk be the counts in the first half – freq* & dfk* be best estimates of freq & dfk in a similar corpus of similar size, etc. – Deleted Interpolation • 1 st half bin • 2 nd half calibrate

freq* depends on doc freq • Contrast – freq=df: • Government Spokesman – df=1: • European Monetary • Similar freq – But evidence for “government spokesman” comes from many documents – Whereas evidence for “European Monetary” comes from a single document • Prediction: – Indep sources more robust – More robust larger freq* • Less shrinking freq df 1 freq* n 10 10 7. 85 75, 288 10 9 8. 57 16, 284 10 8 7. 78 6, 602 10 7 7. 47 2, 755 10 6 6. 86 1, 669 10 5 6. 30 1, 543 10 4 4. 29 693 10 2 4. 42 509 10 3 3. 93 416 10 1 2. 87 282
 – Anything we")
Substring Statistics Outline • Goal: Substring Statistics – Words Substrings (Ngrams) – Anything we do with words, • we should be able to do with substrings (ngrams)… – Stats • freq(str) and location (sufconc), • df(str), dfk(str), jdf(str 1, str 2) • and combinations thereof • Suffix Arrays & LCP • Classes: One str All strs – substrings N classes – Class(<i, j>) = { str | str starts every suffix in interval and no others } – Compute stats over classes N 2 • DFS Traversal of Class Tree • Cumulative Document frequency (cdfk) – freq = cdf 1 – dfk = cdfk – cdfk+1 • Neighbors • Cross Validation • Joint Document Freq – Sketches • Apps We are here

Applications We can compute lots of stats for lots of substrings, But what good is it? • Ngram statistics are fundamental to (nearly) everything we do: • – Foundations of Statistical Natural Language processing – Language Modeling • • • – – • • Speech Recognition OCR Spelling Correction Compression Information Retrieval Word Breaking Term Extraction • • • – Managing Gigabytes • • Challenge: Establish value beyond – Standard corpus frequency and – Trigrams Bell, Cleary & Witten – Elements of Information Theory – More stats Adaptation (df 2 / df 1) Witten, Moffat & Bell – Text Compression Unigrams, …, million-grams, … – Huang, Acero & Hon Information Theory (Compression) • Standard Corpus Freq (freq) Doc freq (df) Generalized Doc Freq (dfk) Joint Doc Freq (jdf) Combinations thereof Jurafsky & Martin – Spoken Language Processing – All ngrams: • • • Manning & Schütze – Speech and Language Processing Contributions • General Overviews • • Cover & Thomas Speech – Statistical Methods for Speech Recognition • • Jelinek Information Retrieval (IR) – Automatic Text Processing • Salton

App: Word Breaking & Term Extraction Challenge: Establish value beyond standard corpus frequency and Trigrams • English – Kim Dae Jung before Presidency • Japanese – 大統領になる以前の 金大中 • Chinese –未上任前的金大中 • No spaces – in Japanese and Chinese • English has spaces – But… • Phrases: white house • NER (named entity recog) • Word Breaking – Dictionary-based (Cha. Sen) • Dynamic Programming • Fewest edges (dictionary entries) that cover input • Challenges for Dictionary – Out-of-Vocabulary (OOV) – Technical Terminology – Proper Nouns
 df")
Using Adaptation to Distinguish Terms from Random Fragments • Adaptation: Pr(k≥ 2|k≥ 1) df 2 / df 1 – Beyond standard corpus frequency • Null hypothesis – Poisson: df 2 / df 1 / D – Not bad for random fragments • OOV (and substrings thereof) – Adapt too much for null hypothesis (Poisson) – If an OOV word is mentioned once in a document, it will probably be mentioned again – Not true for random fragments

word boundary Using Adaptation to Reject Null Hypo Japanese English Gloss フジモリ Fujimori 大統領 President が <function word>

English Example Adaptation Doc Freq Baseline
 3. Select best")
Word Breaking Procedure 1. Generate candidate terms 2. Score candidates (Adaptation) 3. Select best (Viterbi Search) ABC AB ∙ C A ∙ BC A∙B∙C Score(ABC) Score(AB) + Score(C) Score(A) + Score(B) + Score(C)
 • Analogous")
White Space Recovery Task (Unsupervised: No Dictionary & No Labeled Training Data) • Analogous to Japanese Word Breaking • Input: English without white space But harder • Output: Attempt to recover white space Input Gold Standard Philadelphia. Electric. Co. receivedafederallicensetooperateits. Limerick No. 2 nuclearunitatfullpower. The. Nuclear. Regulatory. Commissionissu edthelicence. Thedecisionclearedasignificanthurdleforthe. No. 2 unit, w hichwascompletedaheadofscheduleand$300 millionunderbudget. Philadelphia Electric Co. received a federal license to operate its Limerick No. 2 nuclear unit at full power. The Nuclear Regulatory Commission issued the licence. The decision cleared a significant hurdle for the No. 2 unit, which was completed ahead of schedule and $300 million under budget.
 Supervision would")
White Space Recovery Task (Unsupervised: No Dictionary & No Labeled Training Data) Supervision would help • Analogous to Japanese Word Breaking (dictionaries and labeled training data) • Input: English without white space • Output: Attempt to recover white space Output Gold Standard Philadelphia. Electric Co. receiveda federal license tooperate its Limerick No. 2 nuclearuni tat fullpower. The Nuclear. Regulatory. Commission issued thelice nce. The decision clear eda significant hur dle forthe No. 2 unit , which was completed aheadofschedul eand $300 million under budget. Philadelphia Electric Co. received a federal license to operate its Limerick No. 2 nuclear unit at full power. The Nuclear Regulatory Commission issued the licence. The decision cleared a significant hurdle for the No. 2 unit, which was completed ahead of schedule and $300 million under budget.

Proposed Method >> Baselines Adaptation >> Frequency Proposed Frequency Baseline Adaptation Baseline

Applications We can compute lots of stats for lots of substrings, But what good is it? • Ngram statistics are fundamental to (nearly) everything we do: • – Foundations of Statistical Natural Language processing – Language Modeling • • • – – • • Speech Recognition OCR Spelling Correction Compression Information Retrieval Word Breaking Term Extraction • • • – Managing Gigabytes • • Challenge: Establish value beyond – Standard corpus frequency and – Trigrams Bell, Cleary & Witten – Elements of Information Theory – More stats Adaptation (df 2 / df 1) Witten, Moffat & Bell – Text Compression Unigrams, …, million-grams, … – Huang, Acero & Hon Information Theory (Compression) • Standard Corpus Freq (freq) Doc freq (df) Generalized Doc Freq (dfk) Joint Doc Freq (jdf) Combinations thereof Jurafsky & Martin – Spoken Language Processing – All ngrams: • • • Manning & Schütze – Speech and Language Processing Contributions • General Overviews • • Cover & Thomas Speech – Statistical Methods for Speech Recognition • • Jelinek Information Retrieval (IR) – Automatic Text Processing • Salton

Summary Goal: Words Substrings (Anything you can do with words, we can do with substrings) • Haven’t achieved this goal – But we can do more with substrings than you might have thought • Review: – Using Suffix Arrays to compute Term Frequency and Document Frequency for All Substrings in a Corpus (Yamamoto & Church) • Tutorial: Make substring statistics look easy – Previous treatments are (a bit) inaccessible • Generalization: – Document Frequency (df) dfk (adaptation) • Applications – Word Breaking (Japanese & Chinese) – Term Extraction for Information Retrieval

Programs cdfk ≡ cum df = Σi≥k dfi freq = cdf 1 = j – i + 1 dfk = cdfk – cdfk+1 • Suffix Arrays – create: text suffix array & LCP vector – sufconc: ngram pattern freq & location • Classes – create: text + suffix array + LCP <i, j> & SIL – find_class: ngram <i, j>, SIL, LBL & cdfk • Can estimate Pr(str) from leading terms of cdfk • Many popular stats are summaries of Pr(str) – mean, var (and other moments), entropy, adaptation = df 2 / df 1 • Extensions – Cross-Validation – Estimate Joint Doc Freq using Sketches • jdf(x, y) # of docs that contain both x & y
- Slides: 66