Spark 1 0 and Beyond Patrick Wendell Databricks

Spark 1. 0 and Beyond Patrick Wendell Databricks Spark. incubator. apache. org

About me Committer and PMC member of Apache Spark “Former” Ph. D student at Berkeley Release manager for Spark 1. 0 Background in networking and distributed systems

Today’s Talk Spark background About the Spark release process The Spark 1. 0 release Looking forward to Spark 1. 1

What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop 10× faster o 100× in m n disk, 2 -5× less emory code Efficient Usable Up to General execution graphs In-memory storage Rich APIs in Java, Scala, Python Interactive shell

30 -Day Commit Activity 250 200 45000 16000 40000 14000 35000 12000 30000 150 10000 25000 8000 20000 100 6000 15000 4000 10000 50 0 Patches 5000 2000 0 0 Lines Removed Lines Added Map. Reduce Storm Yarn Spark

Spark Philosophy Make life easy and productive for data scientists Well documented, expressive API’s Powerful domain specific libraries Easy integration with storage systems … and caching to avoid data movement Predictable releases, stable API’s
 2 months of general development 1")
Spark Release Process Quarterly release cycle (3 months) 2 months of general development 1 month of polishing, QA and fixes Spark 1. 0 Feb 1 April 8 th, April 8 th+ Spark 1. 1 May 1 July 8 th, July 8 th+

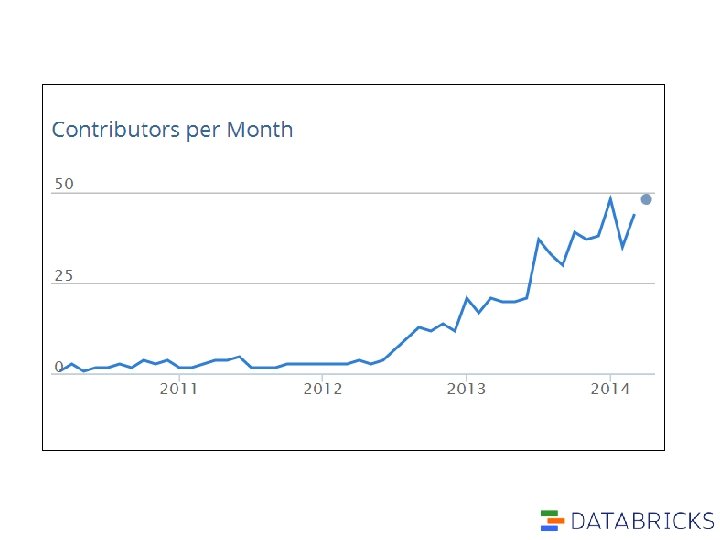
Spark 1. 0: By the numbers - 3 months of development - 639 patches - 200+ JIRA issues - 100+ contributors

API Stability in 1. X API’s are stable for all non-alpha projects Spark 1. 1, 1. 2, … will be compatible @Developer. Api Internal API that is unstable @Experimental User-facing API that might stabilize

Today’s Talk About the Spark release process The Spark 1. 0 release Looking forward to Spark 1. 1

Spark 1. 0 Features Core engine improvements Spark streaming MLLib Spark SQL

Spark Core History server for Spark UI Integration with YARN security model Unified job submission tool Java 8 support Internal engine improvements

History Server Configure with : spark. event. Log. enabled=true spark. event. Log. dir=hdfs: //XX In Spark Standalone, history server is embedded in the master. In YARN/Mesos, run history server as a daemon.
.")
Job Submission Tool Apps don’t need to hard-code master: conf = new Spark. Conf(). set. App. Name(“My App”) sc = new Spark. Context(conf) . /bin/spark-submit <app-jar> --class my. main. Class --name my. App. Name --master local[4] --master spark: //some-cluster

Java 8 Support RDD operations can use lambda syntax class Split extends Flat. Map. Function<String, String> { public Iterable<String> call(String s) { return Arrays. as. List(s. split(" ")); } ); Java. RDD<String> words = lines. flat. Map(new Split()); Old Java. RDD<String> words = lines. flat. Map(s -> Arrays. as. List(s. split(" "))); New
 If you are extending Function classes,")
Java 8 Support NOTE: Minor API changes (a) If you are extending Function classes, use implements rather than extends. (b) Return-type sensitive functions map. To. Pair map. To. Double
, take(), top. Ordered() meta-data name(), id(), get. Storage.")
Python API Coverage rdd operators intersection(), take(), top. Ordered() meta-data name(), id(), get. Storage. Level() runtime configuration set. Job. Group(), set. Local. Property()

Integration with YARN Security Supports Kerberos authentication in YARN environments: spark. authenticate = true ACL support for user interfaces: spark. ui. acls. enable = true spark. ui. view. acls = patrick, matei

Engine Improvements Job cancellation directly from UI Garbage collection of shuffle and RDD data

Documentation Unified Scaladocs across modules Expanded MLLib guide Deployment and configuration specifics Expanded API documentation

Schema. RDD’s Spark SQL DStream’s: Streams of RDD’s RDD-Based Matrices Spark Streaming MLLib real-time machine learning RDDs, Transformations, and Actions Spark

Spark SQL

Turning an RDD into a Relation // Define the schema using a case class Person(name: String, age: Int) // Create an RDD of Person objects, register it as a table. val people = sc. text. File("examples/src/main/resources/people. txt"). map(_. split(", "). map(p => Person(p(0), p(1). trim. to. Int)) people. register. As. Table("people")

Querying using SQL // SQL statements can be run directly on RDD’s val teenagers = sql("SELECT name FROM people WHERE age >= 13 AND age <= 19") // The results of SQL queries are Schema. RDDs and support // normal RDD operations. val name. List = teenagers. map(t => "Name: " + t(0)). collect() // Language integrated queries (ala LINQ) val teenagers = people. where('age >= 10). where('age <= 19). select('name)

Import and Export // Save Schema. RDD’s directly to parquet people. save. As. Parquet. File("people. parquet") // Load data stored in Hive val hive. Context = new org. apache. spark. sql. hive. Hive. Context(sc) import hive. Context. _ // Queries can be expressed in Hive. QL. hql("FROM src SELECT key, value")

In Memory Columnar Storage Spark SQL can cache tables using an inmemory columnar format: - Scan only required columns - Fewer allocated objects (less GC) - Automatically selects best compression

Spark Streaming Web UI for streaming Graceful shutdown User-defined input streams Support for creating in Java Refactored API

MLlib Sparse vector support Decision trees Linear algebra SVD and PCA Evaluation support 3 contributors in the last 6 months
 val parsed.")
MLlib Note: Minor API change val data = sc. text. File("data/kmeans_data. txt") val parsed. Data = data. map( s => s. split(‘t'). map(_. to. Double). to. Array) val clusters = KMeans. train(parsed. Data, 4, 100) val data = sc. text. File("data/kmeans_data. txt") val parsed. Data = data. map( s => Vectors. dense(s. split(' '). map(_. to. Double))) val clusters = KMeans. train(parsed. Data, 4, 100)

1. 1 and Beyond Data import/export leveraging catalyst HBase, Cassandra, etc Shark-on-catalyst Performance optimizations External shuffle Pluggable storage strategies Streaming: Reliable input from Flume and Kafka

Unifying Experience Schema. RDD represents a consistent integration point for data sources spark-submit abstracts the environmental details (YARN, hosted cluster, etc). API stability across versions of Spark

Conclusion Visit spark. apache. org for videos, tutorials, and hands-on exercises. Help us test a release candidate! Spark Summit on June 30 th spark-summit. org Meetup group meetup. com/spark-users
- Slides: 33