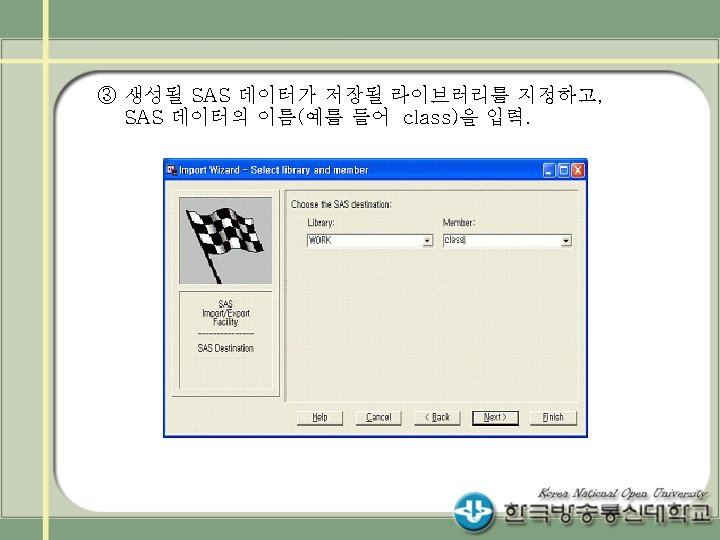
SAS 1 sales SAS WORK sales Data sales






 프로그램을 수행하면 sales라는 SAS 데이터셋이 WORK 라이브러리에 생성됨.")


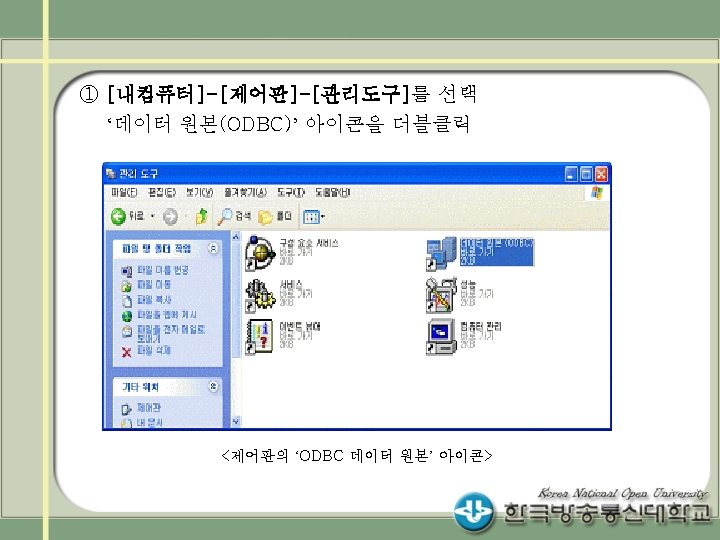
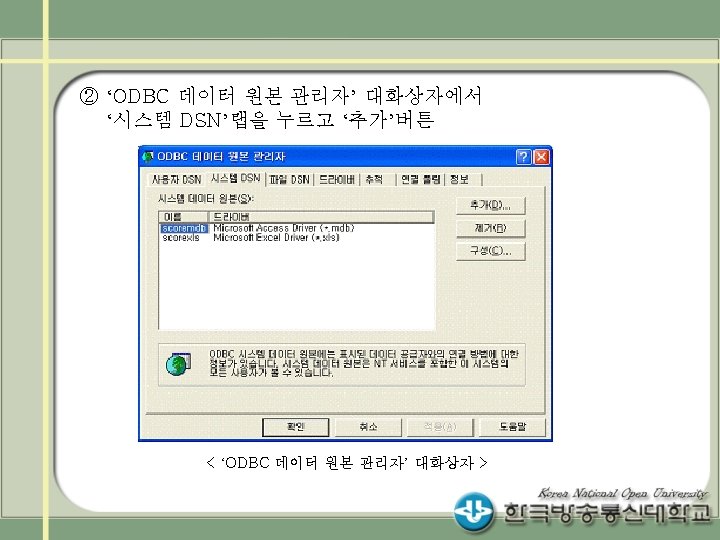
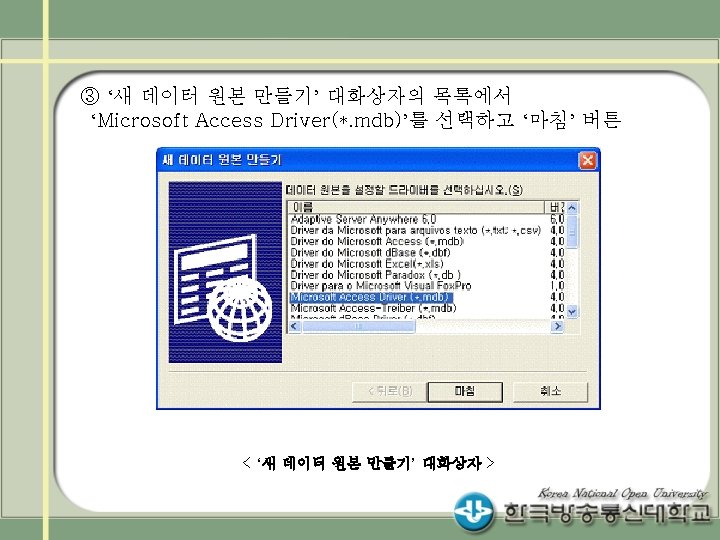
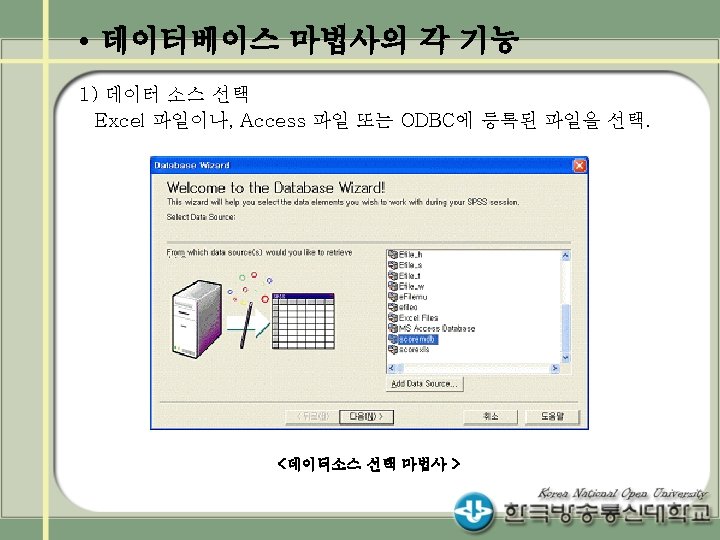
 설정 방법 (예 2) 확장편집기에서 라이브러리 생성 LIBNAME mydata 'C: data'; DATA")


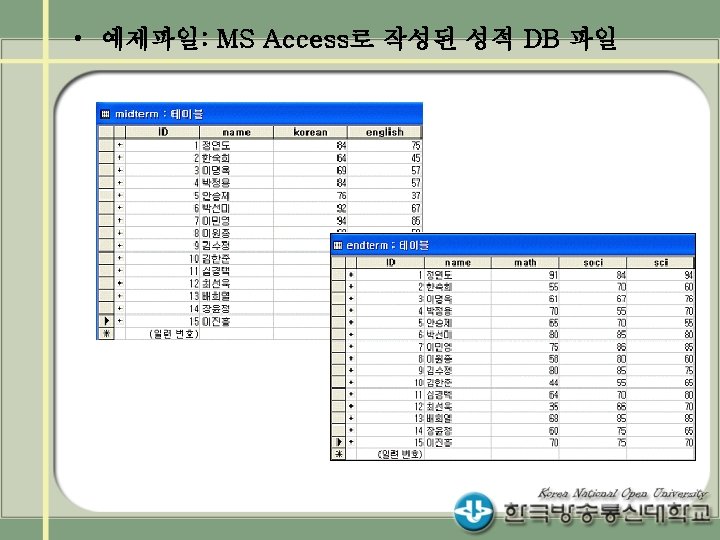
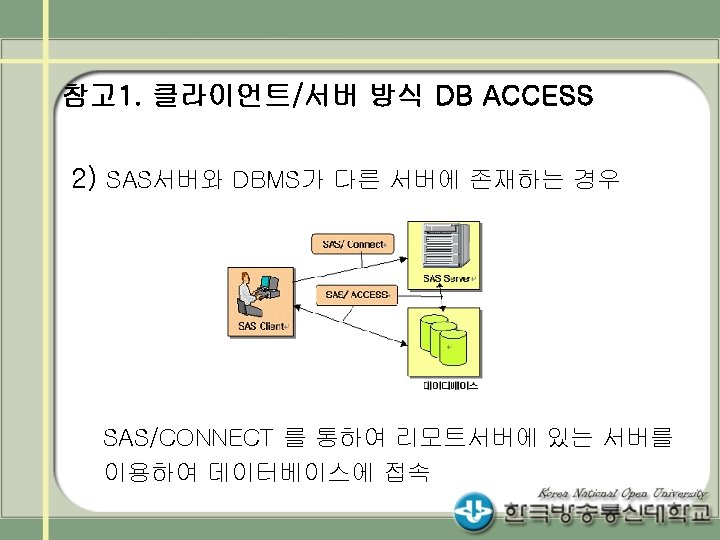
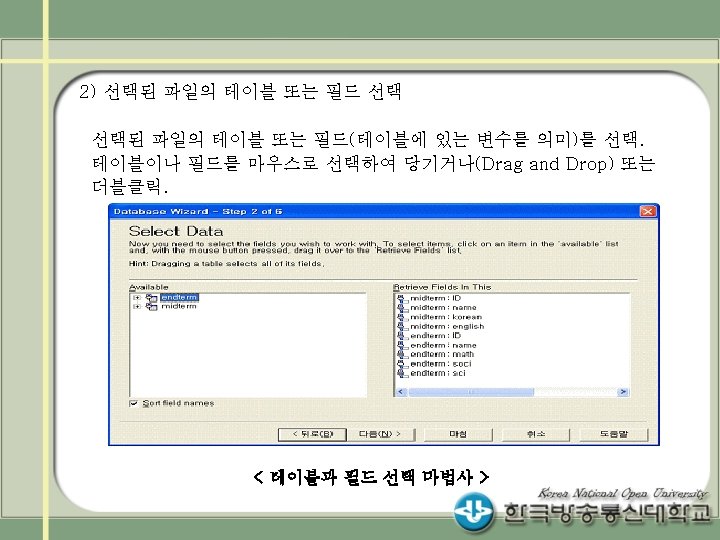
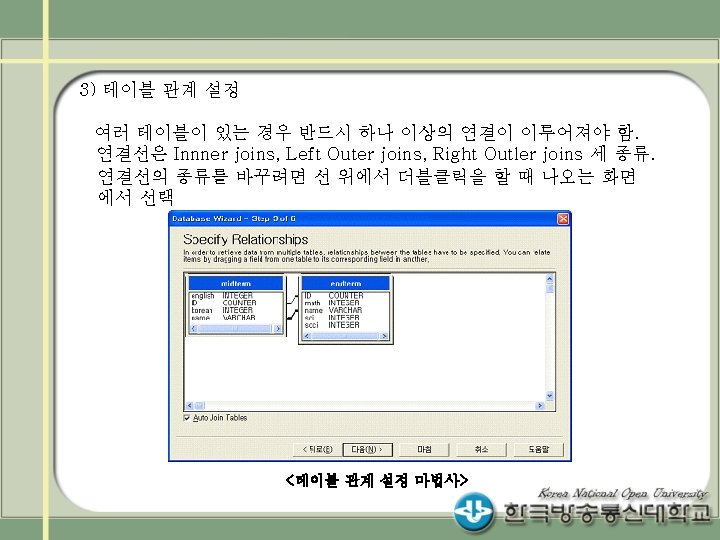
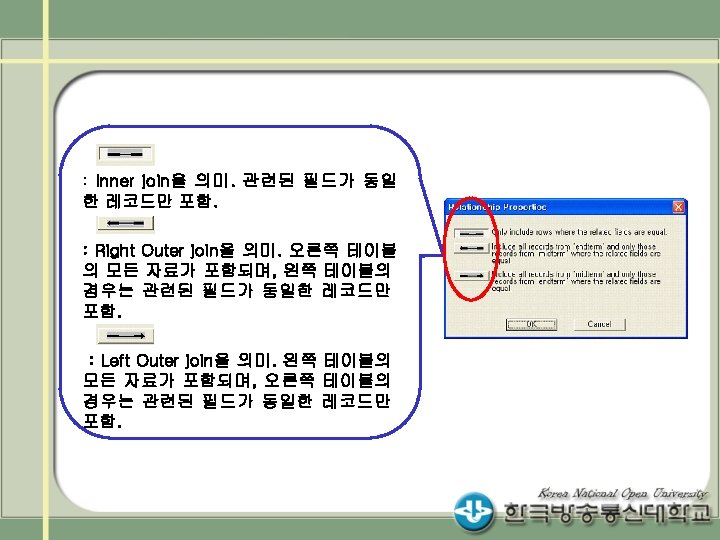
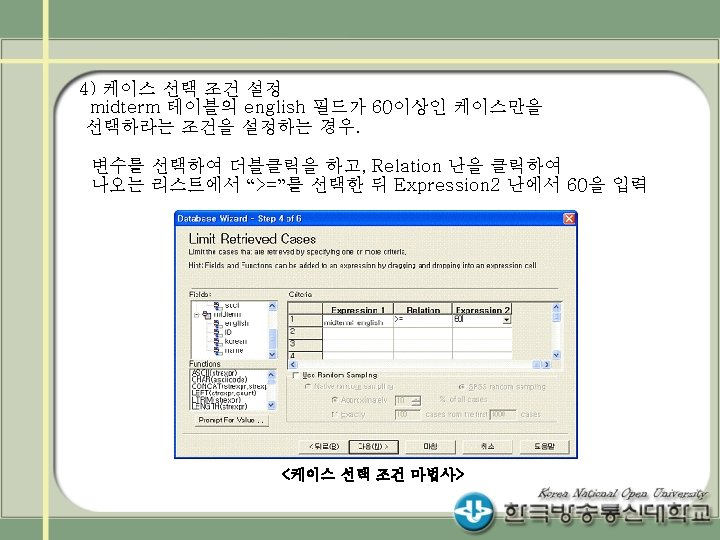
 Access DB의 두개의 테이블 midterm과 endterm을 읽어 두 데이터를 병합(merge)하여 출력하는 프로그램")
 ※ (예3 프로그램에서) Access DB의 사용자이름 및 패스워드가 USER=test, PASSWORD=testuser 로 설정된")
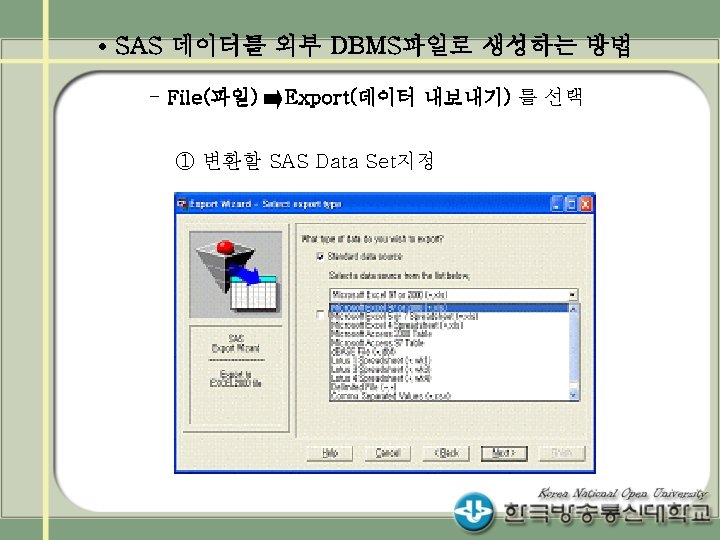
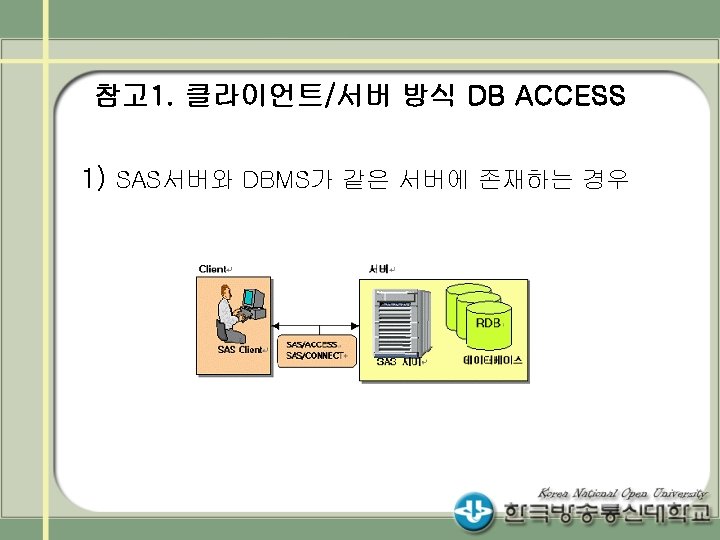
 RDB 데이터의 SAS 데이터로의 변환 Sybase DB의 예 1) Sybase DB LIBNAME")
 RDB 데이터의 SAS 데이터로의 변환 Oracle DB 의 예 2) Oracle DB")

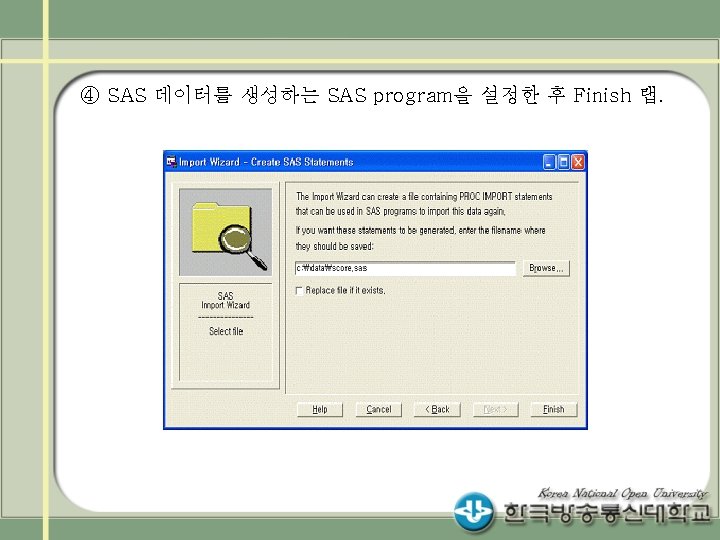
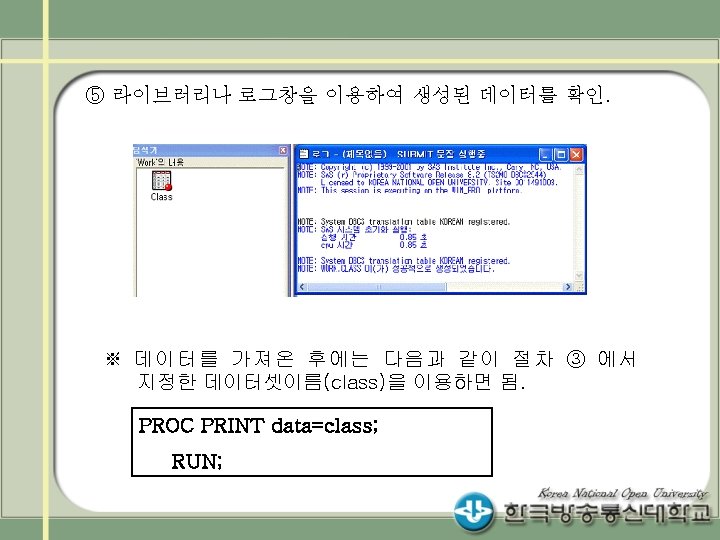
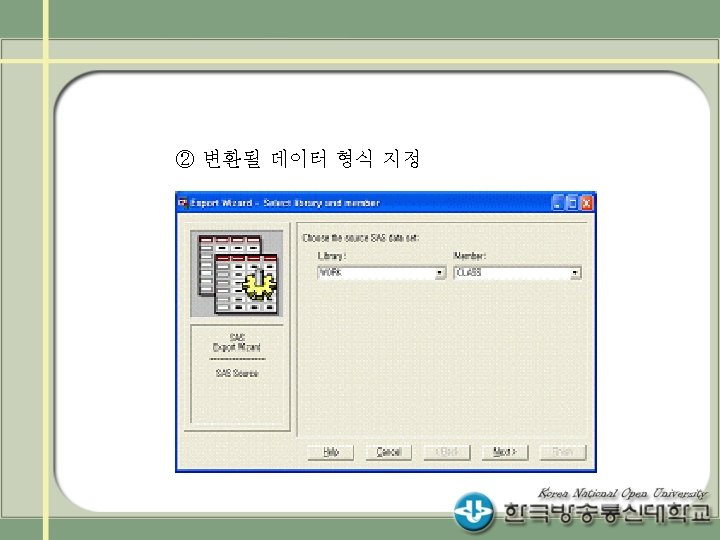
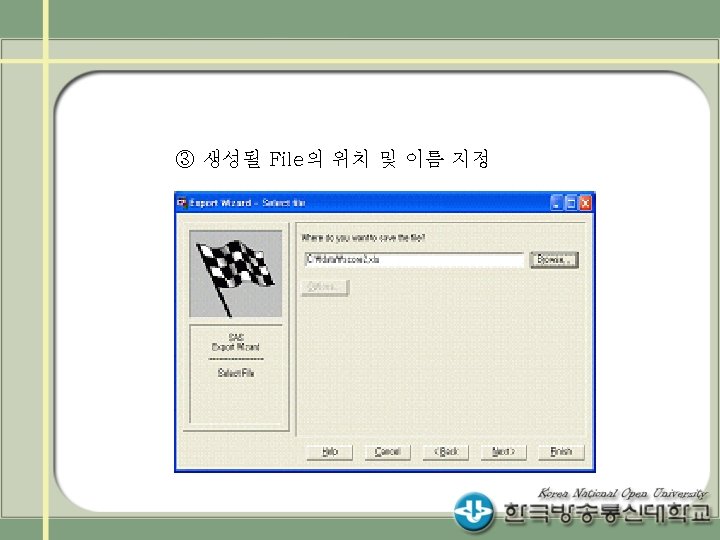
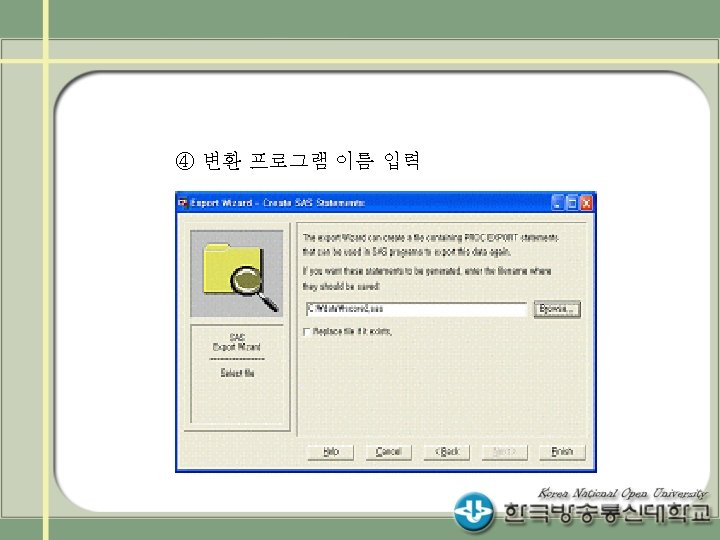
 SAS IMPORT/EXPORT 프로시져 PROC IMPORT OUT= WORK.")





 sql. Fetch 내용 sql. Fetch 함수는 ODBC 데이터베이스의 테이블을 data frame 으로 가져오는")
 sql. Query 내용 sql. Query 함수는 ODBC 데이터베이스에 SQL 문을 수행해서 자료를 가져오는")
 ID name math")


- Slides: 58
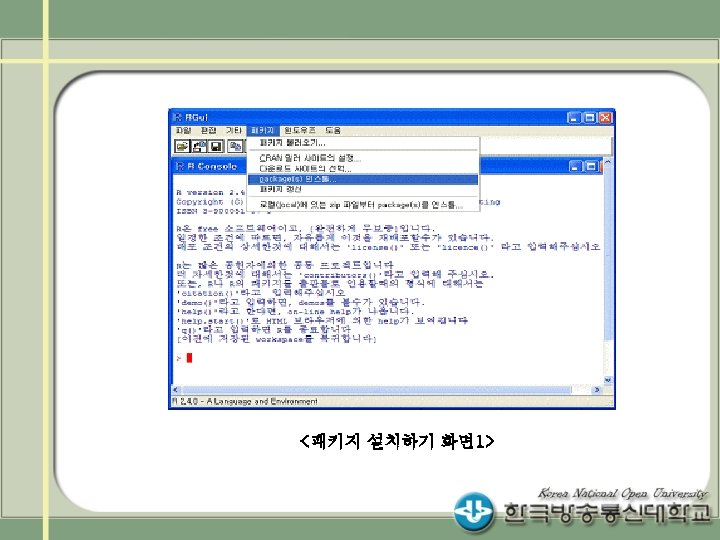
SAS 라이브러리의 생성 - (예 1) 프로그램을 수행하면 sales라는 SAS 데이터셋이 WORK 라이브러리에 생성됨. 생성된 sales 데이터셋은 프로그램의 종 료와 함께 삭제됨. Data sales; INPUT invoice $ 1 -4 location $ 6 -8 @; IF location='KOR' THEN INPUT @10 date mmddyy 8. @19 amount comma 8. ; ELSE IF location ='EUR' THEN INPUT @10 date 7. @18 amount comma 8. ; DATALINES; 1012 KOR 01 -29 -99 3, 295. 50 1013 KOR 01 -30 -99 2, 938. 00 3034 EUR 30 JAN 99 1, 876. 44 … RUN; - 따라서 생성된 SAS 데이터를 보관하여 나중에 다시 사용하고자 한다면 임시 공간이 아닌 다른 곳에 SAS 데이터를 저장.
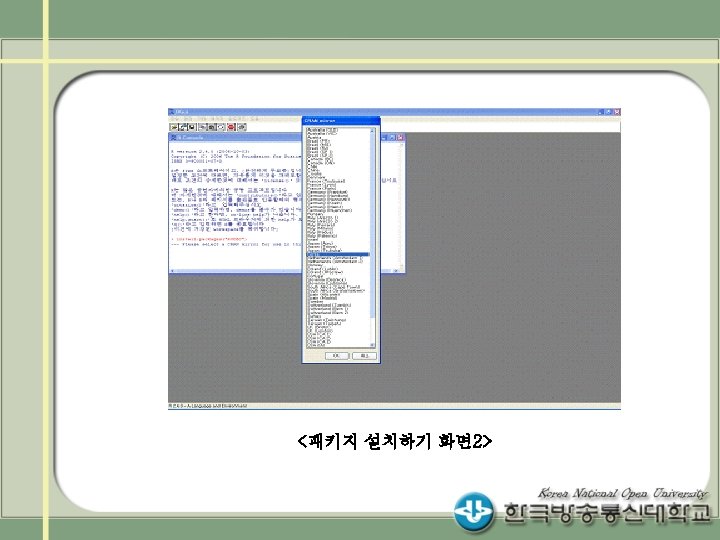
SAS 라이브러리(Library) 설정 방법 (예 2) 확장편집기에서 라이브러리 생성 LIBNAME mydata 'C: data'; DATA mydata. sales; INPUT invoice $ 1 -4 location $ 6 -8 @; IF location='KOR' THEN INPUT @10 date mmddyy 8. @19 amount comma 8. ; ELSE IF location ='EUR' THEN INPUT @10 date 7. @18 amount comma 8. ; DATALINES; 1012 KOR 01 -29 -99 3, 295. 50 1013 KOR 01 -30 -99 2, 938. 00 3034 EUR 30 JAN 99 1, 876. 44 … RUN; PROC PRINT data=mydata. sales; RUN;
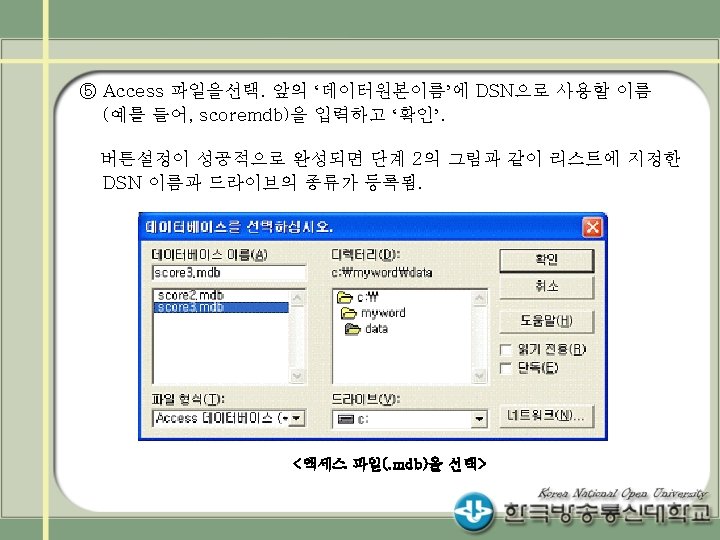
(예 3) Access DB의 두개의 테이블 midterm과 endterm을 읽어 두 데이터를 병합(merge)하여 출력하는 프로그램 LIBNAME myaccess odbc dsn="scoremdb"; PROC SQL; create table test 1 as select * from myaccess. midterm; quit; PROC SQL ; create table test 2 as select * from myaccess. endterm; quit; DATA score; merge test 1 test 2; RUN; PROC PRINT data=score; RUN;
(예3 출력결과) ※ (예3 프로그램에서) Access DB의 사용자이름 및 패스워드가 USER=test, PASSWORD=testuser 로 설정된 경우 LIBNAME myaccess odbc dsn="scoremdb" uid=“test” pwd=“testuser”;
(예 4) RDB 데이터의 SAS 데이터로의 변환 Sybase DB의 예 1) Sybase DB LIBNAME mylib sybase user='sas‘ password='sas' database=SASDB server=SAS schema=dbo; ※ SYBASE의 경우 : user, password를 sas 로 가정, database는 SASDB, server 는 SAS로 하여 데이터베이스에 접속
(예 4) RDB 데이터의 SAS 데이터로의 변환 Oracle DB 의 예 2) Oracle DB LIBNAME mylib oracle user='sas‘ password='sas‘ path=SASPATH ※ ORACLE의 경우 : user, password를 sas로 가정하였고 path를 SASPATH로 하여 연결
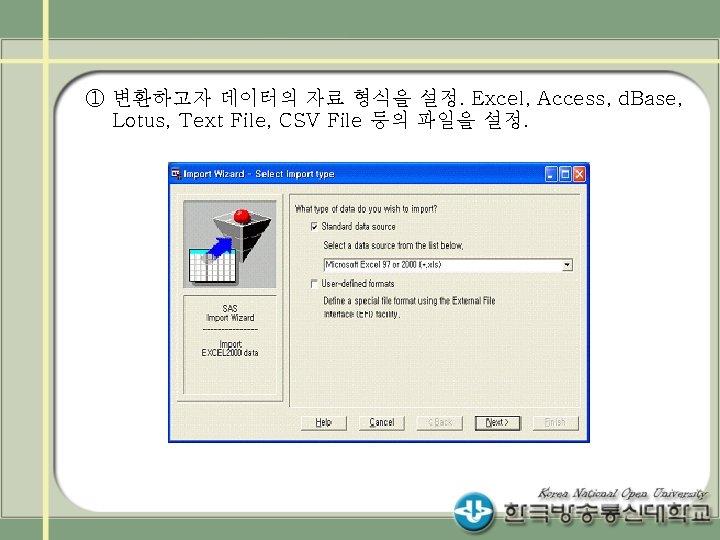
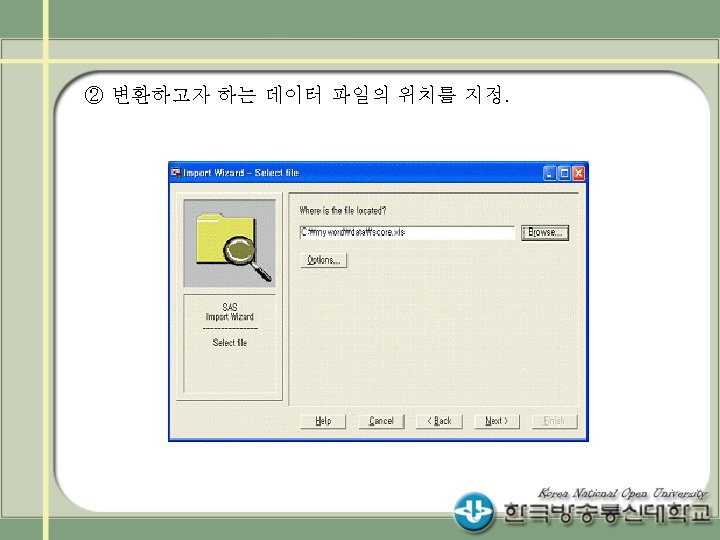
• SAS IMPORT/EXPORT 프로시져 (예 5) SAS IMPORT/EXPORT 프로시져 PROC IMPORT OUT= WORK. class ; DATAFILE= "C: ₩myword₩data₩score. xls" ; DBMS=EXCEL 2000 REPLACE; GETNAMES=YES; RUN; PROC EXPORT DATA= WORK. class ; OUTFILE= "C: ₩data₩score 2. xls" DBMS=EXCEL 2000 REPLACE; RUN;
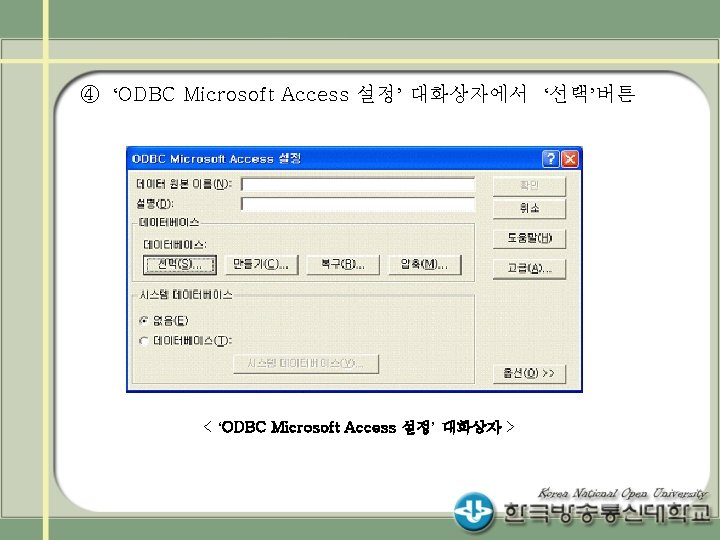
• ACCESS DB 가져오기 - ODBC에 scoremdb 라는 DSN 이름으로 등록되어 있는 경우, > install. packages("RODBC") > library(RODBC) > channel <- odbc. Connect("scoremdb") <RODBC 연결 내용>
• 테이블의 자료 가져오기 - sql. Tables, sql. Fetch, sql. Query 등의 함수를 이용. 1) sql. Tables 함수 내용 sql. Tables 함수는 연결된 데이터베이스의 테이블 이름을 보여줌 > sql. Tables(channel) TABLE_CAT TABLE_SCHEM TABLE_NAME TABLE_TYPE REMARKS 1 C: ₩₩myword₩₩data₩₩score 3 <NA> MSys. Access. Objects SYSTEM TABLE <NA> 2 C: ₩₩myword₩₩data₩₩score 3 <NA> MSys. ACEs SYSTEM TABLE 3 C: ₩₩myword₩₩data₩₩score 3 <NA> MSys. Objects SYSTEM TABLE 4 C: ₩₩myword₩₩data₩₩score 3 <NA> MSys. Queries SYSTEM TABLE 5 C: ₩₩myword₩₩data₩₩score 3 <NA> MSys. Relationships SYSTEM TABLE <NA> endterm 6 C: ₩₩myword₩₩data₩₩score 3 <NA> 7 C: ₩₩myword₩₩data₩₩score 3 <NA> TABLE midterm TABLE
2) sql. Fetch 내용 sql. Fetch 함수는 ODBC 데이터베이스의 테이블을 data frame 으로 가져오는 기능을 수행. > sql. Fetch(channel, "midterm") ID name korean english 1 1 정연도 84 75 2 2 한숙희 64 45 3 3 이명옥 69 57 4 4 박정용 84 57 5 5 안승제 76 37 6 6 박선미 92 67 7 7 이민영 94 85 8 8 이원종 62 52 9 9 김수정 35 38 10 10 김한준 75 36 11 11 심경택 42 29 12 12 최선욱 34 31 13 13 배희열 84 54 14 14 장윤정 63 40 15 15 이진흥 42 55 > sql. Fetch(channel, "endterm") ID name math soci sci 1 1 정연도 91 84 94 2 2 한숙희 55 70 60 3 3 이명옥 61 67 76 4 4 박정용 70 55 70 5 5 안승제 65 70 55 6 6 박선미 80 85 80 7 7 이민영 75 86 85 8 8 이원종 58 80 60 9 9 김수정 80 85 75 10 10 김한준 44 55 65 11 11 심경택 64 70 80 12 12 최선욱 35 66 70 13 13 배희열 68 85 85 14 14 장윤정 60 75 65 15 15 이진흥 70 75 70
3) sql. Query 내용 sql. Query 함수는 ODBC 데이터베이스에 SQL 문을 수행해서 자료를 가져오는 기능을 수행. > sql. Query(channel, "select * from endterm") ID name math soci sci 1 1 정연도 91 84 94 2 2 한숙희 55 70 60 3 3 이명옥 61 67 76 4 4 박정용 70 55 70 5 5 안승제 65 70 55 6 6 박선미 80 85 80 7 7 이민영 75 86 85 8 8 이원종 58 80 60 9 9 김수정 80 85 75 10 10 김한준 44 55 65 11 11 심경택 64 70 80 12 12 최선욱 35 66 70 13 13 배희열 68 85 85 14 14 장윤정 60 75 65 15 15 이진흥 70 75 70
> sql. Query(channel, "select * from endterm where id > 10") ID name math soci sci 1 11 심경택 64 70 80 2 12 최선욱 35 66 70 3 13 배희열 68 85 85 4 14 장윤정 60 75 65 5 15 이진흥 70 75 70 > sql. Query(channel, "select * from endterm where math > 70 ") ID name math soci sci 1 1 정연도 91 84 94 2 6 박선미 80 85 80 3 7 이민영 75 86 85 4 9 김수정 80 85 75
※ 두 테이블을 합친 뒤, 평균이나 표준편차를 구하는 예. > midterm <- sql. Query(channel, "select * from midterm") > endterm <- sql. Query(channel, "select * from endterm") > score <- cbind(midterm, endterm[, c(3: 5)]) > mean(score["korean"]) korean 66. 66667 > sd(score[3]) korean 20. 32123
• Excel 파일 불러오기 - scorexls 라는 DSN이름으로 ODBC에 등록되어 있는 경우 > > library(RODBC) channel 2 <- odbc. Connect("scorexls") sql. Tables(channel 2) sql. Query(channel 2, "select * from [sheet 1$]") <R에서 Excel 파일 열기>