Randomised Controlled Trials in the Social Sciences Cluster


















×ICC is usually quite small, 0. 04 is")


×ICC Clustering may have a large effect if")
×ICC Clustering may have a large effect if")


×ICC For the proposed design, the mean number")
























 The Design and Analysis of Group. Randomized Trials. Oxford,")



 ‘Randomisation by group: A formal")


 Can")

 Cycle helmet")













- Slides: 75
Randomised Controlled Trials in the Social Sciences Cluster randomised trials Martin Bland Professor of Health Statistics University of York www-users. york. ac. uk/~mb 55/
Cluster randomised trials Also called group randomised trials. Research subjects are not sampled independently, but in a group. For example: Ø all the patients in a general practice are allocated to the same intervention, the general practice forming a cluster, Ø all pupils in a school class are allocated to the same intervention, the class forming a cluster.
Members of a cluster will be more like one another than they are like members of other clusters.
Members of a cluster will be more like one another than they are like members of other clusters. We need to take this into account in the analysis and design.
Methods of analysis which ignore clustering: Ø two sample t method, Ø chisquared test for a two way table, Ø difference between two proportions, Ø relative risk, Ø analysis of covariance, Ø logistic regression.
Methods of analysis which ignore clustering: Ø two sample t method, Ø chisquared test for a two way table, Ø difference between two proportions, Ø relative risk, Ø analysis of covariance, Ø logistic regression. May mislead, because they assume that all subjects are independent observations.
Methods which ignore clustering may mislead, because they assume that all subjects are independent observations. Observations within the same cluster are correlated.
Methods which ignore clustering may mislead, because they assume that all subjects are independent observations. Observations within the same cluster are correlated. May lead to standard errors which are too small, confidence intervals which are too narrow, P values which are too small.
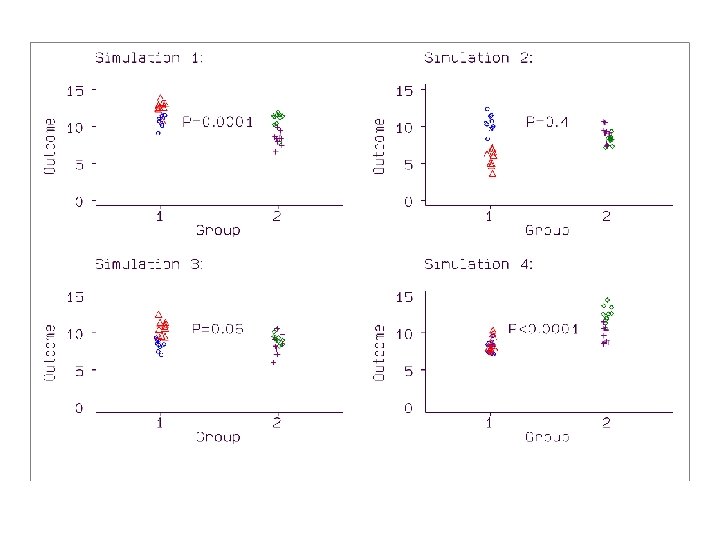
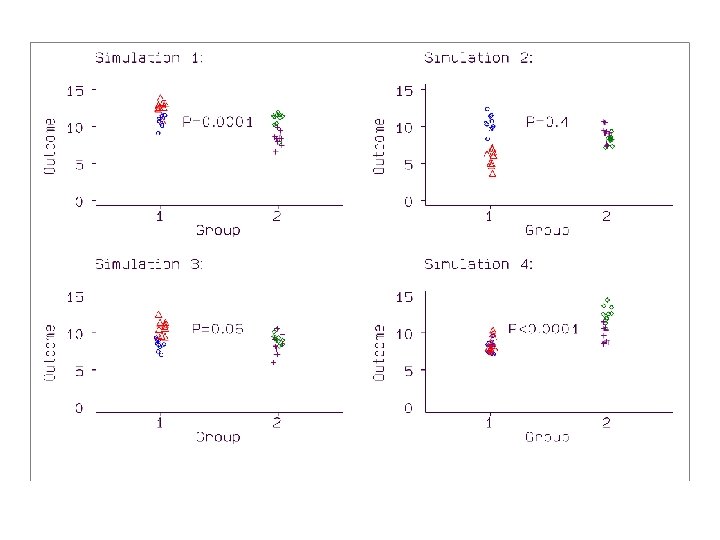
A little simulation Four cluster means, two in each group, from a Normal distribution with mean 10 and standard deviation 2. Generated 10 members of each cluster by adding a random number from a Normal distribution with mean zero and standard deviation 1. The null hypothesis, that there is no difference between the means in the two populations, is true. Two-sample t test comparing the means, ignoring the clustering.
1000 times: 600 significant differences, with P<0. 05 502 highly significant, with P<0. 01. If t test ignoring the clustering were valid, expect 50 significant differences, 5%, and 10 highly significant ones. The analysis assumes that we have 20 independent observations in each group. This is not true. We have two independent clusters of observations, but the observations in those clusters are really the same thing repeated ten times.
A valid statistical analysis. Possible analysis: • find the means for the four clusters • carry out a two-sample t test using these four means only. 1000 simulation runs: 53 (5. 3%) significant at P<0. 05 14 (1. 4%) highly significant at P<0. 01
Simulation is very extreme. Two groups of two clusters and a very large cluster effect. Have seen a proposed study with two groups of two clusters. Smaller cluster effect would only reduce the shrinking of the P values, it would not remove it. Simulation shows that spurious significant differences can occur if we ignore the clustering.
Example: GP Education Trial of General Practictioner education to improve treatment of asthma. Educate GPs in small groups, or not, and evaluate this education by giving repeated questionnaires to their asthmatic patients. Asked for my views on the sample size calculations.
Original: ignored the clustering and the GPs, and treated the design as a comparison of two groups of patients. Revised: produced a sample size calculation based primarily on the number of GPs, not patients.
The trial was funded and a research fellow, a GP, appointed. The cluster nature of the study was selfevident to me. It was not self-evident to the research fellow!
The trial was funded and a research fellow, a GP, appointed. The cluster nature of the study was selfevident to me. It was not self-evident to the research fellow! Many researchers find the importance of clustering very hard to understand.
The study appeared including the following description of the analysis: ‘For each general practitioner a score was calculated for each questionnaire item. Analysis of variance was then carried out for each questionnaire item to compare three groups. . . ’
How big is the effect of clustering? The design effect is what we must multiply the sample size for a trial which is not clustered, to achieve the same power. Alternatively, the power of a cluster randomised trial is the power of an individuall randomised trial of size divided by the design effect. Design effect: Deff = 1 + (m − 1)×ICC where m is the number of observations in a cluster and ICC is the intra-cluster correlation coefficient, the correlation between pairs of subjects chosen at random from the same cluster.
Deff = 1 + (m − 1)×ICC is usually quite small, 0. 04 is a typical figure. If m =1, cluster size one, no clustering, then Deff =1, otherwise Deff will exceed 1.
If we estimate the required sample size ignoring clustering, we must multiply it by the design effect to get the sample size required for the clustered sample. Alternatively, if the sample size is estimated ignoring the clustering, the clustered sample has the same power as for a simple sample of size equal to what we get if we divide our sample size by the design effect.
If we analyse the data as if there were no clusters, the variances of the estimates must be multiplied by Deff, hence the standard error must be multiplied by the square root of Deff.
Deff = 1 + (m − 1)×ICC Clustering may have a large effect if the ICC is large OR if the cluster size is large. E. g. , if ICC = 0. 001, cluster size = 500, the design effect will be 1 + (500 – 1) 0. 001 = 1. 5, Need to increase the sample size by 50% to achieve the same power as an unclustered trial.
Deff = 1 + (m − 1)×ICC Clustering may have a large effect if the ICC is large OR if the cluster size is large. E. g. , if ICC = 0. 001, cluster size = 500, the design effect will be 1 + (500 – 1) 0. 001 = 1. 5, Need to increase the sample size by 50% to achieve the same power as an unclustered trial. Need to estimate variances both within and between clusters. If the number of clusters is small, the between clusters variance will have few degrees of freedom and we will be using the t distribution in inference rather than the Normal. This too will cost in terms of power.
Example: a grant application An evaluation of a peer-led health education intervention. A comparison of two groups each of two clusters (counties) of about 750 people each.
Applicants were aware of the problem of cluster randomisation, but did not give any assessment of its likely impact on the power of the study, except to say that the intra-cluster correlation was "small", i. e. 0. 005 based on a US study.
Deff = 1 + (m − 1)×ICC For the proposed design, the mean number of subjects in a cluster was about 750, so Deff = 1 + 750 × 0. 005 = 4. 75 Thus the estimated sample size for any given comparison should be multiplied by 4. 75.
The estimated sample size for any given comparison should be multiplied by 4. 75. We have the same power as an individually randomised sample of 3000/4. 75 = 630
Degrees of freedom In large sample approximation sample size calculations, power 80% and alpha 5% are embodied in the multiplier (0. 85 + 1. 96)2 = 7. 90.
For a small sample calculation using the t test, 1. 96 must be replaced by the corresponding 5% point of the t distribution with the appropriate degrees of freedom. 2 degrees of freedom gives t = 4. 30. Hence the sample size multiplier is (0. 85 + 4. 30)2 = 26. 52 3. 36 times that for the large sample.
This will reduce the effective sample size even more, down to 630/3. 36 = 188. Thus the 3000 men in two groups of two clusters will give the same power to detect the same difference as 188 men randomised individually.
This will reduce the effective sample size even more, down to 630/3. 36 = 188. Thus the 3000 men in two groups of two clusters will give the same power to detect the same difference as 188 men randomised individually. This proposal came back with many more clusters.
Cluster size small, large number of clusters, small ICC: Design effect close to one. Little effect if the clustering is ignored. E. g. randomised controlled trial of the effects of coordinating care for terminally ill cancer patients (Addington-Hall et al. , 1992). 554 patients randomised by GP. About 200 GPs, so most clusters had only a few patients. Ignored the clustering.
Several approaches can be used to allow for clustering: Ø summary statistic for each cluster Ø adjust standard errors using the design effect Ø robust variance estimates Ø general estimating equation models (GEEs) Ø multilevel modeling Ø Bayesian hierarchical models Ø others
Several approaches can be used to allow for clustering: Ø summary statistic for each cluster Ø adjust standard errors using the design effect Ø robust variance estimates Ø general estimating equation models (GEEs) Ø multilevel modeling Ø Bayesian hierarchical models Ø others Any method which takes into account the clustering will be a vast improvement compared to methods which do not.
A refereeing case study Paper sent in 1997 by the BMJ. Study of the impact of a specialist outreach team on the quality of nursing and residential home care.
Intervention carried out at the residential home level. Eligible homes were put into matched pairs and one of each pair randomised to intervention. Thus the randomisation was clustered.
The randomisation was clustered. Intervention was applied to the care staff, not to the patients. The residents in the home were used to monitor the effect of the intervention on the staff.
Clustering was totally ignored in the analysis.
Clustering was totally ignored in the analysis. Used the patient as the unit of analysis.
Clustering was totally ignored in the analysis. Used the patient as the unit of analysis. Carried out a Mann-Whitney test of the scores between the two groups at baseline. This was not significant.
Clustering was totally ignored in the analysis. Used the patient as the unit of analysis. Carried out a Mann-Whitney test of the scores between the two groups at baseline. This was not significant. Mann-Whitney test at follow-up, completely ignoring the baseline measurements.
Clustering was totally ignored in the analysis. Used the patient as the unit of analysis. Carried out a Mann-Whitney test of the scores between the two groups at baseline. This was not significant. Mann-Whitney test at follow-up, completely ignoring the baseline measurements. Wilcoxon matched pairs test for each group separately and found that one was significant and the other not.
Possible approaches Summary statistic for the home, e. g. the mean change in score. These could then be compared using a t method. As the homes were randomised within pairs, I suggested the paired t method. (This may not be right, as the matching variables may not be informative and the loss of degrees of freedom may be a problem. ) The results should be given as a difference in mean change, with a confidence interval as recommended in the BMJ’s guide-lines to authors, rather than as a P value. Alternative: fit a multi-level model, with homes as one level of variability, subjects another, and variation within subjects a third. A job for a professional statistician.
What happened next? The paper was rejected.
What happened next? The paper was rejected. Study reported in the Lancet!
What happened next? The paper was rejected. Study reported in the Lancet! Extra author, a well-known medical statistician. ‘The unit of randomisation in the study was the residential home and not the resident. Thus, all data were analysed by use of general estimated equation models to adjust for clustering effects within homes. . Clinical data are presented as means with 95% CIs calculated with Huber variance estimates. ’.
I looked for the acknowledgement to an unknown referee, in vain.
Reviews of published trials There have been several reviews of published cluster randomised trials in medical applications.
Some reviews of published cluster randomised trials Authors Source Years Clustering allowed for in sample size Clustering allowed for in analysis Donner et al. 16 non-therapeutic (1990) intervention trials 1979 – 1989 <20% <50% Simpson et al. (1995) 1990 – 1993 19% 57% Isaakidis and 51 trials in Sub-Saharan Ioannidis Africa (2003) 1973 – 20% 2001 (half post 1995) 37% Puffer et al. (2003) 1997 – 2002 56% 92% Eldridge et al. 152 trials in primary health 1997 (in press care 2000 2003) 20% 59% 21 trials from American Journal of Public Health and Preventive Medicine 36 trials in British Medical Journal, Lancet, and New England Journal of Medicine
Importance for the evidence base Incorrect analyses may produce false conclusions. Sample sizes may be too small.
Key references Murray DM. (1998) The Design and Analysis of Group. Randomized Trials. Oxford, University Press. Donner A, Klar N. (2000) Design and Analysis of Cluster Randomised Trials in Health Research. London, Arnold. Many papers by Alan Donner and colleagues. Campbell MK, Elbourne DR, Altman DG for the CONSORT Group. The CONSORT statement: extension to cluster randomised trials. Submitted for publication. Bland JM, Kerry SM, Altman DG. Statistics Notes series in British Medical Journal, numbers 29 -34 – www. york-users. ac. uk/~mb 55
Publications on cluster designs How-to-do-it papers. Statistics notes in the BMJ. Articles in GP journals. Special editions of Statistical Methods in Medical Research and Statistics in Medicine. Papers reporting intraclass correlation coefficients to help others to design clustered studies.
Web of Knowledge search on: randomi* in clusters OR cluster randomi*
This is not a thorough search and will have missed many studies. 2001 includes special issues of Statistics in Medicine and Statistical Methods in Medical Research on cluster randomisation. Ignores papers using clusters in observational studies.
Ignores other terms e. g. ‘group randomised’. Cornfield (1978) ‘Randomisation by group: A formal analysis’ includes the following: ‘Randomization by cluster accompanied by an analysis appropriate to randomization by individual is an exercise in self-deception, however, and should be discouraged. ’ Murray (1998). The Design and Analysis of Group. Randomized Trials. Oxford, University Press.
Are any of these trials “social science”? van der Molen HF, Sluiter JK, Hulshof CTJ, Vink, P, van Duivenbooden, C, Holman, R, Frings-Dresen, MHW. TI Implementation of participatory ergonomics intervention in construction companies. Scandinavian Journal of Work Environment & Health 31, 191 -204. Study objective: The effectiveness of the implementation of participatory ergonomics intervention to reduce physical work demands in construction work was studied.
Are any of these trials “social science”? Shemilt I, Harvey I, Shepstone L, Swift L, Reading R, Mugford M, Belderson P, Norris N, Thoburn J, Robinson J. (2004) A national evaluation of school breakfast clubs: evidence from a cluster randomized controlled trial and an observational analysis. Child Care Health and Development 30, 413 -427. Study objective: To measure the health, educational and social impacts of breakfast club provision in schools serving deprived areas across England. Also Shemilt, I, Mugford M, Moffatt P, Harvey I, Reading R, Shepstone L, Belderson P. (2004) A national evaluation of school breakfast clubs: where does economics fit in? Child Care Health and Development 30, 429 -437.
Are any of these trials “social science”? Strang J, Mc. Cambridge J. (2004) Can the practitioner correctly predict outcome in motivational interviewing? Journal of Substance Abuse Treatment 27. 83 - 88, Study objective: We have examined whether practitioner ratings (immediately post-intervention) or other recorded characteristics of a single-session 1 -hour motivational intervention were predictive of 3 -month cannabis use outcome.
Are any of these trials “social science”? Stephenson JM, Strange V, Forrest S, Oakley A, Copas A, Allen E, Babiker A, Black S, Ali M, Monteiro H, Johnson AM. . (2004) Pupil-led sex education in England (RIPPLE study): cluster-randomised intervention trial. Lancet 364, 338 -346. Study objective: Improvement of sex education in schools is a key part of the UK government's strategy to reduce teenage pregnancy in England. We examined the effectiveness of one form of peer-led sex education in a school-based randomised trial of over 8000 pupils.
Are any of these trials “social science”? Kendrick D, Royal S (2004) Cycle helmet ownership and use; a cluster randomised controlled trial in primary school children in deprived areas. Archives of Disease in Childhood VL 89, 330 -335. Study objective: To assess the effectiveness of two different educational interventions plus free cycle helmets, in increasing cycle helmet ownership and use.
Conclusions • The effects of clustering can be large, inflating Type I errors.
Conclusions • The effects of clustering can be large, inflating Type I errors. • This may not be obvious to researchers, even to statisticians.
Conclusions • The effects of clustering can be large, inflating Type I errors. • This may not be obvious to researchers, even to statisticians. (Quandoque bonus dormitat Homerus)
Conclusions • The effects of clustering can be large, inflating Type I errors. • This may not be obvious to researchers, even to statisticians. (Quandoque bonus dormitat Homerus) (Even the worthy Homer sometimes nods)
Conclusions • The effects of clustering can be large, inflating Type I errors. • This may not be obvious to researchers, even to statisticians. (Quandoque bonus dormitat Homerus) (Even the worthy Homer sometimes nods) (Even the greatest get it wrong).
Conclusions • The effects of clustering can be large, inflating Type I errors. • This may not be obvious to researchers, even to statisticians. • There are many ways to allow for clustering.
Conclusions • The effects of clustering can be large, inflating Type I errors. • This may not be obvious to researchers, even to statisticians. • There are many ways to allow for clustering. • The number of cluster randomised trials published has increased greatly.
Conclusions • The effects of clustering can be large, inflating Type I errors. • This may not be obvious to researchers, even to statisticians. • There are many ways to allow for clustering. • The number of cluster randomised trials published has increased greatly. • The effects of clustering have often been ignored.
Conclusions • The effects of clustering can be large, inflating Type I errors. • This may not be obvious to researchers, even to statisticians. • There are many ways to allow for clustering. • The number of cluster randomised trials published has increased greatly. • The effects of clustering have often been ignored. • The situation has improved.
Recommendations • Keep up the pressure.
Recommendations • Keep up the pressure. • Extend to specialist journals.
Recommendations • Keep up the pressure. • Extend to specialist journals.
Randomised Controlled Trials in the Social Sciences Cluster randomised trials Martin Bland Professor of Health Statistics University of York www-users. york. ac. uk/~mb 55/