Statistics for Microarrays Normalization Review and Cluster Analysis






, e. g. to (attempt to)")






 clusters •")




")
 that a cancer taxonomy can")
 • 7 controls")




 • Which genes (variables) are")
 • Which genes (variables) are")
 • At least k")
 • Which genes (variables) are")


 are used • Which samples")
 hierarchical clustering")
 hierarchical clustering")
 are used Which samples are")




 are used Which samples")




- Slides: 46
Statistics for Microarrays Normalization Review and Cluster Analysis Class web site: http: //statwww. epfl. ch/davison/teaching/Microarrays/
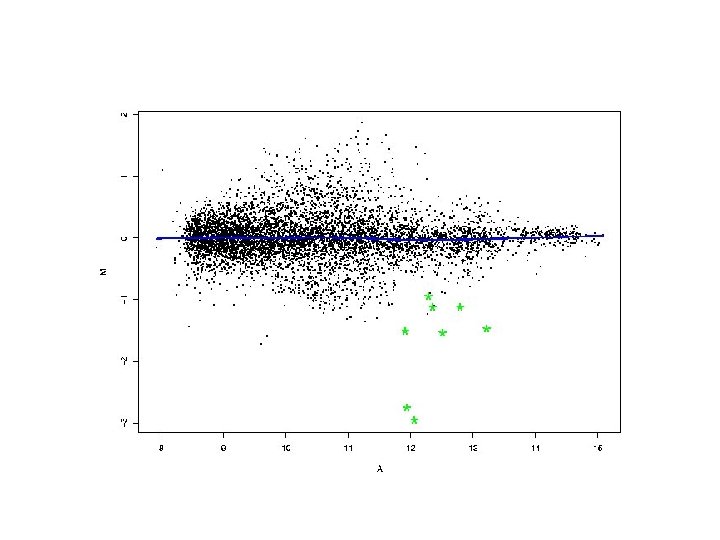
Normalization Methods • Global adjustment (e. g. median or mean for a set of genes) • Intensity-dependent -- shift M by c=c(A); e. g. c(A) made with lowess • Within print-tip group normalization to correct for spatial bias • Both print-tip and intensity-dependent adjustment: perform LOWESS fits to the data within print-tip groups
Print-tip-group normalization
Normalization: Which Spots to use? The LOWESS lines can be run through many different sets of points, and each strategy has its own implicit set of assumptions justifying its applicability. For example, the use of a global LOWESS approach can be justified by supposing that, when stratified by m. RNA abundance, a) only a minority of genes are expected to be differentially expressed, or b) any differential expression is as likely to be upregulation as down-regulation. Pin-group LOWESS requires stronger assumptions: that one of the above applies within each pin-group. The use of other sets of genes, e. g. control or housekeeping genes, involve similar assumptions.
Pre-processed c. DNA Gene Expression Data On p genes for n slides: p is O(10, 000), n is O(10 -100), but growing, Slides Genes 1 2 3 4 5 slide 1 slide 2 slide 3 slide 4 slide 5 … 0. 46 -0. 10 0. 15 -0. 45 -0. 06 0. 30 0. 49 0. 74 -1. 03 1. 06 0. 80 0. 24 0. 04 -0. 79 1. 35 1. 51 0. 06 0. 10 -0. 56 1. 09 0. 90 0. 46 0. 20 -0. 32 -1. 09 . . . . Gene expression level of gene 5 in slide 4 = Log 2( Red intensity / Green intensity) These values are conventionally displayed on a red (>0) yellow (0) green (<0) scale.
Cluster analysis • Used to find groups of objects when not already known • “Unsupervised learning” • Associated with each object is a set of measurements (the feature vector) • Aim is to identify groups of similar objects on the basis of the observed measurements
Clustering Gene Expression Data • Can cluster genes (rows), e. g. to (attempt to) identify groups of coregulated genes • Can cluster samples (columns), e. g. to identify tumors based on profiles • Can cluster both rows and columns at the same time
Clustering Gene Expression Data • Leads to readily interpretable figures • Can be helpful for identifying patterns in time or space • Useful (essential? ) when seeking new subclasses of samples • Can be used for exploratory purposes
Similarity • Similarity sij indicates the strength of relationship between two objects i and j • Usually 0 ≤ sij ≤ 1 • Correlation-based similarity ranges from – 1 to 1
Problems using correlation
Dissimilarity and Distance • Associated with similarity measures sij bounded by 0 and 1 is a dissimilarity dij = 1 - sij • Distance measures have the metric property (dij +dik ≥ djk) • Many examples: Euclidean, Manhattan, etc. • Distance measure has a large effect on performance • Behavior of distance measure related to scale of measurement
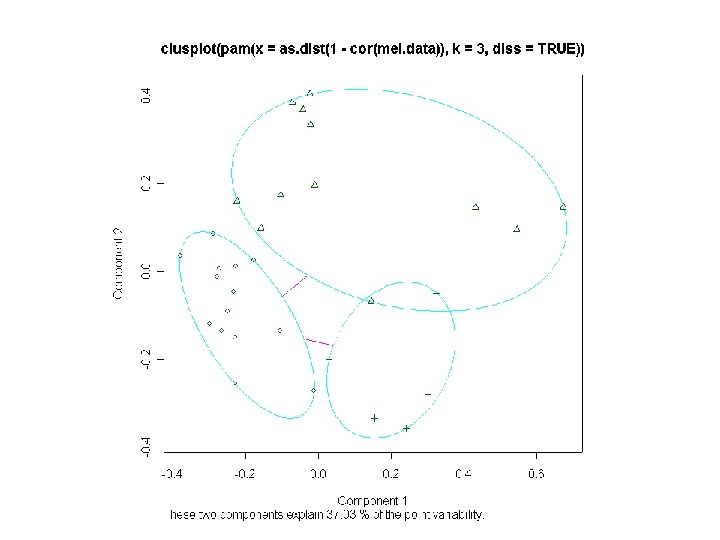
Partitioning Methods • Partition the objects into a prespecified number of groups K • Iteratively reallocate objects to clusters until some criterion is met (e. g. minimize within cluster sums of squares) • Examples: k-means, partitioning around medoids (PAM), self-organizing maps (SOM), model-based clustering
Hierarchical Clustering • Produce a dendrogram • Avoid prespecification of the number of clusters K • The tree can be built in two distinct ways: – Bottom-up: agglomerative clustering – Top-down: divisive clustering
Agglomerative Methods • Start with n m. RNA sample (or G gene) clusters • At each step, merge the two closest clusters using a measure of between-cluster dissimilarity which reflects the shape of the clusters • Examples of between-cluster dissimilarities: – Unweighted Pair Group Method with Arithmetic Mean (UPGMA): average of pairwise dissimilarities – Single-link (NN): minimum of pairwise dissimilarities – Complete-link (FN): maximum of pairwise dissimilarities
Divisive Methods • Start with only one cluster • At each step, split clusters into two parts • Advantage: Obtain the main structure of the data (i. e. focus on upper levels of dendrogram) • Disadvantage: Computational difficulties when considering all possible divisions into two groups
Partitioning vs. Hierarchical • Partitioning – Advantage: Provides clusters that satisfy some optimality criterion (approximately) – Disadvantages: Need initial K, long computation time • Hierarchical – Advantage: Fast computation (agglomerative) – Disadvantages: Rigid, cannot correct later for erroneous decisions made earlier
Generic Clustering Tasks • Estimating number of clusters • Assigning each object to a cluster • Assessing strength/confidence of cluster assignments for individual objects • Assessing cluster homogeneity
Estimating Number of Clusters
(BREAK)
Bittner et al. It has been proposed (by many) that a cancer taxonomy can be identified from gene expression experiments.
Dataset description • 31 melanomas (from a variety of tissues/cell lines) • 7 controls • 8150 c. DNAs • 6971 unique genes • 3613 genes ‘strongly detected’
This is why you need to take logs!
After logging…
How many clusters are present?
Average linkage hierarchical clustering, melanoma only 1 -r =. 54 unclustered ‘cluster’
Issues in Clustering • Pre-processing (Image analysis and Normalization) • Which genes (variables) are used • • Which samples are used Which distance measure is used Which algorithm is applied How to decide the number of clusters K
Issues in Clustering • Pre-processing (Image analysis and Normalization) • Which genes (variables) are used • • Which samples are used Which distance measure is used Which algorithm is applied How to decide the number of clusters K
Filtering Genes • All genes (i. e. don’t filter any) • At least k (or a proportion p) of the samples must have expression values larger than some specified amount, A • Genes showing “sufficient” variation – a gap of size A in the central portion of the data – a interquartile range of at least B • Filter based on statistical comparison – t-test – ANOVA – Cox model, etc.
Issues in Clustering • Pre-processing (Image analysis and Normalization) • Which genes (variables) are used • Which samples are used • Which distance measure is used • Which algorithm is applied • How to decide the number of clusters K
Average linkage hierarchical clustering, melanoma only unclustered ‘cluster’
Average linkage hierarchical clustering, melanoma & controls unclustered ‘cluster’ control
Issues in clustering • Pre-processing • Which genes (variables) are used • Which samples are used • Which distance measure is used • Which algorithm is applied • How to decide the number of clusters K
Complete linkage (FN) hierarchical clustering
Single linkage (NN) hierarchical clustering
Issues in clustering • • Pre-processing Which genes (variables) are used Which samples are used Which distance measure is used • Which algorithm is applied • How to decide the number of clusters K
Divisive clustering, melanoma only
Divisive clustering, melanoma & controls
Partitioning methods K-means and PAM, 2 groups Bittner K-means PAM 1 1 1 # samples 10 1 1 1 2 2 1 1 2 2 2 1 2 1 2 0 1 8 1 0 6 5
Bittner 1 K-means 1 PAM 1 # samples 11 1 1 2 1 2 6 1 2 2 2 4 2 2 2 3 3 1 1 2 4 1 3 3 3
Issues in clustering • • • Pre-processing Which genes (variables) are used Which samples are used Which distance measure is used Which algorithm is applied • How to decide the number of clusters K
How many clusters K? • Many suggestions for how to decide this! • Milligan and Cooper (Psychometrika 50: 159179, 1985) studied 30 methods • Some new methods include GAP (Tibshirani ) and clest (Fridlyand Dudoit) • Applying several methods yielded estimates of K = 2 (largest cluster has 27 members) to K = 8 (largest cluster has 19 members)
Average linkage hierarchical clustering, melanoma only unclustered cluster
Summary • Buyer beware – results of cluster analysis should be treated with GREAT CAUTION and ATTENTION TO SPECIFICS, because… • Many things can vary in a cluster analysis • If covariates/group labels are known, then clustering is usually inefficient
Acknowledgements IPAM Group, UCLA: Debashis Ghosh Erin Conlon Dirk Holste Steve Horvath Lei Li Henry Lu Eduardo Neves Marcia Salzano Xianghong Zhao Others: Sandrine Dudoit Jane Fridlyand Jose Correa Terry Speed William Lemon Fred Wright