Structured Prediction A Large Margin Approach Ben Taskar

Structured Prediction: A Large Margin Approach Ben Taskar University of Pennsylvania Joint work with: V. Chatalbashev, M. Collins, C. Guestrin, M. Jordan, D. Klein, D. Koller, S. Lacoste-Julien, C. Manning

“Don’t worry, Howard. The big questions are multiple choice. ”

Handwriting Recognition x y brace Sequential structure

Object Segmentation x y Spatial structure

Natural Language Parsing x y The screen was a sea of red Recursive structure

Bilingual Word Alignment x y What is the anticipated cost of collecting fees under the new proposal? En vertu des nouvelles propositions, quel est le coût prévu de perception des droits? What is the anticipated cost of collecting fees under the new proposal ? Combinatorial structure En vertu de les nouvelles propositions , quel est le coût prévu de perception de les droits ?

Protein Structure and Disulfide Bridges AVITGACERDLQCG KGTCCAVSLWIKSV RVCTPVGTSGEDCH PASHKIPFSGQRMH HTCPCAPNLACVQT SPKKFKCLSK Protein: 1 IMT

Local Prediction brace Classify using local information Ignores correlations & constraints!

Local Prediction building tree shrub ground

Structured Prediction brace n n Use local information Exploit correlations

Structured Prediction building tree shrub ground
 Trees (CFGs) Associative Markov")
Outline n Structured prediction models n n n Sequences (CRFs) Trees (CFGs) Associative Markov networks (Special MRFs) Matchings Structured large margin estimation n n Margins and structure Min-max formulation Linear programming inference Certificate formulation

Structured Models scoring function space of feasible outputs Mild assumption: linear combination
 y a-z x *Lafferty et al. 01 a-z a-z")
Chain Markov Net (aka CRF*) y a-z x *Lafferty et al. 01 a-z a-z
 y a-z x *Lafferty et al. 01 a-z a-z")
Chain Markov Net (aka CRF*) y a-z x *Lafferty et al. 01 a-z a-z

Associative Markov Nets Point features spin-images, point height Edge features length of edge, edge orientation “associative” restriction j yj jk yk
 … #(PP IN NP) … #(NN ‘sea’)")
CFG Parsing #(NP DT NN) … #(PP IN NP) … #(NN ‘sea’)

Bilingual Word Alignment What is the anticipated cost of collecting fees under the new proposal ? k j En vertu de les nouvelles propositions , quel est le coût prévu de perception de le droits ? n n n position orthography association

Disulfide Bonds: Non-bipartite Matching RSCCPCYWGGCPWGQNCYPEGCSGPKV 1 1 2 3 4 6 2 3 5 1 2 4 5 3 6 Fariselli & Casadio `01, Baldi et al. ‘ 04 4 6 5

Scoring Function 2 RSCCPCYWGGCPWGQNCYPEGCSGPKV 1 2 3 4 5 4 6 RSCCPCYWGGCPWGQNCYPEGCSGPKV 1 3 6 6 n n 5 amino acid identities phys/chem properties

Structured Models scoring function space of feasible outputs Mild assumptions: linear combination sum of part scores
 Margin Likelihood")
Supervised Structured Prediction Model: Prediction Learning Data Estimate w Local (ignores structure) Margin Likelihood (intractable) Example: Weighted matching Generally: Combinatorial optimization
 Trees (CFGs) Associative Markov")
Outline n Structured prediction models n n n Sequences (CRFs) Trees (CFGs) Associative Markov networks (Special MRFs) Matchings Structured large margin estimation n n Margins and structure Min-max formulation Linear programming inference Certificate formulation

OCR Example n We want: “brace” n Equivalently: “brace” “aaaaa” “brace” “aaaab” … “brace” “zzzzz” a lot!

Parsing Example n We want: ‘It was red’ n S A B C D Equivalently: ‘It was red’ S A B C D … ‘It was red’ S A B D F ‘It was red’ S A B C D ‘It was red’ S E F G H a lot!

Alignment Example n We want: ‘What is the’ ‘Quel est le’ n 1 2 3 Equivalently: ‘What is the’ 1 2 ‘Quel est le’ 3 1 2 3 ‘What is the’ 2 ‘Quel est le’ 3 1 1 2 3 ‘What is the’ 1 2 ‘Quel est le’ 3 1 2 3 ‘What is the’ ‘Quel est le’ 1 2 3 … a lot!

Structured Loss b b ‘It was red’ c r r r 0 1 2 3 S A B C D S A E C D S B D A C S B E A C a o o a r r c c e e 2 2 1 0 0 ‘What is the’ ‘Quel est le’ 1 2 3 1 1 2 3 2 1 2 3

Large margin estimation n Given training examples n Maximize margin n Mistake weighted margin: , we want: # of mistakes in y *Collins 02, Altun et al 03, Taskar 03

Large margin estimation n Eliminate n Add slacks for inseparable case

Large margin estimation n Brute force enumeration n Min-max formulation n ‘Plug-in’ linear program for inference
: Inference LP Inference Key step: discrete optim. continuous optim.")
Min-max formulation Structured loss (Hamming): Inference LP Inference Key step: discrete optim. continuous optim.
 Trees (CFGs) Associative Markov")
Outline n Structured prediction models n n n Sequences (CRFs) Trees (CFGs) Associative Markov networks (Special MRFs) Matchings Structured large margin estimation n n Margins and structure Min-max formulation Linear programming inference Certificate formulation

y z Map for Markov Nets a 1 0 0 b 0 1 1 : : : z 0 0 0 a 0 1. 0 0 0. 0 b 0 0. 0 1 0. 0 0 1. 0 : . . z 0 0 0 0 a b. z . . 0

Markov Net Inference LP 0 1 0 0 0 1 0 0 0 0 normalization agreement Has integral solutions z for chains, trees Can be fractional for untriangulated networks

Associative MN Inference LP “associative” restriction 0 1 0 0 n n 0 1 0 0 For K=2, solutions are always integral (optimal) For K>2, within factor of 2 of optimal

CFG Chart n CNF tree = set of two types of parts: n n Constituents (A, s, e) CF-rules (A B C, s, m, e)

CFG Inference LP root inside outside Has integral solutions z

Matching Inference LP What is the anticipated cost of collecting fees under the new proposal ? k j En vertu de les nouvelles propositions , quel est le coût prévu de perception de le droits ? degree Has integral solutions z

LP Duality n Linear programming duality n n n Variables constraints Constraints variables Optimal values are the same n When both feasible regions are bounded

Min-max Formulation LP duality

Min-max formulation summary n Formulation produces concise QP for n n n Low-treewidth Markov networks Associative MNs (K=2) Context free grammars Bipartite matchings Approximate for untriangulated MNs, AMNs with K>2 *Taskar et al 04

Unfactored Primal/Dual QP duality Exponentially many constraints/variables

Factored Primal/Dual By QP duality Dual inherits structure from problem-specific inference LP Variables correspond to a decomposition of variables of the flat case

The Connection b b b 1 c r r r a o o a r r c c r. 8 a. 6 c. 65 e c. 2 o. 4 r. 35 e e 1 2 2 1 0 . 2. 15. 25. 4
")
Duals and Kernels n Kernel trick works: n n Factored dual Local functions (log-potentials) can use kernels

Alternatives: Perceptron n Simple iterative method n Unstable for structured output: fewer instances, big updates n n n May not converge if non-separable Noisy Voted / averaged perceptron [Freund & Schapire 99, Collins 02] n Regularize / reduce variance by aggregating over iterations

Alternatives: Constraint Generation n n Add most violated constraint Handles more general loss functions Only polynomial # of constraints needed Need to re-solve QP many times Worst case # of constraints larger than factored [Collins 02; Altun et al, 03; Tsochantaridis et al, 04]

Length: ~8 chars Letter: 16 x 8 pixels 10 -fold Train/Test 5000/50000 letters 600/6000 words Test error (average per-character) Handwriting Recognition 30 raw pixels quadratic kernel cubic kernel better 25 20 15 Models: 10 Multiclass-SVMs* 45% error reduction over linear CRFs 5 CRFs 33% error reduction over multiclass SVMs 3 M nets 0 MC–SVMs *Crammer & Singer 01 CRFs M^3 nets

Hypertext Classification n Web. KB dataset n n n Four CS department websites: 1300 pages/3500 links Classify each page: faculty, course, student, project, other Train on three universities/test on fourth better relaxed dual loopy belief propagation *Taskar et al 02 53% error reduction over SVMs 38% error reduction over RMNs

3 D Mapping Data provided by: Michael Montemerlo & Sebastian Thrun Laser Range Finder GPS IMU Label: ground, building, tree, shrub Training: 30 thousand points Testing: 3 million points



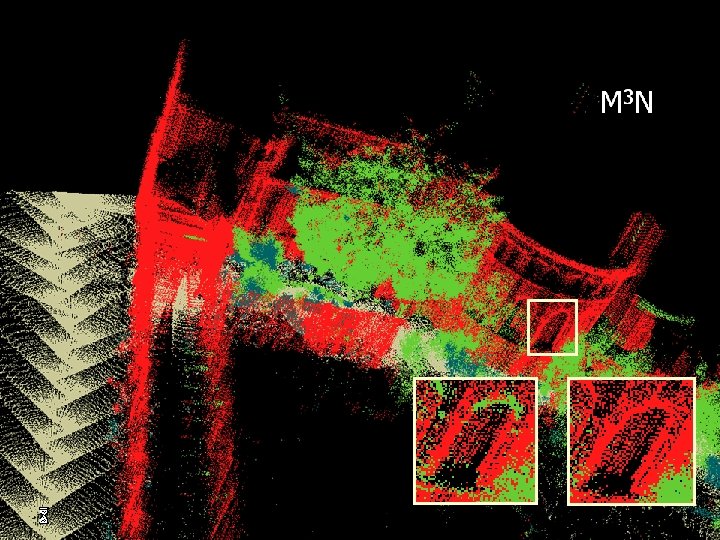

Segmentation results Hand labeled 180 K test points Model Accuracy SVM 68% V-SVM 73% M 3 N 93%

Fly-through
![Word Alignment Results Data: [Hansards – Canadian Parliament] Features induced on 1 mil unsupervised](http://slidetodoc.com/presentation_image_h2/10dc8840ebcae6a4f6eafa5d44e56904/image-57.jpg "Word Alignment Results Data: [Hansards – Canadian Parliament] Features induced on 1 mil unsupervised")
Word Alignment Results Data: [Hansards – Canadian Parliament] Features induced on 1 mil unsupervised sentences Trained on 100 sentences (10, 000 edges) Tested on 350 sentences (35, 000 edges) Model *Error Local learning+matching 10. 0 Our approach 8. 5 GIZA/IBM 4 [Och & Ney 03] 6. 5 +Local learning+matching 5. 4 +Our approach 4. 9 +Our approach+QAP 4. 5 [Taskar+al 05] *Error: weighted combination of precision/recall [Lacoste-Julien+Taskar+al 06]
 Trees (CFGs) Associative Markov")
Outline n Structured prediction models n n n Sequences (CRFs) Trees (CFGs) Associative Markov networks (Special MRFs) Matchings Structured large margin estimation n n Margins and structure Min-max formulation Linear programming inference Certificate formulation

Certificate formulation n Non-bipartite matchings: n n n 4 6 No polynomial-size LP known Simple certificate of optimality Verifying optimality easier than optimizing Compact optimality condition of 5 kl ij Intuition: n 3 1 Spanning trees n n O(n 3) combinatorial algorithm No polynomial-size LP known 2 wrt.

Certificate for non-bipartite matching 2 3 Alternating cycle: n Every other edge is in matching Augmenting alternating cycle: n 1 4 6 5 Score of edges not in matching greater than edges in matching Negate score of edges not in matching n Augmenting alternating cycle = negative length alternating cycle Matching is optimal Edmonds ‘ 65 no negative alternating cycles

Certificate for non-bipartite matching 2 Pick any node r as root = length of shortest alternating path from r to j 3 1 4 6 5 Triangle inequality: Theorem: No negative length cycle distance function d exists Can be expressed as linear constraints: O(n) distance variables, O(n 2) constraints

Certificate formulation n Formulation produces compact QP for n n n Spanning trees Non-bipartite matchings Any problem with compact optimality condition *Taskar et al. ‘ 05
![Disulfide Bonding Prediction Data [Swiss Prot 39] n n 450 sequences (4 -10 cysteines)](http://slidetodoc.com/presentation_image_h2/10dc8840ebcae6a4f6eafa5d44e56904/image-63.jpg "Disulfide Bonding Prediction Data [Swiss Prot 39] n n 450 sequences (4 -10 cysteines)")
Disulfide Bonding Prediction Data [Swiss Prot 39] n n 450 sequences (4 -10 cysteines) Features: n n windows around C-C pair physical/chemical properties Model *Acc Local learning+matching 41% Recursive Neural Net [Baldi+al’ 04] 52% Our approach (certificate) 55% *Accuracy: % proteins with all correct bonds [Taskar+al 05]

Formulation summary n Brute force enumeration n Min-max formulation n n ‘Plug-in’ convex program for inference Certificate formulation n Directly guarantee optimality of

Omissions n Kernels n n Structured generalization bounds n n Non-parametric models Bounds on hamming loss Scalable algorithms (no QP solver needed) n Structured SMO (works for chains, trees) [Taskar 04] n Structured Exp. Grad (works for chains, trees) [Bartlett+al 04] n Structured Extra. Grad (works for matchings, AMNs) [Taskar+al 06]

Open questions n Statistical consistency n n n Learning with approximate inference n n Hinge loss not consistent for non-binary output [See Tewari & Bartlett 05, Mc. Allester 07] Does constant factor approximate inference guarantee anything about learning? No [See Kulesza & Pereira 07] Perhaps other assumptions needed Discriminative structure learning n Using sparsifying priors

Conclusion n Two general techniques for structured large-margin estimation n Exact, compact, convex formulations n Allow efficient use of kernels n Tractable when other estimation methods are not n Efficient learning algorithms n Empirical success on many domains

References Y. Altun, I. Tsochantaridis, and T. Hofmann. Hidden Markov support vector machines. ICML 03. M. Collins. Discriminative training methods for hidden Markov models: Theory and experiments with perceptron algorithms. EMNLP 02 K. Crammer and Y. Singer. On the algorithmic implementation of multiclass kernel-based vector machines. JMLR 01 J. Lafferty, A. Mc. Callum, and F. Pereira. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. ICML 04 n More papers at http: //www. cis. upenn. edu/~taskar


Modeling First Order Effects Monotonicity n n Local inversion Local fertility QAP NP-complete Sentences ( 30 words, 1 k vars) few seconds (Mosek) Learning: use LP relaxation Testing: using LP, 83. 5% sentences, 99. 85% edges integral

Segmentation Model Min-Cut Local evidence 0 1 Spatial smoothness Computing is hard in general, but if edge potentials attractive min-cut algorithm Multiway-cut for multiclass case use LP relaxation [Greig+al 89, Boykov+al 99, Kolmogorov & Zabih 02, Taskar+al 04]

Scalable Algorithms n Batch and online Linear in the size of the data n Iterate until convergence n n For each example in the training sample n n n Run inference using current parameters (varies by method) Online: Update parameters using computed example values Batch: Update parameters using computed sample values Structured SMO (Taskar et al, 03; Taskar 04) Structured Exponentiated Gradient (Bartlett et al, 04) Structured Extragradient (Taskar et al, 05)
 Generative baselines n n")
Experimental Setup n n Standard Penn treebank split (2 -21/22/23) Generative baselines n n Discriminative n n Klein & Manning 03 and Collins 99 Basic = max-margin version of K&M 03 Lexical & Lexical + Aux Lexical features (on constituent parts only) ts-1 [ts … te] te+1 predicted tags xs-1 [xs … xe] xe+1 Auxillary features n n Flat classifier using same features Prediction of K&M 03 on each span

Results for sentences ≤ 40 words Model LP LR F 1 Generative 86. 37 85. 27 85. 82 Lexical+Aux* 87. 56 86. 85 87. 20 Collins 99* 85. 33 85. 94 85. 73 *Trained only on sentences ≤ 20 words *Taskar et al 04

Example The Egyptian president said he would visit Libya today to resume the talks. Generative model: Libya today is base NP Lexical model: today is a one word constituent
- Slides: 75