Security and Privacy for Distributed Optimization and Learning

Security and Privacy for Distributed Optimization and Learning Nitin Vaidya Georgetown University

Secret to happiness is to lower your expectations to the point where they're already met 2

So the secret to good self-esteem is to lower your expectations to the point where they're already met? - Hobbes 3

Goals of the Talk g Background g Problem definitions g Very brief solution sketch No theorems / proofs

argmin g g g Distributed Optimization g g g g Security g g g g Privacy g

argmin
 = cost of robot i to go to location x g")
Application g hi(x) = cost of robot i to go to location x g Minimize total cost of rendezvous 6 2 1 5 3 4

1 2 3 4 5 6 8

argmin What does this have to do with learning?

Deep Neural Networks neuron layer 1 x 1 W 111 a 1 1 a 2 x 2 2 a 3 x 3 W 132 3 a 4

input parameters layer 1 x 1 W 111 1 x 2 2 x 3 3 W 132 output 0. 8 dog 0. 1 cat 0. 09 ship 0. 01 car

How to train your network g Given a machine structure parameters are the only free variables Choose parameters that maximize accuracy Optimize cost function h(w) to find w
 Training Optimize cost function h(w) Machine parameters w 13")
h(w) Training Optimize cost function h(w) Machine parameters w 13

Distributed Training g Data is distributed across different agents

Distributed Training g Data is distributed across different agents Agent 1 Agent 2 Agent 3 Agent 4

Distributed Training g Data is distributed across different agents Collaborate to learn
 Collaborate to learn")
Distributed Training g Data is distributed across different agents h 1(w) Collaborate to learn h 2(w) Training Optimize cost function Σ hi(w) i h 3(w) h 4(w)

Distributed Classification g Many agents collect inputs Agents = sensors Inputs = features g Collaboratively classify object 18

argmin Many applications 19

argmin g g g Distributed Optimization g g g g Security g g g g Privacy g

argmin g g g Distributed Optimization
![Convex Optimization x = [a, b] h(x) a b Wikipedia](http://slidetodoc.com/presentation_image_h/91fe0e37c5d7cae999245b8beeecbc64/image-22.jpg "Convex Optimization x = [a, b] h(x) a b Wikipedia")
Convex Optimization x = [a, b] h(x) a b Wikipedia

Gradient Method x 0 x 1 g x 3 x 2

Gradient Method x 0 x 1 g x 3 x 2

1984 25

Distributed Optimization g Each agent maintains local estimate of optimum x g Iterative computation g Local estimates shared with neighbors in each iteration g Local estimates converge to optimum 26

x 1 x 2 x 3 x 3 Example based on [Nedic and Ozdaglar, 2009]

x 1 x 2 x 3 x 3

x 1 x 2 x 3 x 3 Local cost only

x 1 x 2 x 3 x 3
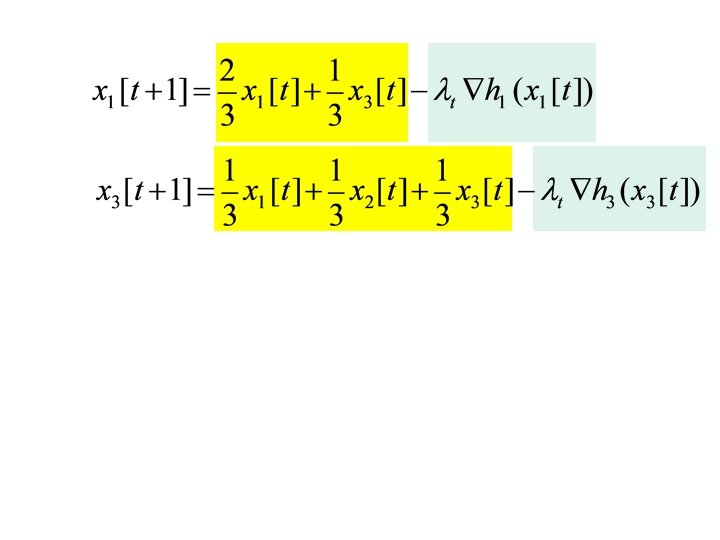
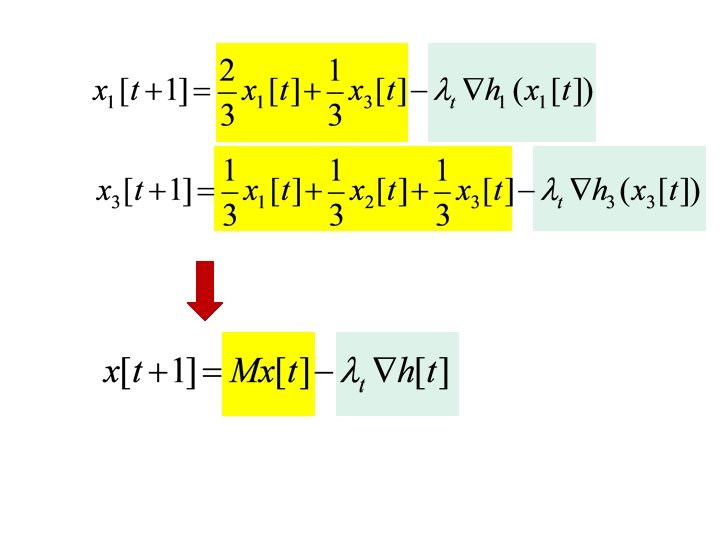

M doubly-stochastic

M doubly-stochastic t

Distributed Optimization In the limit as t ∞ g Consensus: All agents converge to same estimate g Optimality 35

Why does this work?

argmin g g g Distributed Optimization g g g g Security g g g g Privacy g

argmin g g Security g

Security / Fault-Tolerance g What if some of the agents are faulty or adversarial ? 39

1980 40

Byzantine Fault Model g No constraint on misbehavior of faulty agent 41

Byzantine Fault Model g No constraint on misbehavior of faulty agent 42

Distributed Optimization x 1 x 2 z y x 3 Faulty agents can send arbitrary values ~
 = cost of robot i to go to location x")
Distributed Optimization g fi(x) = cost of robot i to go to location x g Faulty agent may choose arbitrary cost function 6 2 1 5 3 4
 x 45")
h 2(x) x 45

Fault-Tolerant Optimization g The original problem not meaningful since it includes cost of faulty agents

Better Goal g N = Non-faulty agents g Optimize only over non-faulty agents 47

x Non-faulty set N

Better Goal g N = Non-faulty agents g Optimize only over non-faulty agents … but this is provably impossible 49

Fault-Tolerant Optimization g Instead of uniform weights allow unequal weights 50

Fault-Tolerant Optimization g Instead of uniform weights allow unequal weights but as close to uniform as possible 51

Fault-Tolerant Optimization g Find xopt such that xopt = arg min for some weight vector � 52

Fault-Tolerant Optimization g Find xopt such that xopt = arg min for some weight vector � How close to uniform weight vector can we get?
 Goal: Identify tight")
Results Answer depends on g g Network topology Redundancy (in functions) Goal: Identify tight necessary/sufficient conditions

Intuition behind Solutions g Must filter bad behavior

Intuition behind Solutions g Must filter bad behavior g Outliers defined using gradients … discard extreme gradients

Fault-Tolerant Classification When can we classify correctly despite adversaries?

Example: Fault-Tolerant Classification g Can good agents in this system classify correctly? 1 2 3 58
 Goal: Identify tight")
Results Answer depends on g g Network topology Redundancy (in observations) Goal: Identify tight necessary/sufficient conditions

argmin g g g Distributed Optimization g g g g Security g g g g Privacy g

argmin g g Privacy g

Privacy g Cooperate without divulging information Agent 1 Agent 2 Agent 3 Agent 62 4 6 2 1 5 3 4

Enhancing Privacy g Basic principle … add balanced noise that cancels over the network x 1 x 2 x 3+n x 3 - n 63

Distributed Optimization g With balanced noise, the estimates converge to optimal of the original optimization problem argmin 64

Summary argmin g g g Distributed Optimization g g g g Security g g g g Privacy g

Open Problems: Fault-Tolerant Learning/Optimization g Vector arguments for fault-tolerant algorithms g Noisy observations … random noise versus adversarial g Topology adaptation g Dynamic topologies g Continuous learning 66

67

68

69
![Distributed Optimization Topic of much research … including recent work g [Tsitsiklis, 1984] …](http://slidetodoc.com/presentation_image_h/91fe0e37c5d7cae999245b8beeecbc64/image-70.jpg "Distributed Optimization Topic of much research … including recent work g [Tsitsiklis, 1984] …")
Distributed Optimization Topic of much research … including recent work g [Tsitsiklis, 1984] … g g g [Nedic and Ozdaglar, 2009] [Duchi et al. , 2012] [Tsianos et al. , 2012] . . . 70

Fault-Tolerant Optimization g Optimize weighted cost over only non-faulty agents �� i i good Lower bounds on number and value of of non-zero weights �� i

Lower Bounds g good - f nodes guaranteed non-zero weight g Non-zero weights > 1 / 2 good 72

73

Consensus: “Flocking problem” g Initial state a, b, c = input b c a 74

Local Averaging b b = 3 b/4+ c/4 c c = a/4+b/4+c/2 a = 3 a/4+ c/4 a 75

= M : = M b b = 3 b/4+ c/4 c c = a/4+b/4+c/2 a = 3 a/4+ c/4 a 76

after 1 iteration after 2 iterations = M 2 : = M M b b = 3 b/4+ c/4 c c = a/4+b/4+c/2 a = 3 a/4+ c/4 a 77

after k iterations : = Mk b b = 3 b/4+ c/4 c c = a/4+b/4+c/2 a = 3 a/4+ c/4 a 78

: = Mk b b = 3 b/4+ c/4 c c = a/4+b/4+c/2 a = 3 a/4+ c/4 a 79

80

x 2 x 3 W 131 W 132 3 s(X 2 W 131+X 3 W 132+b 13)
 z W 131 W 132 3")
Rectifier Linear Unit x 2 x 3 s(z) z W 131 W 132 3 s(X 2 W 131+X 3 W 132+b 13) z
 1980: Byzantine exact consensus, 3")
Pre-history Hajnal 1958 (weak ergodicity of non-homogeneous Markov chains) 1980: Byzantine exact consensus, 3 f+1 nodes 1983: Impossibility of exact consensus with asynchrony & failure Tsitsiklis 1984: Decentralized control [Jadbabaei 2003] (Approximate) 1986: Approximate consensus with asynchrony & failure

Distributed Optimization g g g 84
 such that output = arg min With")
Byzantine Fault-Tolerant Optimization There exist weights (αi’s) such that output = arg min With up to f Byzantine faulty agents: at most |N| - f weights can be guaranteed to be > 0 85
 such that output = arg min With")
Byzantine Fault-Tolerant Optimization There exist weights (αi’s) such that output = arg min With up to f Byzantine faulty agents: at most |N| - f weights can be guaranteed to be > 0 Can we match this bound? How large are non-zero weights? 86
 is convex combination of")
Note g Weights are non-negative and add to 1 h(x) is convex combination of non-faulty functions 87

Centralized Algorithm 88

Centralized Algorithm g How to filter cost functions of faulty agents? (without knowing their identity) g Of the n agents, any f may be faulty

Centralized Algorithm g How to filter cost functions of faulty agents? (without knowing their identity) g Of the n agents, any f may be faulty X

Observations g Optima of in convex hull of optima of non-faulty cost functions Potential solution: * Compute optima of each cost function * Drop largest & smallest f such optima * Output within convex hull of the rest - example : average 91

Potential Solution f=2 X Discard Optima of local cost functions 92

Potential Solution f=2 Average of remaining optima X Discard Optima of local cost functions 93

Potential Solution * Compute optima of each cost function * Drop largest & smallest f such optima * Output within convex hull of the rest - example : average Average of optima can be much worse than optima of average cost 94
 whose gradient is obtained as follows 95")
Centralized Algorithm Define a virtual function G(x) whose gradient is obtained as follows 95
 whose gradient is obtained as follows At")
Centralized Algorithm Define a virtual function G(x) whose gradient is obtained as follows At a given x g g g Sort the gradients of the n local cost functions Discard smallest f and largest f gradients Mean of remaining gradients = Gradient of G at x Virtual function G(x) is convex 96
 is Convex Gradient of continuously differentiable convex functions is non-decreasing and continuous Gradient")
G(x) is Convex Gradient of continuously differentiable convex functions is non-decreasing and continuous Gradient computed for G(x) is non-decreasing and continuous G(x) is convex Use convex optimization techniques on G(x) (e. g. , gradient descent) 97
 = 0 at optimum of G(x) … presently assume")
Centralized Algorithm g Gradient G’(x) = 0 at optimum of G(x) … presently assume smooth functions 98

Centralized Algorithm g The faulty gradients that are not discarded can be expressed as convex combination of gradients of non -faulty functions grad Discard Gradients of local cost functions 99
 = 0 at optimum of G(x) g 0 =")
Centralized Algorithm g Gradient G’(x) = 0 at optimum of G(x) g 0 = G’(x) can be expressed as such that at least |N|-f weights are > max(1/n, ½ (|N|-f)) 100
 = 0 at optimum of G(x). g Optimum of")
Centralized Algorithm g Gradient G’(x) = 0 at optimum of G(x). g Optimum of G(x) also optimizes such that at least |N|-f weights are > max(1/n, ½ (|N|-f)) 101

Distributed Algorithms 102

Distributed Algorithms g Several different version that impose somewhat different requirements on the cost functions (Lipschitz continuity versus Lipschitz gradient) and achieve different convergence properties … 103

Valid Global Cost Functions g Consider the set Y of optima of all functions of the form such that at least |N|-f weights are > ½ (|N|-f) g Set Y is convex … when x is scalar 104
![Asymptotic Behavior g Consensus … |xi[t] – xj[t]| 0 g Validity … distance(xi[t], Y)](http://slidetodoc.com/presentation_image_h/91fe0e37c5d7cae999245b8beeecbc64/image-105.jpg "Asymptotic Behavior g Consensus … |xi[t] – xj[t]| 0 g Validity … distance(xi[t], Y)")
Asymptotic Behavior g Consensus … |xi[t] – xj[t]| 0 g Validity … distance(xi[t], Y) 0 g Limit may or may not exist … algorithm-dependent 105
![Distributed Algorithm Each agent i maintains local estimate xi[t] 106](http://slidetodoc.com/presentation_image_h/91fe0e37c5d7cae999245b8beeecbc64/image-106.jpg "Distributed Algorithm Each agent i maintains local estimate xi[t] 106")
Distributed Algorithm Each agent i maintains local estimate xi[t] 106
![Distributed Algorithm Each agent i maintains local estimate xi[t] In each iteration: g Send](http://slidetodoc.com/presentation_image_h/91fe0e37c5d7cae999245b8beeecbc64/image-107.jpg "Distributed Algorithm Each agent i maintains local estimate xi[t] In each iteration: g Send")
Distributed Algorithm Each agent i maintains local estimate xi[t] In each iteration: g Send xi[t] and gradient h’i(xi[t]) to all agents 107
![Distributed Algorithm Each agent i maintains local estimate xi[t] In each iteration: g Send](http://slidetodoc.com/presentation_image_h/91fe0e37c5d7cae999245b8beeecbc64/image-108.jpg "Distributed Algorithm Each agent i maintains local estimate xi[t] In each iteration: g Send")
Distributed Algorithm Each agent i maintains local estimate xi[t] In each iteration: g Send xi[t] and gradient h’i(xi[t]) to all agents g xi[t+1] filter {x[t]} − λ[t] * filter {h’[t]} filter : drop smallest f, largest f values, mean of (max, min) of the rest 108

Distributed Algorithm g Faulty agents can send different messages to different agents g Filtering limits the impact of misbehavior 109

Distributed Algorithm g Faulty agents can send different messages to different agents g Filtering limits the impact of misbehavior vector of local gradients at local estimates 110

Distributed Algorithm g Faulty agents can send different messages to different agents g Filtering limits the impact of misbehavior where x[t] vector contains state of only non-faulty agents 111

Distributed Algorithm g Faulty agents can send different messages to different agents g Filtering limits the impact of misbehavior where x[t] vector contains state of only non-faulty agents vector of valid combinations of local gradients

113

114

Distributed Algorithm g Faulty agents can prevent convergence … but not consensus g Filtering “effective gradient” at each agent is “comparable” to the gradient of a valid function g Estimates are eventually trapped in Y Y 115

Distributed Algorithm g If faulty agents are prevented from sending different messages to different agents (using Byzantine broadcast) g Consensus & Convergence …. at higher cost 116
- Slides: 116