Seven Databases in Seven Weeks HBase HBase HDFS

Seven Databases in Seven Weeks HBase
 DFS Server")
HBase HDFS (Hadoop Distributed File System) DFS Server


![1日目:HBase をスタンドアロンで展開する 実行コマンド [root@HBase 01 ask]# opt]# cd /opt/ wget http: //ftp. meisei-u. ac.](http://slidetodoc.com/presentation_image_h/e619fcd4331090ed2dda01d046c7fe34/image-5.jpg "1日目:HBase をスタンドアロンで展開する 実行コマンド [root@HBase 01 ask]# opt]# cd /opt/ wget http: //ftp. meisei-u. ac.")
1日目:HBase をスタンドアロンで展開する 実行コマンド [root@HBase 01 ask]# opt]# cd /opt/ wget http: //ftp. meisei-u. ac. jp/mirror/apache/dist/hbase-0. 94. 7/hbase-0. 94. 7. tar. gz tar zxvf hbase-0. 94. 7. tar. gz vi hbase-0. 94. 7/conf/hbase-site. xml ファイル実体配置 /var /files /hbase /zookeeper <? xml version="1. 0"? > <? xml-stylesheet type="text/xsl" href="configuration. xsl"? > <configuration> <property> <name>hbase. rootdir</name> <value>file: ///var/files/hbase</value> </property> <name>hbase. zookeeper. property. data. Dir</name> <value>/var/files/zookeeper</value> </property> </configuration> 単体で可動するための最小限の設定 ファイル設置先の指定で、任意のディレクトリを書き出し先に指定する xmlで指定できる全項目 : src/main/resources/hbase-default. xml
![1日目:HBase をスタンドアロンで展開する JDKが要求される [root@HBase 01 opt]# hbase-0. 94. 7/bin/start-hbase. sh +===================================+ | Error: JAVA_HOME](http://slidetodoc.com/presentation_image_h/e619fcd4331090ed2dda01d046c7fe34/image-6.jpg "1日目:HBase をスタンドアロンで展開する JDKが要求される [root@HBase 01 opt]# hbase-0. 94. 7/bin/start-hbase. sh +===================================+ | Error: JAVA_HOME")
1日目:HBase をスタンドアロンで展開する JDKが要求される [root@HBase 01 opt]# hbase-0. 94. 7/bin/start-hbase. sh +===================================+ | Error: JAVA_HOME is not set and Java could not be found | +-----------------------------------+ | Please download the latest Sun JDK from the Sun Java web site | | > http: //java. sun. com/javase/downloads/ < | | HBase requires Java 1. 6 or later. | | NOTE: This script will find Sun Java whether you install using the | | binary or the RPM based installer. | +===================================+ JDKのバリエーション(以下から選んで導入) Oracle JDK Open JDK 1. 6 1. 7 Javaのインストールディレクトリを指定 [root@HBase 01 opt]# vi hbase-0. 94. 7/conf/hbase-env. sh - # export JAVA_HOME=/usr/java/jdk 1. 6. 0/ + export JAVA_HOME=/usr/java/latest/
![1日目:HBase をスタンドアロンで展開する 起動 [root@HBase 01 opt]# hbase-0. 94. 7/bin/start-hbase. sh starting master, logging to](http://slidetodoc.com/presentation_image_h/e619fcd4331090ed2dda01d046c7fe34/image-7.jpg "1日目:HBase をスタンドアロンで展開する 起動 [root@HBase 01 opt]# hbase-0. 94. 7/bin/start-hbase. sh starting master, logging to")
1日目:HBase をスタンドアロンで展開する 起動 [root@HBase 01 opt]# hbase-0. 94. 7/bin/start-hbase. sh starting master, logging to /opt/hbase-0. 94. 7/bin/. . /logs/hbase-root-master-HBase 01. db. algnantoka. out シェル接続 [root@HBase 01 opt]# hbase-0. 94. 7/bin/hbase shell HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 0. 94. 7, r 1471806, Wed Apr 24 18: 48: 26 PDT 2013 hbase(main): 001: 0> status 1 servers, 0 dead, 2. 0000 average load 停止 [root@HBase 01 opt]# hbase-0. 94. 7/bin/stop-hbase. sh stopping hbase. . .
: 009: 0> help \"create\" Create table; pass table")
1日目:HBase の使い方 テーブル作成 : create hbase(main): 009: 0> help "create" Create table; pass table name, a dictionary of specifications per column family, and optionally a dictionary of table configuration. Dictionaries are described below in the GENERAL NOTES section. Examples: hbase> hbase> hbase> create 't 1', {NAME => 'f 1', VERSIONS => 5} create 't 1', {NAME => 'f 1'}, {NAME => 'f 2'}, {NAME => 'f 3'} # The above in shorthand would be the following: create 't 1', 'f 2', 'f 3‘ create 't 1', {NAME => 'f 1', VERSIONS => 1, TTL => 2592000, BLOCKCACHE => true} create 't 1', 'f 1', {SPLITS => ['10', '20', '30', '40']} create 't 1', 'f 1', {SPLITS_FILE => 'splits. txt'} # Optionally pre-split the table into NUMREGIONS, using # SPLITALGO ("Hex. String. Split", "Uniform. Split" or classname) create 't 1', 'f 1', {NUMREGIONS => 15, SPLITALGO => 'Hex. String. Split'} 基本型 Create ‘Table. Name’ , {NAME => ‘Column. Family. Name’, Option => Value …} … 省略表記 Create ‘Table. Name’ , ‘Column. Family. Name’, …
: 010: 0> help \"put\" Put a cell 'value'")
1日目:HBase の使い方 レコード挿入 : put hbase(main): 010: 0> help "put" Put a cell 'value' at specified table/row/column and optionally timestamp coordinates. To put a cell value into table 't 1' at row 'r 1' under column 'c 1' marked with the time 'ts 1', do: hbase> put 't 1', 'r 1', 'c 1', 'value', ts 1 Sample. Table : create ‘Sample. Table’ , ‘color’ , ‘shape’ put ‘Sample. Table’ , ‘first’ , ‘color: red’ , ‘#F 00’ put ‘Sample. Table’ , ‘first’ , ‘color: blue’ , ‘#00 F’ put ‘Sample. Table’ , ‘first’ , ‘color: yellow’ , ‘#FF 0’
: 011: 0> help \"get\" Get row")
1日目:HBase の使い方 レコード取得 : get Sample. Table hbase(main): 011: 0> help "get" Get row or cell contents; pass table name, row, and optionally a dictionary of column(s), timestamp, timerange and versions. Examples: hbase> hbase> hbase> get get get 't 1', 't 1', 't 1', 'r 1‘ 'r 1', 'r 1', 'r 1', {TIMERANGE => [ts 1, ts 2]} {COLUMN => 'c 1'} {COLUMN => ['c 1', 'c 2', 'c 3']} {COLUMN => 'c 1', TIMESTAMP => ts 1} {COLUMN => 'c 1', TIMERANGE => [ts 1, ts 2], VERSIONS => 4} {COLUMN => 'c 1', TIMESTAMP => ts 1, VERSIONS => 4} {FILTER => "Value. Filter(=, 'binary: abc')"} 'c 1‘ 'c 1', 'c 2‘ ['c 1', 'c 2'] get ‘Sample. Table’ , ‘first’ , ‘color’ get ‘Sample. Table’ , ‘first’ , ‘color: blue’
: 001: 0> help 'scan' Scan a table; pass")
1日目:HBase の使い方 レコード検索 : scan hbase(main): 001: 0> help 'scan' Scan a table; pass table name and optionally a dictionary of scanner specifications. Scanner specifications may include one or more of: TIMERANGE, FILTER, LIMIT, STARTROW, STOPROW, TIMESTAMP, MAXLENGTH, or COLUMNS, CACHE If no columns are specified, all columns will be scanned. To scan all members of a column family, leave the qualifier empty as in 'col_family: '. The filter can be specified in two ways: 1. Using a filter. String - more information on this is available in the Filter Language document attached to the HBASE-4176 JIRA 2. Using the entire package name of the filter. Some examples: hbase> hbase> scan scan '. META. ', {COLUMNS => 'info: regioninfo'} 't 1', {COLUMNS => ['c 1', 'c 2'], LIMIT => 10, STARTROW => 'xyz'} 't 1', {COLUMNS => 'c 1', TIMERANGE => [1303668804, 1303668904]} 't 1', {FILTER => "(Prefix. Filter ('row 2') AND (Qualifier. Filter (>=, 'binary: xyz'))) AND (Timestamps. Filter ( 12 't 1', {FILTER => org. apache. hadoop. hbase. filter. Column. Pagination. Filter. new(1, 0)} For experts, there is an additional option -- CACHE_BLOCKS -- which switches block caching for the scanner on (true) or off (false). By default it is enabled. Examples: hbase> scan 't 1', {COLUMNS => ['c 1', 'c 2'], CACHE_BLOCKS => false} Also for experts, there is an advanced option -- RAW -- which instructs the scanner to return all cells (including delete markers and uncollected deleted cells). This option cannot be combined with requesting specific COLUMNS. Disabled by default. Example: hbase> scan 't 1', {RAW => true, VERSIONS => 10}

1日目:HBase の使い方 Time. Stamp put ‘table’ , ‘first’ , ‘color: red’ , ‘#FFF‘ put ‘table’ , ‘first’ , ‘color: red’ , ‘#000' put ‘table’ , ‘first’ , ‘color: red’ , ‘#0 F 0‘ put ‘table’ , ‘first’ , ‘color: red’ , ‘#00 F' put ‘table’ , ‘first’ , ‘color: red’ , ‘#F 00' ‘first’ , ‘color: red’ timestamp 5 timestamp 4 #F 00 get ‘table’ , ‘first’ , ‘color: red’ #00 F timestamp 3 timestamp 2 #0 F 0 #000 get ‘table’ , ‘first’ , {COLUMN=>‘color: red’ , TIMESTAMP=>4} timestamp 1 #FFF get ‘table’ , ‘first’ , {COLUMN=>‘color: red’ , VERSIONS=>4}
: 009: 0> disable 'table 1' 0 row(s) in 2.")
1日目:HBase の使い方 スキーマ変更: alter hbase(main): 009: 0> disable 'table 1' 0 row(s) in 2. 5190 seconds alter の対象 Table は オフラインでなければ ならない hbase(main): 010: 0> get 'table 1', 'first', 'color: red' COLUMN CELL ERROR: org. apache. hadoop. hbase. Do. Not. Retry. IOException: table 1 is disabled. hbase(main): 012: 0> alter 'table 1' , { NAME => 'color', VERSIONS => 10} Updating all regions with the new schema. . . 1/1 regions updated. Done. 0 row(s) in 1. 3630 seconds 保持するバージョン数の変更 hbase(main): 014: 0> enable 'table 1' 0 row(s) in 2. 3000 seconds alter によるスキーマ変更の手順は以下 1. 新たなスキーマの空テーブルを作る 2. 元テーブルからデータを複製する 3. 元テーブルを破棄する 高コストなので、原則スキーマ変更( Column. Family の変更)は行わない

1日目:HBase の使い方 JRubyスクリプティング hoge. rb include Java import org. apache. hadoop. hbase. client. HTable import org. apache. hadoop. hbase. client. Put import org. apache. hadoop. hbase. HBase. Configuration hbase関係の Javaクラス def jbytes(*args) args. map { |arg| arg. to_s. to_java_bytes } end table = HTable. new( HBase. Configuration. new, "table 1" ) p = Put. new( *jbytes( "third" ) ) p. add( *jbytes( "color", "black", "#000" ) ) p. add( *jbytes( "shape", "triangle", "3" ) ) p. add( *jbytes( "shape", "square", "4" ) ) table. put( p ) レコード挿入タイミング 実行 [root@HBase 01 opt]# hbase-0. 94. 7/bin/hbase shell hoge. rb hbase(main): 002: 0> get 'table 1', 'third' , {COLUMN => ['color', 'shape']} COLUMN CELL color: black timestamp=1369049856405, value=#000 shape: square timestamp=1369049856405, value=4 shape: triangle timestamp=1369049856405, value=3 9 row(s) in 0. 0870 seconds レコードのtimestampが揃う hbase shell は JRuby インタプリタを拡張したものなので、JRubyが実行できる
 バッチ処理 Map. Reduce Hadoop プロジェクト (Googleクローン) リアルタイム応答 Big. Table")
Hbaseとは何か Google の 内部システム (発表した論文より) バッチ処理 Map. Reduce Hadoop プロジェクト (Googleクローン) リアルタイム応答 Big. Table Google File Sytem (GFS) Map. Reduce HBase Hadoop Distributed File Sytem (HDFS)
 スキーマで定義する Row. Key Column. Family 1 Column. Family 2 1 Column 2")
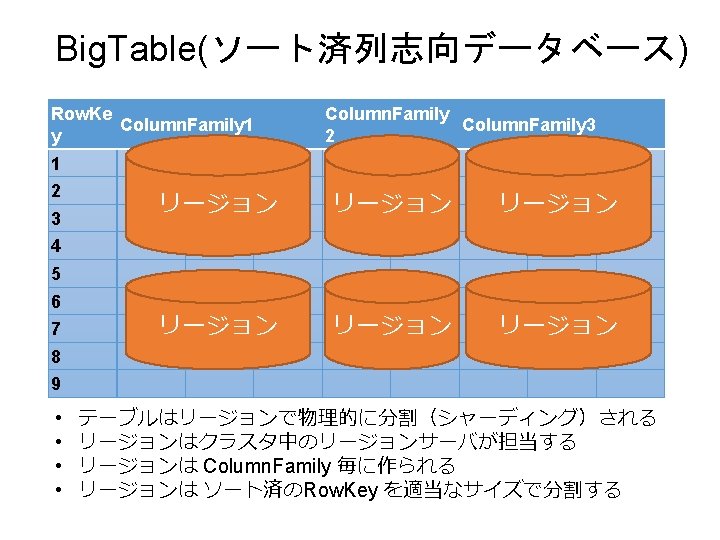
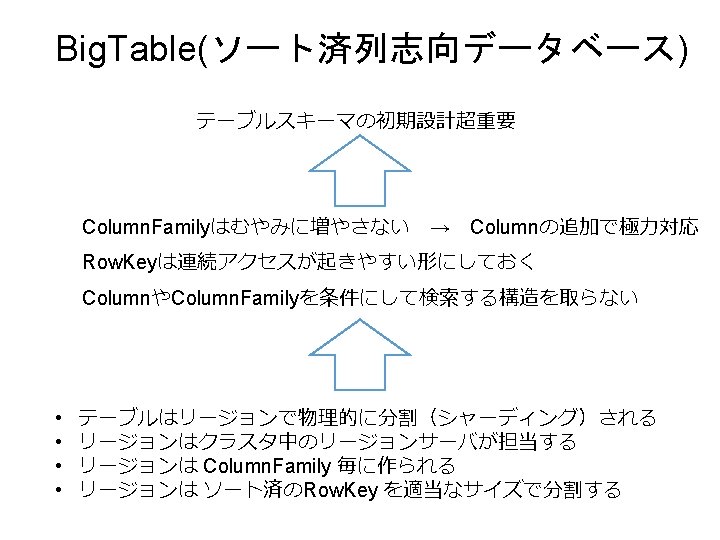
Big. Table(ソート済列志向データベース) スキーマで定義する Row. Key Column. Family 1 Column. Family 2 1 Column 2 Column 1 Column 2 2 Column 3 Column. Family 3 Column 2 Column 3 スキーマレス(自由に追加できる) 必須 ソート済 あるColumn timestamp 5 timestamp 4 #F 00 timestamp 3 timestamp 2 #0 F 0 #000 timestamp 1 #FFF #00 F タイムスタンプでバージョニングされる


 HDFS Read Write Master Server オンメモリ ストア Region Server")
HBase の特徴 を構成する要素 自動フェールオーバー・データの一貫性 (CAP: Consistency) HDFS Read Write Master Server オンメモリ ストア Region Server ローカルストア WAL replicate ローカルストア WAL Zoo. Keeper Region Server (フェールオーバー先) Region


Scan にかかる秒数 250 200 150 100 50 0 圧縮あり 圧縮なし text含む 117. 751 193. 735 圧縮あり text含まず 10. 424 11. 961 圧縮なし
- Slides: 23