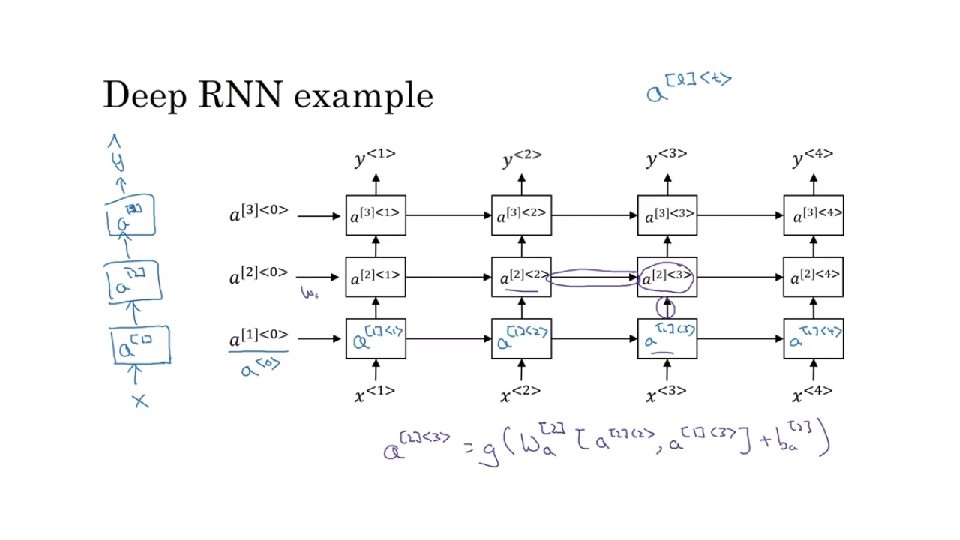
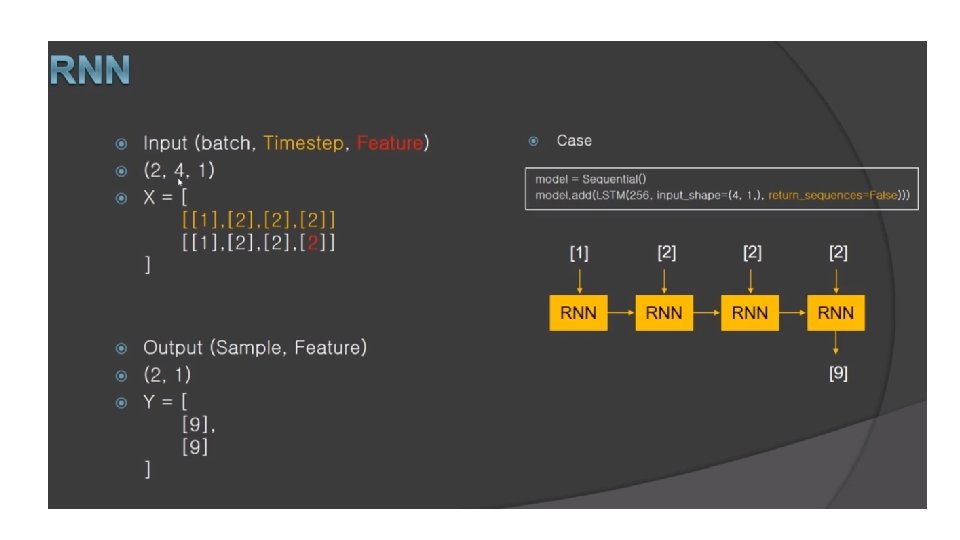
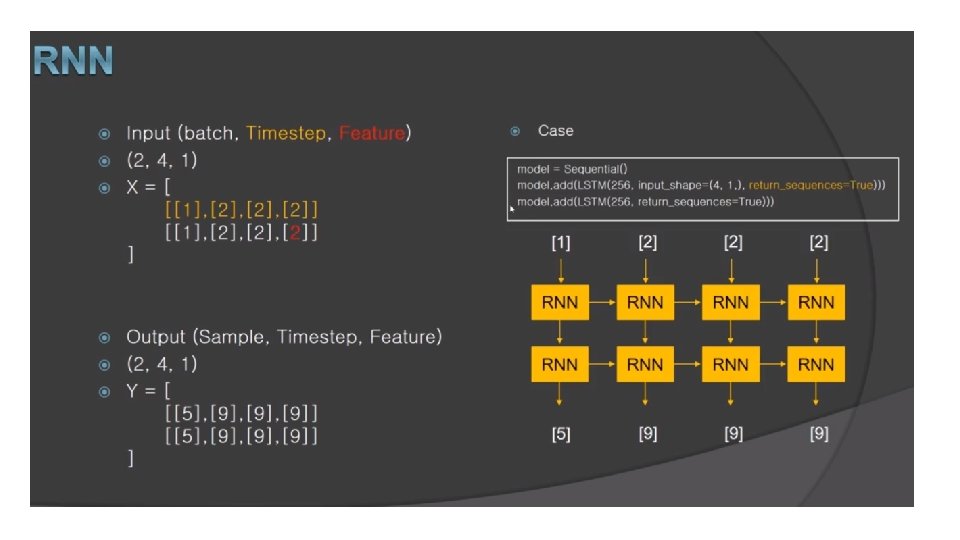
Recurrent Neural Networks deeplearning ai Gated Recurrent Unit
")



 GRU")

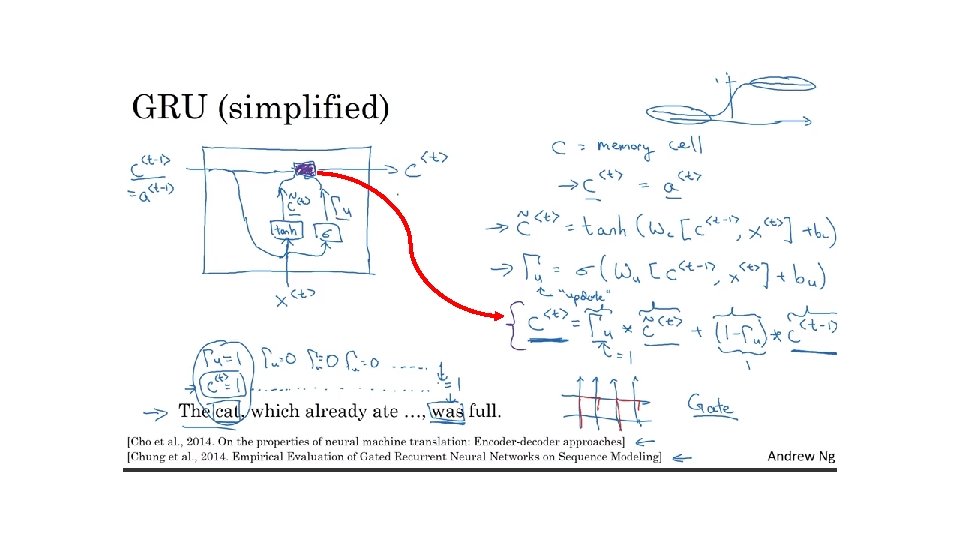

 The cat, which already ate …, was full. [Cho et al. ,")



 unit")
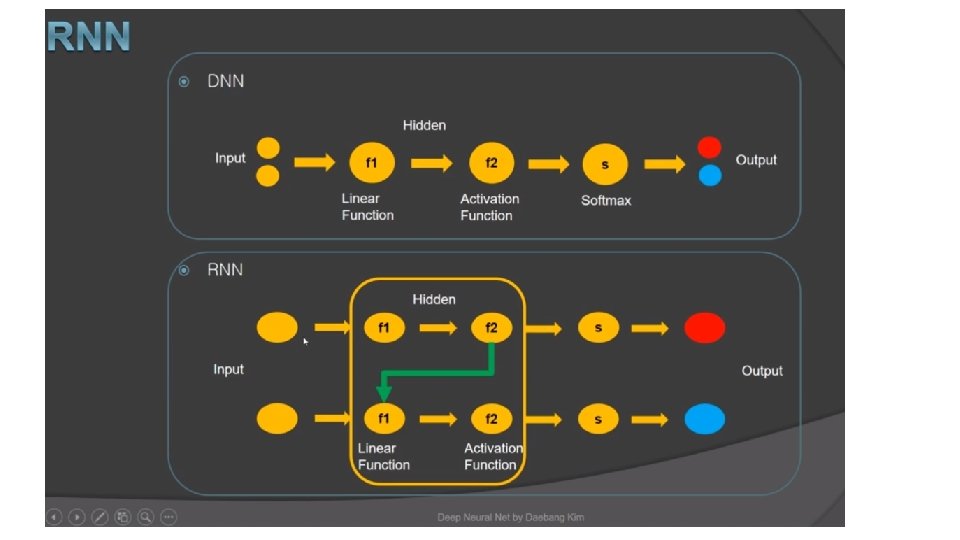
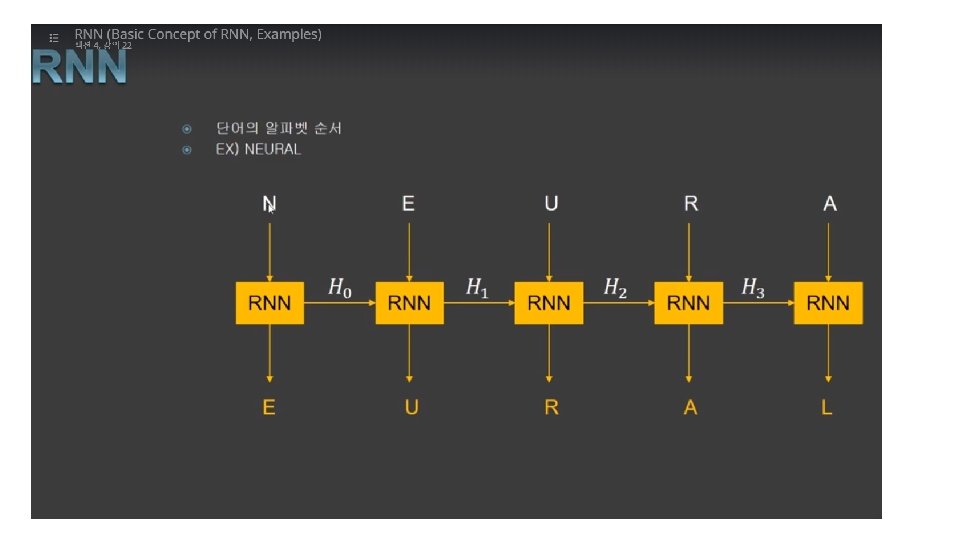
 is a form of neural networks that feed")
 • Standard RNN • Input concatenate with output then feed")





: input gate layer • Decide what information to store in the")
: update the old cell state • Ct-1 Ct “We multiply the")
. “Finally, we need to")

=sigmoid & tanh()=hyperbolic tangent are activation functions")








 reset gate Update gate It combines")



 Andrew Ng")

- Slides: 49
Recurrent Neural Networks deeplearning. ai Gated Recurrent Unit (GRU)
RNN unit Output activation value Andrew Ng
( c ) GRU
Output activation value Candidate of C Update Gate = {0, 1}
Same dimension, for example 100 Element-wise Dot product
GRU (simplified) The cat, which already ate …, was full. [Cho et al. , 2014. On the properties of neural machine translation: Encoder-decoder approaches] [Chung et al. , 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling] Andrew Ng
Memory cell ---- remember ---- for example, one bit : remember the singular or plural cat another bit: remember about eating and talk about food ---- GRU update each memory cell at every steps
Relevant gate
Full GRU The cat, which ate already, was full. Andrew Ng
Recurrent Neural Networks deeplearning. ai LSTM (long short term memory) unit
Introduction • RNN (Recurrent neural network) is a form of neural networks that feed outputs back to the inputs during operation • LSTM (Long short-term memory) is a form of RNN. It fixes the vanishing gradient problem of the original RNN. • Application: Sequence to sequence model based using LSTM for machine translation • Materials are mainly based on links found in https: //www. tensorflow. org/tutorials RNN, LSTM v. 7. c 16 Andrew Ng
LSTM (Long short-term memory) • Standard RNN • Input concatenate with output then feed to input again • LSTM • The repeating structure is more complicated RNN, LSTM v. 7. c 17 Andrew Ng
GRU and LSTM More powerful and general version GRU LSTM [Hochreiter & Schmidhuber 1997. Long short-term memory] Andrew Ng
GRU and LSTM More powerful and general version GRU LSTM [Hochreiter & Schmidhuber 1997. Long short-term memory] Andrew Ng
LSTM in pictures softmax -- * tanh * * forget gate softmax * -- update gate * -- tanh output gate softmax * -- Andrew Ng
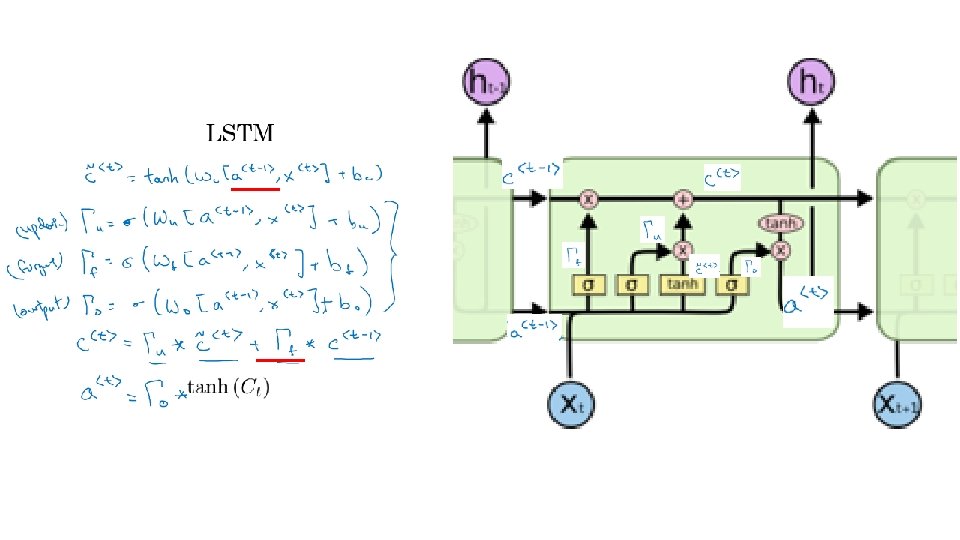
Core idea of LSTM • C= State Ct-1 = State of time t-1 Ct = State of time t • Using gates it can add or remove information to avoid the long term dependencies problem Bengio, et al. (1994) =a sigmoid function. RNN, LSTM v. 7. c A gate controlled by : The sigmoid layer outputs numbers between zero and one, describing how much of each component should be let through. A value of zero means “let nothing through, ” while a value of one means “let everything through!” An LSTM has three of these gates, to protect and control the cell state http: //colah. github. io/posts/2 015 -08 -Understanding-LSTMs/ 23 Andrew Ng
First step: forget gate layer • Decide what to throw away from the cell state What to be kept/forget “For the language model example. . the cell state might include the gender of the present subject, so that the correct pronouns can be used. When we see a new subject, we want to forget the gender of the old subject. ” “It looks at ht− 1 and xt, and outputs a number between 0 and 1 for each number in the cell state Ct− 1. A 1 represents “completely keep this” while a 0 represents “completely get rid of this. ” ” http: //colah. github. io/posts/2015 -08 -Understanding-LSTMs/ RNN, LSTM v. 7. c 24 Andrew Ng
Second step (a): input gate layer • Decide what information to store in the cell state What to be kept/forget New information added to become the state Ct “For the language model example. . In the example of our language model, we’d want to add the gender of the new subject to the cell state, to replace the old one we’re forgetting. ” “Next, a tanh layer creates a vector of new candidate values, ~Ct, that could be added to the state. In the next step, we’ll combine these two to create an update to the state. ” http: //colah. github. io/posts/2015 -08 -Understanding-LSTMs/ RNN, LSTM v. 7. c 25 Andrew Ng
Second step (b): update the old cell state • Ct-1 Ct “We multiply the old state by ft, forgetting the things we decided to forget earlier. Then we add it ∗ ~Ct. This is the new candidate values, scaled by how much we decided to update each state value. ” http: //colah. github. io/posts/2015 -08 -Understanding-LSTMs/ “For the language model example. . this is where we’d actually drop the information about the old subject’s gender and add the new information, as we decided in the previous steps. ” RNN, LSTM v. 7. c 26 Andrew Ng
Third step: output layer • Decide what to output (ht). “Finally, we need to decide what we’re going to output. This output will be based on our cell state, but will be a filtered version. First, we run a sigmoid layer which decides what parts of the cell state we’re going to output. Then, we put the cell state through tanh (to push the values to be between − 1 and 1) and multiply it by the output of the sigmoid gate, so that we only output the parts we decided to. ” http: //colah. github. io/posts/2015 -08 -Understanding-LSTMs/ RNN, LSTM v. 7. c “For the language model example, since it just saw a subject, it might want to output information relevant to a verb, in case that’s what is coming next. For example, it might output whether the subject is singular or plural, so that we know what form a verb should be conjugated into if that’s what follows next. ” 27 Andrew Ng
X is of size nx 1 h is of size mx 1 http: //kvitajakub. github. io/2016/04/14/rnndiagrams/ • Ct(mx 1) Forget gate Ct-1(mx 1) ft(mx 1) i(mx 1) U(mx 1) o (mx 1) t ht(mx 1) ht-1(mx 1) X is of size nx 1 Size( Xt(nx 1) append ht-1(mx 1) )=(n+m)x 1 RNN, LSTM v. 7. c 28 Andrew Ng
Summary of the 7 LSTM equations • ()=sigmoid & tanh()=hyperbolic tangent are activation functions RNN, LSTM v. 7. c 29 Andrew Ng
LSTM Output gate This sigmoid This decides what info Controls what how Isdetermines to add to the cellmuch state goes into output information goes thru Ct-1 ht-1 Forget input gate The core idea is this cell Why sigmoid or tanh: state Ct, it is changed Sigmoid: 0, 1 gating as switch. slowly, with only minor Vanishing gradient problem in linear interactions. It is very LSTM is handled already. easy for information to flow Re. LU replaces tanh ok? along it unchanged. Andrew Ng
it decides what component is to be updated. C’t provides change contents Updating the cell state Decide what part of the cell state to output Andrew Ng
RNN vs LSTM Andrew Ng
Peephole LSTM Allows “peeping into the memory” Andrew Ng
Naïve RNN vs LSTM yt ht-1 Naïve RNN xt yt ct-1 ct LSTM ht ht ht-1 xt c changes slowly ct is ct-1 added by something h changes faster ht and ht-1 can be very different Andrew Ng
These 4 matrix computation should be done concurrently. W z xt ht-1 ct-1 zi Controls forget gate zf Controls Updating Controls input gate information Output gate zi z zf = σ( Wf ) ht-1 xt ) ht-1 zo zo = σ( ht-1 Wi xt xt Information flow of LSTM Wo xt ) ht-1 Andrew Ng
Element-wise multiply yt ct ct-1 ct = zf ct-1 + zi z tanh ht = zo tanh(ct) yt = σ(W’ ht) zf zi z ht-1 xt zo ht Information flow of LSTM Andrew Ng
LSTM information flow yt+1 yt ct+1 ct ct-1 tanh zf zi z tanh zo zf zi z zo ht+1 ht-1 xt ht Information flow of LSTM xt+1 Andrew Ng
GRU – gated recurrent unit LSTM (more compression) reset gate Update gate It combines the forget and input into a single update gate. It also merges the cell state and hidden state. This is simpler than LSTM. There are many other variants too. X, *: element-wise multiply Andrew Ng
GRUs also takes xt and ht-1 as inputs. They perform some calculations and then pass along ht. What makes them different from LSTMs is that GRUs don't need the cell layer to pass values along. The calculations within each iteration insure that the ht values being passed along either retain a high amount of old information or are jump-started with a high amount of new information. Andrew Ng
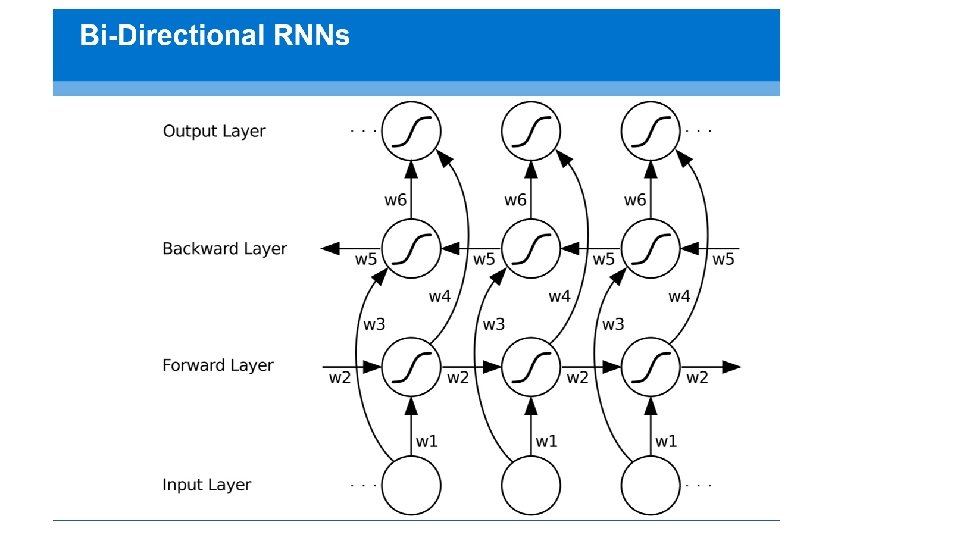
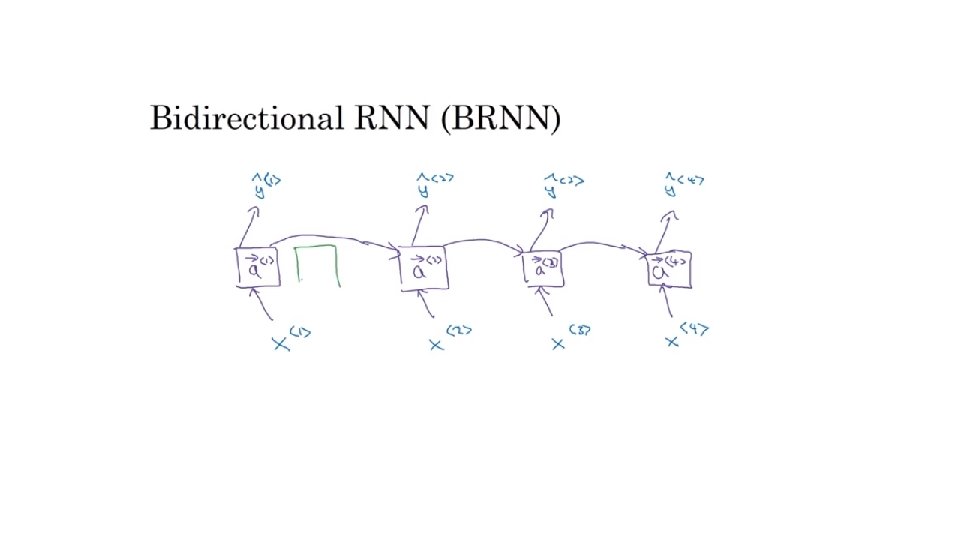
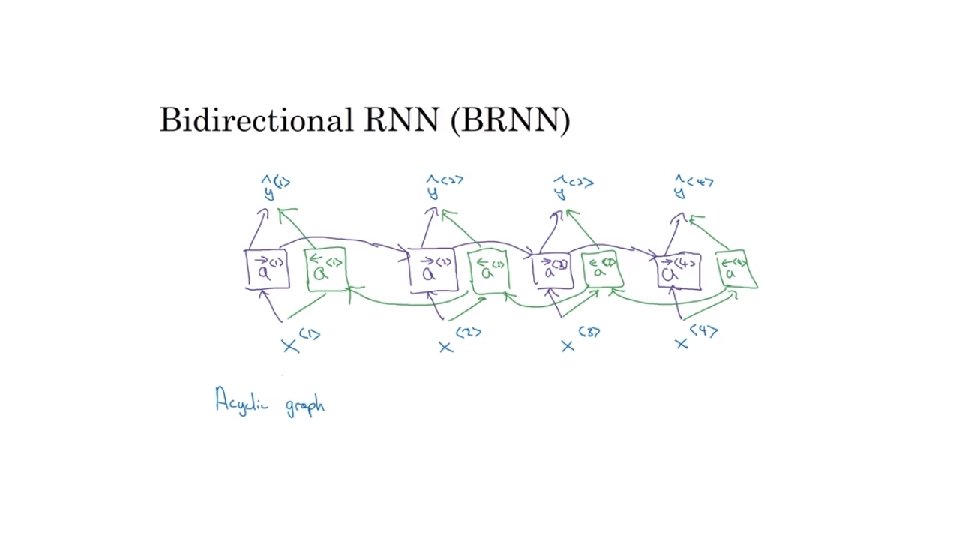
Recurrent Neural Networks deeplearning. ai Bidirectional RNN
Getting information from the future He said, “Teddy bears are on sale!” He said, “Teddy Roosevelt was a great President!” He said, “Teddy bears are on sale!” Andrew Ng
Bidirectional RNN (BRNN) Andrew Ng