SLAM Summer School 2004 An Introduction to SLAM





")

 Sequence")

 leads to")


























 = 1 from notes. Mistake")
















 from discussion of state augmentation in")


















")


")



- Slides: 82
SLAM Summer School 2004 An Introduction to SLAM – Using an EKF Paul Newman Oxford University Robotics Research Group
A note to students The lecture I give will not include all these slides. Some of then and some of the notes I have supplied are more detailed than required and would take too long to deliver. I have included them for completeness and background – for example the derivation of the Kalman filter from Bayes Rule. I have included in the package a working matlab implementation of EKF based SLAM. You should be able to see all the properties of SLAM at work and be able to modify at your leisure. (without having to worry about the awkwardness of a real system to start with). I cannot cover all I would like to in the time available – where applicable, to fill gaps, I forward reference other talks that will be given during the week. I hope the talk, the slides and the notes will whet you appetite regarding what I reckon is great area of research. Above all, please ask me to explain stuff that is unclear – this school is about you learning, not us lecturing. regards Paul Newman
Overview • Kalman Filter was the first tool employed in SLAM – Smith Self and Cheeseman. • Linear KFs implement Bayes rule. No hokieness • We can analyse KF properties easily and learn interesting things about Bayesian SLAM • The vanilla, monolithic, KF-SLAM formulation is a fine tool for small local areas • But we can do better for large areas – as other speakers will mention
5 Minutes on Estimation
Estimation is …. . Data Estimation Engine Prior Beliefs Estimate
Minimum Mean Squared Error Estimation Choose x so argument is minimised Expectation operator (“average”)
Evaluating…. From probability theory Very Important Thing
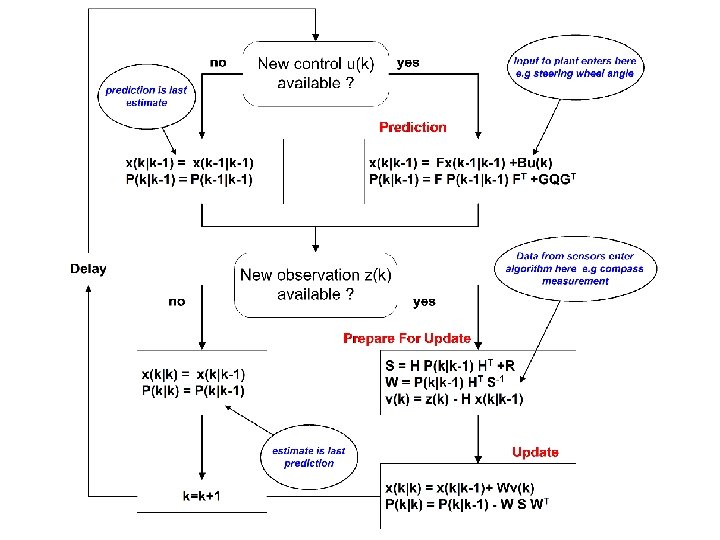
Recursive Bayesian Estimation Key idea: “one mans posterior is another’s prior” ; -) Sequence of data (measurements) We want conditional mean (mmse) of x given Zk Can we iteratively calculate this – ie every time a new measurement comes in, update our estimate?
Yes… At time k Explains data at time k as function of x at time k At time k-1
And if these distributions are Gaussian turning the handle (see supporting material) leads to the Kalman filter……
Kalman Filtering • Ubiquitous estimation tool • Simple to implement • Closely related to Bayes estimation and MMSE • Immensely Popular in robotics • Real time • Recursive (can add data sequentially) • It maintains the sufficient statistics of a Multidimensional Gaussian PDF It is not that complicated! (trust me)
Overall Goal To come up with a recursive algorithm that produces an estimate of state by processing data from a set of explainable measurements and incorporating some kind of plant model Measurement model Sensor H 1 Sensor H 2 Sensor Hn KF Estimate Plant Model Prediction/plant model True underlying state x
Covariance is…. . Multi-dimensional analogy of variance mean P is a symmetric matrix that describes a 1 -standard deviation contour ( ellipsoid in 3 D+ ) of the pdf
The i|j notation true estimated Data up to t=j This is useful for derivations but we can never use it in a calc as x is unknown truth!
The Basics We’ll use these equations as a starting point – I have supplied a full derivation in the support presentation and notes – think of a KF as an off-theshelf estimation tool
Crucial Characteristics • Asynchronisity • Prediction Covariance Inflation • Update Covariance Deflation • Observability • Correlations
Nonlinear Kalman Filtering Same trick as in Non-linear Least Squares: • Linearise around a current estimate using jacobian • Problem becomes linear again Complete derivation is in the notes but…
Recalculate Jacs at each iteration
Using The EKF in Navigation
Vehicle Models - Prediction control Truth model
Noise is in control….
Effect of control noise on uncertainty:
Using Dead-Reckoned Data
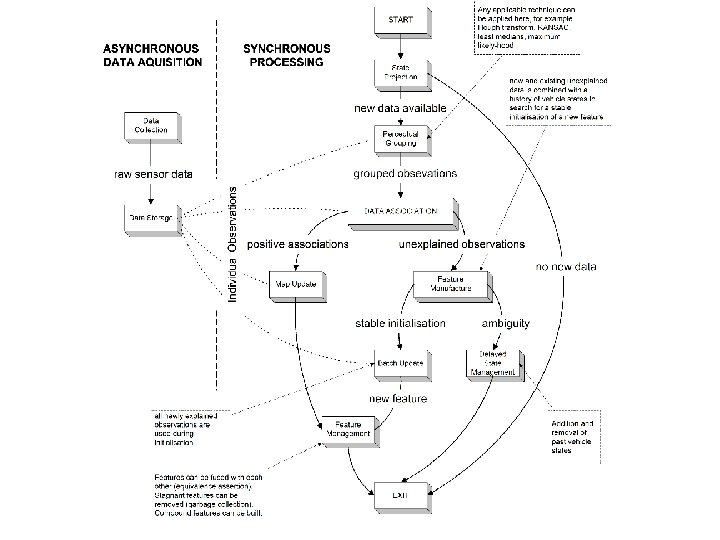
Navigation Architecture
Background T-Composition Compounding transformations
Just functions!
Deduce an Incremental Move These can be in massive error But the common error is subtracted out here
Use this “move” as a control Substitution into Prediction equation (using J 1 and J 2 as Jacobians): Diagonal covariance matrix (3 x 3) of error in uo
Feature Based Mapping and Navigation Look at the code!!
Mapping vs Localisation
Problem Space
Problem Geometry
Landmarks / Features Things that standout to a sensor: Corners, windows, walls, bright patches, texture… Map Point Feature called “i”
Observations / Measurements Relative On Vehicle sensing environment: • Radar • Cameras • Odometry (really) How smart can we be • Sonar Laser with relative only measurements? Absolute Relies on infrastructure: • GPS • Compass
And once again… It is all about probability
From Bayes Rule…. . Input is measurements conditioned on map and vehicle Data: We want to use Bayes rule to “invert this” and get maps and vehicles given measurements.
Problem 1 - Localisation Remove line p(. ) = 1 from notes. Mistake
We can use a KF for this! Plant Model Remember: u is control, J’s are a fancy way of writing jacobians (composition operator). Q is strength of noise in plant model.
Processing Data r
Implementation No features seen here
Location Covariance
Location Innovation
Problem II Mapping Map With known vehicle The state vector is the map
But how is map built? Key Point: State Vector GROWS! New, bigger map Obs of new feature Old map “State augmentation”
How is P augmented? Simple! Use the transformation of covariance rule. . G is the feature initialisation function
Leading to : Angle from Veh to feature Vehicle orientation
So what are models h and f? h is a function of the feature being observed: f is simply the identity transformation :
Turn the handle on the EKF: All hail the Oracle ! How do we know what feature we are observing?
Problem III SLAM “Build a map and use it at the same time” “This a cornerstone of autonomy”
Bayesian Framework
How Is that sum evaluated? A current area of interest/debate – Monte-carlo Methods – Thin Junction Trees – Grid based techniques – Kalman Filter • All have their individual pros and cons • All try to estimate p(xk|Zk) – state of the world given data
Naïve SLAM A union of Localisation and Mapping State vector has vehicle AND map Why naïve? Computation!
Prediction: Note: The control is noisy u = unominal+noise Note: features stay still- no noise added and jacobian is identity
Feature Initialisation: This whole function is y(. ) from discussion of state augmentation in mapping section These last two lines are g() This is our new expanded covariance
EKF SLAM DEMO Look at the code provided!!
Laser Sensing • Fast • Simple • Quantisation Errors
Extruded Museum
SLAM in action At MIT - in collaboration with J. Leonard, J. Tardos and J. Neira
Human Driven Exploration
Navigating
Autonomous Homing
It’s not a simulation…. Homing…Final Adjustment High Expectations of Students…
The Convergence and Stability of SLAM By analysing the behaviour of the LG-KF we can learn about the governing properties of the SLAM problem – which are actually completely intuitive….
We can show that: • The determinant of any submatrix of the map covariance matrix decreases monotonically as observations are successively made. • In the limit as the number of observations increases, the landmark estimates become fully correlated. • In the limit, the covariance associated with any single landmark location estimate is determined only by the initial covariance in the vehicle location estimate.
Prediction:
Observation:
Update:
Proofs Condensed (9)
Take home points: • The entire structure of the SLAM problem critically depends on maintaining complete knowledge of the cross correlation between landmark estimates. Minimizing or ignoring cross correlations is precisely contrary to the structure of the problem. • As the vehicle progresses through the environment the errors in the estimates of any pair of landmarks become more and more correlated, and indeed never become less correlated. • In the limit, the errors in the estimates of any pair of landmarks becomes fully correlated. This means that given the exact location of any one landmark, the location of any other landmark in the map can also be determined with absolute certainty. • As the vehicle moves through the environment taking observations of individual landmarks, the error in the estimates of the relative location between different landmarks reduces monotonically to the point where the map of relative locations is known with absolute precision. • As the map converges in the above manner, the error in the absolute location of every landmark (and thus the whole map) reaches a lower bound determined only by the error that existed when the first observation was made. (We didn’t prove this here. However it is an excellent test for consistency in new SLAM algorithms) This is all under the assumption that we observe all features equally often… – for other cases see Kim Sun-Joon Ph. D MIT 2004
Issues:
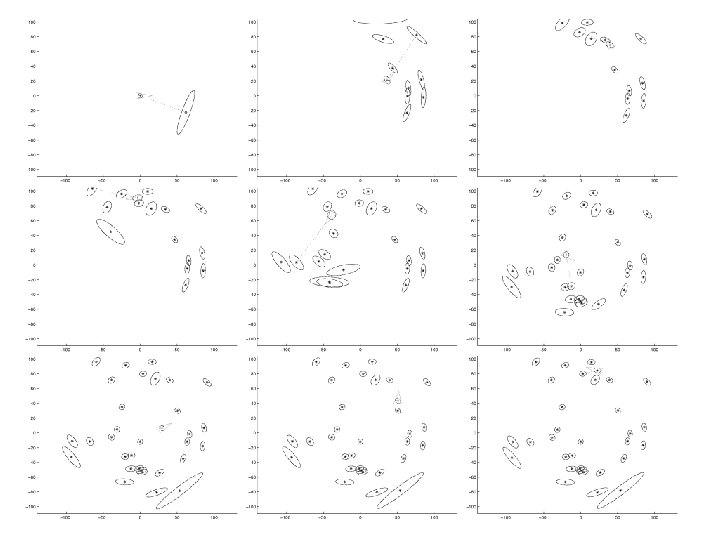
Data Association – a big problem How do we decide which feature (if any) is being observed? How do we close loops? Non-trivial. Jose Neira will talk to you about this but a naïve approach is simply to look through all features and take the one for which: υt S-1υ = ε is smallest and less than a threshold (choosen from a Chi squared distribution it - turns out) • If ε is too large we introduce a new feature into the map
The Problem with Single Frame EKF SLAM • It is uni-modal. It cannot cope with ambiguous situations • It is inconsistent - the linearisations lead to errors which underestimate the covariance of the underlying pdf • It is fragile - if the estimated is in error the linearisation is Very poor – disaster. • But the biggest problem is…. .
S CA LI N G . The Smith Self Cheeseman KF solution scales with the square of the number of mapped things Why quadratic? Because everything is correlated to everything else – 0. 5 N 2 correlations to maintain in P Autonomy + Unknown Terrain + Long Missions + Duration ? We need sustainable SLAM with O(1) complexity
Closing thoughts • An EKF is a great way to learn about SLAM and bounds on achievable performance. • EKF’s are easy to implement • They work fine for small workspaces • But they do have a downside – e. g uni-modal and brittle and scale badly • In upcoming talks you’ll be told much more about map scaling and data-association issues. Try and locate these issues in this opening talk – even better come face to face with them by using the example code! Many thanks for your time. PMN