RISC 5 Decode EXecute Writeback Store Memory ALU



典型的 RISC 5段流水线 Decode EXecute Writeback Store Memory ALU B Data Cache A Registers Instruction Cache Inst. Register PC Imm Fetch This version designed for regfiles/memories with synchronous reads and writes. 6

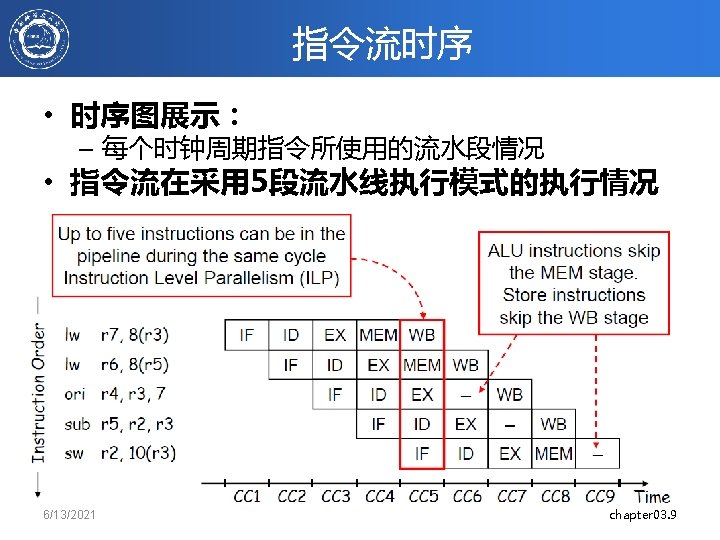


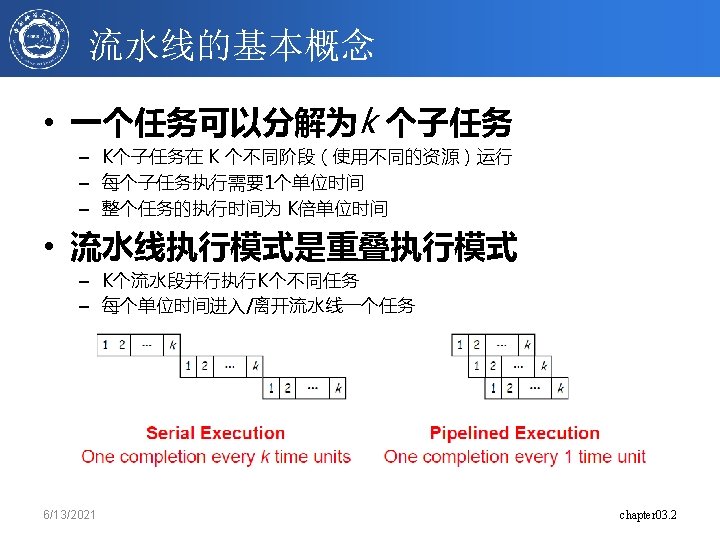
Pipeline CPI Examples Time Inst 1 Inst 2 Inst 3 Measure from when first instruction finishes to when last instruction in sequence finishes. Inst 1 Inst 2 Bubble Inst 3 Inst 1 Bubble 1 Inst 2 Inst Bubble 3 2 Inst 3 3 instructions finish in 3 cycles CPI = 3/3 =1 3 instructions finish in 4 cycles CPI = 4/3 = 1. 33 3 instructions finish in 5 cycles CPI = 5/3 = 1. 67 12







Interlocking Versus Bypassing add x 1, x 3, x 5 sub x 2, x 1, x 4 F F add x 1, x 3, x 5 D X M W F D X M W F D X bubble Instruction interlocked in decode stage bubble M W sub x 2, x 1, x 4 add x 1, x 3, x 5 M W sub x 2, x 1, x 4 Bypass around ALU with no bubbles 19

Example Bypass Path Decode EXecute Writeback Store Memory ALU B Data Cache A Registers Instruction Cache Inst. Register PC Imm Fetch 20

Fully Bypassed Data Path Fetch Decode Memory F Store Writeback ALU B Data Cache A Registers Instruction Cache Inst. Register PC Imm EXecute D X M W F D X M W [ Assumes data written to registers in a W cycle is readable in parallel D cycle (dotted line). Extra write data register and bypass paths required if this is not possible. ] 21


采用软件方法避免数据相关 Try producing fast code for a = b + c; d = e – f; assuming a, b, c, d , e, and f in memory. Slow code: LW Rb, b LW Rc, c ADD Ra, Rb, Rc SW a, Ra LW Re, e LW Rf, f SUB Rd, Re, Rf SW d, Rd 6/13/2021 Fast code: LW LW LW ADD LW SW SUB SW Rb, b Rc, c Re, e Ra, Rb, Rc Rf, f a, Ra Rd, Re, Rf d, Rd chapter 3. 23
 • 无条件直接转移 – Opcode, PC, and offset • 基于基址寄存器的无条件转移 –")
Control Hazards 如何计算下一条指令地址(next PC) • 无条件直接转移 – Opcode, PC, and offset • 基于基址寄存器的无条件转移 – Opcode, Register value, and offset • 条件转移 – Opcode, Register (for condition), PC and offset • 其他指令 – Opcode and PC ( and have to know it’s not one of above ) 24

Control flow information in pipeline Fetch Decode EXecute Opcode, offset known Store ALU B Data Cache A Registers Inst. Register PC Instruction Cache Writeback Branch condition, Jump register value known Imm PC known Memory 25
![RISC-V Unconditional PC-Relative Jumps Jump? [ Kill bit turns instruction into a bubble ]](http://slidetodoc.com/presentation_image_h2/6b1ea90a95f204b7e447bceed0d928d2/image-26.jpg "RISC-V Unconditional PC-Relative Jumps Jump? [ Kill bit turns instruction into a bubble ]")
RISC-V Unconditional PC-Relative Jumps Jump? [ Kill bit turns instruction into a bubble ] Add Fetch Decode ALU B Registers Instruction Cache Inst. Register PC_fetch Kill Imm +4 A FKill PC_decode PCJump. Sel EXecute 26

Pipelining for Unconditional PC-Relative Jumps F j target D X M W F D X bubble M W ; 等同于 jal x 0, offset ; pc +=sext(offset) target: add x 1, x 2, x 3 27



RISC-V Conditional Branches Fetch Inst. Decode ALU B Registers Instruction Cache Inst. Register PC_fetch Kill +4 Cond? Add PC_execute DKill A PC_decode FKill Branch? Add PCSel EXecute 30

Pipelining for Conditional Branches F beq x 1, x 2, target D X M W F D X bubble M W target: add x 1, x 2, x 3 31

Pipelining for Jump Register • Register value obtained in execute stage (等同于 jalr x 0, 0(x 1); F D X M W jr x 1 F pc=0(x 1) bubble D X M W F D X bubble M W target: add x 5, x 6, x 7 32




DYSEAC, first mobile computer! • Carried in two tractor trailers, 12 tons + 8 tons • Built for US Army Signal Corps [Courtesy Mark Smotherman] 36

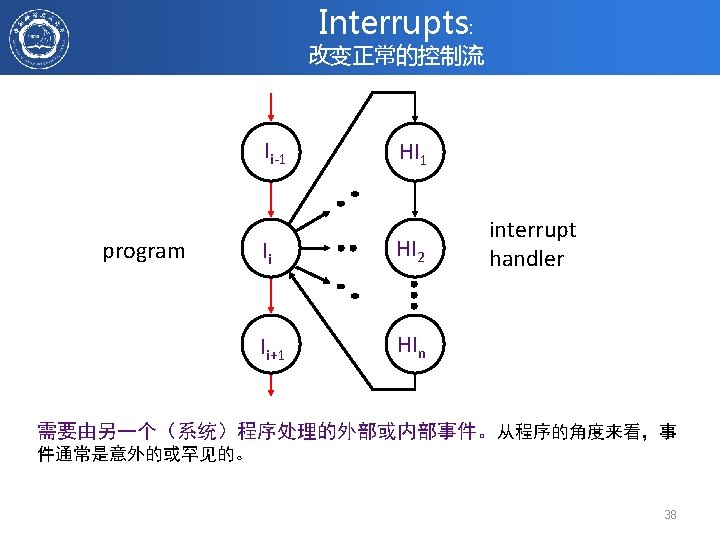



Exception Handling PC Inst. Mem PC address Exception D Decode Illegal Opcode E + M Overflow 5 -Stage Pipeline Data Mem W Data address Exceptions Asynchronous Interrupts • 如何处理不同流水段的多个并发异常? • 如何以及在哪里处理外部异步中断? 41

Exception Handling 5 -Stage Pipeline Commit Point Select Handler PC E Illegal Opcode + M Overflow Data Mem Data address Exceptions Exc D Exc E Exc M PC Kill F D PC E PC M Asynchronous Stage Kill D Stage Kill E Stage W Cause PC address Exception D Decode EPC PC Inst. Mem Interrupts Kill Writeback 42






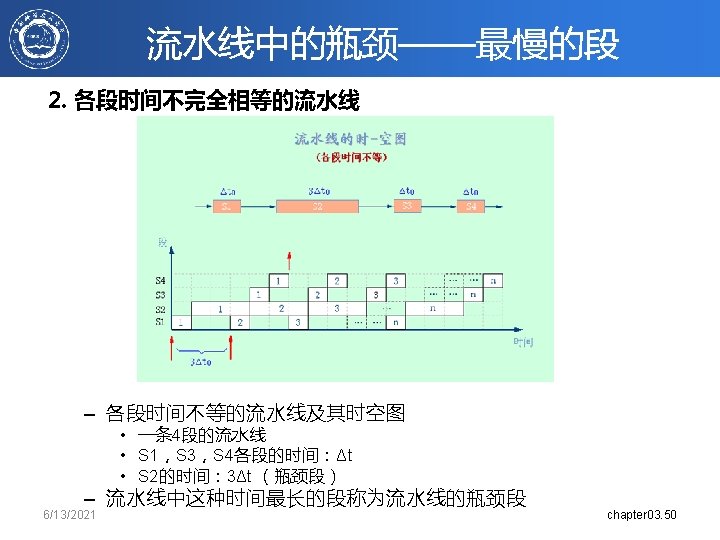

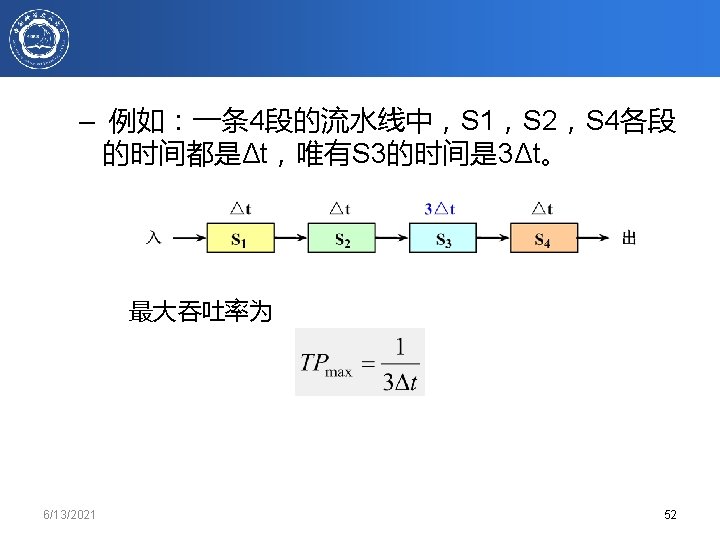
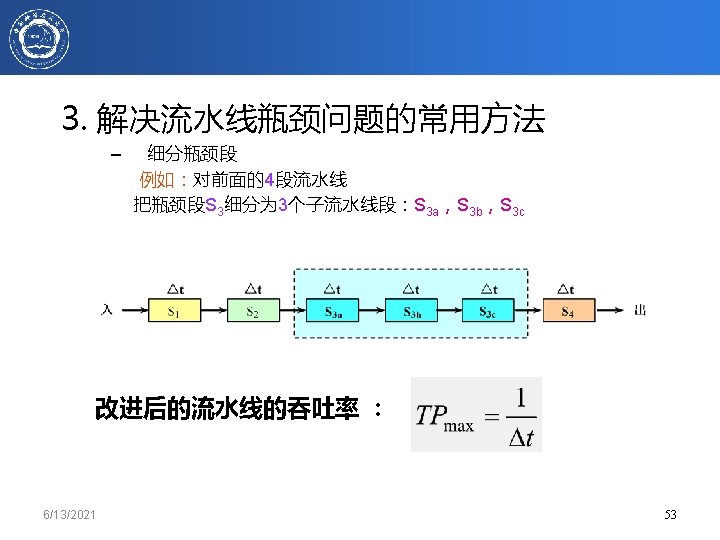
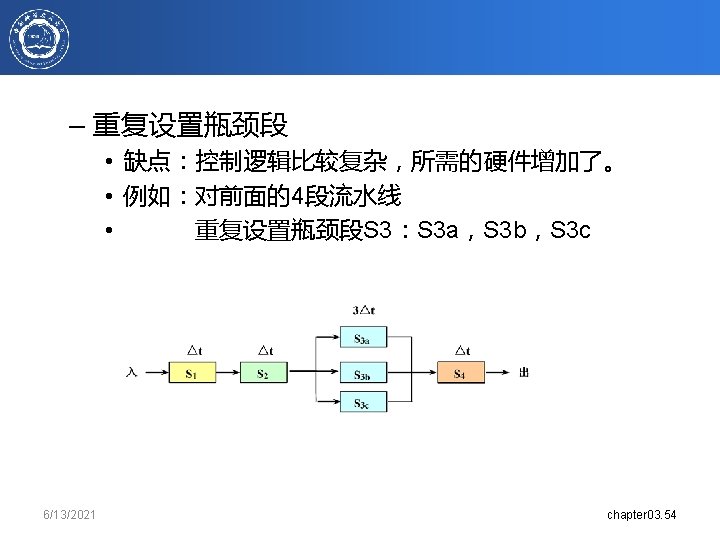
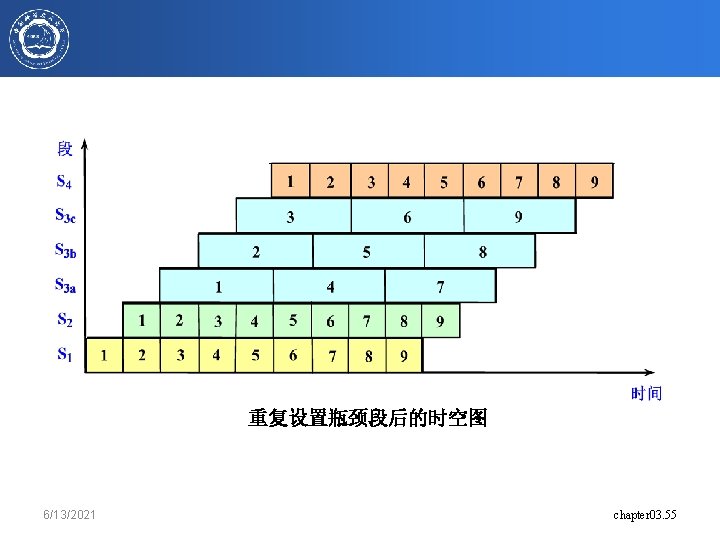






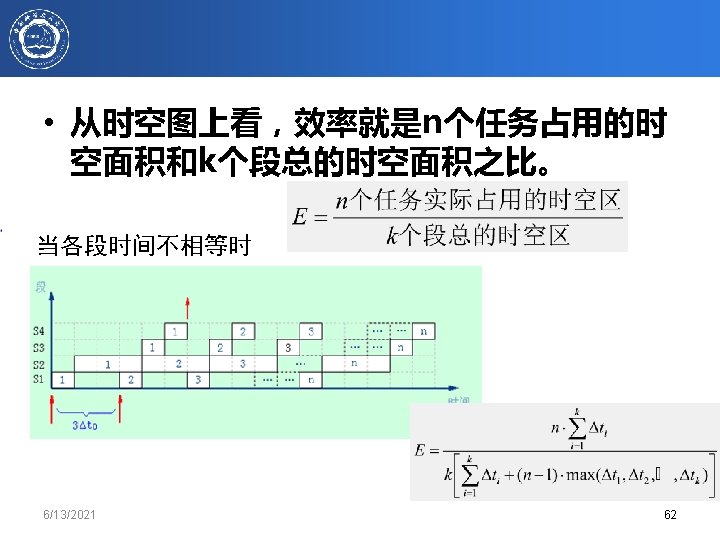


6/13/2021 chapter 3. 64


流水线的加速比计算 For simple RISC pipeline, CPI = 1: 6/13/2021 chapter 3. 66

 机器B:")
例如: Dual-port vs. Single-port • • • 机器A: Dual ported memory (“Harvard Architecture”) 机器B: Single ported memory 存在结构相关的机器B的时钟频率是机器A的时钟频率的1. 05倍 Ideal CPI = 1 在机器B中load指令会引起结构相关,所执行的指令中Loads指 令占 40% Average instruction time = CPI * Clock cycle time 无结构相关的机器A: Average Instruction time = Clock cycle time 存在结构相关的机器B: Average Instruction time = (1+0. 4*1) * clock cycle time /1. 05 = 1. 3 * clock cycle time 6/13/2021 chapter 3. 68




评估减少分支策略的效果 Scheduling Stall pipeline Predict taken Predict not taken Delayed branch Branch penalty 3 1 1 0. 5 CPI speedup v. unpipelined 3. 5 4. 4 4. 5 4. 6 speedup v. scheme stall 1. 0 1. 26 1. 29 1. 31 1. 14 = 1 + 1*14%*100% 1. 09 = 1+1*14%*65% 1. 07 = 1+ 0. 5*14% Conditional & Unconditional = 14%, 65% change PC 6/13/2021 chapter 3. 72



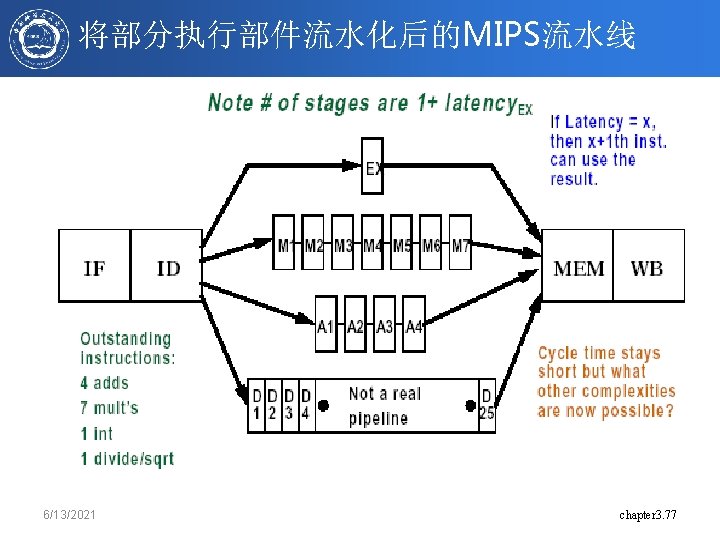
扩展的MIPS流水线 6/13/2021 chapter 3. 75
 – 定义1:完成某一操作所需的cycle数 – 定义2:使用当前指令所产生结果的指令与当前指令间的最小间隔周期数 • 循环间隔(Repeat/Initiation interval) –")
Latency & Repeat Interval • 延时(Latency) – 定义1:完成某一操作所需的cycle数 – 定义2:使用当前指令所产生结果的指令与当前指令间的最小间隔周期数 • 循环间隔(Repeat/Initiation interval) – 发射相同类型的操作所需的间隔周期数 • 对于EX部件流水化的新的MIPS Function Unit Latency Integer ALU Data Memory (Integer and FP loads(1 less for store latency)) FP Add 0 1 Repeat Interval 1 1 3 1 FP multiply 6 1 FP Divide (also integer divide and FP sqrt) 24 25 6/13/2021 chapter 3. 76

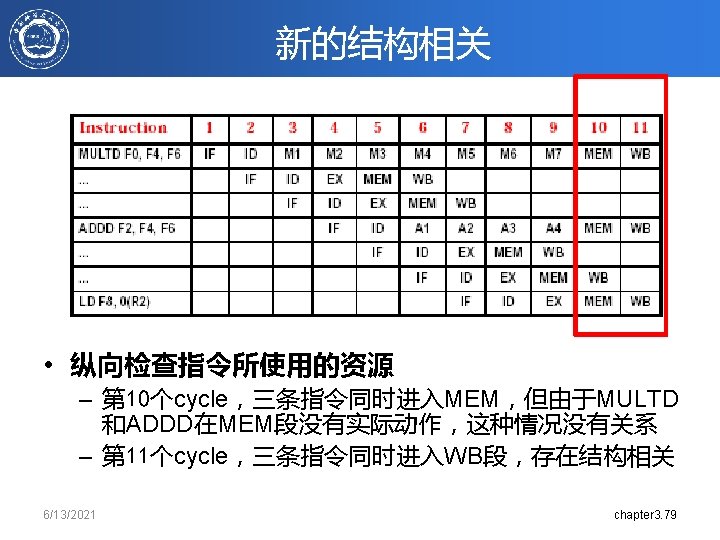

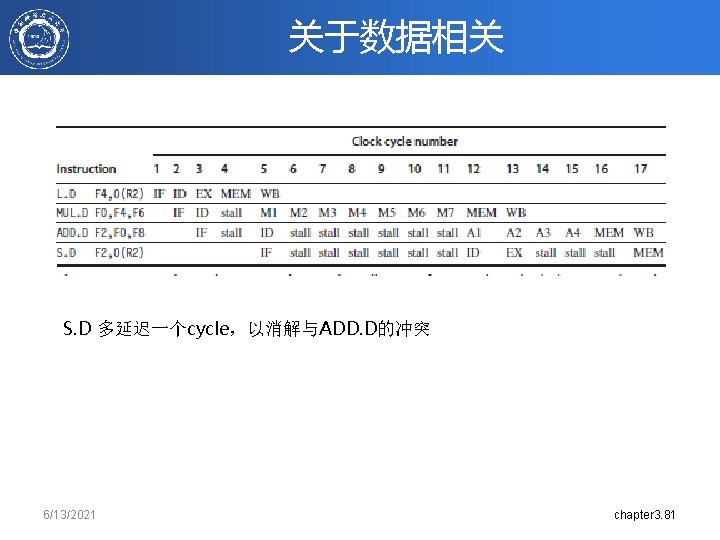




MIPS中的异常 • IF – page fault, misaligned address, memory protection violation • ID – undefined or illegal opcode • EX – arithmetic exception • MEM – page fault, misaligned address, memory protection violation • WB – none 6/13/2021 chapter 3. 85



MIPS流水线的性能 Stalls per FP operation for each major type of FP operation for the SPEC 89 FP benchmarks 6/13/2021 chapter 3. 88

平均每条指令的stall数 The stalls occurring for the MIPS FP pipeline for five for the SPEC 89 FP benchmarks. 6/13/2021 chapter 3. 89

MIPS R 4000 • 实际的 64 -bit 机器 – 主频 100 MHz ~200 MHz – 较深的流水线(级数较多)(有时也称为 superpipelining) 6/13/2021 90

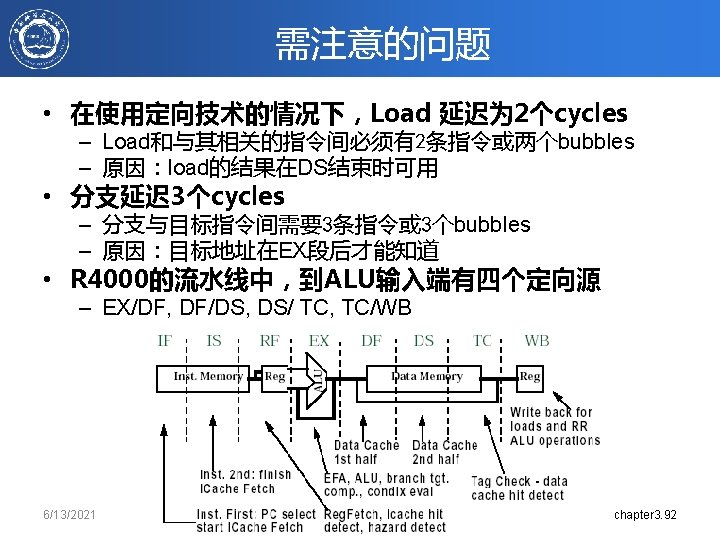

ALU输入端的定向源 6/13/2021 chapter 03. 93

图示 IF IS IF RF IS IF EX RF IS IF DS DF EX RF IS IF TC DS DF EX RF IS IF WB TC DS DF EX RF IS IF IF THREE Cycle Branch Latency (conditions evaluated during EX phase) IS IF RF IS IF EX RF IS IF DS DF EX RF IS IF TC DS DF EX RF IS IF WB TC DS DF EX RF IS IF TWO Cycle Load Latency Delay slot plus two stalls Branch likely cancels delay slot if not taken 6/13/2021 chapter 3. 94


MIPS R 4000 浮点数操作 • 3个功能部件组成:FP Adder, FP Multiplier, FP Divider • 在乘/除操作的最后一步要 使用FP Adder • FP操作需要2(negate)-112个(square root)cycles • 8 种类型的FP units: – – – – – 6/13/2021 Stage A D E M N R S U Functional unit Description FP adder Mantissa ADD stage FP divider Divide pipeline stage FP multiplier Exception test stage FP multiplier First stage of multiplier FP multiplier Second stage of multiplier FP adder Rounding stage FP adder Operand shift stage Unpack FP numbers chapter 3. 96

6/13/2021 chapter 03. 97
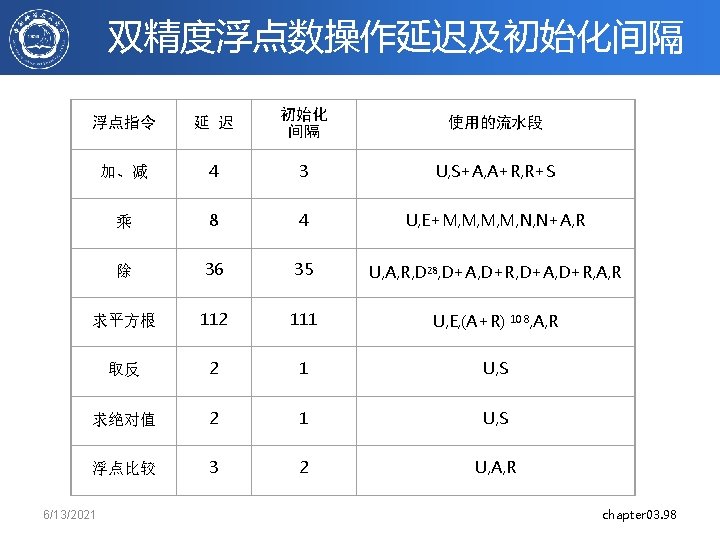

MIPS FP 流水段 FP Instr Add, Subtract Multiply Divide Square root Negate Absolute value FP compare 1 2 3 4 U S+A A+R R+S U E+M M 28 U A R D … U E (A+R)108 … U S U A R 5 N 6 7 8 … N+A R D+A,D+R, D+A, D+R, A, R AR Stages: M N R S U 6/13/2021 First stage of multiplier Second stage of multiplier Rounding stage Operand shift stage Unpack FP numbers A D E Mantissa ADD stage Divide pipeline stage Exception test stage chapter 3. 99

6/13/2021 chapter 3. 100

6/13/2021 chapter 3. 101

6/13/2021 chapter 3. 102

6/13/2021 chapter 3. 103
 6/13/2021 chapter 3. 104")
R 4000性能(1) 6/13/2021 chapter 3. 104
 6/13/2021 chapter 3. 105")
R 4000 性能(2) 6/13/2021 chapter 3. 105

")
Acknowledgements • These slides contain material developed and copyright by: – John Kubiatowicz (UCB) – Krste Asanovic (UCB) – David Patterson (UCB) – Chenxi Zhang (Tongji) • UCB material derived from course CS 152、CS 252、CS 61 C • KFUPM material derived from course COE 501、COE 502 6/13/2021 107



![在新的Datapath下各段的操作 • IF – IF/ID. IR ←Mem[PC]; – IF/ID. NPC, PC ←(if ((EX/MEM. opcode](http://slidetodoc.com/presentation_image_h2/6b1ea90a95f204b7e447bceed0d928d2/image-111.jpg "在新的Datapath下各段的操作 • IF – IF/ID. IR ←Mem[PC]; – IF/ID. NPC, PC ←(if ((EX/MEM. opcode")
在新的Datapath下各段的操作 • IF – IF/ID. IR ←Mem[PC]; – IF/ID. NPC, PC ←(if ((EX/MEM. opcode == branch) & EX/MEM. cond) {EX/MEM. ALUOutput} else {PC+4}); • ID – ID/EX. A ←Regs[IF/ID. IR[rs]]; ID/EX. B ← Regs[IF/ID. IR[rt]]; – ID/EX. NPC←IF/ID. NPC; ID/EX. IR ← IF/ID. IR; – ID/EX/Imm ← sign-extend(IF/ID. IR[immediate field]); • EX – ALU instruction • EX/MEM. IR ← ID/EX. IR; • EX/MEM. ALUOutput ← ID/EX. A func ID/EX. B; or • EX/MEM. ALUOoutput ← ID/EX. A op ID/EX. Imm; 6/13/2021 chapter 3. 111

– Load or store instruction • EX/MEM. IR ← ID/EX. IR • EX/MEM. ALUOutput ← ID/EX. A + ID/EX. Imm • EX/MEM. B ← ID/EX. B – Branch instruction • EX/MEM. ALUOutput ← ID/EX. NPC + (ID/EX. Imm << 2) • EX/MEM. cond ← (ID/EX. A == 0); • MEM – ALU Instruction • MEM/WB. IR ←EX/MEM. IR • MEM/WB. ALUOutput ←EX/MEM. ALUOutput; – Load or store instruction • MEM/WB. IR ←EX/MEM. IR; • MEM/WB. LMD ← Mem[EX/MEM. ALUOutput]; or • Mem[EX/MEM. ALUOutput] ← EX/MEM. B; (store) 6/13/2021 chapter 3. 112
![• WB – ALU instruction • Regs[MEM/WB. IR[rd]] ← MEM/WB. ALUOutput; or •](http://slidetodoc.com/presentation_image_h2/6b1ea90a95f204b7e447bceed0d928d2/image-113.jpg "• WB – ALU instruction • Regs[MEM/WB. IR[rd]] ← MEM/WB. ALUOutput; or •")
• WB – ALU instruction • Regs[MEM/WB. IR[rd]] ← MEM/WB. ALUOutput; or • Regs[MEM/WB. IR[rt]] ← MEM/WB. ALUOutput; – For load only • Regs[MEM/WB. IR[rt]] ← MEM/WB. LMD 6/13/2021 chapter 3. 113
 6/13/2021 Reg DMem Ifetch Reg DMem Reg ALU O")
简化的 Pipelining Time (clock cycles) 6/13/2021 Reg DMem Ifetch Reg DMem Reg ALU O r d e r Ifetch ALU I n s t r. ALU Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Ifetch Reg Reg DMem Reg chapter 3. 114
- Slides: 114