Spracherkennung unter schwierigen Bedingungen Natrlichsprachliche Interfaces Ideale Bedingungen

Spracherkennung unter schwierigen Bedingungen Natürlichsprachliche Interfaces

Ideale Bedingungen • • Deutlich und mit normaler, natürlicher Stimme sprechen Möglichst Dialektfrei, keine Umgangssprache Beigelegtes Headset verwenden Immer das Mikrofon verwenden, welches beim Training verwendet wurde Sprechgarnitur immer auf die selbe Weise tragen, 2 cm seitlich vom Mund, keine Berührungen mit Haut oder Haaren Akustisches Umfeld muss gleich sein, wie bei der Aufnahme (Halligkeit und Nebengeräusche) Essen, trinken und rauchen sie nicht beim Diktieren Bei Erkältung warten, bis diese abgeklungen ist


Übersicht • Mikrofone – – – – • Probleme Hörfläche des Menschen Frequenzbereiche der Phoneme Konflikte der Frequenzbereiche Robuste Spracherkennung – – • Charakteristika Abstrahlwinkel der Stimme Aufstellungsmöglichkeiten Bauarten von Mikrofonen Rauschunterdrückung im Mikrofonarray Algorithmen vor der Verarbeitung Nach der Verarbeitung Transkriptionen – IPA – Ext. IPA

Mikrofoncharakteristiken Kugelcharakteristik Mikrofon ohne spezifische Richtcharakteristik. Es ist für Schallwellen aus allen Richtungen gleich empfindlich. Niere (Kardioid, Superkardioid, Hyperkardioid) Mikrofon mit Richtcharakteristik, bei der Schall vorzugsweise von vorne aufgenommen wird. Schall, der von hinten auf das Mikrofon auftrifft, wird ausgeblendet. Acht-Charakteristik Richtcharakteristik eines Mikrofons in Form einer liegenden Acht, bei der Schall vorzugsweise aus zwei gegenüberliegenden Richtungen aufgenommen wird. Schall aus den anderen beiden Richtungen, oder Schall, der von unten oder oben auf das Mikrofon auftrifft, wird ausgeblendet. Keule Mikrofon mit starker Richtcharakteristik, bei dem der Schall vorzugsweise von vorne und kaum von der Seite aufgenommen wird. Schall, der von hinten auf das Mikrofon auftrifft, wird nur wenig ausgeblendet.

Abstrahlwinkel der Stimme • Schallabstrahlung der Stimme ist gerichtet • Pegel ist rund 5 d. B niedriger in seitlicher Richtung • Pegel ist rund 10 d. B niedriger in rückwärtiger Richtung • Dabei wird der Klangcharakter erheblich geändert: • Frequenzen über 1000 Hz werden zur Seite und nach hinten mit geringerem Pegel abgestrahlt

Aufstellungsmöglichkeiten Headset • Ein Nahbesprechungs-Mikrofon wird dicht etwas seitlich vom Mund platziert getragen • Wird meist kombiniert mit einer aktiven Rauschunterdrückung • Kabel kann Stören und die Nähe zum Mund kann Störgeräusche verursachen Einbaumikrofone z. B. im Monitor oder in der Tastatur • Empfindlich für Störgeräusche • Sind weit entfernt vom Sprecher (Richtcharakteristik) • Störgeräusche auch von der direkten Umgebung (z. B. Tastatur) • Kabel kann Stören Einbau-Mikrofone im Computer • Eignen sich nicht sehr gut, da sie weit entfernt aufgestellt werden • Sind von vielen Störgeräuschen umgeben

Mikrofonklips • Nahbesprechungs-Mikrofon, wird direkt am Pullover getragen • Haben ungefähr die selben Eigenschaften wie Headsets Desktop • Desktop-Mikrofone werden ca. 15 cm entfernt mit Richtung zum Sprecher neben dem Monitor platziert aufgestellt • Funktionieren gut, aber nur in ruhigen Räumen Ear-piece • Werden in das Ohr gesteckt mit Richtung zum Mund • Funktionieren ganz gut, aber nicht so gut wie Nahbesprechungs-Mikrofone • Kabel kann Stören Hand-held • Hand. Mikrofone nehmen wenig Störgeräusche auf • Müssen ca. 10 cm vom Mund platziert werden, eignet sich für einige Anwendungen nicht so gut Handset • Sehen aus wie Telefone und sind ganz gut geeignet

Bauarten von Mikrofonen
 • Störgeräusche – Verständlichkeit – Hörfläche")
Schwierige Bedingungen • Eingangspegel der Stimme (Input level) • Störgeräusche – Verständlichkeit – Hörfläche des Menschen – Frequenzbereiche der Phoneme

Eingangspegel der Stimme – Variiert von Aussage zu Aussage und auch innerhalb einer Aussage – Abhängig von der Sprech-Variation (normal, geflüstert, geschrieen) – Abhängig von der Entfernung zum Mikrofon – Abhängig von der Ausrichtung des Mikrofons – Normalisierung des Sprachsignals funktioniert nicht, da der Eingangspegel ein Langzeitmerkmal des Sprachsignals ist Heute ist schönes Frühlingswetter

Störgeräusche • • • Regelmäßige Hintergrundgeräusche – können beim Training mit in das HMM aufgenommen werden (Computerlüfter, Straßenlärm) – dürfen sich beim Training nicht von den Störgeräuschen bei der Anwendung unterscheiden Unregelmäßige Hintergrundgeräusche wie Türen-Knallen oder Tastaturgeräusche verursachen Probleme Störungen durch andere Sprecher – Menschen können einzelne Stimmen aus einer Menschenmenge heraushören (Cocktailpartyeffekt) – Spracherkennungsmodell in der Regel nur für eine einzelne Stimme ausgelegt Raumakustik und Reflexionen – Reflexionen können als linearer Filter modelliert werden, in dem die Geometrie des Raumes, das Material und die Position des Sprechers dargestellt werden Aufnahmevorrichtung – Bei der Verwendung verschiedener Mikrofone ändert sich sie allgemeine Transferfunktion

Sprecher spezifische Probleme • Unterschiede in der Physiologie des Vokaltraktes • Unterschiede in der Länge und der Form des Vokaltraktes • Formanten der männlichen Stimme tiefer als die von Frauen und Kindern • Verschiedene Sprechstile • normal, langsam, schnell, geschrien
 geringer als +10 d. B ist, wird")
Verständlichkeit Wenn der Geräuschspannungsabstand (SNR signal-to-noise ratio) geringer als +10 d. B ist, wird das Sprachsignal unverständlich Ab +30 d. B ist die Verständlichkeit gegeben, wenn auch mangelhaft Zu unverfälschten Übertragung von Sprache ist ein Frequenzband von 3600 Hz erforderlich.

Hörfläche des Menschen

Frequenzbereiche der Phoneme
")
Lösungsmöglicheiten für eine robuste Spracherkennung • Modelle für Nicht-Sprachlaute • Active Noise Cancellation (ANC) • Mikrofonarray • Regelmässig auftretender Störschall wird mit in das HMM aufgenommen
 im Erkennungssystem Du. Deutsch")
Modelle für die Abdeckung von Nicht-Sprachlaute (garbage models) im Erkennungssystem Du. Deutsch
 • • • Zwei Mikrofone im Headset kommen zum Einsatz,")
Active Noise Cancellation (ANC) • • • Zwei Mikrofone im Headset kommen zum Einsatz, eines Nimmt die Sprache mit dem Hintergrundgeräusch auf und eines nimmt nur das Hintergrundgeräusch auf. Eines der beiden Signale wird in der Phase gedreht. Beide Signale werden wieder gemischt, woraufhin sich die beiden Gegenphasigen Signale auslöschen. Übrig bleibt nur das Sprachsignal

Mikrofonarray • Ein Mikrofonarray führt eine räumliche Abtastung eines Signals durch • Durch Laufzeitunterschiede erkennt das System ob von Vorne gesprochen worden ist • Signale, welche seitlich eingestrahlt werden, werden nicht mit verarbeitet

• Die spektrale Subtraktion zur Elimination eines additiven Rauschspektrums. Dazu wird eine Schätzung des Rauschanteils durchgeführt und der Rauschanteil dann vom Spektrum subtrahiert.

• Die Normalisierung des Verhältnisses von Signal- zu Rauschleistung in den einzelnen Frequenzbändern, durch eine additive Maskierung der entsprechenden Filterbankausgänge.

• Normalisierung des Hintergrundpegels. In Sprachpause-Bereichen sorgt eine adaptive Skalierung des Signals der einzelnen Filterbankausgänge für eine Absenkung des Geräuschpegels. Signalanteile in denen Sprache vorliegt bleiben unverändert.

• • • Autoregressives Model Manipulation von Verzerrungsmessungen Auditorische Modelle Kurz Zeit Amplitudenschätzungen Mixture Densities Weitere Techniken

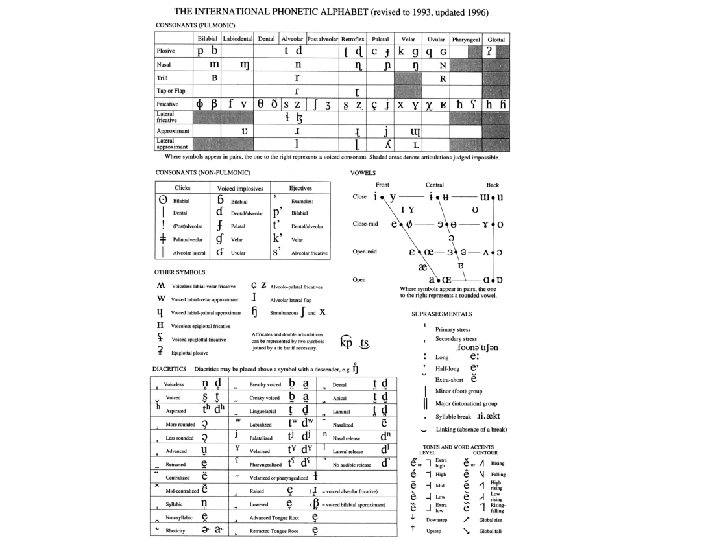
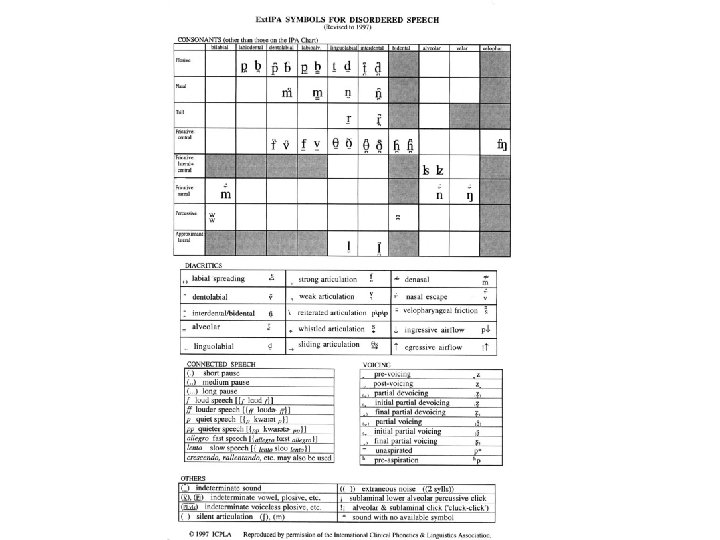
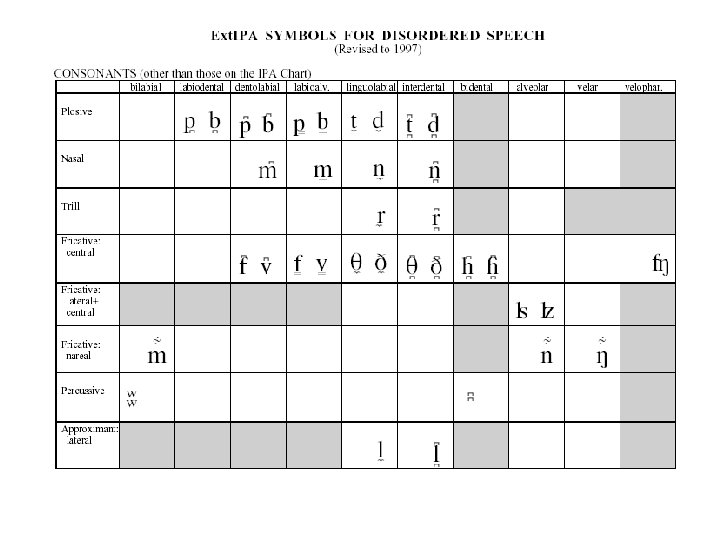
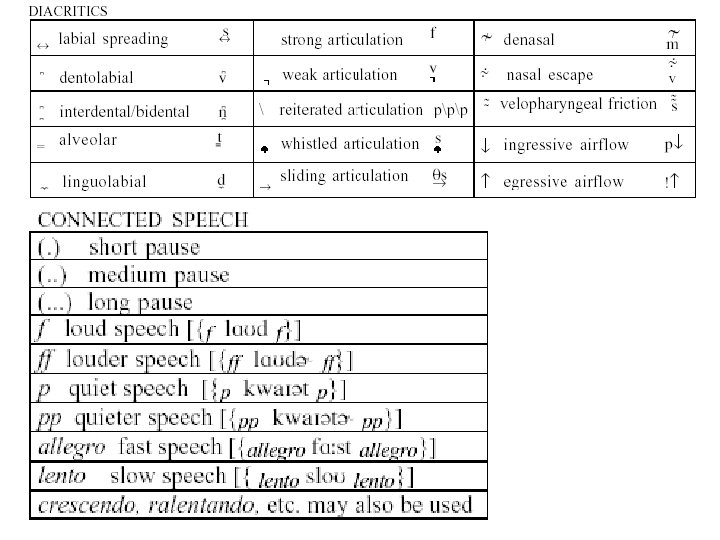
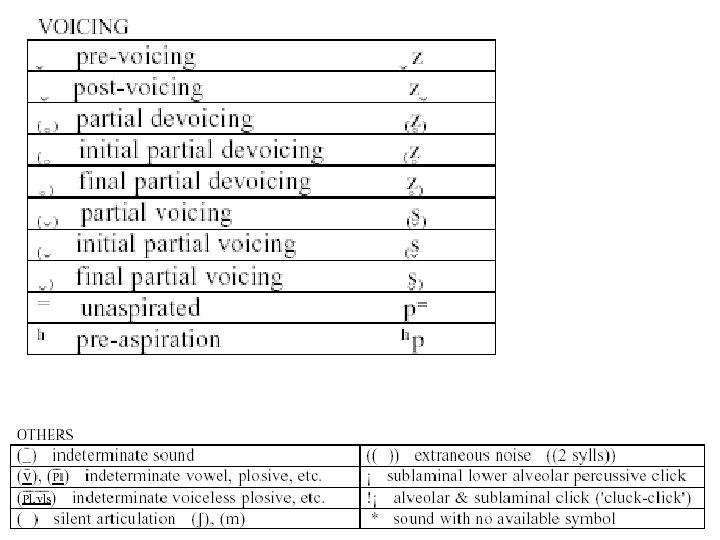
Transkription von pathologischer Artikulation • IPA • Ext. IPA – Symbole – Diakritika – Verbundene Sprache – Stimmhaftigkeit – Andere Symbole
 Mikrofonaufnahmetechnik S. Hirzel Verlag Stuttgart, Leipzig 2. Auflage 1995")
Literatur Dickreiter, Michael (S. 56) Mikrofonaufnahmetechnik S. Hirzel Verlag Stuttgart, Leipzig 2. Auflage 1995 http: //www. techfak. uni-bielefeld. de/ags/ni/projects/datamining/datason/l/ web_psychoak/html/slide_3. html acero_thesis
- Slides: 31