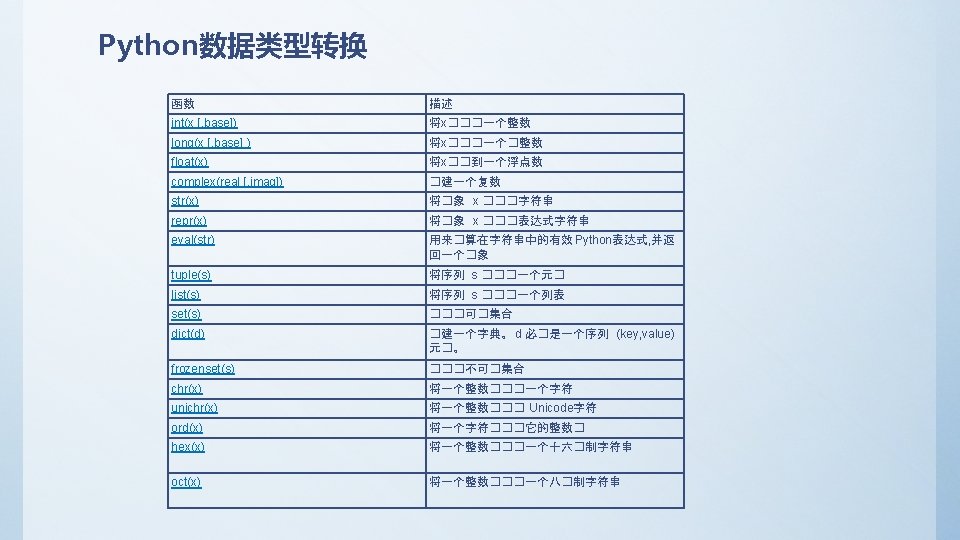
Pycharm Python Python Python and exec not assert








































 np. array( x, dtype) 将�入数据�化�一个 ndarray 将�入数据�化�一个�型� type的ndarray np.")

 np. subtract(ndarray, ndarray) np. multiply(ndarray, ndarray) np. divide(ndarray, ndarray)")
![文件�写 �明 np. save(string, ndarray) 将ndarray保存到文件名� [string]. npy 的文件中(无��) np. savez(string, ndarray 1, ndarray](https://slidetodoc.com/presentation_image_h2/d667d335121240c6b3ed8678b7b6aff9/image-48.jpg "文件�写 �明 np. save(string, ndarray) 将ndarray保存到文件名� [string]. npy 的文件中(无��) np. savez(string, ndarray 1, ndarray")



 df. describe() df. min() df. idxmax(axis=0, skipna=True) df. idxmin(axis=0, skipna=True)")











![2、分析乘客存活率与各单变量之间的关系 – 查看总存活率 survived_rate = float(df['Survived']. sum()) / df['Survived']. count() Print(‘survived_rate: ', survived_rate) –](https://slidetodoc.com/presentation_image_h2/d667d335121240c6b3ed8678b7b6aff9/image-71.jpg "2、分析乘客存活率与各单变量之间的关系 – 查看总存活率 survived_rate = float(df['Survived']. sum()) / df['Survived']. count() Print(‘survived_rate: ', survived_rate) –")





- Slides: 85
Pycharm软件界面
• Python 保留字符 下面的列表显示了在Python中的保留字。这些保留字不能用作常数或变数,或任何 其他标识符名称。所有 Python 的关键字只包含小写字母。 and exec not assert finally or break for pass class from print continue global raise def if return del import try elif in while else is with except lambda yield
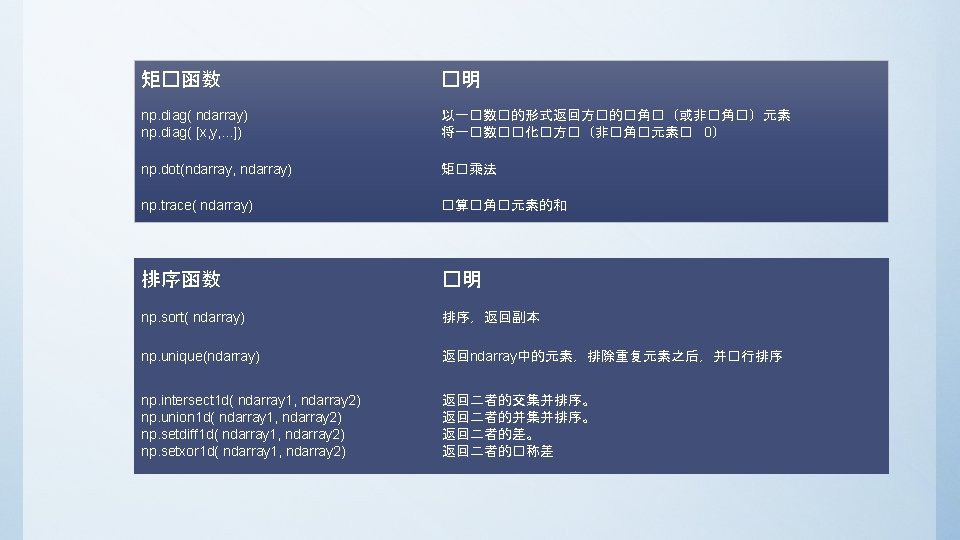
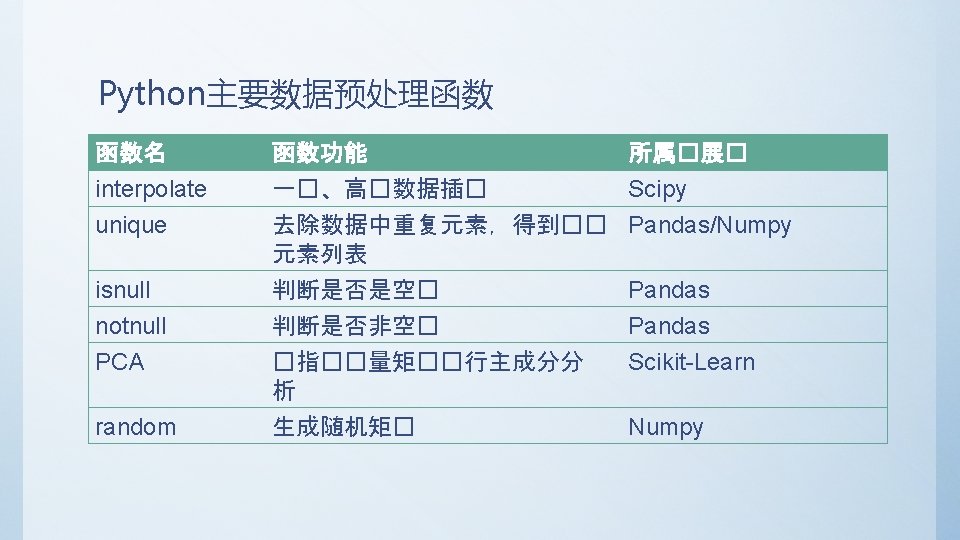
生成函数 作用 np. array( x) np. array( x, dtype) 将�入数据�化�一个 ndarray 将�入数据�化�一个�型� type的ndarray np. asarray( array ) 将�入数据�化�一个新的( copy)ndarray np. ones( N ) np. ones( N, dtype) np. ones_like( ndarray ) 生成一个N�度的一�全一 ndarray 生成一个N�度�型是 dtype的一�全一 ndarray 生成一个形状与参数相同的全一ndarray np. zeros( N) np. zeros( N, dtype) np. zeros_like(ndarray) 生成一个N�度的一�全零 ndarray 生成一个N�度�型位 dtype的一�全零 ndarray �似 np. ones_like( ndarray ) np. empty( N, dtype) np. empty(ndarray) 生成一个N�度的未初始化一� ndarray 生成一个N�度�型是 dtype的未初始化一� ndarray �似 np. ones_like( ndarray ) np. eye( N ) np. identity( N ) �建一个 N * N的�位矩�(�角�� 1,其余� 0) np. arange( num) np. arange( begin, end, step) 生成一个从0到num-1步数� 1的一� ndarray 生成一个从begin到end-step的步数� step的一� ndarray np. in 1 d(ndarray, [x, y, . . . ]) �� ndarray中的元素是否等于[x, y, . . . ]中的一个,返回bool数�
多元�算函数 �明 np. add(ndarray, ndarray) np. subtract(ndarray, ndarray) np. multiply(ndarray, ndarray) np. divide(ndarray, ndarray) np. floor_divide(ndarray, ndarray) np. power(ndarray, ndarray) np. mod(ndarray, ndarray) np. maximum(ndarray, ndarray) np. fmax(ndarray, ndarray) np. minimun(ndarray, ndarray) np. fmin(ndarray, ndarray) np. copysign(ndarray, ndarray) np. greater_equal(ndarray, ndarray) np. less_equal(ndarray, ndarray) np. not_equal(ndarray, ndarray) logical_and(ndarray, ndarray) logical_or(ndarray, ndarray) logical_xor(ndarray, ndarray) np. dot( ndarray, ndarray) 相加 相减 乘法 除法 �整除法(�弃余数) 次方 求模 求最大�(忽略 Na. N) 求最小�(忽略 Na. N) 将参数 2中的符号�予参数 1 > >= < <= == != & | ^ �算两个 ndarray的矩�内� np. ix_([x, y, m, n], . . . ) 生成一个索引器,用于Fancy indexing(花式索引)
文件�写 �明 np. save(string, ndarray) 将ndarray保存到文件名� [string]. npy 的文件中(无��) np. savez(string, ndarray 1, ndarray 2, . . . ) 将所有的ndarray��保存到文件名� [string]. npy的文件中 np. savetxt(sring, ndarray, fmt, newline='n') 将ndarray写入文件,格式� fmt np. load(string) �取文件名 string的文件内容并�化� ndarray�象(或字 典�象) np. loadtxt(string, delimiter) �取文件名 string的文件内容,以delimiter�分隔符�化� ndarray
����函数 �明 df. count() df. describe() df. min() df. idxmax(axis=0, skipna=True) df. idxmin(axis=0, skipna=True) df. quantile(axis=0) 非Na. N的数量 一次性�生多个���� 最小� 最大� 返回含有最大�的 index的Series 返回含有最小�的 index的Series �算�本的分位数 df. sum(axis=0, skipna=True, level=Na. N) df. mean(axis=0, skipna=True, level=Na. N) df. median(axis=0, skipna=True, level=Na. N) df. mad(axis=0, skipna=True, level=Na. N) df. var(axis=0, skipna=True, level=Na. N) df. std(axis=0, skipna=True, level=Na. N) df. skew(axis=0, skipna=True, level=Na. N) df. kurt(axis=0, skipna=True, level=Na. N) df. cumsum(axis=0, skipna=True, level=Na. N) df. cummin(axis=0, skipna=True, level=Na. N) df. cummax(axis=0, skipna=True, level=Na. N) df. cumprod(axis=0, skipna=True, level=Na. N) df. diff(axis=0) df. pct_change(axis=0) 返回一个含有求和小�的 Series 返回一个含有平均�的 Series 返回一个含有算�中位数的 Series 返回一个根据平均��算平均��离差的 Series 返回一个方差的Series 返回一个�准差的 Series 返回�本�的偏度(三�距) 返回�本�的峰度(四�距) 返回�本的累�和 返回�本的累�最大� 返回�本的累�最小� 返回�本的累�� 返回�本的一�差分 返回�本的百分比数�化
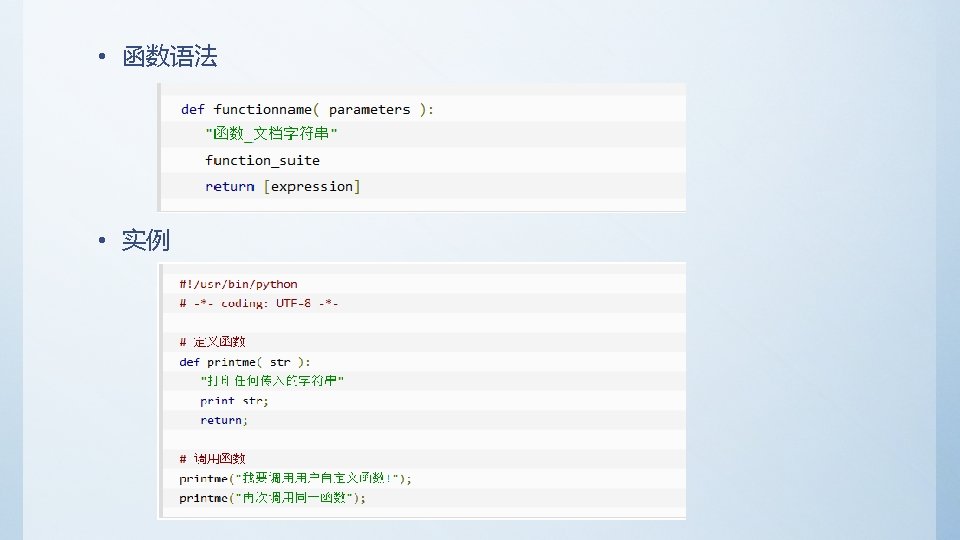
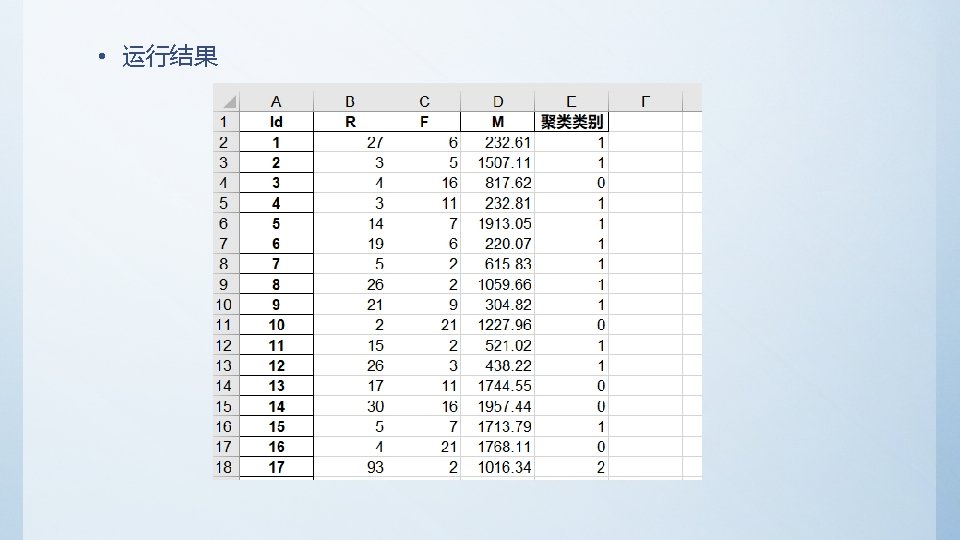
• Python代码
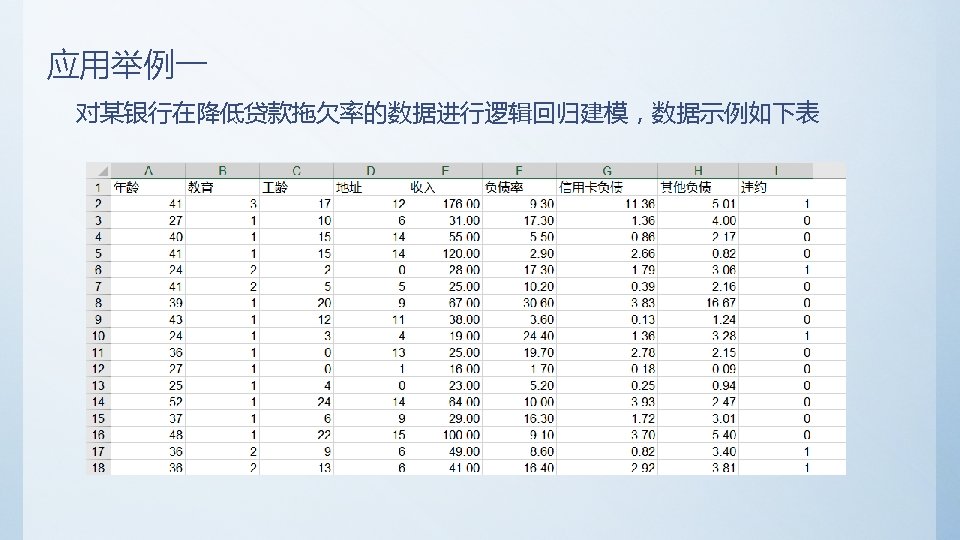
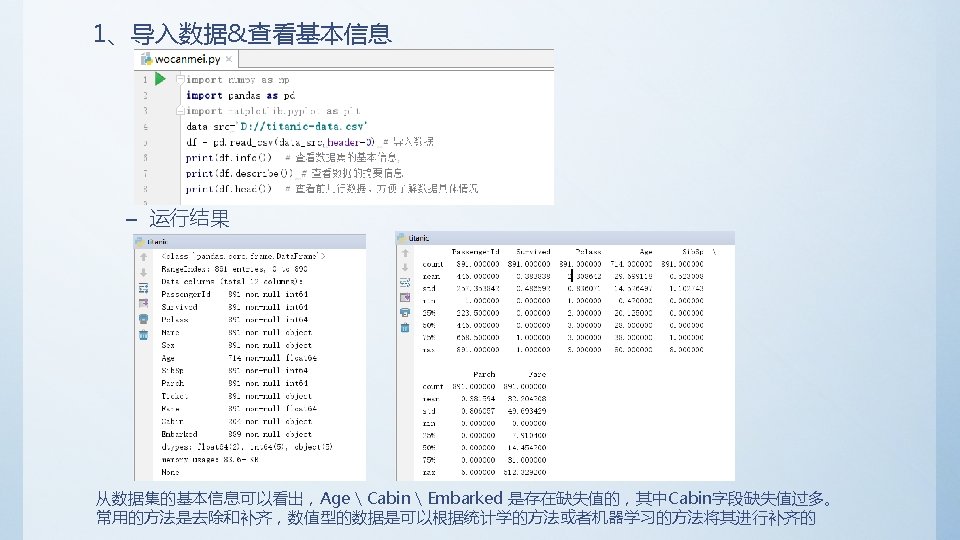
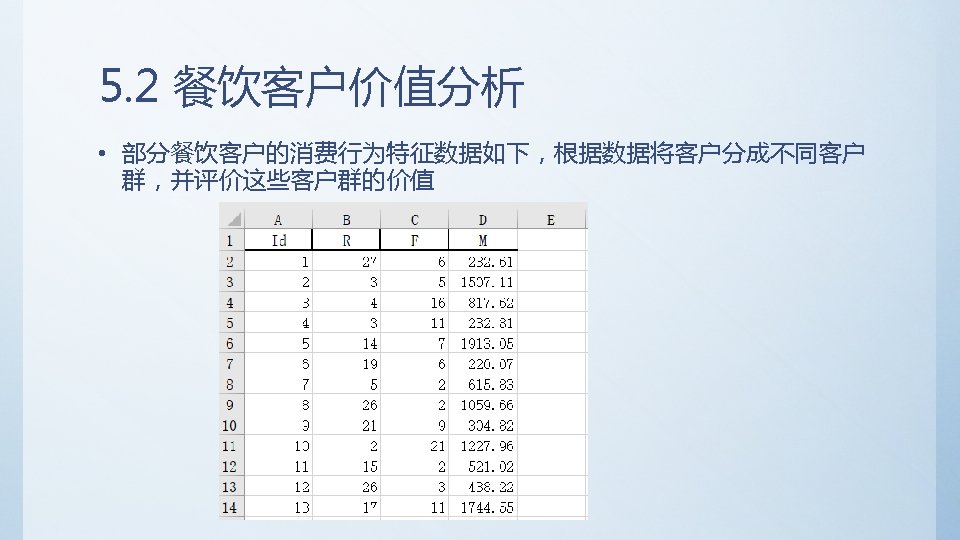
5. 1 Titanic数据集分析 • 前期准备 – 数据下载 https: //d 17 h 27 t 6 h 515 a 5. cloudfront. net/topher/2016/December/584 bcec 3_ titanic-data/titanic-data. csv – 软件准备 python 3. 6+ anaconda 或 使用集成开发环境 pycharm • 数据格式 Passenger. Id => 乘客ID Survived => 是否生还 Pclass => 乘客等级(1/2/3等舱 位) Name => 乘客姓名 Sex => 性别 Age => 年龄 Sib. Sp => 堂兄弟/妹个数 Parch => 父母与小孩个数 Ticket => 船票信息 Fare => 票价 Cabin => 客舱 Embarked => 登船港口
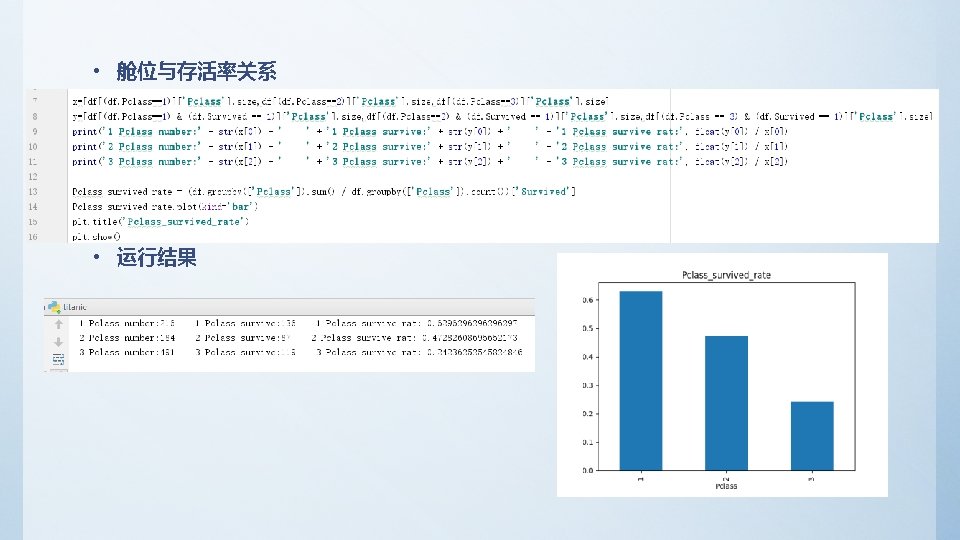
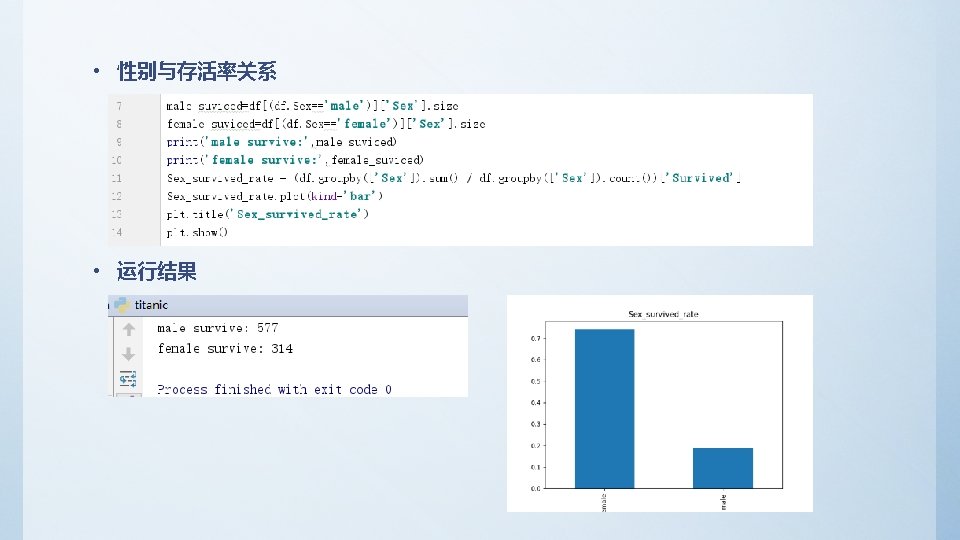
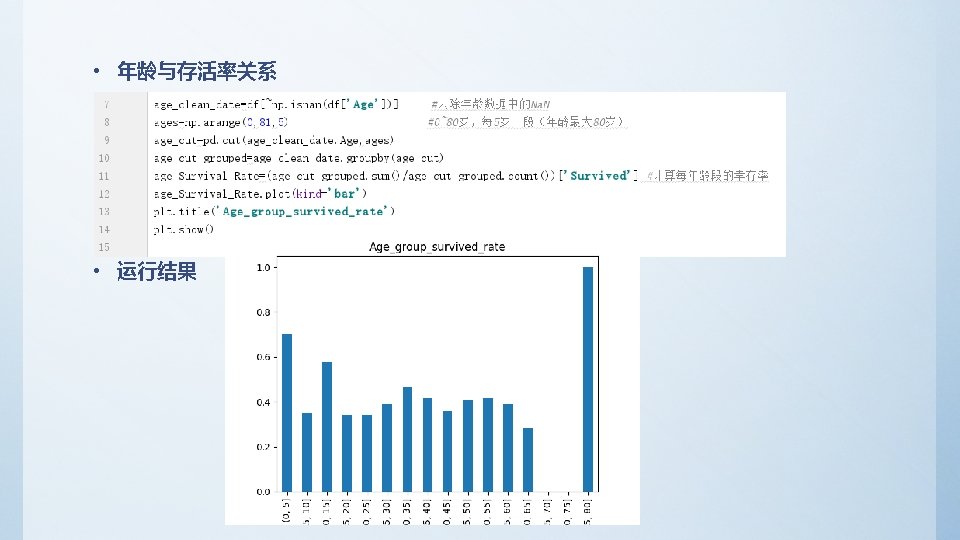
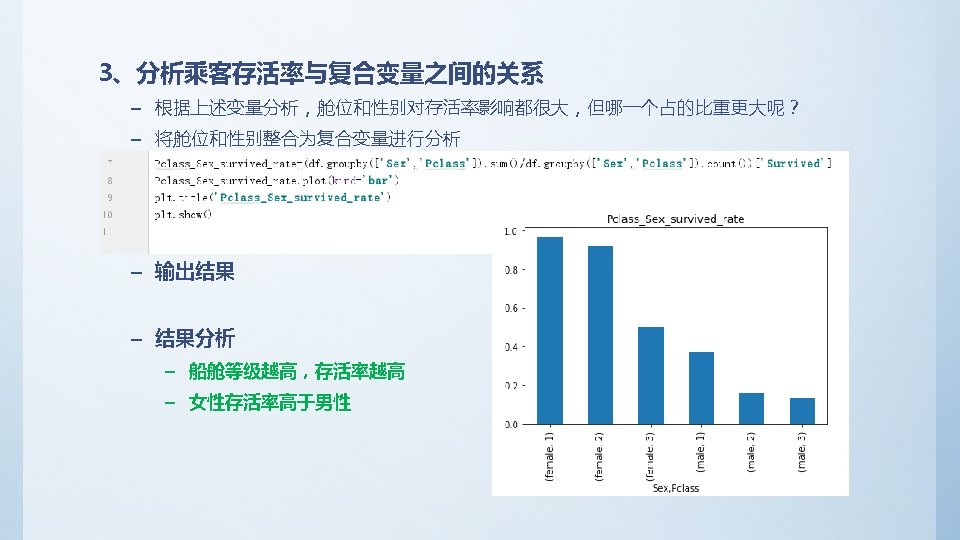
2、分析乘客存活率与各单变量之间的关系 – 查看总存活率 survived_rate = float(df['Survived']. sum()) / df['Survived']. count() Print(‘survived_rate: ', survived_rate) – 输出结果 survived_rate: 0. 383838
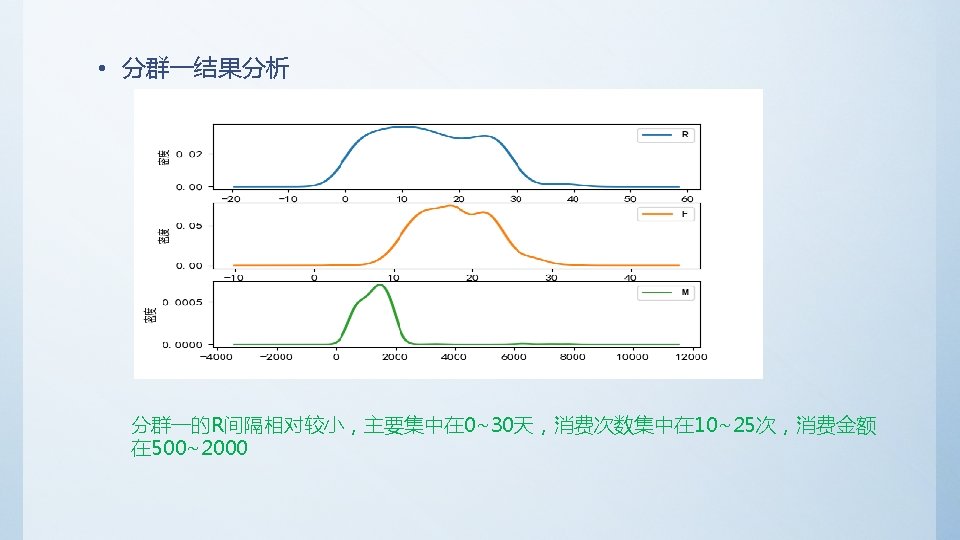
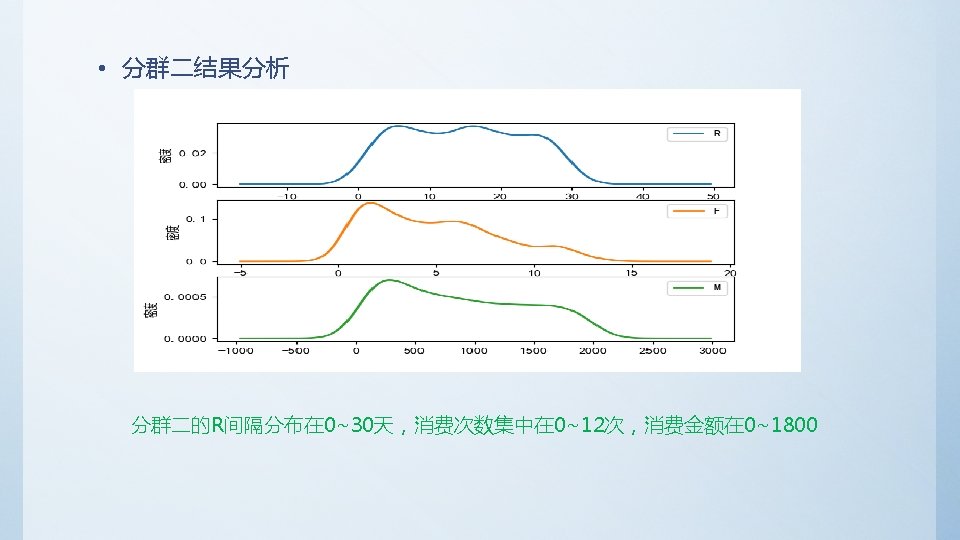
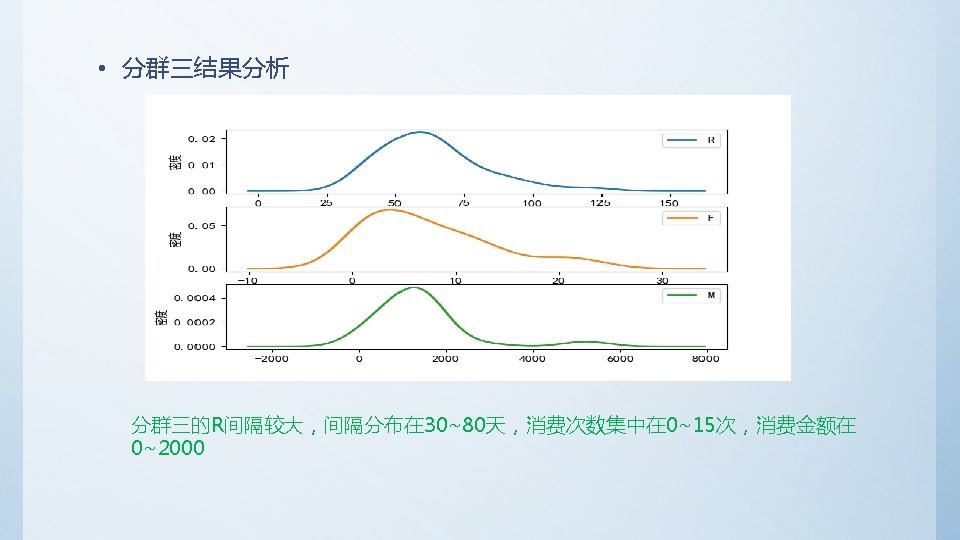
• Python代码
演示结束! 感谢聆听! THANK YOU FOR WATCHING!