Semantic segmentation Image classification Disadvantages 1 The most


 The most serious problem is the inability to explain the reasoning process")


 Why Rightmost Hyperplane ? Hyperplane has a")
 1. Training data set . . T=(")







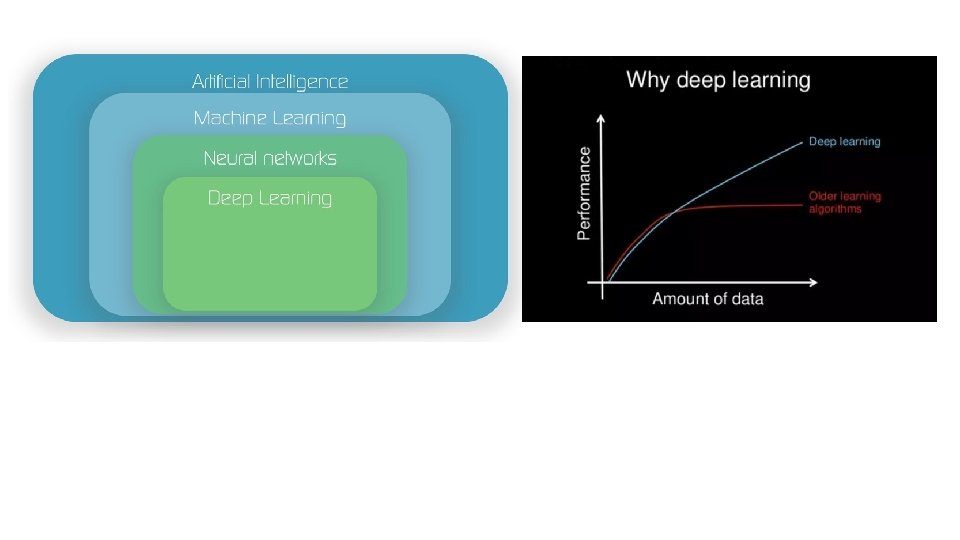
- Slides: 16
Semantic segmentation , Image classification
Disadvantages: (1) The most serious problem is the inability to explain the reasoning process and the basis of reasoning. (2) When the data is insufficient, the neural network cannot work. (3) Turn all the characteristics of the problem into numbers, and turn all the reasoning into numerical calculations. The result is bound to be lost information.
Decision Trees Applicable to small data sets, typical decision tree analysis uses hierarchical variables or decision nodes during a step-by-step process. For example, a given user can be classified as reliable or unreliable. Advantage: The calculation amount is simple, the interpretability is strong, and it is more suitable for processing samples with missing attribute values, and can deal with irrelevant features; Good at assessing a range of different characteristics, qualities, and characteristics of people, places, and things Disadvantage: Easy to overfit (following random forests, reducing overfitting)
Random Forest: Discriminant Model, Multi-Classification and Regression, Regularized Maximum Likelihood Estimation, Bagging, Random Future Random forest generation method: 1. Generate n samples from the sample set by resampling 2. Assuming that the number of sample features is a, select k features in a for n samples, and obtain the best segmentation point by establishing a decision tree. 3. Repeat m times to generate m decision trees 4. Most voting mechanisms to make predictions advantage 1. On many current datasets, it has great advantages over other algorithms and performs well. 2, it can handle very high dimensional data, and no need to make feature selection 3, training speed is fast, easy to make parallelization method 4, in the training process, can detect the interaction between the features 5, the implementation is relatively simple 6. For an unbalanced data set, it balances the error. 7. If a large part of the features are lost, the accuracy can still be
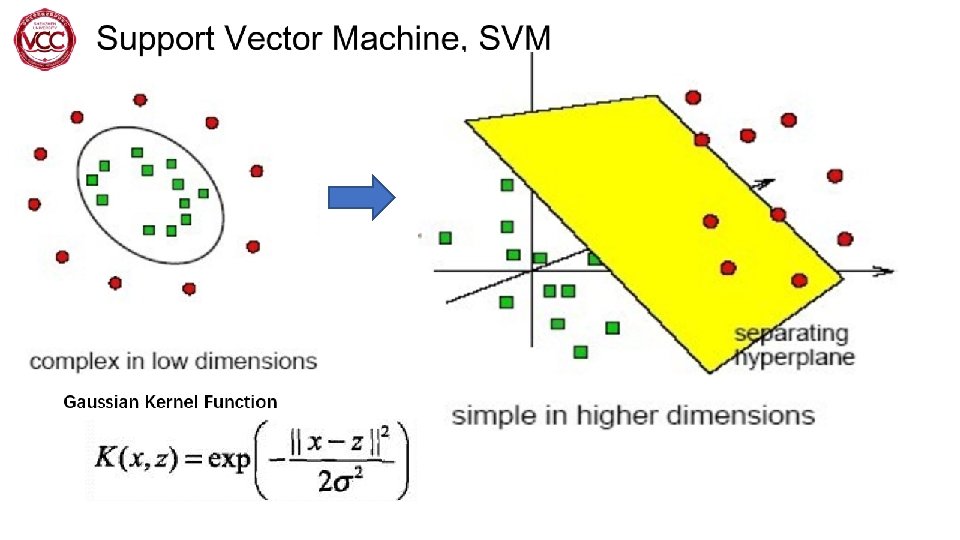
Support Vector Machine 1. Large-Margin Separating Hyperplane(超平面) Why Rightmost Hyperplane ? Hyperplane has a largest-margin to cloest Xn Reduce noise
1. Large-Margin Separating Hyperplane(超平面) 1. Training data set . . T=(
Function interval Geometric interval Maximum interval Consider
Lagrange duality
Features: Map low-dimensional space to high-dimensional space to achieve linear separability Advantage : Realize nonlinear classification, can be used for classification and regression, low generalization error, easy to explain Disadvantage: Unable to process large amounts of data
Clustering Algorithms k-Means, EM, Hierarchical Clstering Advantage : Classify unlabeled data to make data meaningful