Spark Scala http aibigdata csu edu cn n
 http: //aibigdata. csu. edu. cn")
Spark大数据 编程基础(Scala版) http: //aibigdata. csu. edu. cn



主要内容 n 6. 1 Spark SQL概述 n 6. 2 创建Data. Frame n 6. 3 Data. Frame操作 n 6. 4 Spark SQL实例 n 6. 5 本章小结 n 思考与习题


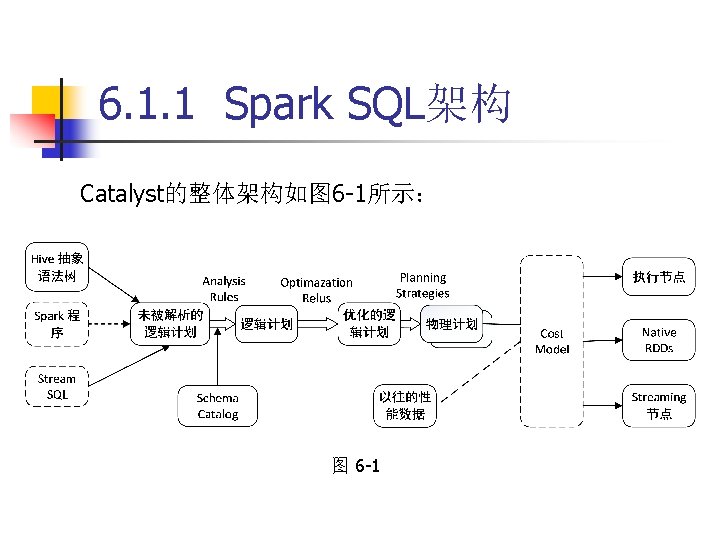

Analyzer:主要完成绑定 作,将不同来源的 Unresolved Logical Plan和数据元数据(如Hive metastore、 Schema Catalog)进行绑定,生成Resolved Logical")
6. 1. 1 Spark SQL架构 (2)Analyzer:主要完成绑定 作,将不同来源的 Unresolved Logical Plan和数据元数据(如Hive metastore、 Schema Catalog)进行绑定,生成Resolved Logical Plan。 (3)Optimizer:对Resolved Logical Plan进行优化,生成 Optimized Logical Plan。
Planner:将Optimized Logical Plan转换为Physical Plan。 (5)Cost. Model:主要根据过去的性能统计数据,选择最 佳的物理执行计划。")
6. 1. 1 Spark SQL架构 (4)Planner:将Optimized Logical Plan转换为Physical Plan。 (5)Cost. Model:主要根据过去的性能统计数据,选择最 佳的物理执行计划。


6. 1. 1 Spark SQL架构 图 6 -2


6. 1. 2 程序主入口Spark. Session 从Spark 2. 0以上版本开始,Spark SQL模块的 编程主入口点是Spark. Session,替代了Spark 1. 6 中的SQLContext以及Hive. Context接口,实现了 SQLContext和Hive. Context对数据加载、转换、处 理等全部功能。



6. 1. 2 程序主入口Spark. Session




6. 1. 2 程序主入口Spark. Session 该文件在Spark安装文件的“/examples/src/main/resources” 目录下,读取文件时,需写出该文件所在的具体位置,在本书 中,具体位置为“/usr/local/spark-2. 3. 0 -binhadoop 2. 7/examples/src/main/resources/people. json”

6. 1. 2 程序主入口Spark. Session 代码 6 -2 scala> val df = spark. read. json("/usr/local/spark-2. 3. 0 -binhadoop 2. 7/examples/src/main/resources/people. json") //调用Data. Frame的create. Or. Replace. Temp. View方法,将df注册成people临时 表 scala>df. create. Or. Replace. Temp. View("people") //调用spark. Session提供的sql接口,对people临时表进行sql查询,sql()返回 的也是Data. Frame对象 scala>val sql. DF = spark. sql("SELECT * FROM people") scala>sql. DF. show() // +-----------+ // | age| name| // +----------+ // |null|Michael| // | 30 | Andy | // | 19 | Justin| // +----------+









6. 1. 3 Data. Frame与RDD





















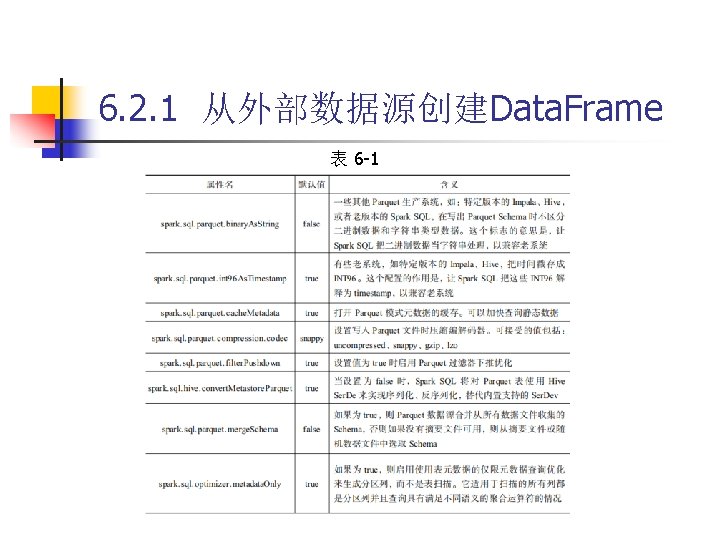












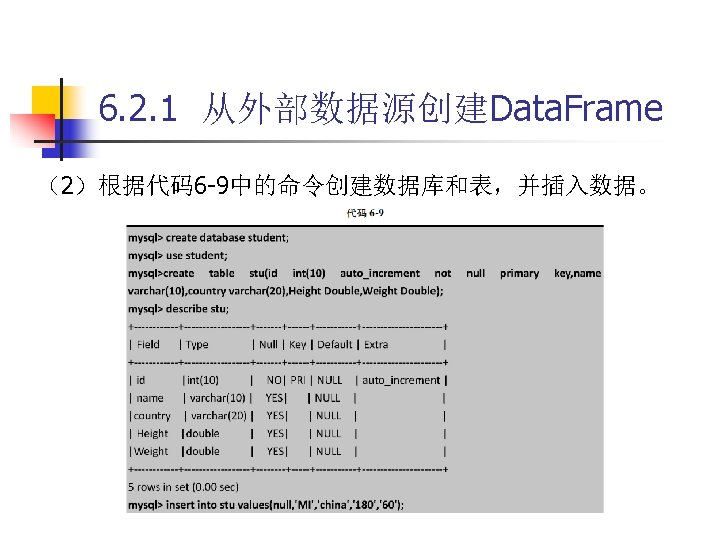
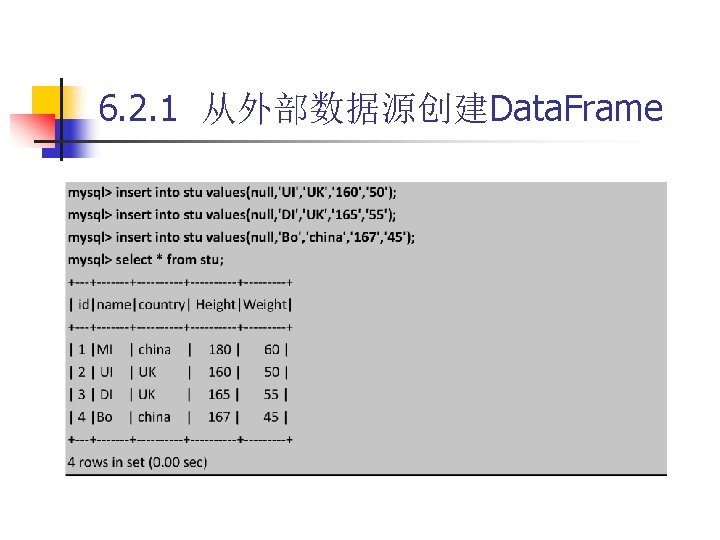
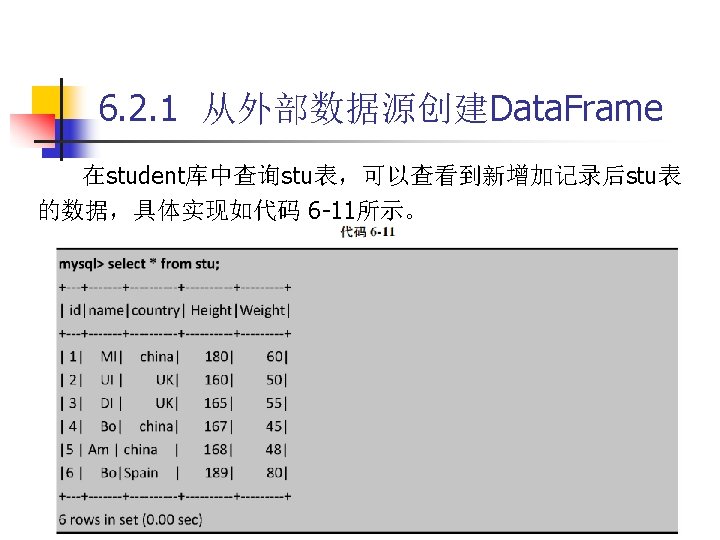
6. 2. 1 从外部数据源创建Data. Frame 代码 6 -7 spark-shell --jars /usr/local/spark-2. 3. 0 -bin-hadoop 2. 7/jars/mysql-connector-java 5. 1. 40/mysql-connector-java-5. 1. 40 -bin. jar --driver-class-path /usr/local/spark 2. 3. 0 -bin-hadoop 2. 7/jars/mysql-connector-java-5. 1. 40/mysql-connector-java 5. 1. 40 -bin. jar

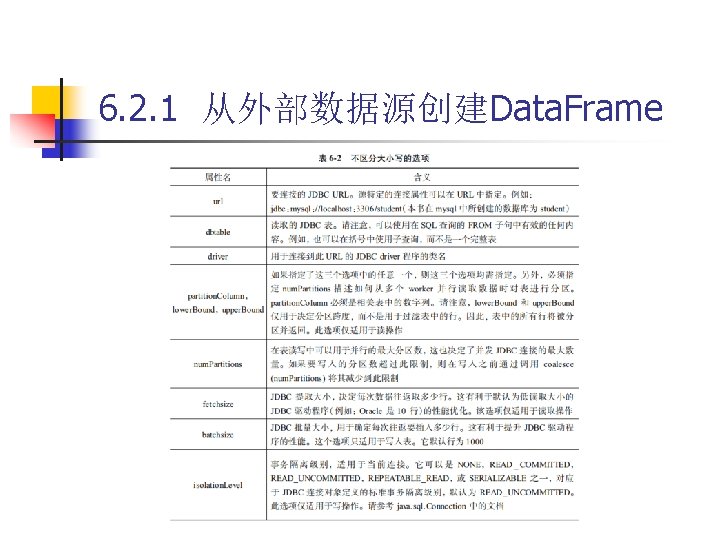












6. 2. 2 RDD转换为Data. Frame


6. 2. 2 RDD转换为Data. Frame


根据需求从原始RDD中创建一个Rows的RDD。 (2)创建一个表示为Struct. Type类型的Schema,匹配(1) 中创建的RDD的Rows的结构。 (3)通过Spark. Session提供的create. Data. Frame方法,应用 Schema到Rows的RDD。")
6. 2. 2 RDD转换为Data. Frame (1)根据需求从原始RDD中创建一个Rows的RDD。 (2)创建一个表示为Struct. Type类型的Schema,匹配(1) 中创建的RDD的Rows的结构。 (3)通过Spark. Session提供的create. Data. Frame方法,应用 Schema到Rows的RDD。


6. 2. 2 RDD转换为Data. Frame

6. 2. 2 RDD转换为Data. Frame

6. 2. 2 RDD转换为Data. Frame

6. 2. 2 RDD转换为Data. Frame 代码 6 -13示例中,Struct. Type和Struct. Field类型都位于 org. apache. spark. sql. types包中,其中 Struct. Field(name, datatype, nullable)表示Struct. Type中的字段, 字段中的名称由name表示,字段的数据类型由data. Type表示, nullable用于表示值是否允许为null值。Struct. Type(fields)表 示由Struct. Fields(fields)描述的序列,支持排序功能。




6. 3. 1 Transformation操作

6. 3. 1 Transformation操作


6. 3. 1 Transformation操作 代码 6 -14 scala> df. agg("age" -> "mean", "Height" -> "min", "Weight" -> "max"). show() +--------------+-----------------+ | avg(age)|min(Height)|max(Weight)| +--------------+-----------------+ |20. 90909091| 155| 85| +--------------+-----------------+

 res 11: org. apache. spark.")
6. 3. 1 Transformation操作 代码 6 -15 scala> df("Height") res 11: org. apache. spark. sql. Column = Height scala> df. apply("Weight") res 12: org. apache. spark. sql. Column = Weight
: Column 该方法用来获取指定字段,apply()和col()参数类型、 个数以及返回值类型均相同,只能获取某一列,返回对象 为Column类型,如代码 6 -16所示。")
6. 3. 1 Transformation操作 3. col(col. Name: String): Column 该方法用来获取指定字段,apply()和col()参数类型、 个数以及返回值类型均相同,只能获取某一列,返回对象 为Column类型,如代码 6 -16所示。 代码 6 -16 scala> df. col("name") res 4: org. apache. spark. sql. Column = name

, df(\"Weight\") as \"Weight_KG\"). show(6)")
6. 3. 1 Transformation操作 代码 6 -17 scala> df. select(df("name"), df("Weight") as "Weight_KG"). show(6) scala> df. select(df("name"), df("Weight")*2 as "Weight_Jin"). show(6)

. show(6) scala> df. select(\"age\").")
6. 3. 1 Transformation操作 代码 6 -18 scala> df. select("age"). show(6) scala> df. select("age"). distinct. show()

 scala> df. drop(\"institute\").")
6. 3. 1 Transformation操作 代码 6 -19 scala> df. print. Schema() scala> df. drop("institute"). print. Schema()
: Data. Frame 返回Data. Frame,包含当前Data. Frame的数据记录,同 时Rows不在另一个Data.")
6. 3. 1 Transformation操作 7. except(other: Data. Frame): Data. Frame 返回Data. Frame,包含当前Data. Frame的数据记录,同 时Rows不在另一个Data. Frame中,相当于两个Data. Frame 做减法。具体实现如代码 6 -20所示。

6. 3. 1 Transformation操作 代码 6 -20 scala> val newdf = spark. read. json("/home/ubuntu/newstudent. json") newdf: org. apache. spark. sql. Data. Frame = [Height: string, Weight: string. . . 4 more fields] scala> newdf. show(false)
")
6. 3. 1 Transformation操作 续代码 6 -20 scala> df. show(false)
. show(false)")
6. 3. 1 Transformation操作 续代码 6 -20 scala> df. except(newdf). show(false)
: Data. Frame 按参数指定的SQL表达式的条件过滤Data. Frame,如代 码 6")
6. 3. 1 Transformation操作 8. filter(condition. Expr: String): Data. Frame 按参数指定的SQL表达式的条件过滤Data. Frame,如代 码 6 -21所示。
. show(false) +---------+-----------+---------------------+-------+")
6. 3. 1 Transformation操作 代码 6 -21 scala> df. filter("age >24 "). show(false) +---------+-----------+---------------------+-------+ |Height|Weight|age|country | institute |name| +---------+-----------+---------------------+-------+ | 155 | 60 |25 |Portugal | chemical engineering institude|MY | +---------+-----------+---------------------+-------+

. agg(\"Height\" -> \"mean\").")
6. 3. 1 Transformation操作 代码 6 -22 scala> df. group. By("country"). agg("Height" -> "mean"). show() +-------------------+ |country| avg(Height)| +-------------------+ | Russia | 167. 0| | France | 187. 0| | Spain| 188. 0| |Geneva| 185. 0| | Japan | 180. 5| | china |172. 33333334| |Portugal| 155. 0| +-------------------+


. count(). show() +-----+-------+")
6. 3. 1 Transformation操作 代码 6 -23 scala> df. group. By("country"). count(). show() +-----+-------+ |country|count| +-----+-------+ | Russia | 1| | France| 1| | Spain| 2| |Geneva| 1| | Japan| 2| | china | 3| |Portugal| 1| +------+-------+
: Data. Frame 取两个Data. Frame中同时存在的数据记录,返回 Data. Frame。具体实现示例如代码")
6. 3. 1 Transformation操作 10. intersect(other: Data. Frame): Data. Frame 取两个Data. Frame中同时存在的数据记录,返回 Data. Frame。具体实现示例如代码 6 -24所示。
. show(false) +----------+------+-------------------------------+-------+ |Height|Weight|age|country| institute")
6. 3. 1 Transformation操作 代码 6 -24 scala> df. intersect(newdf). show(false) +----------+------+-------------------------------+-------+ |Height|Weight|age|country| institute |name| +----------+------+-------------------------------+-------+ | 185 | 75 |20 | china | computer science and technology department| MI | +----------+------+-------------------------------+-------+

. show(false) +---------+----------+-------------------------------+-------+ |Height|Weight|age|country |institute")
6. 3. 1 Transformation操作 代码 6 -25 scala> df. limit(3). show(false) +---------+----------+-------------------------------+-------+ |Height|Weight|age|country |institute |name| +---------+----------+-------------------------------+-------+ | 185 | 75 | 20 | china | computer science and technology department| MI | | 187 | 70 | 21 | Spain | medical college | MU| | 155 | 60 | 25 |Portugal| chemical engineering institude | MY | +----------+-------+-------------------------------+-------+

. show(false)")
6. 3. 1 Transformation操作 代码 6 -26 scala> df. order. By("age", "Height"). show(false)


. show(false)")
6. 3. 1 Transformation操作 代码 6 -27 scala> df. sort($"age". desc). show(false)
: Data. Frame sample对数据集进行采样,返回一个新的Data. Frame。")
6. 3. 1 Transformation操作 14. sample(with. Replacement: Boolean, fraction: Double): Data. Frame sample对数据集进行采样,返回一个新的Data. Frame。 with. Replacement=true,表示重复抽样; with. Replacement=false,表示不重复抽样;fraction参数是 生成行的比例。具体实现如代码 6 -28所示。
. show() scala>")
6. 3. 1 Transformation操作 代码 6 -28 scala> df. sample(true, 0. 5). show() scala> df. sample(false, 0. 5). show()


. show() scala>")
6. 3. 1 Transformation操作 代码 6 -29 scala> df. where("name = 'Ar'"). show() scala> df. where($"age">24). show()



6. 3. 1 Transformation操作 代码 6 -30 scala> val joindf = spark. read. json("/home/ubuntu/joininfo. json") joindf: org. apache. spark. sql. Data. Frame = [math_score: bigint, name: string] scala> joindf. show() scala> df. join(joindf, "name"). show()



6. 3. 1 Transformation操作 代码 6 -31 scala> val na_df = spark. read. json("/home/ubuntu/ex. Student. json") na_df: org. apache. spark. sql. Data. Frame = [Height: string, Weight: string. . . 4 more fields] scala> na_df. show() +---------+----------+-------+ |Height|Weight| age|country|institute|name| +---------+----------+-------+ | 185| 75|null| china| null| MI | | 187| 70| 21 | china| null| MU| | null|null| null| | 166| 62| 19| Japan| SEM| MK| | 164| 55| 20| china| SEM| By| | 195| 85| 20| Japan| SEM| CY| +---------+----------+-------+
. show() +---------+----------+-------+ |Height|Weight|age|country|institute|name|")
6. 3. 1 Transformation操作 续代码 6 -31 scala> na_df. na. drop(). show() +---------+----------+-------+ |Height|Weight|age|country|institute|name| +---------+----------+-------+ | 166| 62| 19 | Japan| SEM| MK | | 164| 55| 20 | china| SEM| By| | 195| 85| 20 | Japan| SEM| CY| +---------+----------+-------+
, (\"institute\", \"jsj\"), (\"Height\",")
6. 3. 1 Transformation操作 续代码 6 -31 scala>na_df. na. fill(Map(("age", 0), ("institute", "jsj"), ("Height", "0"), ("Weight", "0"), (" country", "china"), ("name", "XXX"))). show() +---------+----------+-------+ |Height|Weight|age|country|institute|name| +---------+----------+-------+ | 185| 75| 0| china| jsj| MI| | 187| 70| 21 | china| jsj| MU | | 0| 0| 0| china| jsj| XXX| | 166| 62| 19| Japan| SEM| MK | | 164| 55| 20| china| SEM| By| | 195| 85| 20| Japan| SEM| CY| +---------+----------+-------+


6. 3. 2 Action操作

 res 83: Array[org. apache.")
6. 3. 1 Transformation操作 代码 6 -32 scala> df. collect() res 83: Array[org. apache. spark. sql. Row] = Array([185, 75, 20, china, computer science and technology department, MI], [187, 70, 21, Spain, medical college, MU], [155, 60, 25, Portugal, chemical engineering institude, MY], [166, 62, 19, Japan, SEM, MK], [187, 80, 24, France, school of materials, Ab], [167, 60, 21, Russia, school of materials, Ar], [185, 75, 20, Geneva, medical college, Ad], [168, 48, 20, china, computer science and technology department, Am], [189, 80, 20, Spain, chemical engineering institude, Bo], [164, 55, 20, china, SEM, By], [195, 85, 20, Japan, SEM, CY])

 res 84:")
6. 3. 1 Transformation操作 代码 6 -33 scala> df. collect. As. List() res 84: java. util. List[org. apache. spark. sql. Row] = [[185, 75, 20, china, computer science and technology department, MI], [187, 70, 21, Spain, medical college, MU], [155, 60, 25, Portugal, chemical engineering institude, MY], [166, 62, 19, Japan, SEM, MK], [187, 80, 24, France, school of materials, Ab], [167, 60, 21, Russia, school of materials, Ar], [185, 75, 20, Geneva, medical college, Ad], [168, 48, 20, china, computer science and technology department, Am], [189, 80, 20, Spain, chemical engineering institude, Bo], [164, 55, 20, china, SEM, By], [195, 85, 20, Japan, SEM, CY]]
: Long 返回Data. Frame的数据记录的条数,如代码 6 -34所示。 代码 6 -34")
6. 3. 2 Action操作 3. count(): Long 返回Data. Frame的数据记录的条数,如代码 6 -34所示。 代码 6 -34 scala> df. count() res 85: Long = 11

. show() +---------------------+ |summary| Height|")
6. 3. 1 Transformation操作 代码 6 -35 scala> df. describe("Height"). show() +---------------------+ |summary| Height| +---------------------+ | count | 11 | | mean | 177. 0909091| | stddev|13. 232192149863495| | min | 155 | | max | 195| +---------------------+
: Row 返回Data. Frame的第一行,等同于head()方法,如代码 6 -36所示。 代码 6 -36")
6. 3. 2 Action操作 5. first(): Row 返回Data. Frame的第一行,等同于head()方法,如代码 6 -36所示。 代码 6 -36 scala> df. first() res 87: org. apache. spark. sql. Row = [185, 75, 20, china, computer science and technology department, MI]
: Row 不带参数的head方法,返回Data. Frame的第一条数据记录, 指定参数n时,则返回前n条数据记录,如代码 6 -37所示。 代码 6")
6. 3. 2 Action操作 6. head(): Row 不带参数的head方法,返回Data. Frame的第一条数据记录, 指定参数n时,则返回前n条数据记录,如代码 6 -37所示。 代码 6 -37 scala> df. head(2) res 88: Array[org. apache. spark. sql. Row] = Array([185, 75, 20, china, computer science and technology department, MI], [187, 70, 21, Spain, medical college, MU])

 scala> df. show(2,")
6. 3. 2 Action操作 代码 6 -38 scala> df. show(2, false) scala> df. show(2, true)

 res 91: Array[org. apache.")
6. 3. 1 Transformation操作 代码 6 -39 scala> df. take(2) res 91: Array[org. apache. spark. sql. Row] = Array([185, 75, 20, china, computer science and technology department, MI], [187, 70, 21, Spain, medical college, MU])


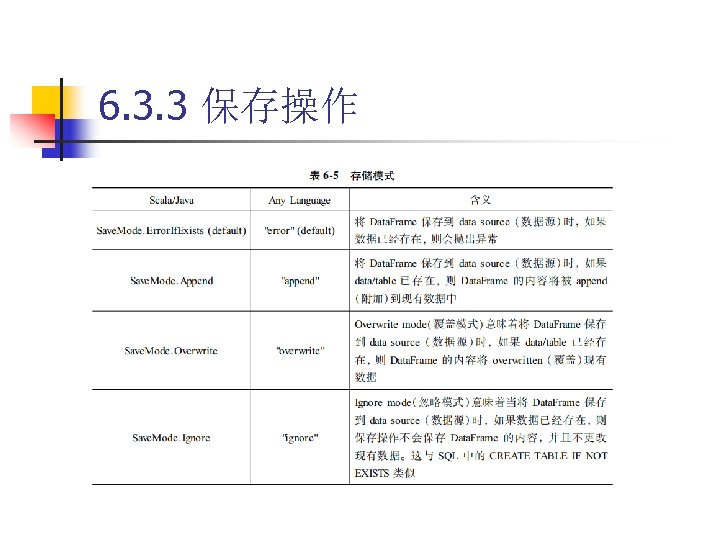
6. 3. 3 保存操作 代码 6 -40 //读取parquet格式数据 scala>val users. DF = spark. read. load("examples/src/main/resources/users. parquet") //保存成Parquet格式 scala>users. DF. write. save("user. Info. parquet") //也可以选择部分数据保存成Parquet格式 scala>users. DF. select("name", "favorite_color"). write. save("names. And. Fav. Colors. pa rquet")


6. 3. 3 保存操作 代码 6 -41 scala> val people. Df = spark. read. format("json"). load("/home/ubuntu/student. json") people. Df: org. apache. spark. sql. Data. Frame = [age: string, institute: string. . . 3 more fields] scala>people. Df. select("name", "age"). write. format("parquet"). save("name. And. Ages. Inf o. parquet")





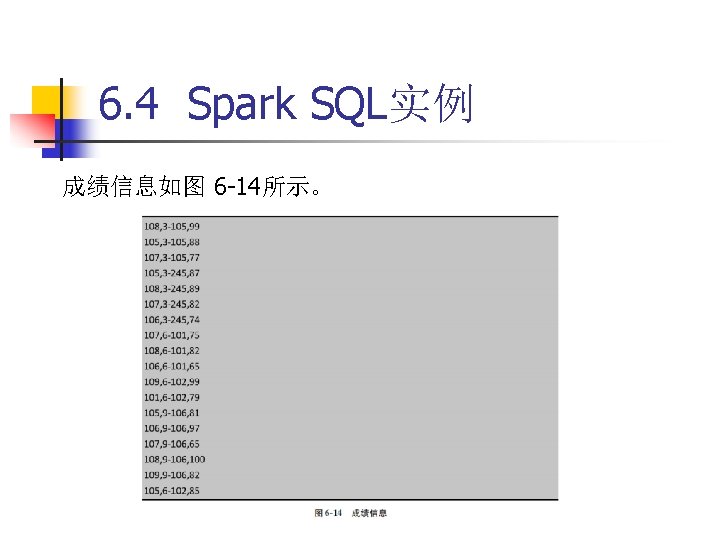


6. 4 Spark SQL实例

6. 4 Spark SQL实例

6. 4 Spark SQL实例

6. 4 Spark SQL实例

6. 4 Spark SQL实例

6. 4 Spark SQL实例

6. 4 Spark SQL实例

6. 4 Spark SQL实例

6. 4 Spark SQL实例

6. 4 Spark SQL实例





- Slides: 184