Statistical tests for Quantitative variables ztest ttest Correlation
 BY Dr. Shaikh Shaffi Ahamed")
Statistical tests for Quantitative variables (z-test, t-test & Correlation) BY Dr. Shaikh Shaffi Ahamed Ph. D. , Associate Professor Dept. of Family & Community Medicine College of Medicine, King Saud University
 Able to understand the factors to apply for the")
Objectives: n n n (1) Able to understand the factors to apply for the choice of statistical tests in analyzing the data. (2) Able to apply appropriately Z-test, student’s t-test & Correlation (3) Able to interpret the findings of the analysis using these three tests.

Choosing the appropriate Statistical test n Based on the three aspects of the data Type of variables n Number of groups being compared & n Sample size n
 Outcome variable: Quantitative Comparison: (i)sample mean with")
Statistical Tests Z-test: Study variable: Qualitative (Categorical) Outcome variable: Quantitative Comparison: (i)sample mean with population mean (ii)two sample means Sample size: larger in each group(>30) & standard deviation is known

Steps for Hypothesis Testing Formulate H 0 and H 1 Select Appropriate Test Choose Level of Significance Calculate Test Statistic TSCAL (1)Determine Critical Value TSCR (3) Determine Prob Assoc with Test Stat (2) Determine if TSCL falls into (Non) Rejection Region (4) Compare with Level of Significance, Reject/Do not Reject H 0 Draw Research Conclusion
: • The education department at a university")
Example( Comparing Sample mean with Population mean): • The education department at a university has been accused of “grade inflation” in medical students with higher GPAs than students in general. • GPAs of all medical students should be compared with the GPAs of all other (non-medical) students. – There are 1000 s of medical students, far too many to interview. – How can this be investigated without interviewing all medical students ?

What we know: • The average GPA for all other students is 2. 70. This value is a parameter. • To the right is the statistical information for a random sample of medical students: = 2. 70 = 3. 00 s= 0. 70 n= 117
 and")
Questions to ask: • Is there a difference between the parameter (2. 70) and the statistic (3. 00)? • Could the observed difference have been caused by random chance? • Is the difference real (significant)?
 is the same as the pop. mean (2.")
1. The sample mean (3. 00) is the same as the pop. mean (2. 70). – The difference is trivial and caused by random chance. 2. The difference is real (significant). – Medical students are different from all other students.

Step 1: Make Assumptions and Meet Test Requirements • Random sampling – Hypothesis testing assumes samples were selected using random sampling. – In this case, the sample of 117 cases was randomly selected from all medical students. • Level of Measurement is Ratio scale – GPA is measured on ration scale, so the mean is an appropriate statistic. • Sampling Distribution is normal in shape – This is a “large” sample (n≥ 100).

Step 2 State the Null Hypothesis • H 0: μ== – We can state Ho: No difference between the sample mean and the population parameter – (In other words, the sample mean of 3. 0 really the same as the population mean of 2. 7 – the difference is not real but is due to chance. ) – The sample of 117 comes from a population that has a GPA of 2. 7. – The difference between 2. 7 and 3. 0 is trivial and caused by random chance.
 State the Alternative Hypothesis • H 1: μ≠ – Or")
Step 2 (cont. ) State the Alternative Hypothesis • H 1: μ≠ – Or H 1: There is a difference between the sample mean and the population parameter – The sample of 117 comes a population that does not have a GPA of 2. 7. In reality, it comes from a different population. – The difference between 2. 7 and 3. 0 reflects an actual difference between medical students and other students. – Note that we are testing whether the population the sample comes from is from a different population or is the same as the general student population.

Step 3 Select Sampling Distribution and Establish the Critical Region • Sampling Distribution= Z – Alpha (α) =. 05 – α is the indicator of “rare” events. – Any difference with a probability less than α is rare and will cause us to reject the H 0.
 Select Sampling Distribution and Establish the Critical Region • Critical")
Step 3 (cont. ) Select Sampling Distribution and Establish the Critical Region • Critical Region begins at Z= ± 1. 96 – This is the critical Z score associated with α =. 05, two-tailed test. – If the obtained Z score falls in the Critical Region, or “the region of rejection, ” then we would reject the H 0.

When the Population σ is not known, use the following formula:

Test the Hypotheses • Substituting the values into the formula, we calculate a Z score of 4. 62.

Two-tailed Hypothesis Test When α =. 05, then. 025 of the area is distributed on either side of the curve in area (C ) The. 95 in the middle section represents no significant difference between the population and the sample mean. The cut-off between the middle section and +/-. 025 is represented by a Z-value of +/- 1. 96.

Step 5 Make a Decision and Interpret Results • The obtained Z score fell in the Critical Region, so we reject the H 0. – If the H 0 were true, a sample outcome of 3. 00 would be unlikely. – Therefore, the H 0 is false and must be rejected. • Medical students have a GPA that is significantly different from the non-medical students (Z = 4. 62, p< 0. 05).

Summary: • The GPA of medical students is significantly different from the GPA of non-medical students. • In hypothesis testing, we try to identify statistically significant differences that did not occur by random chance. • In this example, the difference between the parameter 2. 70 and the statistic 3. 00 was large and unlikely (p <. 05) to have occurred by random chance.

Comparison of two sample means Example : Weight Loss for Diet vs Exercise Did dieters lose more fat than the exercisers? Diet Only: sample mean = 5. 9 kg sample standard deviation = 4. 1 kg sample size = n = 42 standard error = SEM 1 = 4. 1/ Ö 42 = 0. 633 Exercise Only: sample mean = 4. 1 kg sample standard deviation = 3. 7 kg sample size = n = 47 standard error = SEM 2 = 3. 7/ Ö 47 = 0. 540 measure of variability = [(0. 633)2 + (0. 540)2] = 0. 83

Example : Weight Loss for Diet vs Exercise Step 1. Determine the null and alternative hypotheses. Null hypothesis: No difference in average fat lost for two methods. Sample mean difference is zero. Alternative hypothesis: There is a difference in average fat lost in sample for two methods. Sample mean difference is not zero. Step 2. Sampling distribution: Normal distribution (z-test) Step 3. Assumptions of test statistic ( sample size > 30 in each group) Step 4. Collect and summarize data into a test statistic. The sample mean difference = 5. 9 – 4. 1 = 1. 8 kg and the standard error of the difference is 0. 83. So the test statistic: z = 1. 8 – 0 = 2. 17 0. 83

Example : Weight Loss for Diet vs Exercise Step 5. Determine the p-value. Recall the alternative hypothesis was two-sided. p-value = 2 [proportion of bell-shaped curve above 2. 17] Z-test table => proportion is about 2 0. 015 = 0. 03. Step 6. Make a decision. The p-value of 0. 03 is less than or equal to 0. 05, so … • If really no difference between dieting and exercise as fat loss methods, would see such an extreme result only 3% of the time, or 3 times out of 100. • Prefer to believe truth does not lie with null hypothesis. We conclude that there is a statistically significant difference between average fat loss for the two methods.
 Outcome variable: Quantitative Comparison: (i)sample mean with")
Student’s t-test: Study variable: Qualitative ( Categorical) Outcome variable: Quantitative Comparison: (i)sample mean with population mean (ii)two means (independent samples) (iii)paired samples Sample size: each group <30 ( can be used even for large sample size)
 Whether the")
Student’s t-test 1. Test for single mean (Student’s t-test for single mean) Whether the sample mean is equal to the predefined population mean ? 2. Test for difference in means ( Student’s t-test for independent samples) Whether the CD 4 level of patients taking treatment A is equal to CD 4 level of patients taking treatment B ? 3. Test for paired observation ( Student’s t-test for dependent samples) Whether the treatment conferred any significant benefit ?

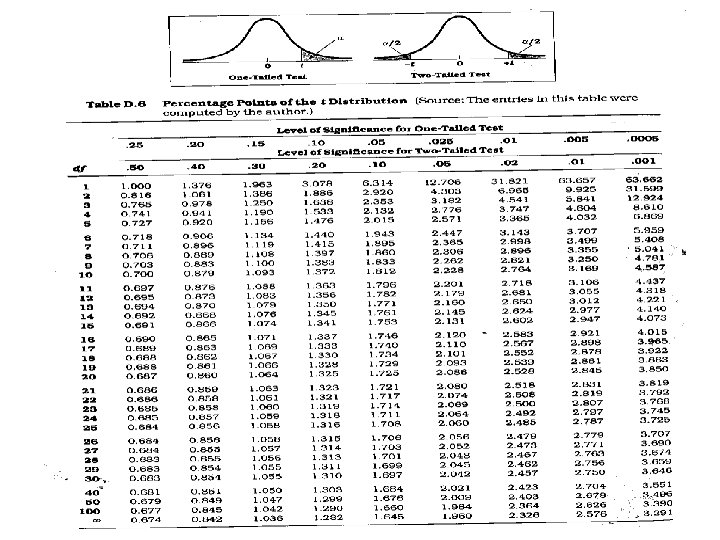
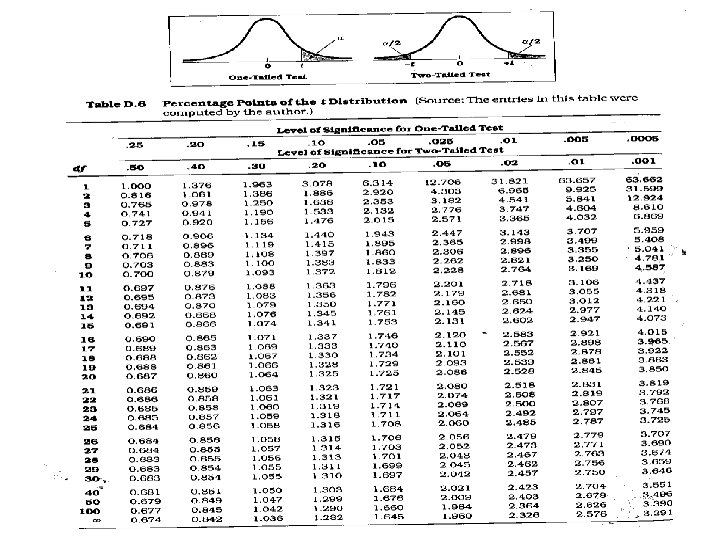
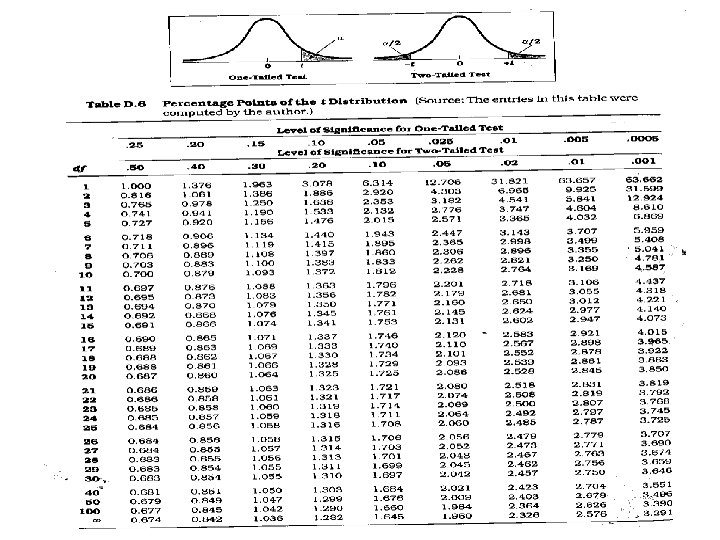
Steps for test for single mean 1. Questioned to be answered Is the Mean weight of the sample of 20 rats is 24 mg? N=20, =21. 0 mg, sd=5. 91 , =24. 0 mg 2. Null Hypothesis The mean weight of rats is 24 mg. That is, The sample mean is equal to population mean. 3. Test statistics 4. Comparison with theoretical value if tab t (n-1) < cal t (n-1) reject Ho, if tab t (n-1) > cal t (n-1) accept Ho, Inference 5. --- t (n-1) df

t –test for single mean • Test statistics n=20, =21. 0 mg, sd=5. 91 , =24. 0 mg t = t. 05, 19 = 2. 093 Accept H 0 if t < 2. 093 Reject H 0 if t >= 2. 093 Inference : We reject Ho, and conclude that the data is not providing enough evidence, that the sample is taken from the population with mean weight of 24 gm

t-test for difference in means Given below are the 24 hrs total energy expenditure (MJ/day) in groups of lean and obese women. Examine whether the obese women’s mean energy expenditure is significantly higher ? . Lean 6. 1 7. 5 7. 9 8. 1 10. 9 7. 0 7. 5 5. 5 7. 6 8. 1 8. 4 10. 2 8. 8 9. 7 11. 5 Obese 9. 2 9. 7 11. 8 9. 2 10. 0 12. 8

Null Hypothesis Obese women’s mean energy expenditure is equal to the lean women’s energy expenditure. Data Summary lean Obese N 13 9 8. 10 10. 30 S 1. 38 1. 25

Solution • • • H 0: m 1 - m 2 = 0 (m 1 = m 2) H 1: m 1 - m 2 ¹ 0 (m 1 ¹ m 2) = 0. 05 df = 13 + 9 - 2 = 20 Critical Value(s): Reject H 0 . 025 -2. 086 0 2. 086 t

Calculating the Test Statistic: Compute the Test Statistic: _ t = _ (X 1 - X 2) -(m 1 - m 2) n 1 n 2 Hypothesized Difference (usually zero when testing for equal means) df = n + n - 2 1 2 SP = (n 1 - 1) × (n 1 -1) + ( n 2 - 1) 2 S 1 + (n 2 -1 ) ×S 22 2

Developing the Pooled -Variance t Test • Calculate the Pooled Sample Variances as an Estimate of the Common Populations Variance: = Pooled-Variance = Variance of Sample 1 = Variance of sample 2 = Size of Sample 1 = Size of Sample 2

First, estimate the common variance as a weighted average of the two sample variances using the degrees of freedom as weights SP 2 n 1 - 1)× + (n 2 - 1) × S 2 ( = (n 1 - 1)+ (n 2 - 1 ) 2 (13 - 1)× 1. 38 2 + (9 - 1) × 125. = 1. 765 = ( 13 - 1)+(9 - 1) 2 S 1 2
- (m")
Calculating the Test Statistic: t = ( X 1 - X 2 )- (m 1 - m 2) =| 8. 1 2 SP n 1 n 2 176. | - 10. 3 - 0 1 + 1 13 9 tab t 9+13 -2 =20 dff = t 0. 05, 20 =2. 086 = 3. 82
 is higher")
T-test for difference in means Inference : The cal t (3. 82) is higher than tab t at 0. 05, 20. ie 2. 086. This implies that there is a evidence that the mean energy expenditure in obese group is significantly (p<0. 05) higher than that of lean group

Example Suppose we want to test the effectiveness of a program designed to increase scores on the quantitative section of the Graduate Record Exam (GRE). We test the program on a group of 8 students. Prior to entering the program, each student takes a practice quantitative GRE; after completing the program, each student takes another practice exam. Based on their performance, was the program effective?

• Each subject contributes 2 scores: repeated measures design Student Before Program After Program 1 520 555 2 490 510 3 600 585 4 620 645 5 580 630 6 560 550 7 610 645 8 480 520
 between")
• Can represent each student with a single score: the difference (D) between the scores Before Program After Program Student D 1 520 555 35 2 490 510 20 3 600 585 -15 4 620 645 25 5 580 630 50 6 560 550 -10 7 610 645 35 8 480 520 40

• Approach: test the effectiveness of program by testing significance of D • Null hypothesis: There is no difference in the scores of before and after program • Alternative hypothesis: program is effective → scores after program will be higher than scores before program → average D will be greater than zero H 0: µ D = 0 H 1: µ D > 0

So, need to know ∑D and ∑D 2: Student Before Program After Program D D 2 1 520 555 35 1225 2 490 510 20 400 3 600 585 -15 225 4 620 645 25 625 5 580 630 50 2500 6 560 550 -10 100 7 610 645 35 1225 8 480 520 40 1600 ∑D = 180 ∑D 2 = 7900

Recall that for single samples: For related samples: where: and

Mean of D: Standard deviation of D: Standard error:

Under H 0, µD = 0, so: From Table B. 2: for α = 0. 05, one-tailed, with df = 7, t critical = 1. 895 2. 714 > 1. 895 → reject H 0 The program is effective.

Z- value & t-Value “Z and t” are the measures of: How difficult is it to believe the null hypothesis? High z & t values Difficult to believe the null hypothesis accept that there is a real difference. Low z & t values Easy to believe the null hypothesis have not proved any difference.

Karl Pearson Correlation Coefficient
 As Age As Height As Age As duration of")
Working with two variables (parameter) As Age As Height As Age As duration of HIV BP Weight Cholesterol CD 4 CD 8

A number called the correlation measures both the direction and strength of the linear relationship between two related sets of quantitative variables.

Correlation Contd…. § Types of correlation – § Positive – Variables move in the same direction § § § Examples: Height and Weight Age and BP

Correlation contd… § Negative Correlation § Variables move in opposite direction § Examples: § Duration of HIV/AIDS and CD 4 CD 8 § Price and Demand § Sales and advertisement expenditure

Correlation contd…. . § Measurement of correlation 1. Scatter Diagram 2. Karl Pearson's coefficient of Correlation

Graphical Display of Relationship § Scatter diagram § Using the axes – X-axis horizontally – Y-axis vertically – Both axes meet: origin of graph: 0/0 – Both axes can have different units of measurement – Numbers on graph are (x, y)

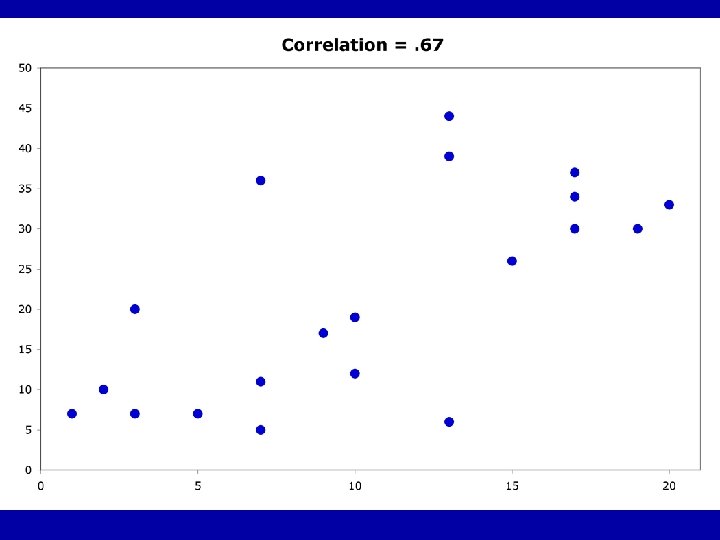
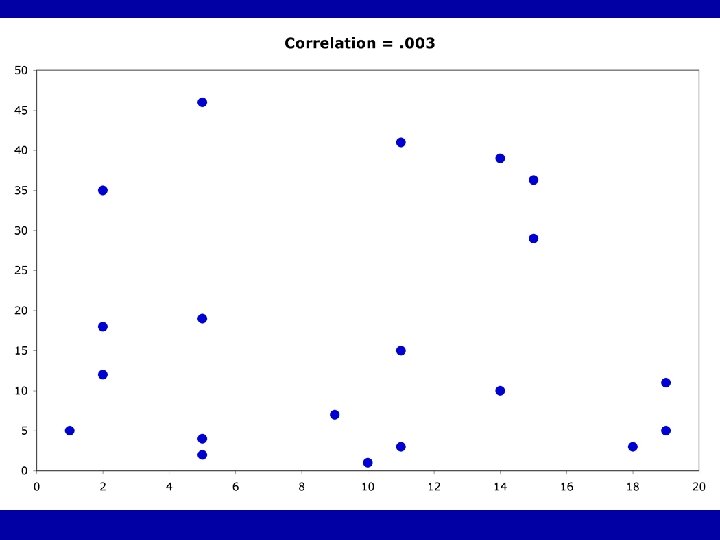
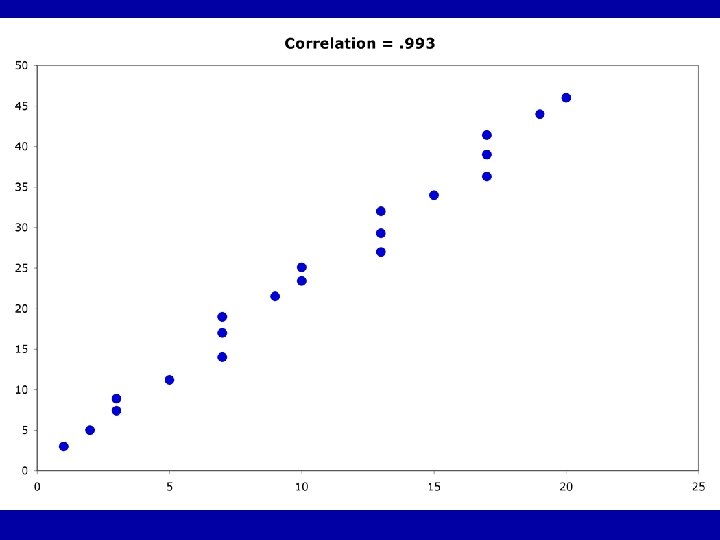
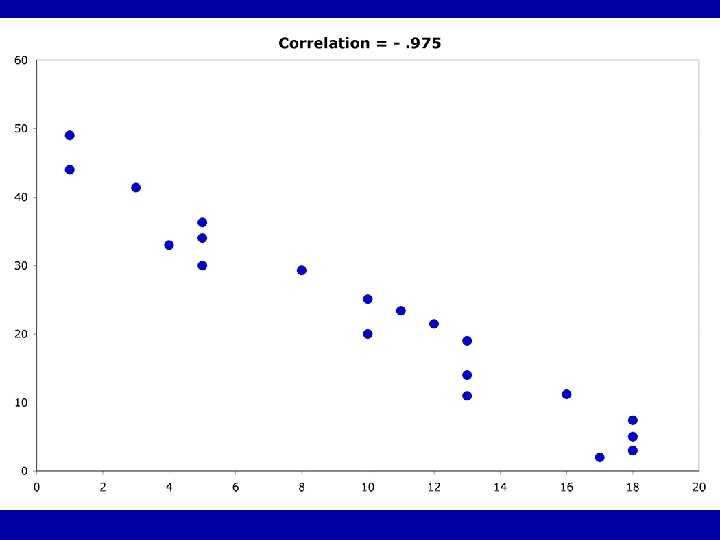
Guess the Correlations: . 67 . 993 . 003 -. 975
![The Pearson r (SC) (SU) SCU r = [ SC 2 N ][ (SC)2](http://slidetodoc.com/presentation_image_h/0585b64110dcbeb2776bed349e026c88/image-59.jpg "The Pearson r (SC) (SU) SCU r = [ SC 2 N ][ (SC)2")
The Pearson r (SC) (SU) SCU r = [ SC 2 N ][ (SC)2 N SU 2 ] (SU)2 N

We Need: § § § Sum of the Xs SC Sum of the Ys SU Sum of the Xs squared Sum of the Ys squared Sum of the squared Xs Sum of the squared Ys (SC)2 (SU)2 SC 2 SU 2 § Sum of Xs times the Ys § Number of Subjects (N) SCU

Example: A sample of 6 children was selected, data about their age in years and weight in kilograms was recorded as shown in the following table. Find the correlation between age and weight. serial No Age (years) Weight (Kg) 1 7 12 2 6 8 3 8 12 4 5 10 5 6 11 6 9 13
 (x) Weight (Kg) (y) xy X 2 Y 2 1")
Serial n. Age (years) (x) Weight (Kg) (y) xy X 2 Y 2 1 7 12 84 49 144 2 6 8 48 36 64 3 8 12 96 64 144 4 5 10 50 25 100 5 6 11 66 36 121 6 9 13 117 81 169 Total ∑x= 41 ∑y= 66 ∑xy= 461 ∑x 2= 291 ∑y 2= 742

r = 0. 759 strong direct correlation
 Test score (Y) 10 8")
EXAMPLE: Relationship between Anxiety and Test Scores Anxiety (X) Test score (Y) 10 8 2 1 5 6 ∑X = 32 2 100 4 20 3 64 9 24 9 4 81 18 7 1 49 7 6 25 36 30 5 36 25 30 ∑Y = 32 ∑X 2 = 230 ∑Y 2 = 204 ∑XY=129 X 2 Y 2 XY

Calculating Correlation Coefficient r = - 0. 94 Indirect strong correlation
 provides a quantitative way to express the degree")
Correlation Coefficient a correlation coefficient (r) provides a quantitative way to express the degree of linear relationship between two variables. • Range: r is always between -1 and 1 • Sign of correlation indicates direction: - high with high and low with low -> positive - high with low and low with high -> negative - no consistent pattern -> near zero • Magnitude (absolute value) indicates strength (-. 9 is just as strong as. 9). 10 to. 40 weak. 40 to. 80 moderate. 80 to. 99 high 1. 00 perfect

About “r” § r is not dependent on the units in the problem § r ignores the distinction between explanatory and response variables § r is not designed to measure the strength of relationships that are not approximately straight line § r can be strongly influenced by outliers

Correlation Coefficient: Limitations 1. Correlation coefficient is appropriate measure of relation only when relationship is linear 2. Correlation coefficient is appropriate measure of relation when equal ranges of scores in the sample and in the population. 3. Correlation doesn't imply causality – – – Using U. S. cities a cases, there is a strong positive correlation between the number of churches and the incidence of violent crime Does this mean churches cause violent crime, or violent crime causes more churches to be built? More likely, both related to population of city (3 d variable -- lurking or confounding variable)

Ice-cream sales are strongly correlated with crime rates. Therefore, ice-cream causes crime.

Without proper interpretation, causation should not be assumed, or even implied.
 and quantitative outcome variables.")
In conclusion ! Z-test will be used for both categorical(qualitative) and quantitative outcome variables. Student’s t-test will be used for only quantitative outcome variables. Correlation will be used to quantify the linear relationship between two quantitative variables
- Slides: 71