SQL 3 3 1 SQL q Not Null



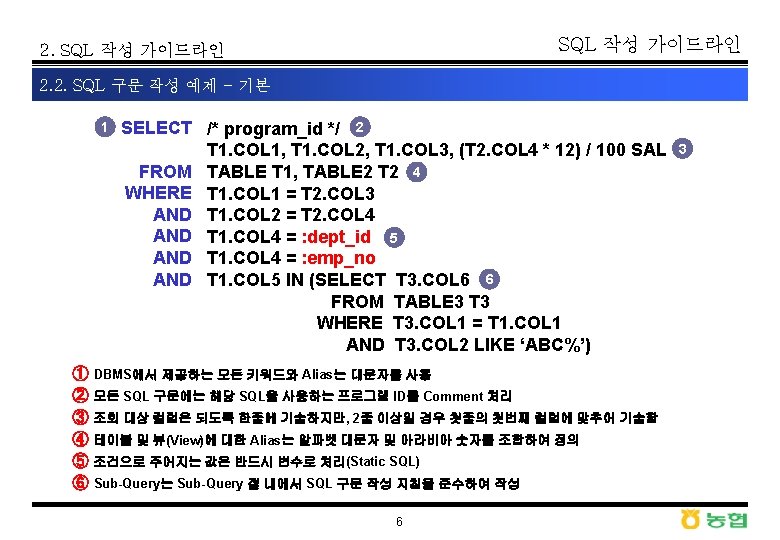










 þ Nested Loops와 Hash")
 þ Nested Loops와 Hash")
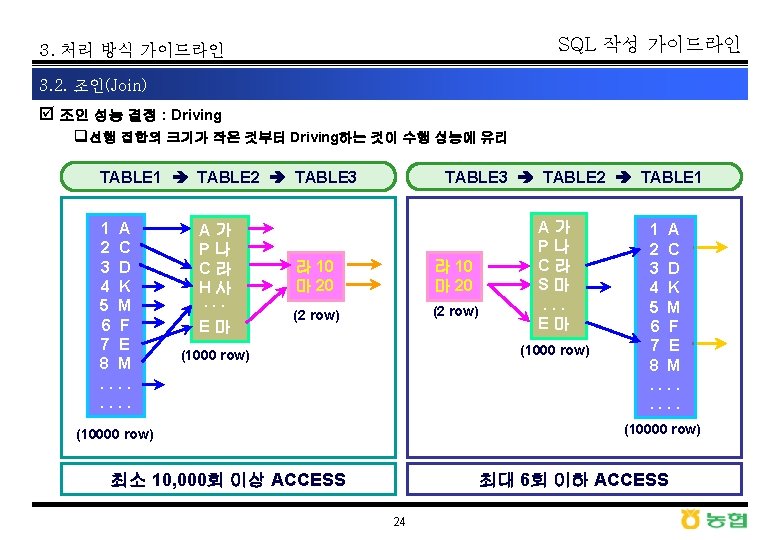
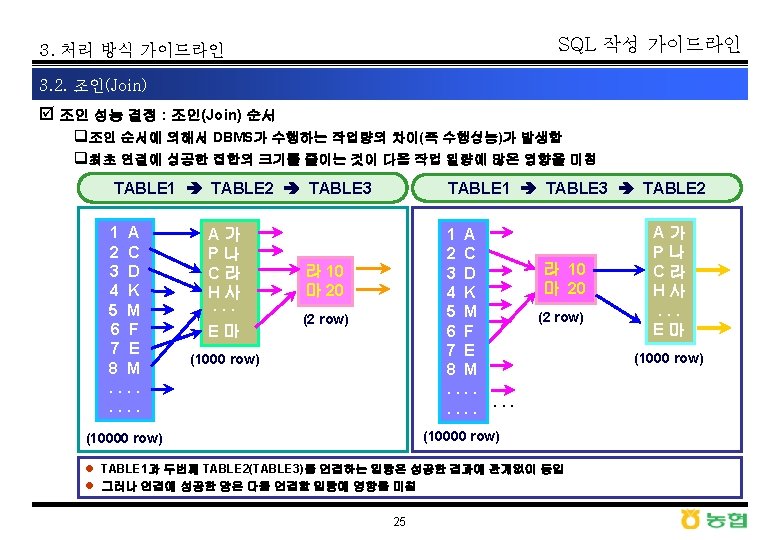
 þ 조인 순서에 따른")
 þ 실행계획에 따른 수행속도")
 þ 액세스 경로의 결정")


")

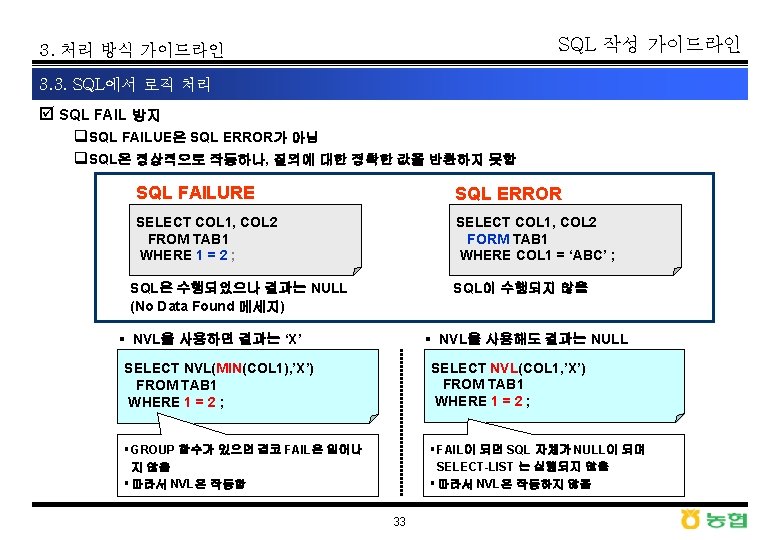




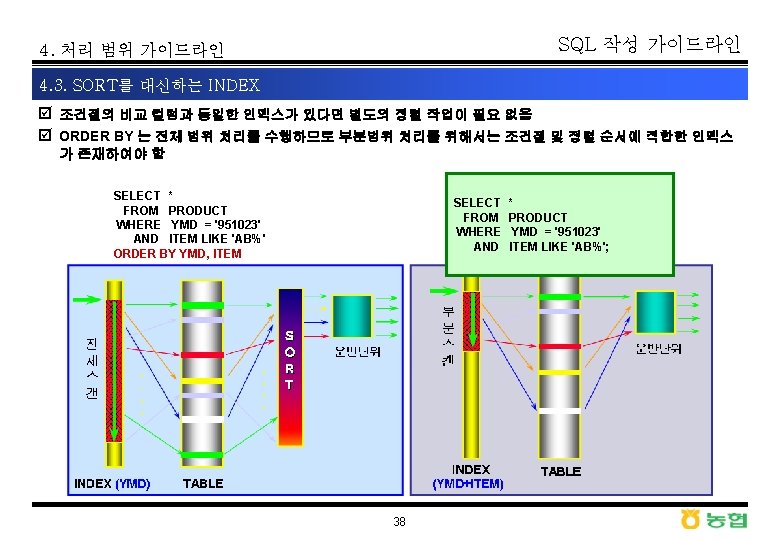




- Slides: 45
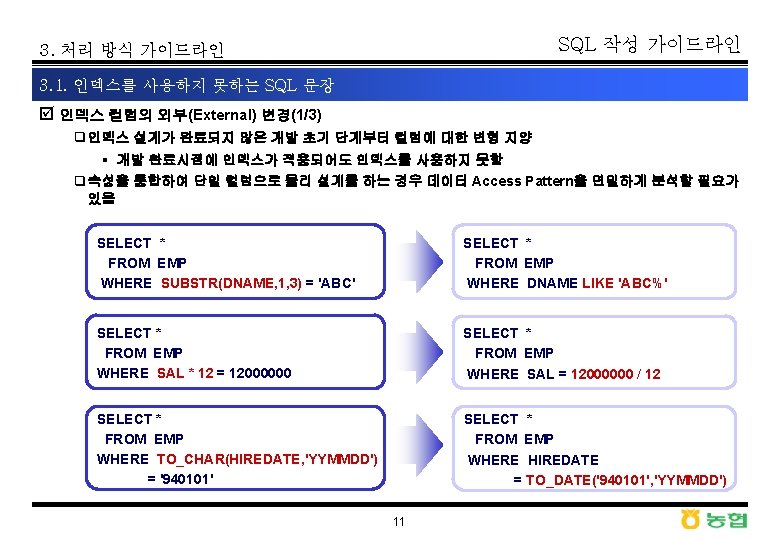
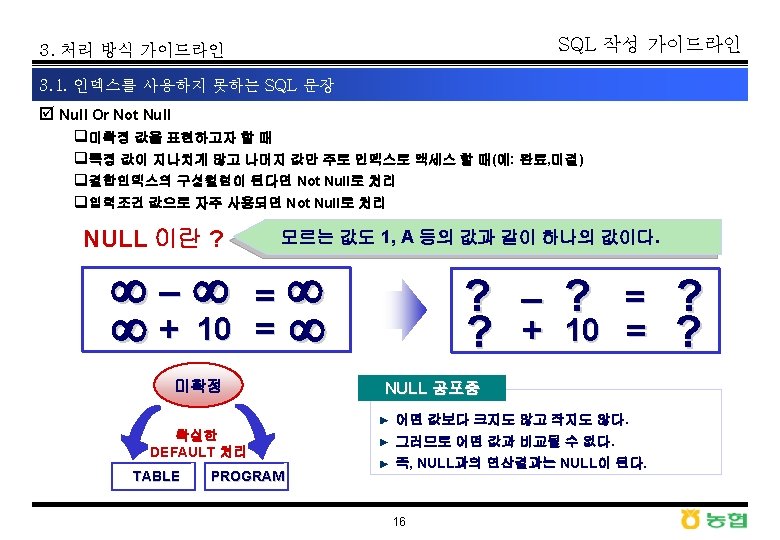
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 1. 인덱스를 사용하지 못하는 SQL 문장 þ 유형 q 인덱스 컬럼의 내외부 변형, Not 연산자, Null Or Not Null Value의 비교, DBMS Optimizer의 취사선택에 의하여 인덱스 사용을 저해하는 요소는 SQL 문장 작성시 지양하여야 함 INDEX COLUMN의 변형 SELECT * FROM DEPT WHERE SUBSTR(DNAME, 1, 3) = 'ABC' NOT Operator SELECT * FROM EMP WHERE JOB <> 'SALES' NULL, NOT NULL SELECT * FROM EMP WHERE ENAME IS NOT NULL Optimizer 의 취사선택 SELECT * FROM EMP WHERE JOB LIKE 'AB%' AND EMPNO = '7890' 10
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 1. 인덱스를 사용하지 못하는 SQL 문장 þ 인덱스 컬럼의 외부(External) 변경(2/3) SELECT * FROM EMP WHERE EMPNO BETWEEN 100 AND 200 AND NVL(JOB, 'X') = 'CLERK' SELECT * FROM EMP WHERE EMPNO BETWEEN 100 AND 200 AND JOB = 'CLERK' SELECT * FROM EMP WHERE DEPTNO || JOB = '10 SALESMAN' SELECT * FROM EMP WHERE DEPTNO = '10' AND JOB = 'SALESMAN' 12
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 1. 인덱스를 사용하지 못하는 SQL 문장 þ 인덱스 컬럼의 외부(External) 변경(3/3) q 수행 성능 향상을 목적으로 실행 계획을 고정시키기 위하여 인덱스 컬럼을 의도적으로 Suppressing q 실행 계획을 제어함으로써 수행 성능 향상이 확실한 경우에만 적용 SELECT CUSTNO, CHULDATE FROM CHULGOT WHERE CUSTNO = 'DN 02' AND STATUS = '90' SELECT CUSTNO, CHULDATE FROM CHULGOT WHERE CUSTNO = 'DN 02' AND RTRIM(STATUS) = '90' 4 rows, 0. 51 sec TABLE ACCESS BY ROWID CHULGOT AND-EQUAL INDEX RANGE SCAN CH_STATUS INDEX RANGE SCAN CH_CUSTNO 4 rows, 0. 03 sec TABLE ACCESS BY ROWID CHULGOT INDEX RANGE SCAN CH_CUSTNO 13
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 1. 인덱스를 사용하지 못하는 SQL 문장 þ 인덱스 컬럼의 내부(Internal) 변경 q 데이터 타입 불일치 경우에 발생되므로 조건절에서 비교하는 데이터 값과 컬럼의 데이터 타입을 반드시 동 일하게 처리 SELECT * FROM SAMPLET WHERE CHA = 10 CREATE TABLE SAMPLET ( CHR CHAR(10), NUMBER (12, 3), VARCHAR 2(20), DATE) SELECT * FROM SAMPLET WHERE TO_NUMBER(CHA) = 10 SELECT * FROM SAMPLET WHERE NUM LIKE '9410%' SELECT * FROM SAMPLET WHERE DAT = '01 -JAN-94' SELECT * FROM SAMPLET WHERE TO_CHAR(NUM) LIKE '9410%' SELECT * FROM SAMPLET WHERE DAT = TO_DATE('01 -JAN-94') 14
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 1. 인덱스를 사용하지 못하는 SQL 문장 þ Not Operator q 조회 대상 집합에 대해서 부분범위 처리할 수 있으며 인덱스의 사용이 가능한 ‘NOT EXISTS’를 활용 q 조회 조건에 부합되는 모집합을 조회시 확인자(체크) 역할을 수행 SELECT INTO FROM WHERE 'Not fornd !' : COL 1 EMPNO <> '1234' SELECT * FROM EMP WHERE ENAME LIKE '천%' AND JOB <> 'SALES' ‘천씨’ 성을 갖는 사람도 극소 이며 영업사원도 극소이므로 ENAME_IDX와 JOB_IDX 모두 효율이 좋은 경우 SELECT ’Not found' INTO : COL 1 FROM DUAL WHERE NOT EXISTS ( SELECT '' FROM EMP WHERE EMPNO = '1234') SELECT * FROM EMP A WHERE A. ENAME LIKE '천% ' AND NOT EXISTS ( SELECT '' FROM EMP B WHERE A. Empno = B. Empno AND B. JOB = 'SALES') SELECT * FROM EMP WHERE ENAME LIKE ’천%' MINUS SELECT * FROM EMP WHERE JOB = 'SALES' 15
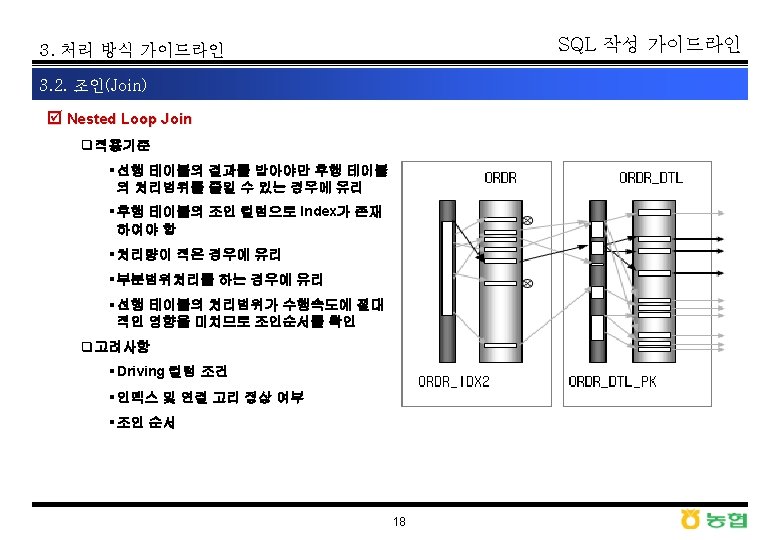
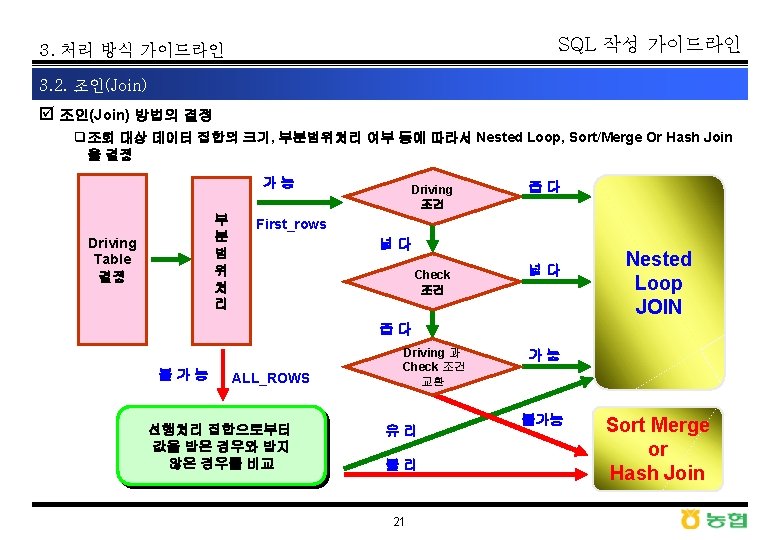
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 2. 조인(Join) þ Nested Loops와 Hash 조인의 비교(일반적인 경우) SELECT FROM WHERE AND HASH JOIN TABLE ACCESS BY INDEX ROWID 청약 6. 48 sec INDEX RANGE SCAN IX_청약_PK TABLE ACCESS FULL 수출입자 A. BUYER_COUNTRY_CD, A. BUYER_CD 청약_V A , 수출입자 B A. BUYER_COUNTRY_CD = B. COUNTRY_CD A. BUYER_CD = B. CUSTOMER_CD B. CUSTOMER_TYPE = '2' NESTED LOOPS TABLE ACCESS BY INDEX ROWID 청약 0. 2 sec INDEX RANGE SCAN IX_청약_PK TABLE ACCESS BY INDEX ROWID 수출입자 INDEX RANGE SCAN IX_수출입자_PK SELECT /*+ ORDERED USE_HASH(A B) */ BUYER_CD, COUNT(*) FROM 청약 A , 수출입자 B WHERE A. BUYER_COUNTRY_CD = B. COUNTRY_CD AND A. BUYER_CD = B. CUSTOMER_CD AND B. CUSTOMER_TYPE = '2' GROUP BY A. BUYER_CD 10 sec SELECT BUYER_CD, COUNT(*) FROM 청약 A , 수출입자 B WHERE A. BUYER_COUNTRY_CD = B. COUNTRY_CD AND A. BUYER_CD = B. CUSTOMER_CD AND B. CUSTOMER_TYPE = '2' GROUP BY A. BUYER_CD 28 sec 22 SORT GROUP BY HASH JOIN TABLE ACCESS FULL 청약 TABLE ACCESS FULL 수출입자 SORT GROUP BY NESTED LOOPS TABLE ACCESS FULL 청약 TABLE ACCESS BY ROWID 수출입자 INDEX RANGE SCAN IX_수출입자_PK
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 2. 조인(Join) þ Nested Loops와 Hash 조인의 비교(연결고리 이상인 경우) SELECT /*+ ORDERED USE_NL(X Y) */ COUNT(Y. ACC_NM), COUNT(Y. USR_CMPNY), COUNT(X. ACC_CD), . . . FROM AC_MST X, AC_DTL Y WHERE Y. USR_CMPNY = 'TOONI' AND Y. CHNL_GB = 'CH_A' AND Y. ACC_UNT = 'A' AND X. ACC_CD = Y. ACC_CD AND X. YEAR_NO = '07' SELECT /*+ ORDERED USE_HASH(X Y) */ COUNT(Y. ACC_NM), COUNT(Y. USR_CMPNY), COUNT(X. ACC_CD), . . . FROM AC_MST X, AC_DTL Y WHERE Y. USR_CMPNY='TOONI' AND Y. CHNL_GB = 'CH_A' AND Y. ACC_UNT = 'A' AND X. ACC_CD = Y. ACC_CD AND X. YEAR_NO = '07' 1 SORT (AGGREGATE) 63806 NESTED LOOPS 1057 INDEX (RANGE SCAN) OF ‘PK_AC_MST' (UNIQUE) 63806 TABLE ACCESS (BY INDEX ROWID) OF 'AC_DTL' 67380192 INDEX (RANGE SCAN) OF ‘PK_AC_DTL' (UNIQUE) Cpu : 195. 09 Elapsed : 215. 94 § PK_AC_MST : YEAR_NO + ACC_CD § PK_AC_DTL : USR_CMPNY + CHNL_GB + ACC_UNT 0 SELECT STATEMENT GOAL: CHOOSE 1 SORT (AGGREGATE) 63806 HASH JOIN 1056 INDEX (RANGE SCAN) OF ‘PK_AC_MST' (UNIQUE) 63806 TABLE ACCESS (BY INDEX ROWID) OF 'AC_DTL' 63807 INDEX (RANGE SCAN) OF ‘PK_AC_DTL' (UNIQUE) Cpu : 0. 37 Elapsed : 0. 37 23
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 2. 조인(Join) þ 조인 순서에 따른 수행속도 차이 예제 SALES CHANNELS PRODUCTS SELECT /*+ ORDERED USE_NL(S C P) */ C. CHANNEL_DESC, P. PROD_NAME, S. * FROM SALES_T 1 S, CHANNELS C, PRODUCTS P WHERE S. CHANNEL_ID = C. CHANNEL_ID AND S. PROD_ID = P. PROD_ID AND S. AMOUNT_SOLD >= 1000 AND C. CHANNEL_CLASS = 'Indirect' AND P. PROD_CATEGORY = 'Boys' 16469 NESTED LOOPS 297852 NESTED LOOPS 689122 TABLE ACCESS FULL SALES_T 1 297852 TABLE ACCESS BY INDEX ROWID CHANNELS 689122 INDEX UNIQUE SCAN CHAN_PK 16469 TABLE ACCESS BY INDEX ROWID PRODUCTS 297852 INDEX UNIQUE SCAN PRODUCTS_PK 16. 3 sec SALES PRODUCTS CHANNELS SELECT /*+ ORDERED USE_NL(S P C) */ C. CHANNEL_DESC, P. PROD_NAME, S. * FROM SALES_T 1 S, PRODUCTS P, CHANNELS C WHERE S. CHANNEL_ID = C. CHANNEL_ID AND S. PROD_ID = P. PROD_ID AND S. AMOUNT_SOLD >= 1000 AND C. CHANNEL_CLASS = 'Indirect' AND P. PROD_CATEGORY = 'Boys' 16469 NESTED LOOPS 40008 NESTED LOOPS 689122 TABLE ACCESS FULL SALES_T 1 40008 TABLE ACCESS BY INDEX ROWID PRODUCTS 689122 INDEX UNIQUE SCAN PRODUCTS_PK 16469 TABLE ACCESS BY INDEX ROWID CHANNELS 40008 INDEX UNIQUE SCAN CHAN_PK 10. 5 Sec 26
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 2. 조인(Join) þ 실행계획에 따른 수행속도 차이 예제 § CU_NATION : NATION + ADDR 1 § CH_CUSTNO : CUSTNO + CHULQTY SELECT /*+ ORDERED USE_NL(Y X) */ CHULNO, CHULDATE, CUSTNAME FROM CUSTOMER Y, CHULGOT X 1 rows, WHERE X. CUSTNO = Y. CUSTNO 0. 15 sec AND X. CHULDATE = '941003' AND Y. NATION = 'KOR' NESTED LOOPS TABLE ACCESS BY ROWID CUSTOMER INDEX RANGE SCAN CU_NATION TABLE ACCESS BY ROWID CHULGOT INDEX RANGE SCAN CH_CUSTNO 고객 데이터의 상당 부분이 'KOR'이며 출고 데이터 중 특정일자에 해당하는 건 이 극소수인 상황임 § CH_CHULDATE : CHULDATE + CHULNO § PK_CUSTNO : CUSTNO SELECT /*+ ORDERED USE_NL(X Y) */ NESTED LOOPS CHULNO, CHULDATE, CUSTNAME TABLE ACCESS BY ROWID CHULGOT FROM CHULGOT X, CUSTOMER Y INDEX RANGE SCAN CH_CHULDATE WHERE X. CUSTNO = Y. CUSTNO 1 rows, TABLE ACCESS BY ROWID CUSTOMER AND X. CHULDATE = '941003' 0. 04 sec INDEX UNIQUE SCAN PK_CUSTNO AND Y. NATION = 'KOR' 27
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 2. 조인(Join) þ 액세스 경로의 결정 q상수 값을 받을 수 있어야 액세스 자격이 획득됨 (Nested Loops Join인 경우) q어떤 액세스 경로가 가장 유리한가? q인덱스 구조가 어떻게 되어 있는가? TAB 1 TAB 2 A 2 B 2 A 1 B 1 & B 2 TAB 3 TAB 2 TAB 1 # B 2 # A 1 A 2 C 1 TAB 3 # C 1 C 2 SELECT A 1, A 2, . . , B 1, B 2, . . , C 1, C 2, . . . FROM TAB 1 x, TAB 2 y, TAB 3 z WHERE x. A 1 = y. B 1 AND z. C 1 = y. B 2 AND x. A 2 = '10' AND y. B 2 like 'B%' 28 CASE ACCESS PATH TAB 1 TAB 2 TAB 3 A 2 = '10' B 1 = A 1 and B 2 like 'B%' C 1 = B 2 TAB 3 TAB 1 B 2 like 'B%' C 1 = B 2 A 1 = B 1 and A 2 = '10' TAB 3 TAB 2 TAB 1 Full table scan B 2 = C 1 and B 2 like 'B%' A 1 = B 1 and A 2 = '10' . . .
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 3. SQL에서 로직 처리 þ SQL 문장에서의 IF 처리 q단순 로직의 IF 문은 SQL 문장 내에서 CASE Or DECODE 문으로 처리 가능 q로직 처리한 결과를 조회 결과로 리턴 받음으로써 어플리케이션의 비효율 제거 q. CASE 보다는 DECODE 문이 DBMS 부하를 많이 유발함 IF A = 10 THEN 1 ELSE IF A = 20 THEN 2 ELSE 3 END IF IF A < 10 THEN 1 ELSE IF A < 20 THEN 2 ELSE 3 END IF DECODE SELECT DECODE(A, 10, 1, 20, 2, 3) … FROM ………. CASE SELECT CASE A when 10 then 1 when 20 then 2 else 3 END FROM ………. DECODE SELECT DECODE(SIGN(A-10), -1, 1, DECODE(SIGN(A-20), -1, 2, 3)) FROM ………. CASE SELECT CASE when A < 10 then 1 when A < 20 then 2 else 3 END FROM ………. 29
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 3. SQL에서 로직 처리 þ 문자의 부등호 비교 q. DECODE 보다는 CASE가 유리 q. DECODE 사용시는 LEAST, GREATEST 와 같은 내부 함수를 추가적으로 사용 IF A <= ‘ABC’ THEN 1 DECODE SELECT DECODE(LEAST(A, ’ABC’), A, 1, DECODE(GREATEST(A, ’DEF’), A, 3, 2)) FROM ………. CASE SELECT CASE WHEN A <= ‘ABC’ then 1 WHEN A >= ‘DEF’ then 3 ELSE 2 END FROM ………. DECODE SELECT DECODE(LEAST(A||’ ’, ’ABC’), A||’ ’, 1, DECODE(LEAST(A, ’DEF’), A, 2, 3)) FROM ………. CASE SELECT CASE WHEN A < ‘ABC’ then 1 WHEN A > ‘DEF’ then 3 ELSE 2 END FROM ………. ELSE IF A >= ‘DEF’ THEN 3 ELSE 2 END IF IF A < ‘ABC’ THEN 1 ELSE IF A > ‘DEF’ THEN 3 ELSE 2 END IF 30
SQL 작성 가이드라인 3. 처리 방식 가이드라인 3. 3. SQL에서 로직 처리 þ SUM(CASE) q펼칠 컬럼이 너무 많을 때는 먼저 GROUP BY 한 후 처리 DATA ITEM YYMM SQ ABC ABC ABC …… ABC BAC …… 9801 9802 9803 …… 9806 9801 …… 1 2 3 1 … QTY 100 250 100 120 200 …… 300 200 …… SELECT ITEM, CASE WHEN YYMM = ‘ 9801’ THEN QTY END M 1, CASE WHEN YYMM = ‘ 9802’ THEN QTY END M 1 M 2, M 2 M 3 M 4 M 5 M 6 ITEM. . . ------- -----CASE WHEN YYMM = ‘ 9806’ THEN QTY END 100 M 6 ABC 250 FROM TABLE_NAME ABC 150 WHERE CONDITIONS ; § CASE(DECODE)를 이용하여 행단위 -> 열단위 변환 SELECT item, SUM(case when yymm = ’ 9801’ then qty end), SUM(case when yymm = ‘ 9802’ then qty end), . . . SUM(case when yymm = ‘ 9806’ then qty end) FROM table_name WHERE conditions GROUP BY item; 31 ABC 100 ABC 200 ……. ABC BAC 200 ITEM ------ABC BAC 300 M 1 M 2 M 3 M 4 M 5 M 6 ----- -----350 450 200 0 0 300 200 0 0 …………… § SUM(CASE)를 확장하여 통상 보고 서 형태의 View 제공 가능
SQL 작성 가이드라인 4. 처리 범위 가이드라인 4. 2. 1: M 조인의 부분범위 처리 þ 확인자로 처리 q메인 집합을 기준으로 부분범위 처리를 수행함으로 SQL의 수행 처리 속도를 향상 시킴 q그러나, Sub-Query의 수행 결과를 Main-Query에서 사용하지 못함 SELECT X. CUST_NO, X. ADDR, X. NAME, . . . CUST_NO는 CUST 테이 블의 PK INDEX임 FROM CUST X, REQT Y WHERE X. CUST_NO = Y. CUST_NO AND X. CUST_STAT IN ('A', 'C', 'F') 전체범위 AND Y. UN_PAY > 0 GROUP BY X. CUST_NO HAVING SUM(Y. UN_PAY) BETWEEN : VAL 1 AND : VAL 2 SELECT X. CUST_NO, X. ADDR, X. NAME, . . . FROM CUST X WHERE CUST_STAT IN ('A', 'C', 'F') AND EXISTS ( SELECT ’X' FROM REQT Y WHERE Y. CUST_NO = X. CUST_NO AND Y. UN_PAY > 0 GROUP BY Y. CUST_NO HAVING SUM(Y. UN_PAY)BETWEEN : VAL 1 AND : VAL 2 ) 부분범위 SUB_QUERY 의 수행결과를 MAIN_QUERY 에서 사용할 수 없음 35
SQL 작성 가이드라인 4. 처리 범위 가이드라인 4. 2. 1: M 조인의 부분범위처리 þ 함수로 처리 q. M쪽의 집합 관련 부분을 함수로 처리하여 부분범위 처리를 유도 q과도한 함수 사용은 DBMS의 부하를 유발함으로 Scalar Sub-Query 형태로 사용하는 것이 바람직함 SELECT X. CUST_NO, X. ADDR, X. NAME, . . . FROM CUST X, REQT Y WHERE X. CUST_NO = Y. CUST_NO AND X. CUST_STAT IN ('A', 'C', 'F') AND Y. UN_PAY > 0 GROUP BY X. CUST_NO HAVING SUM(Y. UN_PAY) BETWEEN : VAL 1 AND : VAL 2 전체범위 부분범위 Create or replace Function unpay_sum (v_custno in varchar 2) return number is sum_unpay number ; begin. . . SELECT SUM(UN_PAY) INTO sum_unpay FROM REGT WHERE CUST_NO = v_custno AND UN_PAY > 0 ; . . . . return sum_unpay ; end unpay_sum ; SELECT CUST_NO, ADDR, UN_PAY, . . . FROM ( SELECT CUST_NO, ADDR, UNPAY_SUM(CUST_NO) UN_PAY, . . FROM CUST WHERE CUST_STAT IN ('A', 'C', 'F') ) WHERE UN_PAY BETWEEN : VAL 1 AND : VAL 2 36
SQL 작성 가이드라인 4. 처리 범위 가이드라인 4. 2. 1: M 조인의 부분범위처리 þ Scalar Sub-Query로 처리 q. M쪽의 집합 관련 부분을 Scalar Sub-Query로 처리하여 부분범위 처리를 유도 q함수(Function)보다는 Scalar Sub-Query가 DBMS의 수행 성능에 유리함 SELECT X. CUST_NO, x. ADDR, x. NAME, . . . FROM CUST X, REQT y WHERE X. CUST_NO = Y. CUST_NO AND X. CUST_STAT IN ('A', 'C', 'F') 전체범위 AND Y. UN_PAY > 0 GROUP BY X. CUST_NO HAVING SUM(X. UN_PAY) BETWEEN : VAL 1 AND : VAL 2 부분범위 SELECT CUST_NO, ADDR, UN_PAY, . . . FROM (SELECT X. CUST_NO, X. ADDR, (SELECT SUM(Y. UN_PAY) FROM REGT Y WHERE X. CUST_NO = Y. CUST_NO AND Y. UN_PAY > 0 ) AS un_pay, . . FROM CUST_X WHERE X. CUST_STAT IN ('A', 'C', 'F') ) WHERE UN_PAY BETWEEN : VAL 1 AND : VAL 2 37
SQL 작성 가이드라인 4. 처리 범위 가이드라인 4. 3. SORT를 대신하는 INDEX þ Sort를 대신하는 Index 활용 사례 SELECT ORDDATE, CUSTNO FROM ORDER 1 T WHERE ORDDATE BETWEEN '940101' AND '941130' ORDER BY ORDDATE DESC SELECT /*+ INDEX_DESC(A ORDDATE) */ ORDDATE, CUSTNO FROM ORDER 1 T A WHERE ORDDATE BETWEEN '940101' AND '941130' 21200 SORT ORDER BY 21201 INDEX RANGE SCAN ORDDATE index : ORDDATE + CUSTNO 20 5. 2 sec INDEX RANGE SCAN DESCENDING ORDDATE index : ORDDATE + CUSTNO 0. 01 sec 인덱스 구조 변경 및 조건 추가 SELECT /*+ INDEX_DESC(A ORDDATE) */ ORDDATE, CUSTNO FROM ORDER 1 T A WHERE ORDDEPT LIKE '7%' AND ORDDATE <= '991231' SELECT ORDDATE, CUSTNO FROM ORDER 1 T WHERE ORDDEPT LIKE '7%' ORDER BY ORDDATE DESC 0. 02 sec 12. 5 sec 20 INDEX RANGE SCAN DESCENDING ORDDATE 42000 SORT ORDER BY 42001 INDEX RANGE SCAN ORDDEPT index : ORDDEPT + ORDDATE + CUSTNO ORDDATE index : ORDDATE + ORDDEPT + CUSTNO 39
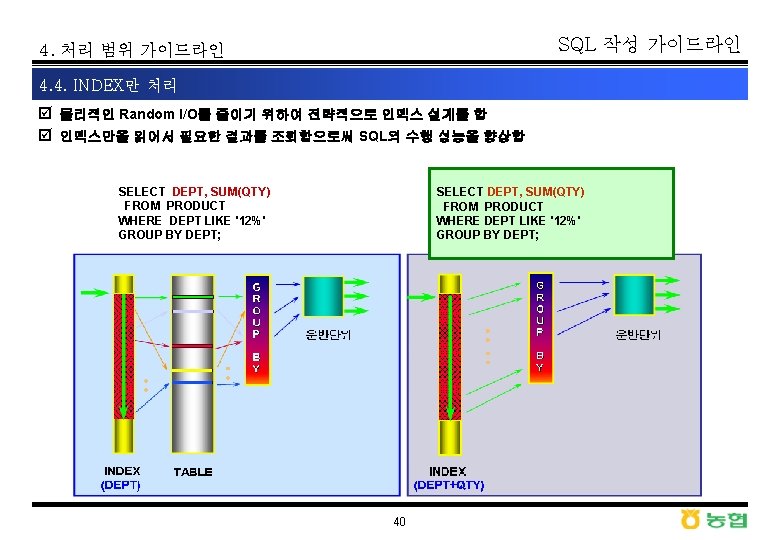
SQL 작성 가이드라인 4. 처리 범위 가이드라인 4. 4. INDEX만 처리 þ Index만 처리하는 SQL 활용 사례 SQL> SELECT STATUS, COUNT(*) FROM ORDER 2 T WHERE ITEM LIKE 'HJ%' GROUP BY STATUS 20 SORT GROUP BY 36630 TABLE ACCESS BY INDEX ROWID ORDER 2 T 36631 INDEX RANGE SCAN ITEM_IDX 1 20 SORT GROUP BY 36631 INDEX RANGE SCAN ITEM_IDX 1 index : ITEM + STATUS 10. 3 sec 41 2. 5 sec
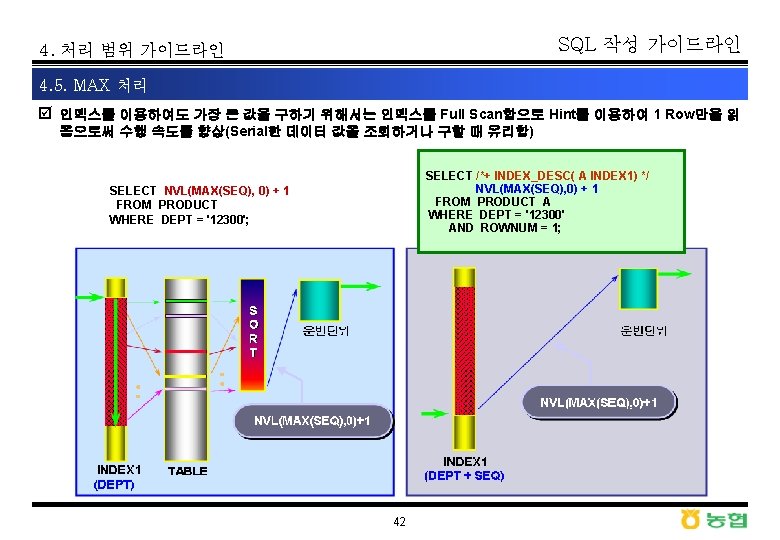
SQL 작성 가이드라인 4. 처리 범위 가이드라인 4. 5. MAX 처리 þ MAX 처리의 SQL 활용 사례 SQL> SELECT /*+ INDEX_DESC(A dept_date) */ NVL(MAX(ORDDATE), ' 없음') FROM ORDER 1 T A WHERE ORDDEPT = '430' AND STATUS = '30' AND ROWNUM = 1 SQL> SELECT NVL(MAX(ORDDATE), '없음') FROM ORDER 1 T WHERE ORDDEPT = '430' AND STATUS = '30' 2. 53 sec 0. 01 sec 1 SORT AGGREGATE 2892 TABLE ACCESS BY INDEX ROWID ORDER 1 T 15230 INDEX RANGE SCAN DEPT_DATE 1 COUNT STOPKEY 1 TABLE ACCESS BY INDEX ROWID ORDER 1 T 1 INDEX RANGE SCAN DESCENDING DEPT_DATE index : ORDDEPT + ORDDATE 43
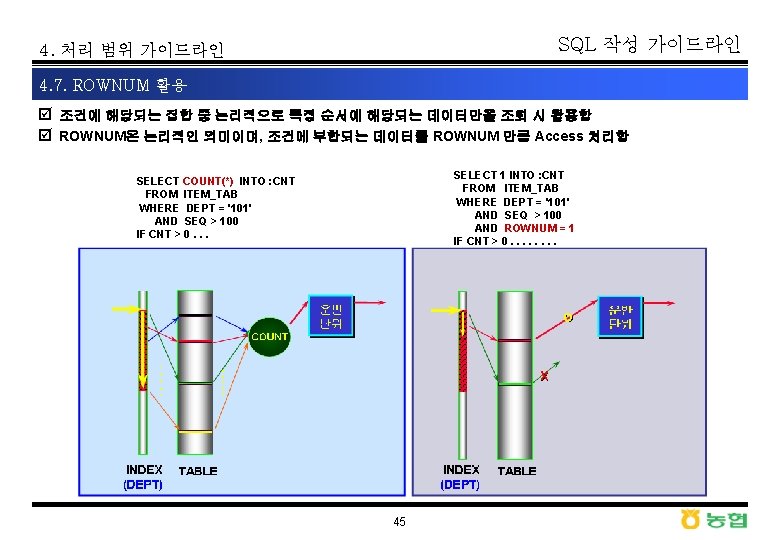
SQL 작성 가이드라인 4. 처리 범위 가이드라인 4. 6. EXISTS 활용 þ 조건에 부합되는 데이터의 존재 유무 확인 시 활용(Count는 전체 데이터를 Access) þ EXISTS, NOT EXISTS 는 Boolean(True Or False)의 개념 SELECT 1 INTO : CNT FROM DUAL WHERE EXISTS ( SELECT FROM WHERE AND IF CNT > 0. . . SELECT COUNT(*) INTO : CNT FROM ITEM_TAB WHERE DEPT = '101' AND SEQ > 100 IF CNT > 0. . . 44 'X' ITEM_TAB DEPT = '101' SEQ > 100 )