Search Engines S L Sangam Dept of Library

Search Engines S. L. Sangam Dept of Library and Information Science Karnataka University Dharwad

What is Search Engine? l Search engine is a software program that searches for sites based on the words that you designate as search terms. Search engines look through their own databases of information in order to find what it is that you are looking for. “Search engine” is the popular term for an Information Retrieval (IR) system l Search Engine is a computer programme that searches for documents containing keywords or phrases of Internet users

HISTORY Archie – First search tool for the Internet l Gopher – indexed plain text documents l Jughead – searched the files stored in Gopher index systems l Wandex – first Web search engine l

Viz. l There are 300, 000 search engines!

Anatomy of a SE 1. Determine Key Words 2. Submit to Directories 3. Get Links 4. Optimise Web Pages 5. Submit to Spider Engines
 l Use")
Characteristics Search Engines… Key features… l Proximity searches (NEAR, ADJ, BEFORE, AFTER) l Use of parentheses to group search terms l Truncation searches (‘industr*’) l Field-specific searching (Title, URL, Text) l Natural language queries (‘Why is the sky blue? ’) l Relevance ranking of search results l Number of search terms l Number of times each search term occurs l Proximity of search terms l Location of search terms (title, text)
")
Conti. . l Key features… l l l l Sub-searching (searching within retrieved records) Case sensitivity Limit by language Limit by age of documents Limit by audio, video and image type Translation of search results (title and description) Limit by domain, host

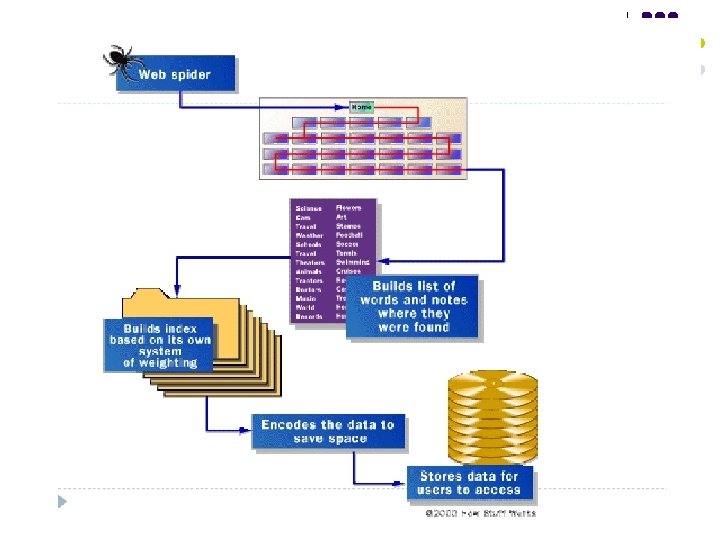
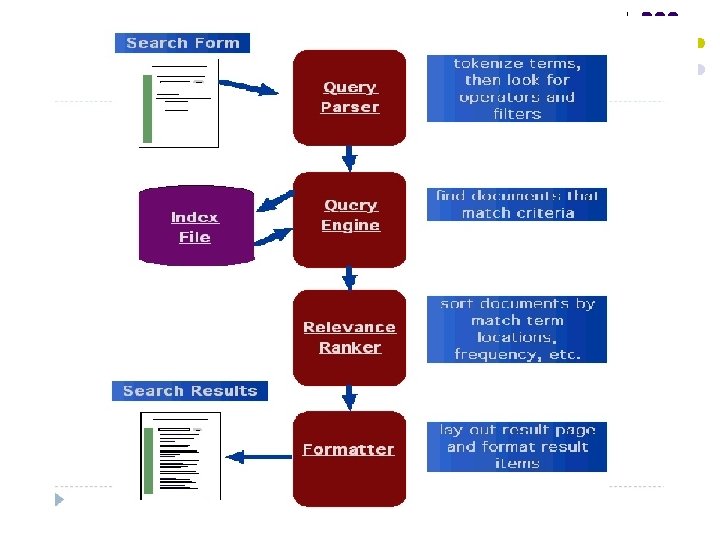
Parts of Search Engine l A search engine has three major parts: 1. A spider, a crawler, or a robot 2. Index or database 3. Search utility

How do Search Engine Works Spiders l. Robots

Types of Search Engines l l l General Search Engines Meta Search Engines Intelligent Search Engines Subject Search Engines Specialized Search Engines

1. General Search Engines l General search engines are those, which search for information from their own databases/index. l These are based on the generic retrieval tools customized for searching performance, indexing, speed etc. l These use either the Boolean operators or statistical methods or mathematical to search information. ex: www. google. com

Search Engines Google Page. Rank 1. Google runs on a unique combination of advanced hardware and software. 2. Google interprets a link from page A to page B as a vote, by page A, for page B. 3. Votes cast by pages that are themselves "important" weigh more heavily and help to make other pages "important. "

Search Engines 4. Google combines Page. Rank with sophisticated text-matching techniques to find pages that are both important and relevant to your search. 5. VNUnet’s James Middleton article in 2001: “One such posting on a security newsgroup claimed that searching using the string ‘Index of / +banques +filetype: xls’ eventually turned up sensitive Excel spreadsheets from French banks. The same technique could also be used to find password files. ”



Search Engines Yahoo! Slurp 1. Yahoo uses a crawler, or robot, to scour the Web for documents called Yahoo Slurp, the robot collects documents from the Web to build a searchable index for search services using the Yahoo search engine 2. The crawler is also keeping copies of those pages--what's known as "caching" pages. "
 l MSN (originally The Microsoft Network) is a")
Search Engines MSN (The Microsoft Network) l MSN (originally The Microsoft Network) is a collection of Internet sites and services provided by Microsoft. The Microsoft Network debuted as an online service and Internet service provider on August 24, 1995, to coincide with the release of the Windows 95 operating system l The range of services offered by MSN has changed since its initial release in 1995. MSN was once a simple online service for Windows 95, an early experiment at interactive multimedia content on the Internet, and one of the most popular dial-up Internet service providers. l Microsoft used the MSN brand name to promote numerous popular web-based services in the late 1990 s, most notably Hotmail and Messenger, before reorganizing many of them in 2005 under another brand name, Windows Live. MSN's Internet portal, MSN. com, is currently the 16 th most visited domain name on the Internet
 l AOL Inc. (NYSE: AOL, previously known as America Online, written")
AOL (America Online) l AOL Inc. (NYSE: AOL, previously known as America Online, written as "AOL" and stylized as "Aol. " but commonly pronounced as an initialism) is an American global Internet services and media company. AOL is headquartered at 770 Broadway in New York. l Founded in 1983 as Control Video Corporation, it has franchised its services to companies in several nations around the world or set up international versions of its services l AOL is headquartered in New York City, but has many offices throughout cities in North America, such as Atlanta, Baltimore, Beverly Hills, Boston, Chicago, Detroit, Dulles, Mountain View, San Francisco, and Toronto. London and Tokyo are its foreign offices. As of December 2011, it serves 3. 3 million paid subscribers l AOL is best known for its online software suite, also called AOL, that allowed customers to access the world's largest "walled garden" online community and eventually reach out to the Internet as a whole.

Search Engines Ask Jeeves Teoma 1. The Teoma Crawler is Ask Jeeves' Web-indexing robot 2. The crawler collects documents from the Web to build the ever -expanding index for their advanced search functionality 3. Teoma analyzes the Web as it actually exists - in subjectspecific communities. It creates a comprehensive and highquality index.

Ask Jeeves Teoma

2. Meta Search Engines l Meta Search Engines search more than one search engine at the same time. They can search up to 20 search engines all at once. l Meta search engines behave as search Engines for Search Engines. In order to avoid ‘Searcher' going from one search engine to another Metasearch engines are made. l When the results are obtained from different search tools, the display mechanism merges them and removes the duplicate ones. l Metasearch engines do not maintain their own database and therefore cannot accept website submission. ex: www. metacrawler. com, www. dogpile. com

Meta Search Tools. . . Search using multiple search engines Search using a meta search tool

Advantages and Disadvantages Meta Search Engine. . . l Advantages: l l Query can be run across multiple search engines User needs to learn only the search interface of the meta search tool Better results: retrieves top-ranking pages from individual search engines Disadvantages: l l Unique features of individual search engines is lost Not exhaustive: use only top results returned by search engines

3. Intelligent search Engines l Intelligent search Engines are those which are maintained by intelligent agents, and ranks the results according to the preferences of the people. l They allow the natural language searching instead of entering ‘keywords’. l They also provide personalized services at definite intervals. Ex: www. ask. com

4. Subject Specific Search Engines l As the name suggest they are related to only a particular subject. l They also act like other search engines but the fact that they include only sites on a particular subject or material. ex: www. sciencesearch. com www. sosig. ac. uk/harvester. html

5. Specialized search Engines l These cover usually the targeted topics or aspects of a topic. l These search engines provide access to such information which other types of search engines cannot provide. l They are broadly cateriogised as deep web, domain names, multimedia/images and new page tracking search engines. ex: www. invisibleweb. com

Search Tools. . . l When to use search tools? l l l Need to be used cautiously Good for simple searches, particularly if search terms are distinctive or unique Good for testing with a few keywords – and find which individual search engine returns good results Good for ‘quick searching’ if you are in a hurry and want to find a few relevant sites quickly For complex searches, involving many search terms, Boolean logic, etc. , it is better to use individual search engines
 l Ixquick")
Search Tools. . . l Demonstration: l Meta. Crawler (www. metacrawler. com) l Ixquick (www. ixquick. com) l Dogpile (www. dogpile. com) l Pro. Fusion (www. profusion. com)

Web Search Strategies l Search steps: 1. Analyze the search topic and identify the search terms (both inclusion and exclusion), their synonyms (if any), phrases and Boolean relations (if any) 2. Select the search tool(s) to be used (meta search engine, directory, general search engine, specialty search engine) 3. Translate the search terms into search statements of the selected search engine 4. Perform search 5. Refine the search based on results 6. Visit the actual site(s) and save the information (using File. Save option of the browser)

Web Search Strategies l Tips for effective searching: l Broad or general concept searches: start with directory-based services (want a few highly relevant sites for a broad topic) l Highly specific or topics with unique terms/ many concepts: use the search tools l Go through the ‘help’ pages of search tools carefully l Gather sufficient information about the search topic before searching l l Spelling variations, synonyms, broader and narrower terms Use specific keywords, rare/unusual words are better than common ones

Web Search Strategies. . . l Tips for effective web searching… l Repeat the search by varying search terms and their combinations; try this on different search tools l Enter most important terms first - some search tools are sensitive to word order l Use the NOT operator to exclude unwanted pages (e. g. : biodata, resumes, courses) l Go through at least 5 pages of search results before giving up the scan l Select 2 or 3 search tools and master the search techniques

Advantages and Disadvantages: Search Engines. . . l l Advantages of search engines: l Best suited for complex keyword/ concept searches l Control over search: search terms can be combined as required l Searches can be limited to period of time, fields, source type, etc. l Currency of information, made possible by regular addition by web spiders l Exhaustive information can be retrieved (with lots of patience!) Disadvantages: l Time consuming l False positives l Search engines vary in terms of search techniques/ syntax l Dead links, redundant links (same document gets displayed) l Spamming (‘salting’ of pages) l Higher ranking of paying sites
 as little vocabulary control is")
Limitations of search engines: l Poor retrieval effectiveness (relevance) as little vocabulary control is exercised by web site developers and the index engines l Different search engines return different search results due to the variation in indexing and search process (40% non-overlap) l None of the search engines come close to indexing the entire web, much less the entire Internet. Content not indexed: l PDF documents l Content that requires log in l Databases searched using CGI programs l Web content on intranets behind fire walls

Conclusion l Different engines have different strong points; use the engine and feature that best fits the job you need to do. One thing is obvious; the engine with the most pages in the database IS NOT the best. Not surprisingly, you can get the most out of your engine by using your head to select search words, knowing your search engine to avoid mistakes with spelling and truncation, and using the special tools available such as specifiers for titles, images, links, etc. The hardware power for rapid searches and databases covering a large fraction of the net is yesterday's accomplishment. We, as users, are living in a special time when search engines are undergoing a more profound evolution, the refinement of their special tools

- Slides: 48