STRING Protein networks from data and text mining








































































- Slides: 81
STRING Protein networks from data and text mining Lars Juhl Jensen
9. 6 million proteins
functional associations
guilt by association
genomic context
gene fusion
Korbel et al. , Nature Biotechnology, 2004
phylogenetic profiles
Korbel et al. , Nature Biotechnology, 2004
experimental data
gene coexpression
physical interactions
Jensen & Bork, Science, 2008
curated knowledge
protein complexes
pathways
Letunic & Bork, Trends in Biochemical Sciences, 2008
many databases
different formats
different identifiers
variable quality
not comparable
hard work
parsers
mapping files
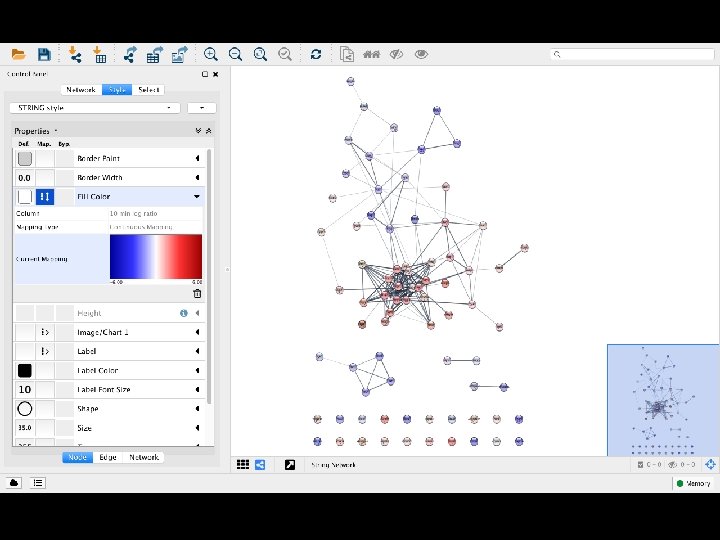
quality scores
von Mering et al. , Nucleic Acids Research, 2005
score calibration
von Mering et al. , Nucleic Acids Research, 2005
implicit weighting by quality
common scale
missing most of the data
>10 km
too much to read
computer
as smart as a dog
teach it specific tricks
named entity recognition
comprehensive lexicon
cyclin dependent kinase 1
CDC 2
orthographic variation
spaces and hyphens
cyclin dependent kinase 1
cyclin-dependent kinase 1
prefixes and suffixes
CDC 2
h. Cdc 2
“black list”
SDS
co-mentioning
counting
within documents
within paragraphs
within sentences
quality scores
score calibration
integration
visualization
string-db. org Szklarczyk et al. , Nucleic Acids Research, 2015
web resource
download files
REST API
Bioconductor package
Cytoscape App
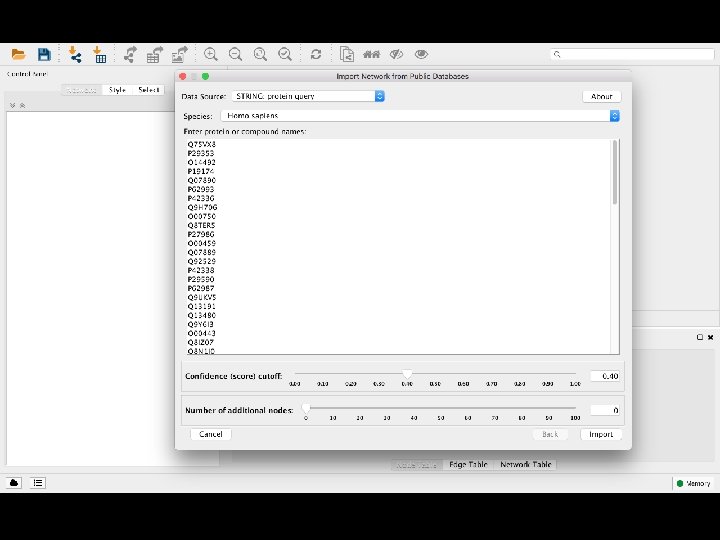
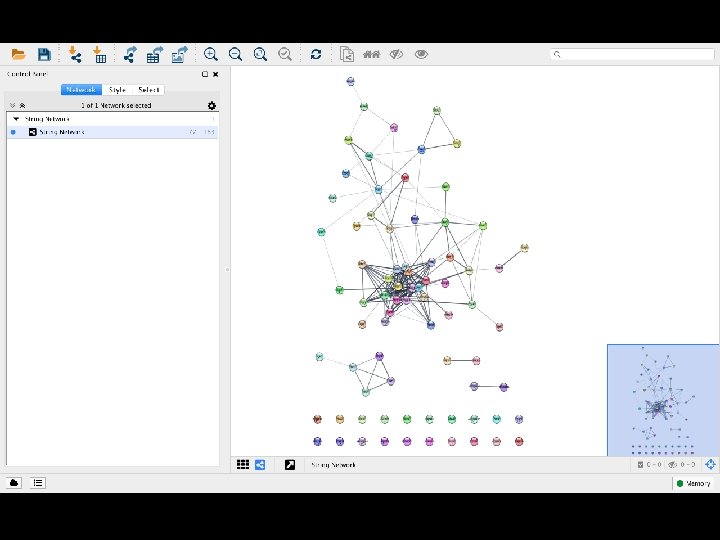
protein query
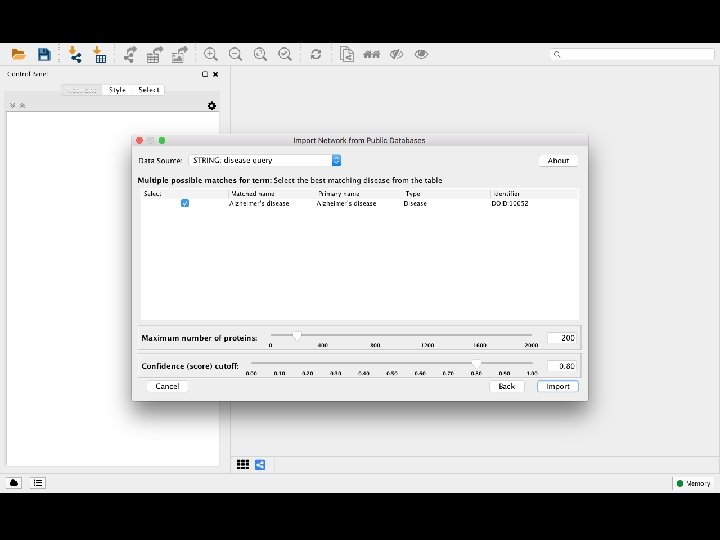
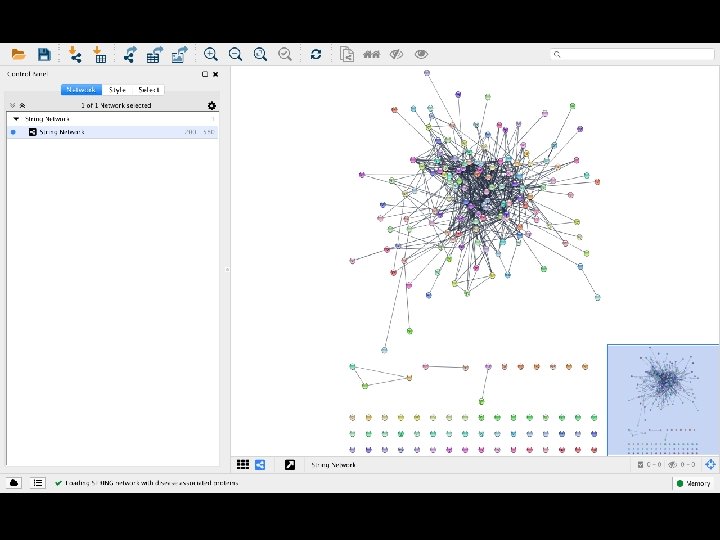
disease query
Acknowledgments Damian Szklarczyk John "Scooter" Morris Helen Cook Michael Kuhn Stefan Wyder Milan Simonovic Alberto Santos Nadezhda Doncheva Alexander Roth Peer Bork Christian von Mering