Spark Scala http aibigdata csu edu cn n
 http: //aibigdata. csu. edu. cn")
Spark大数据 编程基础(Scala版) http: //aibigdata. csu. edu. cn



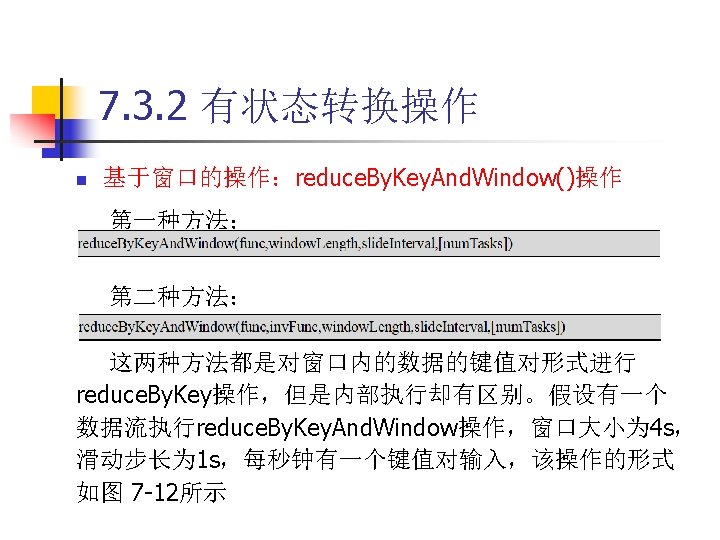
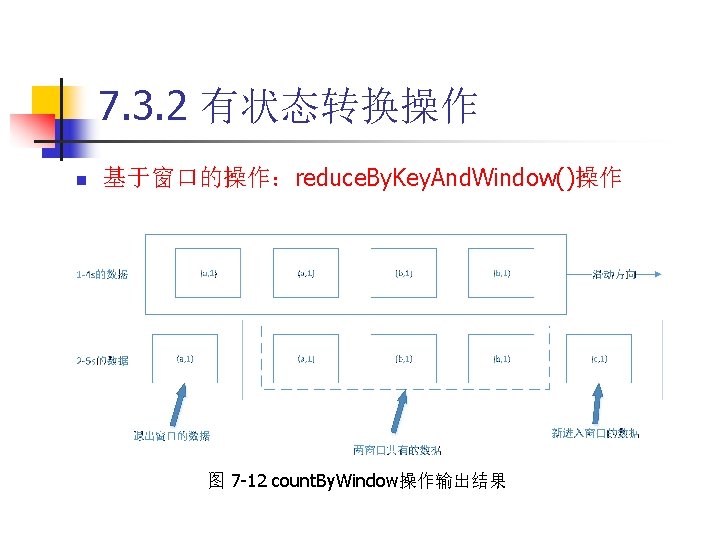
主要内容 n 7. 1 Spark Streaming 作机制 n 7. 2 DStream输入源 n 7. 3 DStream转换操作 n 7. 4 DStream输出操作 n 7. 5 Spark Streaming处理流式数据 n 7. 6 Spark Streaming性能调优 n 7. 7 本章小结


7. 1. 1 Spark Streaming 作流程 图 7 -1 Spark Streaming数据输入/输出图



7. 1. 1 Spark Streaming 作流程 n Streaming. Context对象 在RDD编程中需要生成一个Spark. Context对象,在 Spark SQL中需要生成一个Spark. Session对象,同理, 如果要运行一个Spark Streaming程序,就需要生成一 个Streaming. Context对象,它是Spark Streaming程序 的主入口。

7. 1. 1 Spark Streaming 作流程 n Streaming. Context对象 可以从一个Spark. Conf对象中创建一个Streaming. Context 对象。在spark-shell中,由于默认了一个Spark. Context对象, 也就是sc,因此,可以用代码7 -1创建Streaming. Context对象: 代码7 -1 import org. apache. spark. streaming. _ val ssc = new Streaming. Context(sc, Seconds(1))


7. 1. 1 Spark Streaming 作流程 n Streaming. Context对象 如果是编写一个独立的Spark Streaming程序,则需要 在代码文件中用代码7 -2创建Streaming. Context对象。 代码7 -2





7. 1. 2 Spark Streaming处理机制 n DStream Spark Streaming应用程序中,除了使用数据源产生的 数据流来创建DStream,也会在已有的DStream上使用某种 操作创建新的DStream,图 7 -4显示了对lines DStream做 flat. Map操作产生新的words DStream。 图 7 -4利用flat. Map操作把行DStream转换为单词DStream的过程











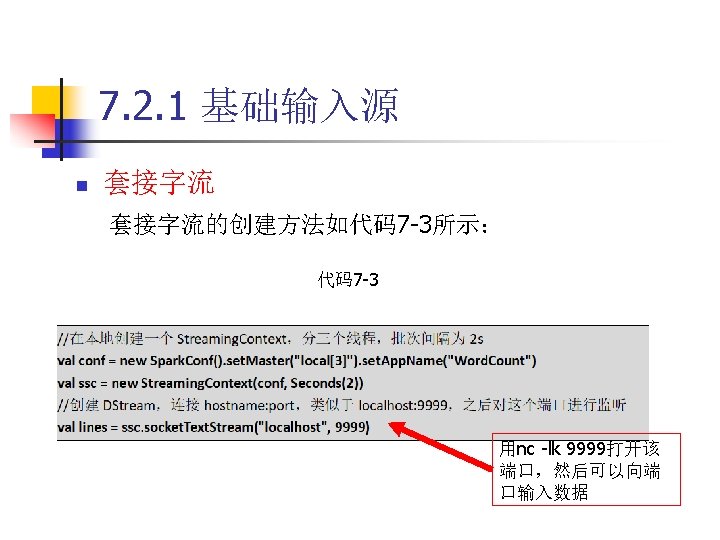



把Kafka目录中的libs目录添加到 程中。 (3)导入Kafka. Utils类并创建基于Kafka的Dstream,如代 码7 -4所示,具体细节参考 https: //spark.")
7. 2. 2 高级输入源 n Kafka (2)把Kafka目录中的libs目录添加到 程中。 (3)导入Kafka. Utils类并创建基于Kafka的Dstream,如代 码7 -4所示,具体细节参考 https: //spark. apache. org/docs/2. 3. 3/streaming-kafka-08 -integration. html 代码 7 -4

把Flume目录中的lib文件夹添加到 程中。 (3)导入 Flume. Utils类并创建基于Flume的Dstream,如代 码7 -5所示,具体细节参考 https:")
7. 2. 2 高级输入源 n Flume (2)把Flume目录中的lib文件夹添加到 程中。 (3)导入 Flume. Utils类并创建基于Flume的Dstream,如代 码7 -5所示,具体细节参考 https: //spark. apache. org/docs/2. 3. 3/streaming-flumeintegration. html 代码 7 -5































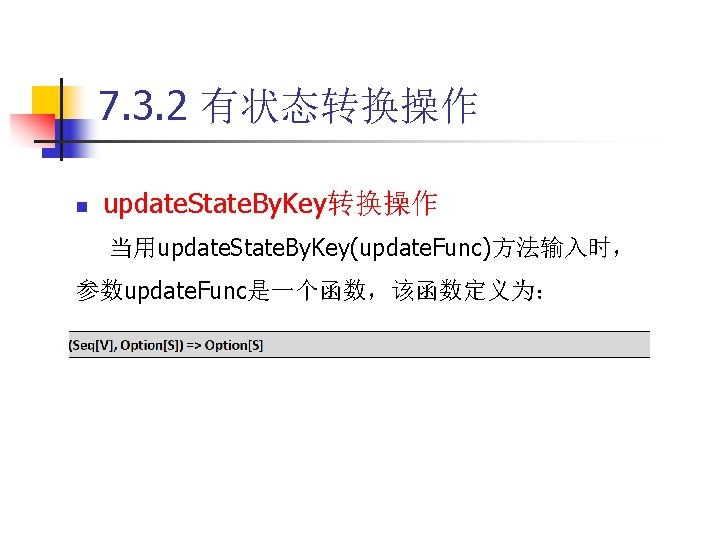




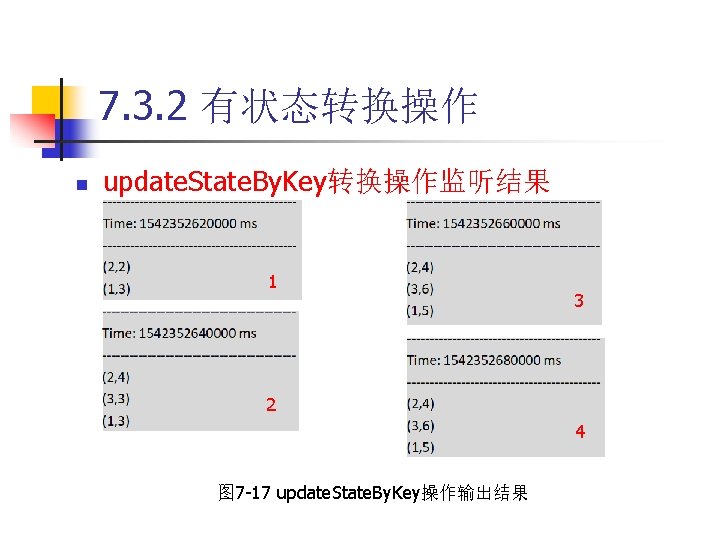




7. 4 DStream输出操作 n save. As. Text. Files操作 代码7 -10


















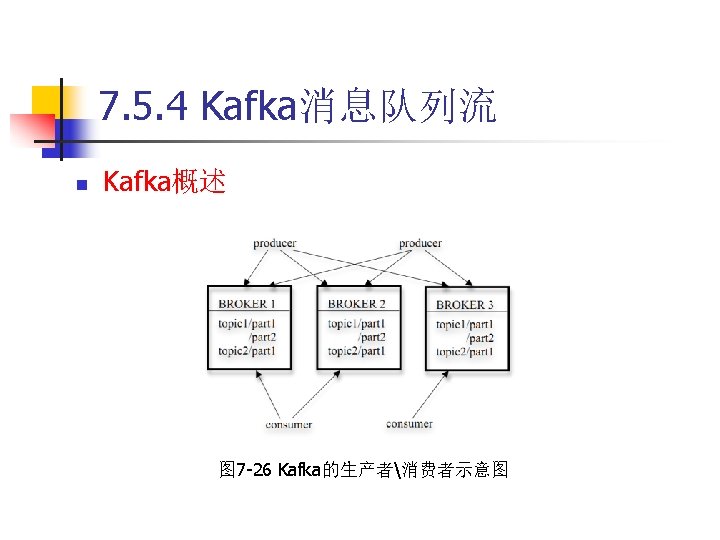


对Kafka的安装进行测试: 1)在解压后的Kafka文件夹下打开终端,执行命令来启 动Zookeeper服务: $ bin/zookeeper-server-start. sh config/zookeeper. properties")
7. 5. 4 Kafka消息队列流 n 安装于配置Kafka (2)对Kafka的安装进行测试: 1)在解压后的Kafka文件夹下打开终端,执行命令来启 动Zookeeper服务: $ bin/zookeeper-server-start. sh config/zookeeper. properties



配置Kafka依赖 1)下载spark-streaming-kafka-0 -8_2. 11. jar包。在命令行输入: $ wget http:")
7. 5. 4 Kafka消息队列流 n 安装于配置Kafka (3)配置Kafka依赖 1)下载spark-streaming-kafka-0 -8_2. 11. jar包。在命令行输入: $ wget http: //central. maven. org/maven 2/org/apache/spark-streamingkafka-0 -8_2. 11/2. 3. 3/spark-streaming-kafka-0 -8_2. 11 -2. 3. 3. jar (注:Kafka的依赖包需要和Spark与Scala的版本相对应,具 体版本对应的信息可查看 https: //mvnrepository. com/artifact/org. apache. spark/spark-
把spark-streaming-kafka-0 -8_2. 11. jar和Kafka目录下 的libs文件夹中的jar包导入 程。")
7. 5. 4 Kafka消息队列流 n 安装于配置Kafka 2)把spark-streaming-kafka-0 -8_2. 11. jar和Kafka目录下 的libs文件夹中的jar包导入 程。




 (2)在 程中创建Streaming. Examples. scala文件,用 于设置log 4 j日志级别,该文件路径为Spark安装目录 下的")
7. 5. 4 Kafka消息队列流 n Kafka示例(创建过程) (2)在 程中创建Streaming. Examples. scala文件,用 于设置log 4 j日志级别,该文件路径为Spark安装目录 下的 /examples/src/main/scala/org/apache/spark/exampl es/streaming,如代码 7 -15所示:




 (4)设置生产者的配置参数,点击Run中的Debug Configurations,并在Kafka. Word. Count. Producer中的 program arguments输入信息如图 7")
7. 5. 4 Kafka消息队列流 n Kafka示例(创建过程) (4)设置生产者的配置参数,点击Run中的Debug Configurations,并在Kafka. Word. Count. Producer中的 program arguments输入信息如图 7 -29所示: 图 7 -29 配置参数图






















- Slides: 138