Simultaneous Multithreading Maximizing OnChip Parallelism Presented By Daron

Simultaneous Multithreading: Maximizing On-Chip Parallelism Presented By: Daron Shrode Shey Liggett

Introduction n n Simultaneous Multithreading – a technique permitting several independent threads to issue instructions to a superscalar’s multiple functional units in a single cycle. The objective of SM is to substantially increase processor utilization in the face of both long memory latencies and limited available parallelism per thread.
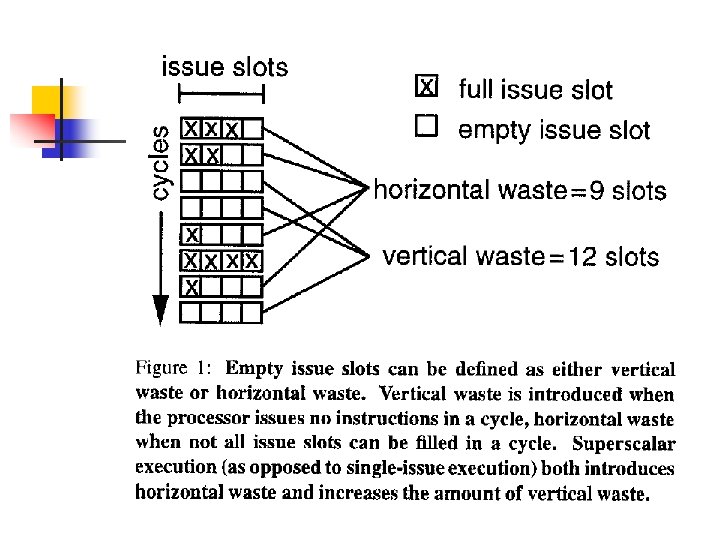

Overview n n Introduce several SM models Evaluate the performance of those models relative to superscalar and fine-grain multithreading Show to tune the cache hierarchy for SM processors Demonstrate the potential for performance and real-estate advantages of SM architectures over small-scale, on chip multiprocessors

Simulation Environment n n Developed a simulation environment that defines an implementation of SM architecture Uses emulation-based instructions-level simulation, similar to Tango and g 88 Models the execution pipelines, the memory hierarchy (both in terms of hit rates and bandwidths), the TLBs, and the branch prediction logic of a wide superscalar processor Based on the Alpha AXP 21164, augmented first for wider superscalar execution and then for multithreaded execution
 n Typical Simulated configuration contains 10 functional units of four")
Simulation Environment (cont. ) n Typical Simulated configuration contains 10 functional units of four types (four integer, two floating point, three load/store and 1 branch) and a maximum issue rate of 8 instructions per cycle.
")
Simulation Environment (cont. )
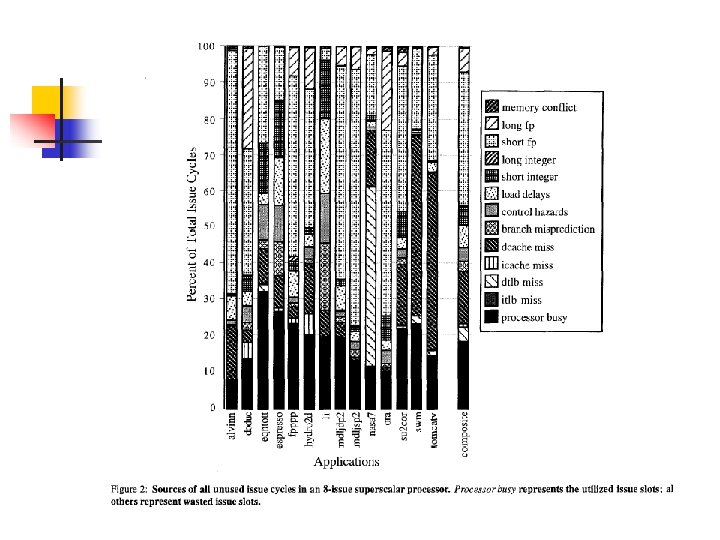

Superscalar Bottlenecks n n No dominant source of wasted issue bandwidth, therefore, no dominant solution No single latency-tolerating technique will produce a dramatic increase in the performance of these programs if it only attacks specific types of latencies

SM Machine Models
")
SM Machine Models (cont. )
")
SM Machine Models (cont. )
")
SM Machine Models (cont. )
")
SM Machine Models (cont. )
")
SM Machine Models (cont. )
 n n n In summary, the results show that")
SM Machine Models (cont. ) n n n In summary, the results show that simultaneous multithreading surpasses limits on the performance attainable through either single-thread execution or fine-grain multithreading, when run on a wide superscalar. Simplified implementations of SM with limited perthread capabilities can still attain high instruction throughput. These improvements come without any significant tuning of the architecture for multithreaded execution.

Cache Design n n Cache sharing caused performance degradation in SM processors. Different cache configurations were simulated to determine optimum configurations
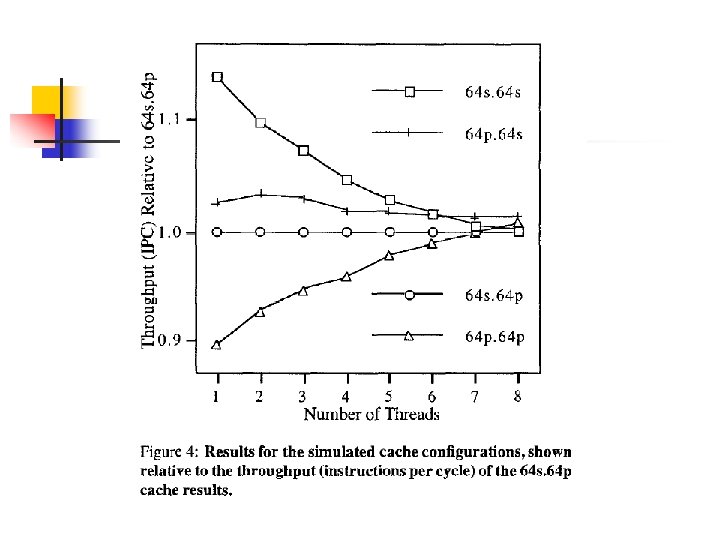

Cache Design n Two configurations appear to be good choices: n n n 64 s 64 p. 64 s Important Note: cache sizes today are larger than those at the time of the paper (1995).

Simultaneous Multithreading vs Single-Chip Multiprocessing n On organizational level, the two are similar: n n n Multiple register sets Multiple functional units High issue bandwidth on a single chip
 n Key difference is the way resources")
Simultaneous Multithreading vs Single-Chip Multiprocessing (cont. ) n Key difference is the way resources are partitioned and scheduled: n n n MP statically partitions resources SM allows partitions to change every cycle MP and SM tested in similar configurations to compare performance:
")
Simultaneous Multithreading vs Single-Chip Multiprocessing (cont. )

Conclusion

Pentium 4 n n n n n Product Features Available at 1. 50, 1. 60, 1. 70, 1. 80, 1. 90 and 2 GHz Binary compatible with applications running on previous members of the Intel microprocessor line Intel ® Net. Burst™ micro-architecture System bus frequency at 400 MHz Rapid Execution Engine: Arithmetic Logic Units (ALUs) run at twice the processor core frequency Hyper Pipelined Technology Advance Dynamic Execution —Very deep out-of-order execution —Enhanced branch prediction Level 1 Execution Trace Cache stores 12 K micro-ops and removes decoder latency from main execution loops 8 KB Level 1 data cache 256 KB Advanced Transfer Cache (on- die, full speed Level 2 (L 2) cache) with 8 -way associativity and Error Correcting Code (ECC) 144 new Streaming SIMD Extensions 2 (SSE 2) instructions Enhanced floating point and multimedia unit for enhanced video, audio, encryption, and 3 D performance Power Management capabilities —System Management mode —Multiple low-power states

AMD Athlon The AMD Athlon XP processor features a seventh-generation microarchitecture with an integrated, exclusive L 2 cache, which supports the growing processor and system bandwidth requirements of emerging software, graphics, I/O, and memory technologies. The high-speed execution core of the AMD Athlon XP processor includes multiple x 86 instruction decoders, a dual-ported 128 -Kbyte split level-one (L 1) cache, an exclusive 256 -Kbyte L 2 cache, three independent integer pipelines, three address calculation pipelines, and a superscalar, fully pipelined, out-of-order, three-way floating-point engine. The floating-point engine is capable of delivering outstanding
 The following features summarize the AMD Athlon XP processor Quanti.")
AMD Athlon (cont. ) The following features summarize the AMD Athlon XP processor Quanti. Speed architecture: n An advanced nine-issue, superpipelined, superscalar x 86 processor microarchitecture designed for increased Instructions Per Cycle (IPC) and high clock frequencies n Fully pipelined floating-point unit that executes all x 87 (floating-point), MMX, SSE and 3 DNow! instructions n Hardware data pre-fetch that increases and optimizes performance on high-end software applications utilizing high-bandwidth system capability n Advanced two-level Translation Look-aside Buffer (TLB) structures for both enhanced data and instruction address translation. The AMD Athlon XP processor with Quanti. Speed architecture incorporates three TLB optimizations: the L 1 DTLB increases from 32 to 40 entries, the L 2 ITLB and L 2 DTLB both use exclusive architecture, and the TLB entries can be speculatively loaded.
- Slides: 26