Spark Scala http aibigdata csu edu cn 9
 http: //aibigdata. csu. edu. cn")
Spark大数据 编程基础(Scala版) http: //aibigdata. csu. edu. cn








")
9. 1 Spark机器学习简介 � 9‑ 1 spark. ml� (Spark 2. 3. 0)
")
9. 1 Spark机器学习简介 � 9‑ 1 spark. ml� (Spark 2. 3. 0)


9. 2. 1 Pipeline概念 Pipeline的相关概念有: l Data. Frame l Transformer l Estimator l Parameter









9. 2. 2 Pipeline 作流程 stage分为:Transformer和Estimator。Transformer主要用 于在一个Data. Frame的基础上生成另一个Data. Frame,而 Estimator主要用于数据拟合,用于生成一个Transformer。将 以处理文档数据的 作流为例,介绍Pipeline模型。
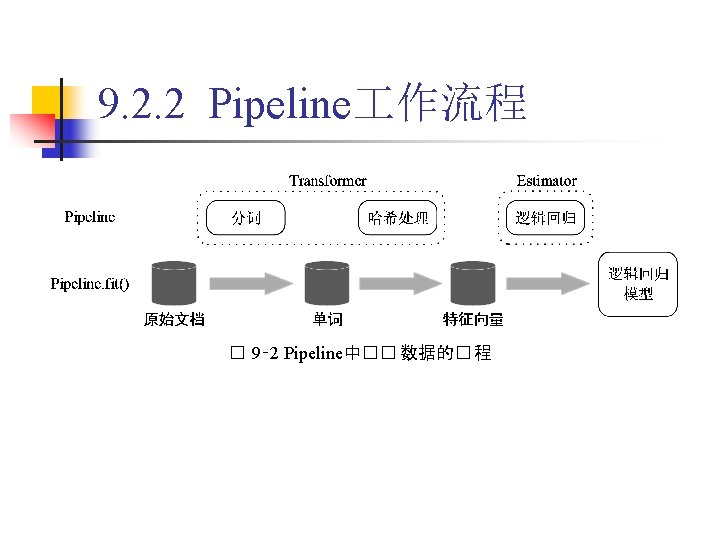



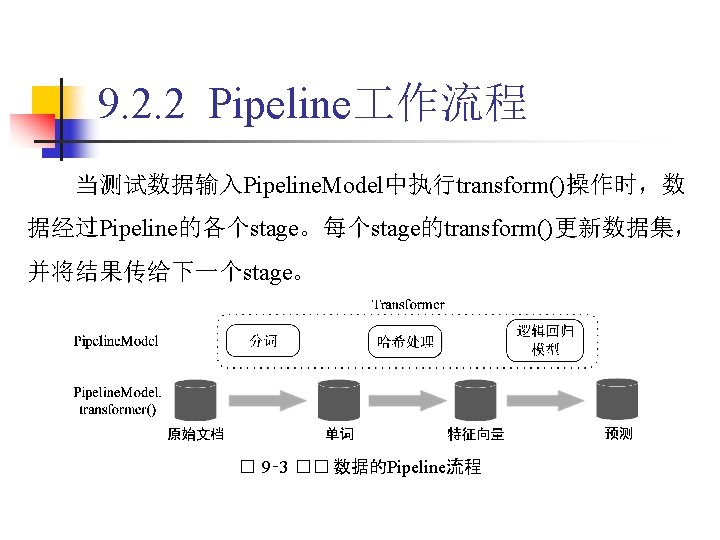
转变为 Transformer(转换器)。 � 9‑ 3")
9. 2. 2 Pipeline 作流程 在图 9 -3中,Pipeline. Model和原始的Pipeline有相同的stage。 不同的是,原始Pipeline中的Estimator(评估器)转变为 Transformer(转换器)。 � 9‑ 3 �� 数据的Pipeline流程



 唯一的Pipeline stage ID 组成Pipeline的stage,必须有唯一的实例ID,例如 Hashing. TF(Transformer)的实例my. Hashing. TF不能在Pipeline")
9. 2. 2 Pipeline 作流程 (3) 唯一的Pipeline stage ID 组成Pipeline的stage,必须有唯一的实例ID,例如 Hashing. TF(Transformer)的实例my. Hashing. TF不能在Pipeline 中使用两次。但是可以创建两个Hashing. TF(Transformer)实 例my. Hashing. TF 1和my. Hashing. TF 2,在同一个Pipeline中出现, 因为不同的实例会创建不同的ID。

9. 2. 3 Pipeline实例 本小节中,将介绍两个实例: l Transformer、Estimatior和Parameter实例; l Pipeline构建使用实例。


9. 2. 3 Pipeline实例 1. Transformer、Estimator和Parameter实例 代� 9‑ 1

9. 2. 3 Pipeline实例 1. Transformer、Estimator和Parameter实例 � 代� 9‑ 1

9. 2. 3 Pipeline实例 1. Transformer、Estimator和Parameter实例 � 代� 9‑ 1

9. 2. 3 Pipeline实例 1. Transformer、Estimator和Parameter实例 � 代� 9‑ 1

9. 2. 3 Pipeline实例 1. Transformer、Estimator和Parameter实例 � 代� 9‑ 1

9. 2. 3 Pipeline实例 1. Transformer、Estimator和Parameter实例 � 代� 9‑ 1



9. 2. 3 Pipeline实例 � 9‑ 4 Transformer、Estimator和Parameter� 例� 出

9. 2. 3 Pipeline实例 � 9‑ 4 Transformer、Estimator和Parameter� 例� 出

9. 2. 3 Pipeline实例 � 9‑ 4 Transformer、Estimator和Parameter� 例� 出

9. 2. 3 Pipeline实例 � 9‑ 4 Transformer、Estimator和Parameter� 例� 出

9. 2. 3 Pipeline实例 � 9‑ 4 Transformer、Estimator和Parameter� 例� 出

9. 2. 3 Pipeline实例 � 9‑ 4 Transformer、Estimator和Parameter� 例� 出



9. 2. 3 Pipeline实例 2. Pipeline构建使用实例 代� 9‑ 2





. save(保存路 径)保存到磁盘中。")
9. 2. 3 Pipeline实例 训练完成的Pipeline. Model调用. write. overwrite(). save(保存路 径)保存到磁盘中。

方法加载调用保存在本 地的Pipeline. Model。")
9. 2. 3 Pipeline实例 使用Pipeline. Model. load(存储路径)方法加载调用保存在本 地的Pipeline. Model。































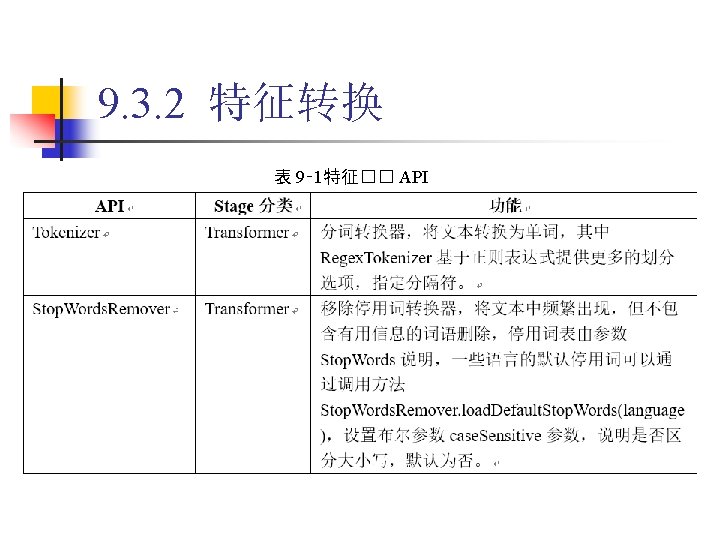
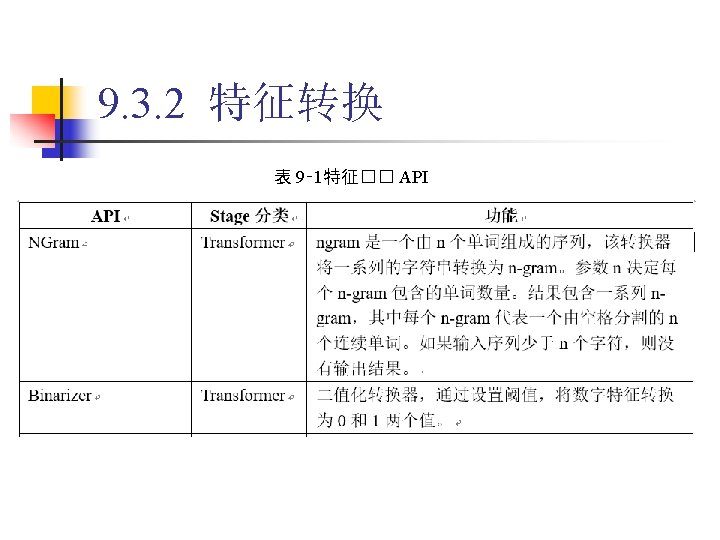
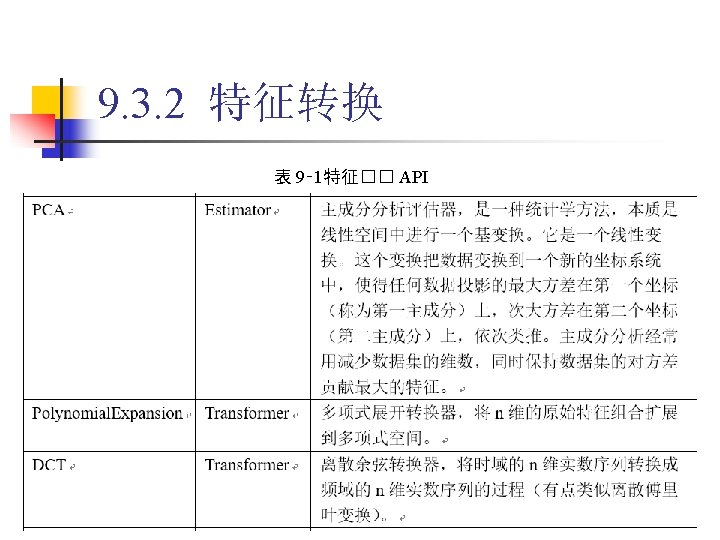

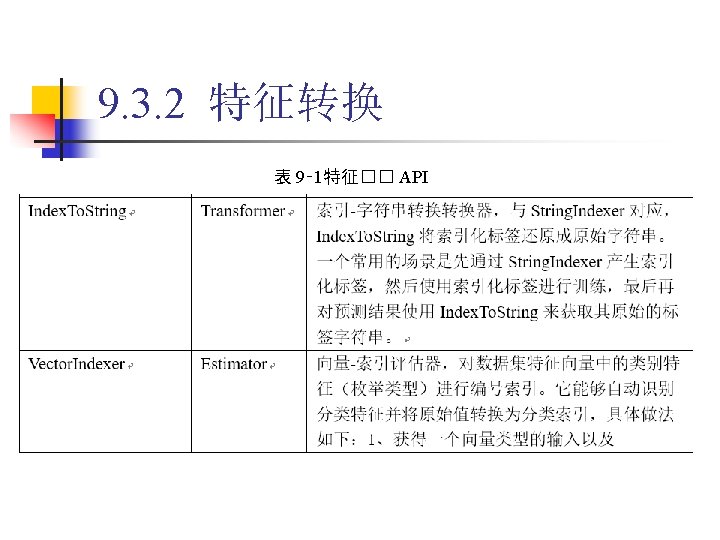
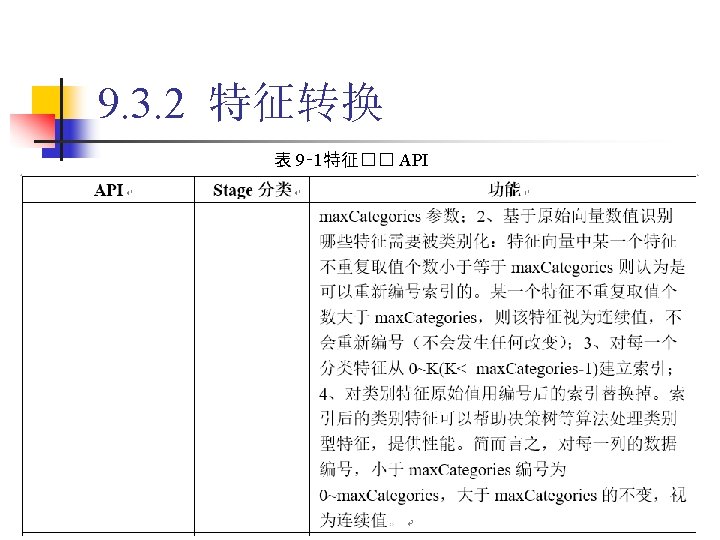
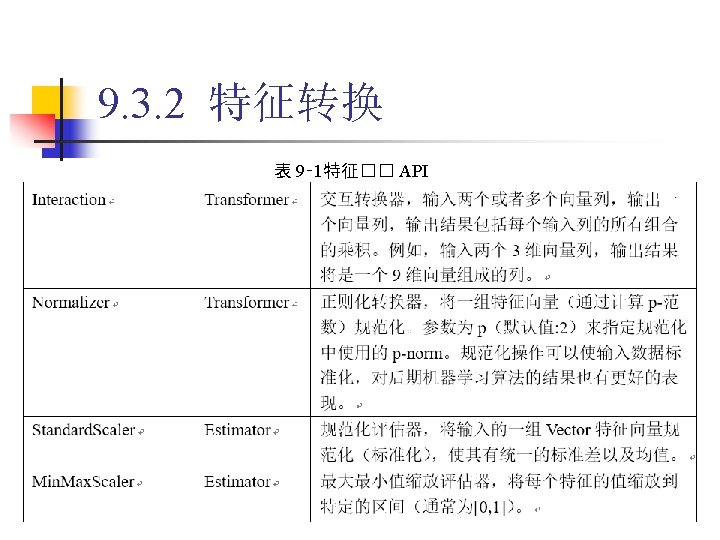
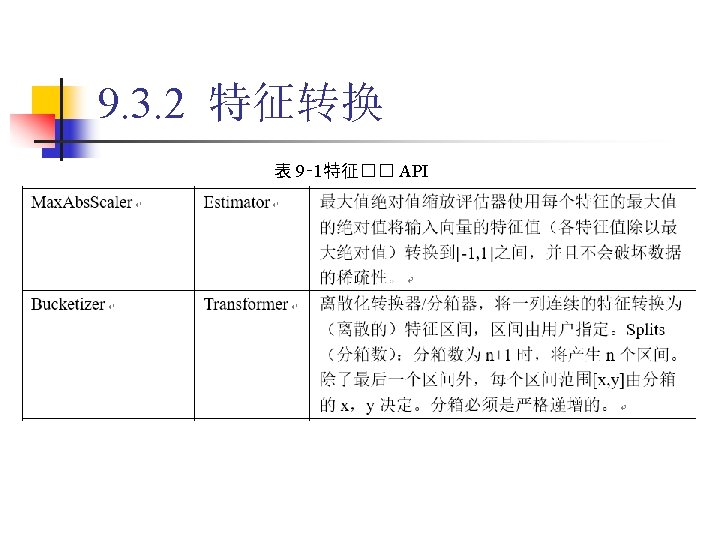

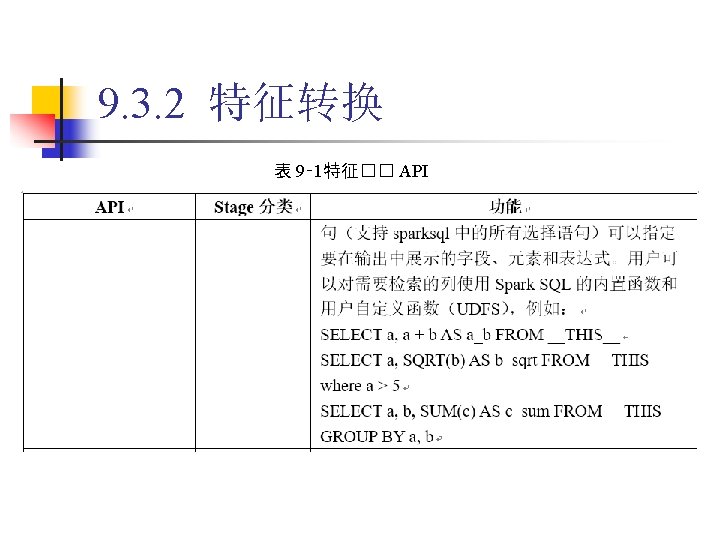
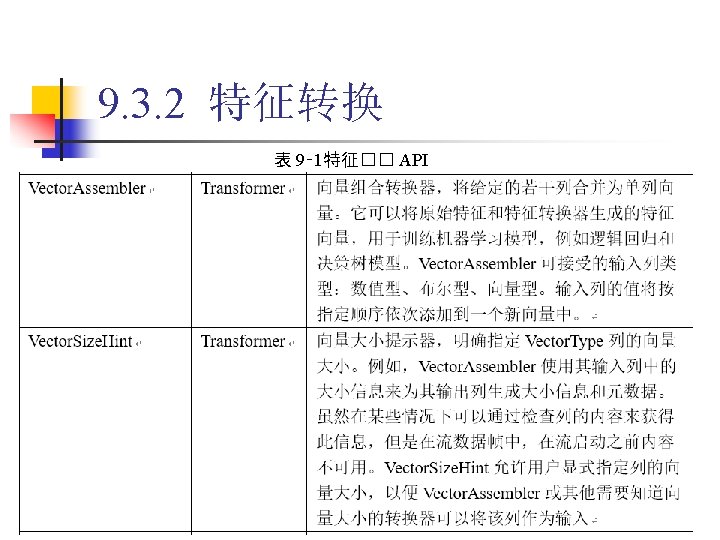



9. 3. 2 特征转换 1. Binarizer 代� 9‑ 5








9. 3. 2 特征转换 2. Min. Max. Scaler 代� 9‑ 6








9. 3. 2 特征选择 1. Vector. Slicer 假设有一个Data. Frame,列名为user. Features,具体内容如 图 9 -10所示。 � 9‑ 10 user. Features



9. 3. 2 特征选择 1. Vector. Slicer 代� 9‑ 7

9. 3. 2 特征选择 1. Vector. Slicer � 代� 9‑ 7

9. 3. 2 特征选择 1. Vector. Slicer � 代� 9‑ 7

9. 3. 2 特征选择 1. Vector. Slicer � 代� 9‑ 7






9. 3. 2 特征选择 2. RFormula 假设现在有一个包括id、country、hour、clicked四列的 Data. Frame,如图 9 -14所示。使用R公式clicked~country+hour, 表示基于country和hour信息预测clicked值,通过转换可以得到 如图 9 -15所示。 � 9‑ 14初始Data. Frame � 9‑ 15� 果Data. Frame









9. 3. 2 特征选择 3. Chi. Sq. Selector 举例:如图 9 -17所示的Data. Frame,包含三列数据,列名为 id,features,clicked,其中clicked是预测值。 � 9‑ 17 初始Data. Frame

9. 3. 2 特征选择 3. Chi. Sq. Selector 使用Chi. Sq. Selector,且设置num. Top. Features=1。根据预测 目标clicked,features的第三列被选为最有效的特征。如图 9 -18 所示,新增的selected. Features列表示选出的特征。 � 9‑ 18 � 果Data. Frame


9. 3. 2 特征选择 3. Chi. Sq. Selector 代� 9‑ 9

9. 3. 2 特征选择 3. Chi. Sq. Selector � 代� 9‑ 9

9. 3. 2 特征选择 3. Chi. Sq. Selector � 代� 9‑ 9

9. 3. 2 特征选择 3. Chi. Sq. Selector � 代� 9‑ 9





9. 4. 1 模型选择 对于回归模型,通常选择Regression. Evaluator作为Evaluator, 对二分类模型,通常选择Binary. Classification. Evaluator作为 Evaluator; 对于多分类问题,通常选择Multiclass. Classification Evaluator作为Evaluator。Evaluator中默认的评估准则,可通过调 用set. Metric. Name方法重写。














9. 4. 3 Train. Validation. Split 和Cross. Validator一样,Train. Validation. Split使用最佳的参数 Para. Map和整个数据集训练Estimator。在本小节实例中,将通过 代码9 -11所示实例介绍使用Train. Validation. Split进行超参调优。

9. 4. 3 Train. Validation. Split 代� 9‑ 11

9. 4. 3 Train. Validation. Split � 代� 9‑ 11

9. 4. 3 Train. Validation. Split � 代� 9‑ 11

9. 4. 3 Train. Validation. Split � 代� 9‑ 11

9. 4. 3 Train. Validation. Split 输出结果如图 9 -21所示。 � 9‑ 21 Train. Validation. Split超参��� 例� 出

9. 4. 3 Train. Validation. Split � 9‑ 21 Train. Validation. Split超参��� 例� 出




- Slides: 176