SQL Study Left Outer Join SELECT tblnamelist no

SQL Study
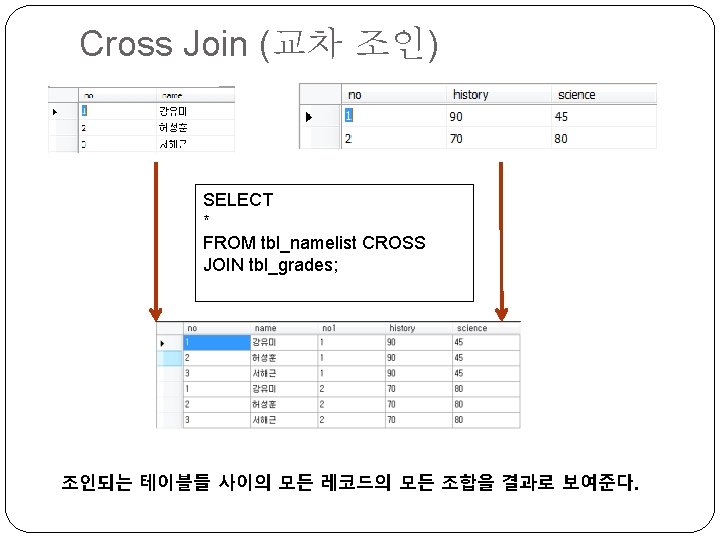
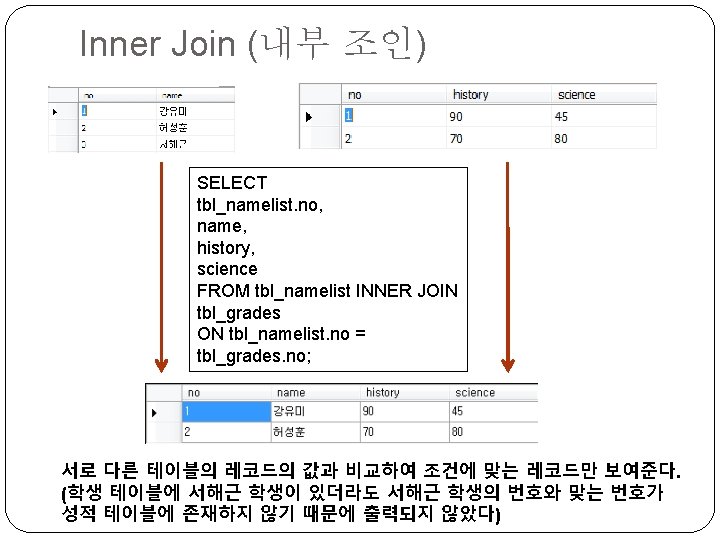

Left Outer Join SELECT tbl_namelist. no, name, history, science FROM tbl_namelist LEFT OUTER JOIN tbl_grades ON tbl_namelist. no = tbl_grades. no; 서로 다른 테이블의 레코드의 값과 비교하여 조건에 맞는 레코드를 출력하고 맞는 레코드가 없더라도 JOIN문 왼쪽에 있는 레코드는 모두 출력한다.

Right Outer Join SELECT tbl_namelist. no, name, history, science FROM tbl_namelist RIGHT OUTER JOIN tbl_grades ON tbl_namelist. no = tbl_grades. no; 서로 다른 테이블의 레코드의 값과 비교하여 조건에 맞는 레코드를 출력하고 맞는 레코드가 없더라도 JOIN문 오른쪽에 있는 레코드는 모두 출력한다.

Full outer join SELECT tbl_namelist. no, name, history, science FROM tbl_namelist FULL OUTER JOIN tbl_grades ON tbl_namelist. no = tbl_grades. no; 서로 다른 테이블의 레코드의 값과 비교하여 조건에 맞는 레코드를 출력하고 맞는 레코드가 없더라도 JOIN문 양쪽에 있는 레코드는 모두 출력한다.


 as lowest FROM tbl_results group by team having")
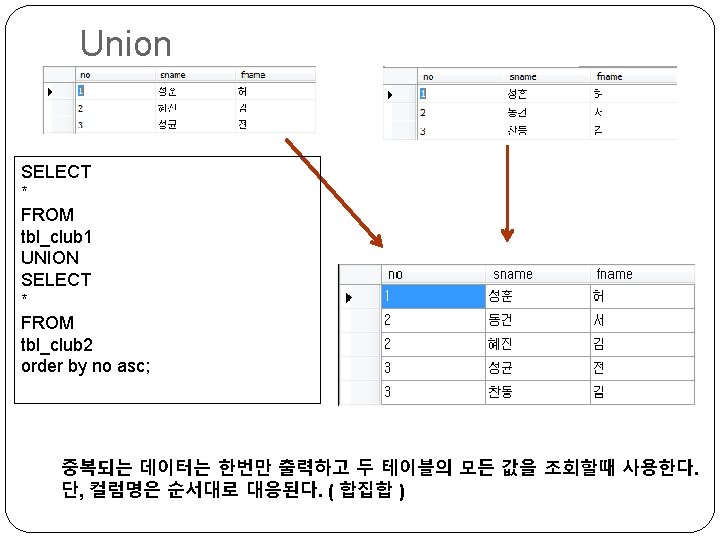
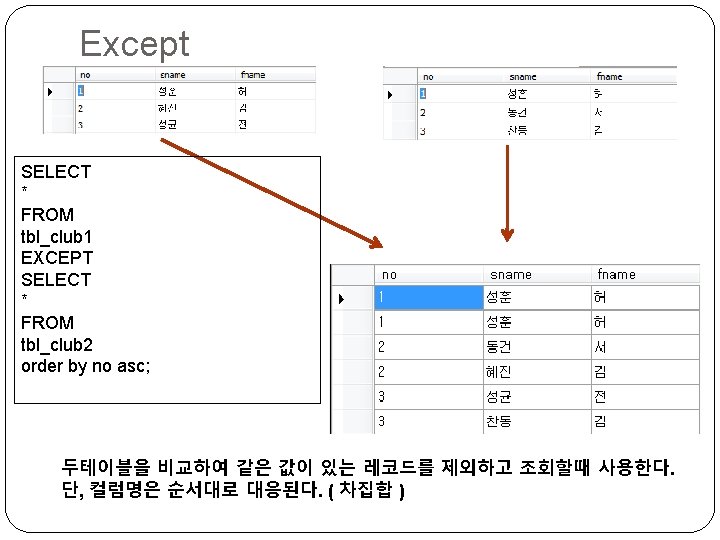
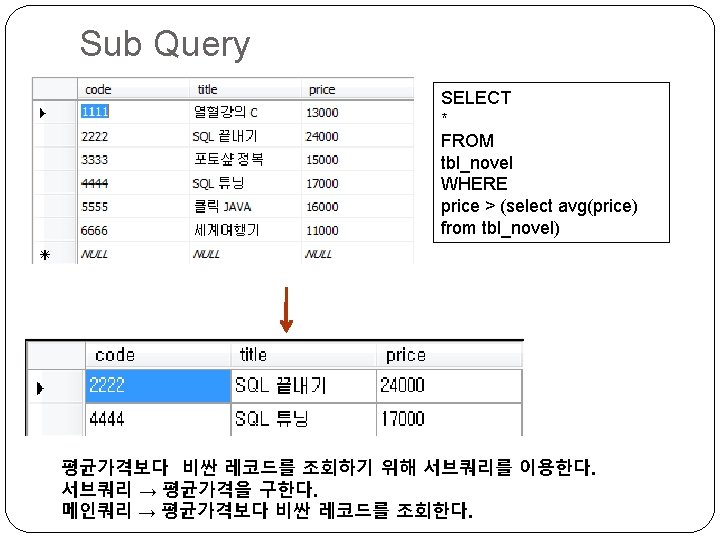
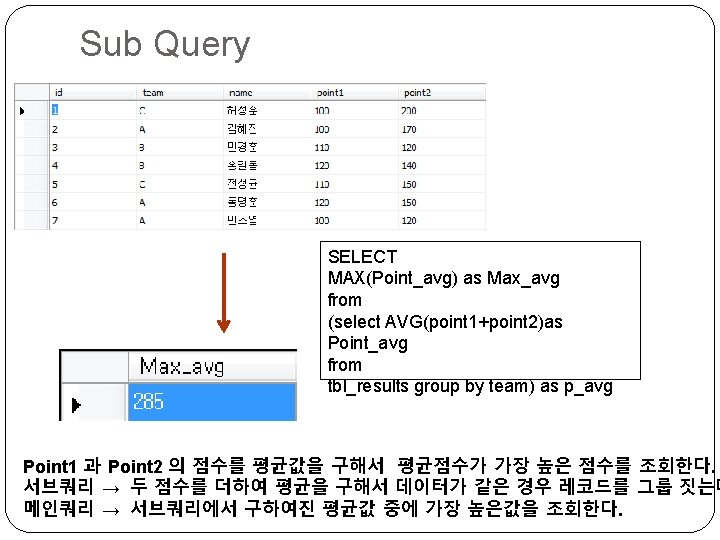
Sub Query SELECT team, MIN(point 2) as lowest FROM tbl_results group by team having MIN(point 2) < (select AVG(point 2) from tbl_results); Point 2값의 평균값 보다 작은 점수를 가진 레코드를 팀별로 조회한다. 서브쿼리 → point 2의 평균값을 구한다. 메인쿼리 → 팀별로 그룹지어 서브테이블과 Having의 조건을 비교하여 조회한다.
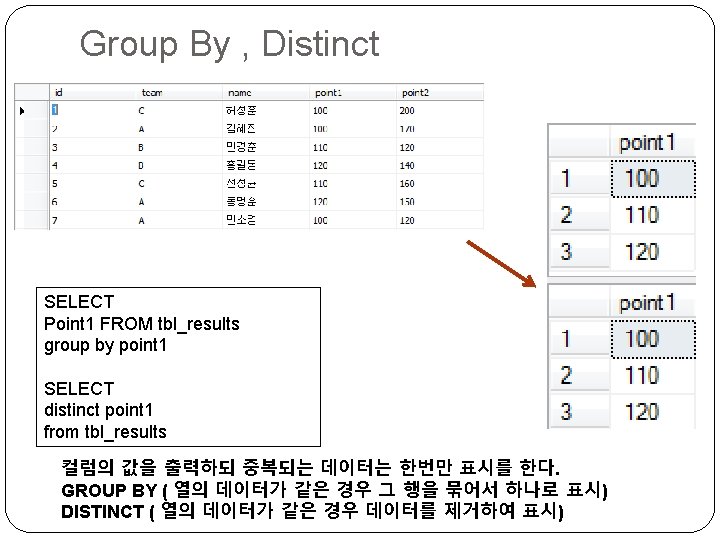

Order By SELECT * FROM tbl_novel order by price asc; SELECT * FROM tbl_novel order by price desc; 선택된 행을 기준으로 오름차순과 내림차순으로 표시.

 + '***' as Ltrim_Test, '***' + RTRIM(pname)")
LTRIM, RTRIM SELECT pname, '***' + LTRIM(pname) + '***' as Ltrim_Test, '***' + RTRIM(pname) + '***' as Rtrim_Test FROM tbl_pet; ; 문자열의 맨 앞(LTRIM)이나 맨 뒤(RTRIM)의 공백을 제거해준다.

 as CEILING_RESULT, FLOOR(cost) AS FLOOR_RESULT FROM tbl_sum 해당 컬럼의")
CEILING, FLOOR SELECT cost, CEILING(cost) as CEILING_RESULT, FLOOR(cost) AS FLOOR_RESULT FROM tbl_sum 해당 컬럼의 값보다 큰 수 중에 가장 작은 정수를 구한다. (CEILING) 해당 컬럼의 값보다 작은 수 중에 가장 큰 정수를 구한다. (FLOOR)
![DAY SELECT date 1, DAY(date 1) as [DAY] FROM tbl_datelist; 해당 DATETIME 자료형의 레코드](http://slidetodoc.com/presentation_image/776c6511c25195603f8f7da25b35c3de/image-20.jpg "DAY SELECT date 1, DAY(date 1) as [DAY] FROM tbl_datelist; 해당 DATETIME 자료형의 레코드")
DAY SELECT date 1, DAY(date 1) as [DAY] FROM tbl_datelist; 해당 DATETIME 자료형의 레코드 값의 년/월/일 등 필요한 내용만 출력한다.
 as Add_M, DATEDIFF(D,")
DATEADD, DATEDIFF SELECT date 1, date 2, DATEADD(m, 6, date 1) as Add_M, DATEDIFF(D, date 1, date 2) as Diff_D 1, DATEDIFF(D, GETDATE(), date 2) as Diff_D 2 FROM tbl_datelist; DATETIME 타입의 날짜를 합(DATEADD)이나 차(DATEDIFF)로 조작할 수 있다. 예제에서는 DATEADD함수를 이용하여 해당 DATE에 6개월을 더하였다. Date 1과 Date 2의 날짜의 차를 구하였다. 현재 날짜에서 date 2의 날짜의 차를 구하였다.
 as 대문자, LOWER(sname) as 소문자 FROM tbl_stdname 해당 컬럼의")
UPPER, LOWER SELECT sname, UPPER(sname) as 대문자, LOWER(sname) as 소문자 FROM tbl_stdname 해당 컬럼의 데이터를 대문자(UPPER), 소문자(LOWER)로 변환하여준다.
 as rength from tbl_stdname 해당 컬럼의 데이터의 길이를 구하여준다.")
LEN SELECT sname, LEN(sname) as rength from tbl_stdname 해당 컬럼의 데이터의 길이를 구하여준다.
 AS RAND_RESULT 1, RAND() AS RAND_RESULT 2, RAND(3) AS RAND_RESULT 3;")
RAND SELECT RAND() AS RAND_RESULT 1, RAND() AS RAND_RESULT 2, RAND(3) AS RAND_RESULT 3; 난수를 구하여 주는 함수다. () 안에는 초기화에 사용되는 SEED값을 지정할 수 있다.

 as Max_price, AVG(price) as Avg_price, MIN(price) as Min_price,")
MAX, MIN, AVG, SUM SELECT MAX(price) as Max_price, AVG(price) as Avg_price, MIN(price) as Min_price, SUM(price) as Sum_price FROM tbl_novel 해당된 레코드의 가장 큰 값(MAX), 가장 작은 값(MIN), 평균값(AVG), 합계(SUM)를 구하여 준다.
, getdate(), <①> ) 이해 => CONVERT(변환될 자료형, 자료, 스 타일)")
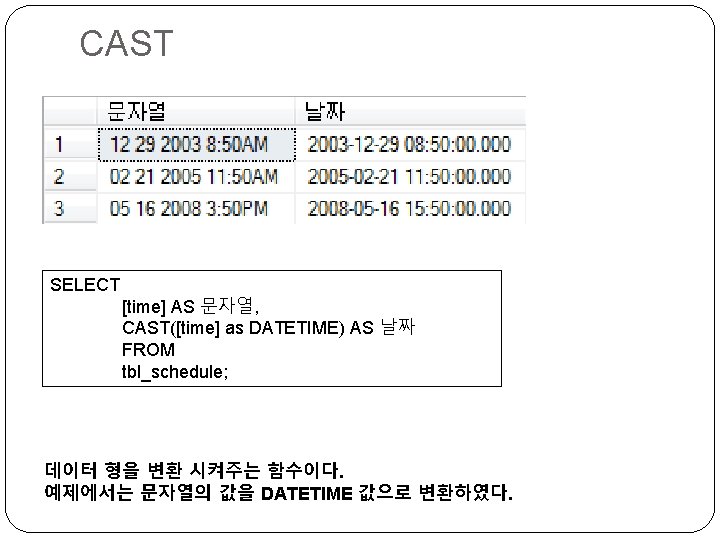
CONVERT SELECT CONVERT( varchar(20), getdate(), <①> ) 이해 => CONVERT(변환될 자료형, 자료, 스 타일)


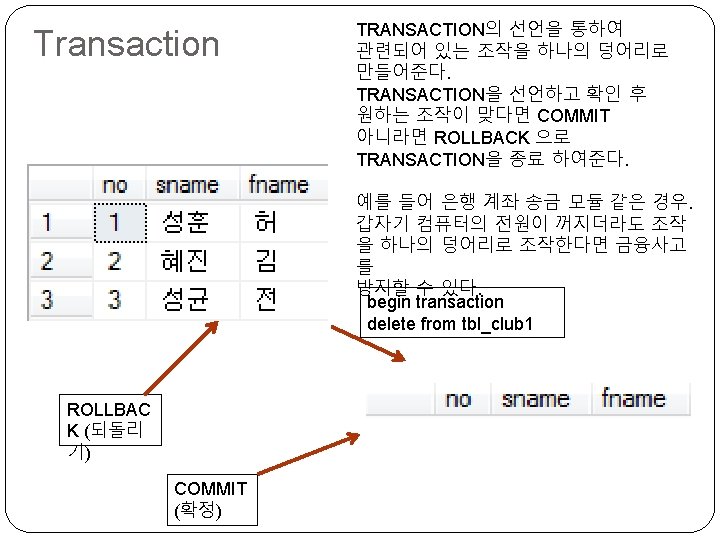
Transaction




- Slides: 49