Project C Sage Infrastructure Tools Project Carole Goble

Project C Sage Infrastructure Tools Project • Carole Goble, University of Manchester, UK • Ted Liefeld, Broad Institute • Alex Pico, Gladstone Institutes • Marc Hadfield, Alitora

Tools Afternoon Session • Review of developments to date – – – Creating Semantic Model for Sage Networks Storing Sage Networks with Alitora for Search & Visualization Performing Key Driver Analysis with Gene. Pattern Taverna workflow for annotating and analyzing the network model Working with Sage Networks in Cytoscape • Other network model tools – Additional tool providers discuss integrating with Sage • Looking forward – open questions and gaps – breakout sessions

Project Workstream C: Tools Raw Datasets Annotated & Standardized Network Inference Infrastructure Tools Access & Analysis

Core principles 1. Maximize access 2. Maximize use 3. Maximize reuse ü Distribute multiple file formats ü Make use of existing standards and tools ü Design for flexible, extensible solutions ü Support collaboration and community annotation

The SAGE Pipeline FORMAT Re-integrate Visualisation Network Data R-Script Data Re-integrate FORMAT Cytoscape Visualisation
 2. Direct Download:")
Session for Project C: Tools 1. Sage Semantic Ontology (Data Model) 2. Direct Download: just give me the data 3. Search and Browse: web interface 4. Interactive Analysis: extensible workflows A. Gene Pattern Workflow B. Taverna Workflow C. Cytoscape Workflow 5. Related Tools: related communities A. SCF/SWAN –Tim Clark B. Bio 2 RDF – Michel Dumontier
 Standard triple: base unit of “meaning”…")
RDF (Semantic) Standard triple: base unit of “meaning”…

Semantic Linked. Data
")
Sage Ontology (OWL)

Tools and Semantics

Tools and Linked. Data

Direct Download 1. Go to http: //sagebase. org/commons 2. Access standardized datasets and networks contributed to Sage Commons 3. Download networks as: A. Formatted text files (. tab) B. Simple interaction files (. sif) C. Cytoscape session files (. cys) D. Semantic OWL files (. owl)

Repository of Sage Networks Web App Plug Ins Alitora’s Semantic Repository

Repository of Semantic Data Copyright Alitora Systems, Inc. 2009

Semantic Repository Graph Database Designed for network storage & query Scalable to billions of data objects Federated Cloud-deployable Web-scale Indexing 1 billion RDF triples/hour 1000 QPS/CPU: “semantic select” Clustering Algorithms in graph elements Queries can focus on relevant Cluster(s) Typical Query is 1 -to-1 to relevant Cluster Worst case query performance is inverted index As per semantic queries, there are no “joins” Full Pathway Queries

Knowledge Relevancy Algorithms help determine which knowledge is important across billions of facts. Sage “KDA” is an example of an algorithm to find important “nodes” in the networks. Relevancy can be based on Graph Topology

Collaborative Interface

Sage. Commons Web Demo

Search and Browse 1. Go to http: //saas. alitora. com/sagedemo/ 2. Access web interface to semantic database A. Anonymous access B. Login to store and share findings C. Identify networks for download, visualization and workflows
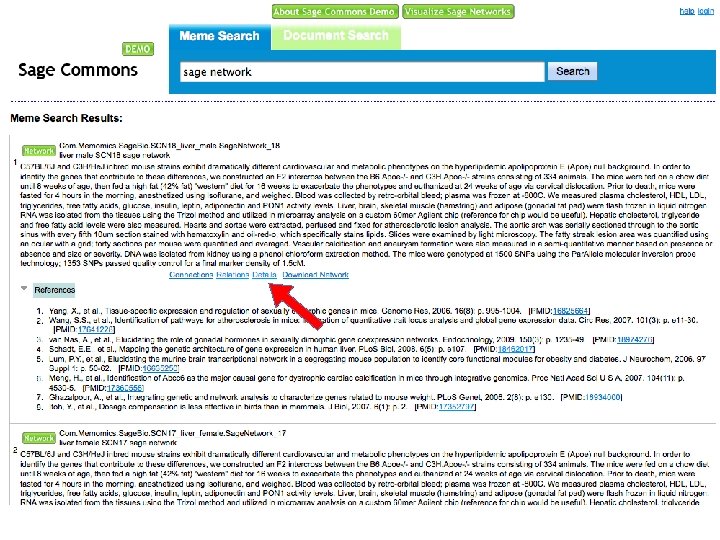
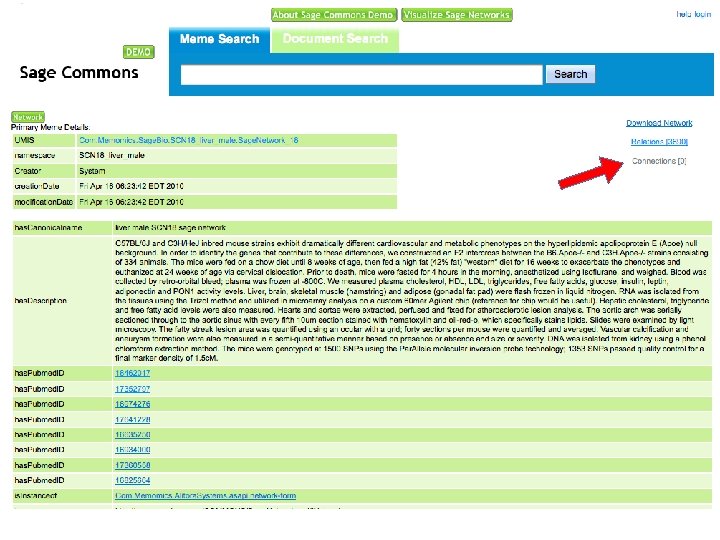
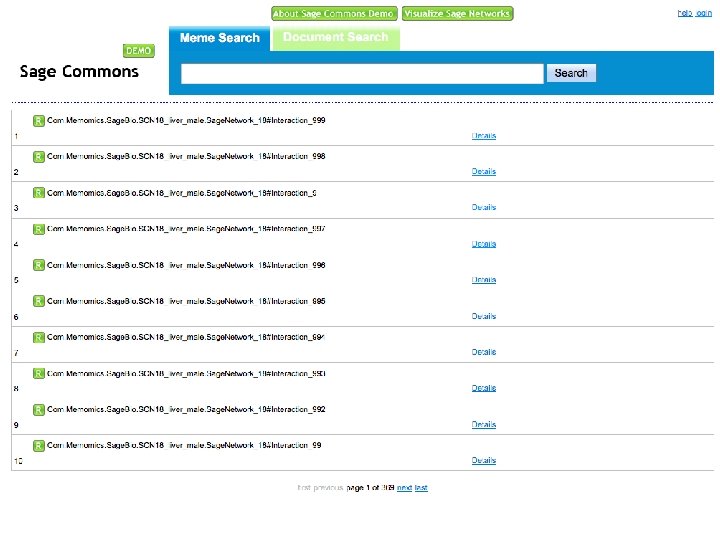
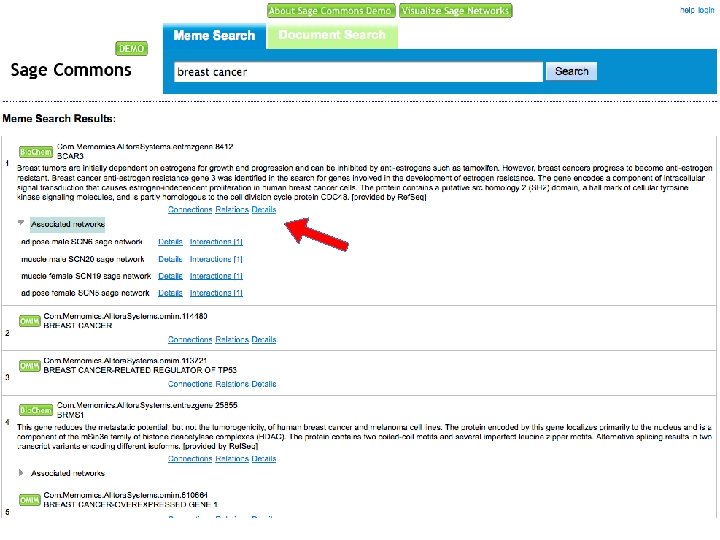
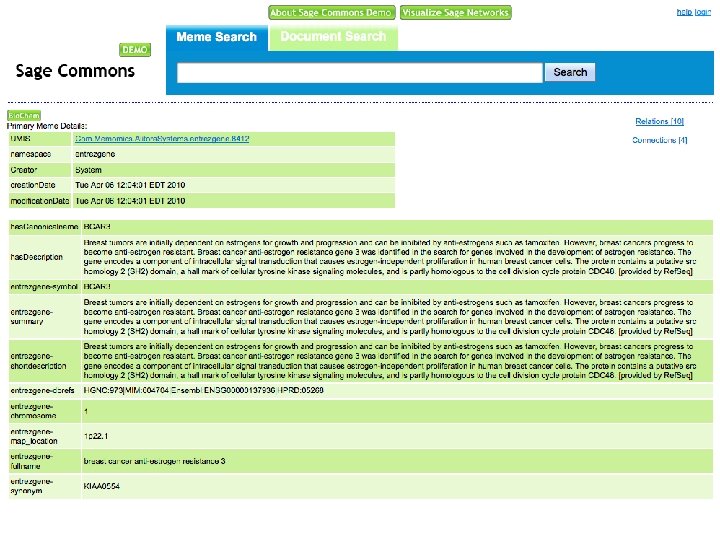
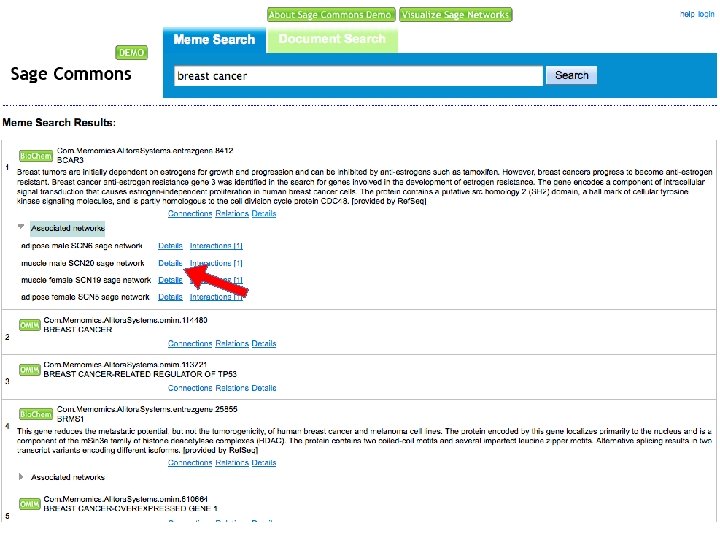
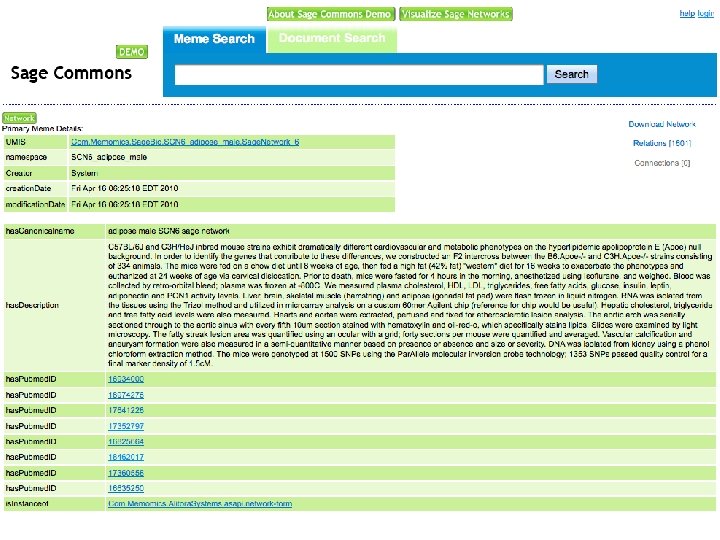
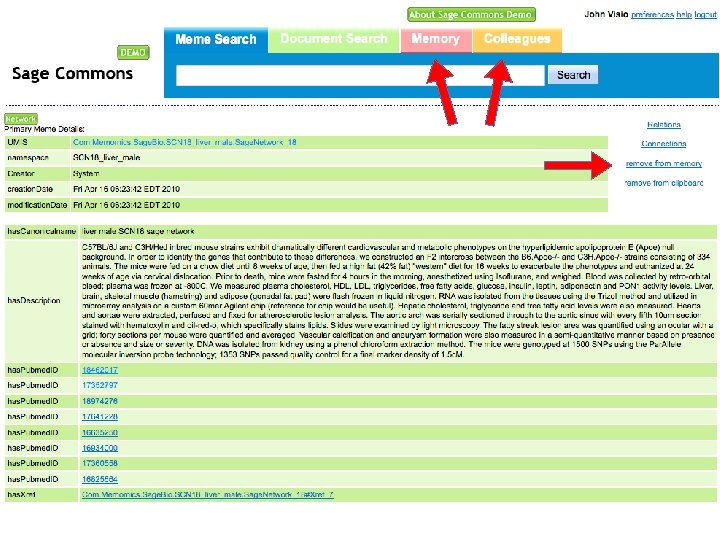

Sage Commons Demo Open API Web interface Cytoscape plugin

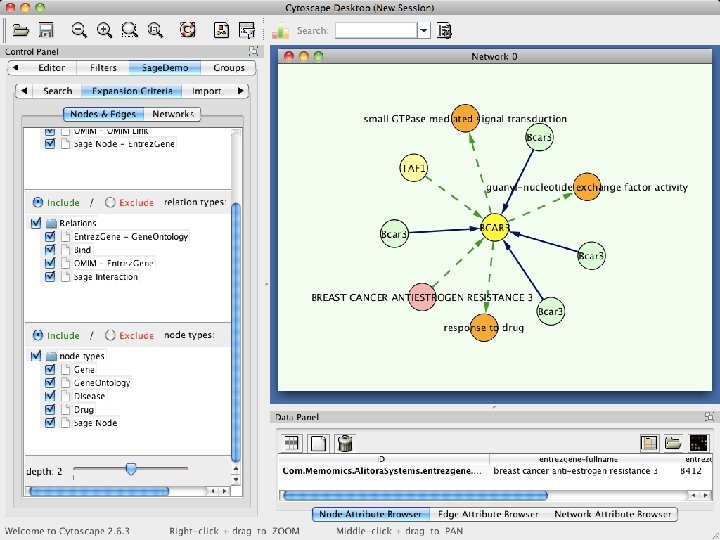
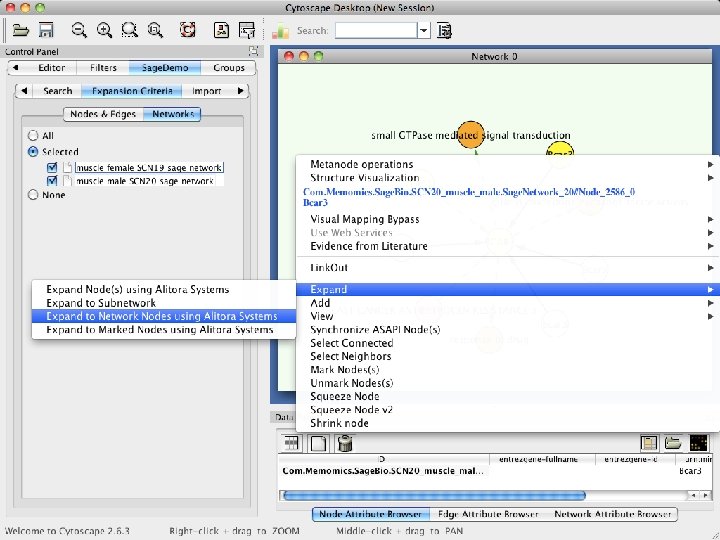
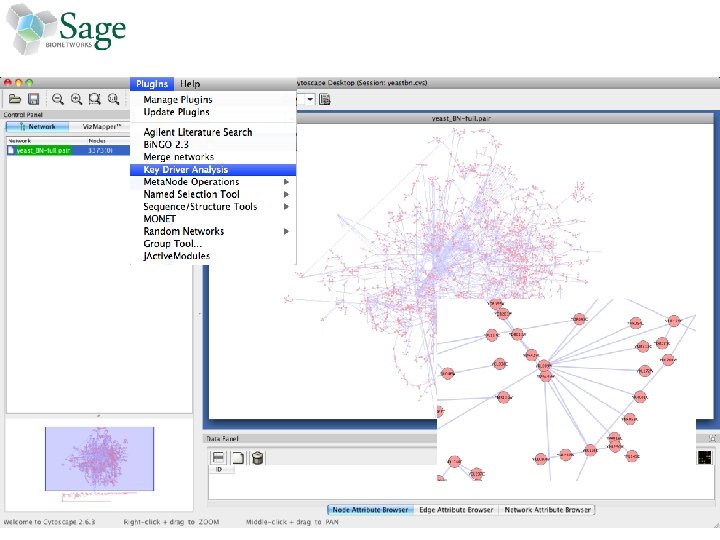
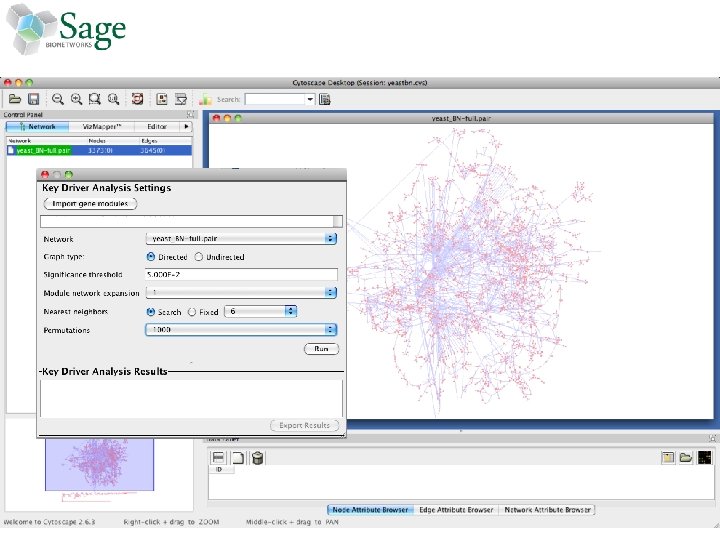
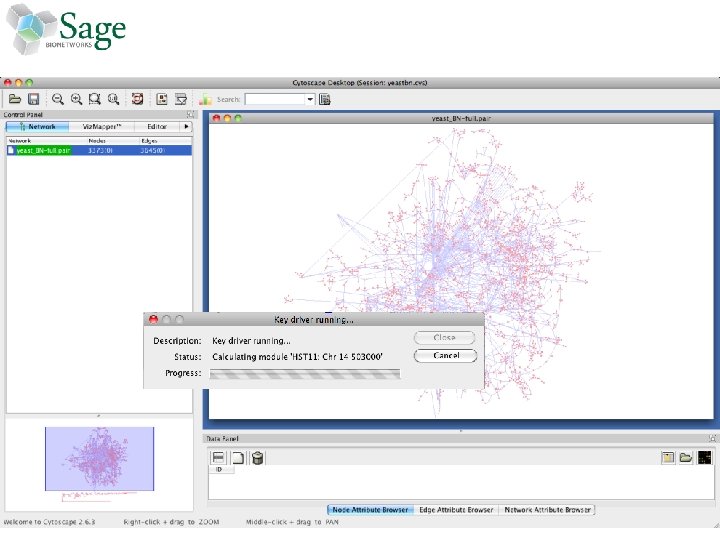
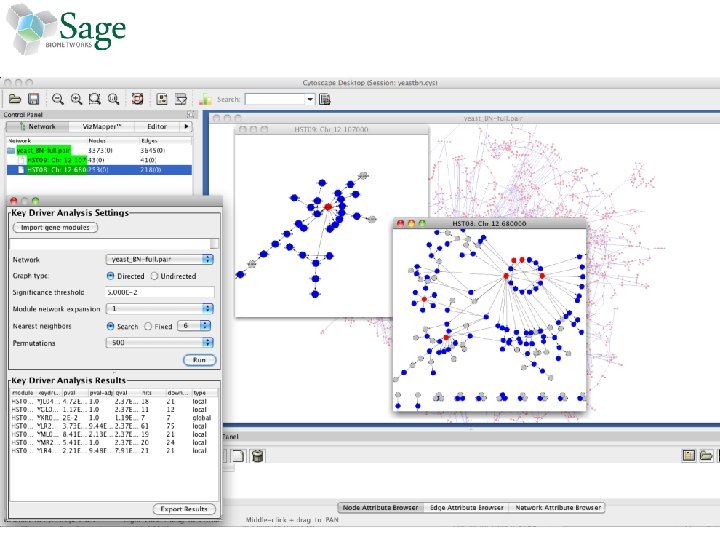
Interactive Analysis Extensible workflows direct Sage Commons networks through customizable pipelines for analysis and visualization 1. Access semantic database of networked data 2. Perform Key Driver Analysis (KDA) 3. Write results back to database 4. Visualize network and results in Cytoscape

Gene. Pattern Workflow

An integrative genomics analysis platform with • Comprehensive repository of tools • Construction of flexible, reproducible analysis workflows • Ability to add new tools easily • Interface accessible to many levels of user • Configurable to available compute resources www. genepattern. org

Gene. Pattern: A platform for integrative genomics Module Repository KNN PCA GISTIC GSEA SVM NMF FLAME CBS Module Integrator Pipeline Environment all_aml_train Preprocess Client User Interfaces all_aml_test Preprocess SOM Clustering Class Neighbors Weighted Voting Cross-Val SOM Cluster Viewer Marker Selection Viewer Prediction Results Viewer Weighted Voting Train/Test Visualizer Prediction Results Viewer Golub and Slonim et. al 1999 Web Programming

Gene. Pattern Software Release Information n Originally released 2004 n Current version 3. 2. 1, released November 2009 n Currently 12, 000+ users, 500+ organizations, ~90 countries Availability n Freely available, runs on Windows, Mac OS, and Linux platforms Resources n http: //www. genepattern. org n User workshops, documentation, email help desk, online user forum n Reich et al. (2006) Nature Genetics n Collaborations with 2 NIH Biomedical Computing Roadmap Centers and NCI’s cancer biomedical informatics grid (ca. BIG) Gene. Pattern is a winner of the 2005 Bio. IT World Best Practices Award

Web 2. 0 community to share diverse computational tools www. genomespace. org 6 Seed Tools 3 Driving Biological Projects Cytoscape Galaxy Gene. Pattern Genomica IGV UCSC Browser Cancer linc. RNAs Stem cell circuits Outreach: new tools Outreach: new DPBs Partner Institutions

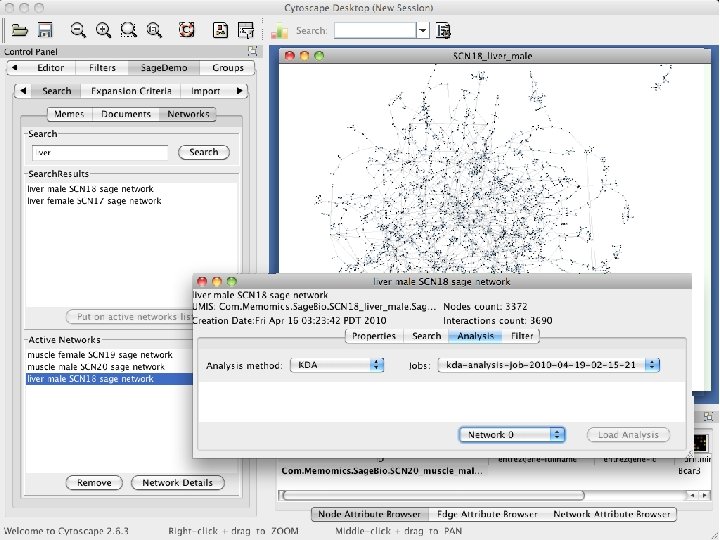
Performing Key Driver Analysis in Gene. Pattern • Sage provided R scripts that perform the KDA analysis • These were wrapped as a Gene. Pattern (GP) module – GP generated a web user interface and web service for KDA – This web service was used to integrate KDA into Taverna • A demonstration Gene. Pattern pipeline (workflow) –Calculate a differentially expressed genes in a TCGA dataset –Perform KDA using a Sage breast cancer network model and the gene list from the differentially expressed genes –Reformats the KDA output for Cytoscape –Launches Cytoscape to visualize the results

Key Driver Analysis Demo

Taverna Workflow

A suite of tools for bioinformatics • Fully featured, extensible and scalable scientific workflow management system – – Workbench, server, portal Standards-compliant provenance collection Immediate ingest of web services Grid services, Beanshell scripts, R-scripts, Bio. MOBY services… • Web 2. 0 social collaboration environments (“E-Labs”) for sharing – Methods, workflows – Systems biology data, models and SOPS – Statistical methods • Curated catalogue of Web Services

Taverna Open Suite of Tools Workflow Repository Workflow GUI Workbench Client User Interfaces Third Party Tools Service Catalogue Provenance Store Workflow Server Web Portal Activity and Service Plug-in Manager Open Provenance Model Secure Service Access Programming and APIs

Taverna Software Release Information • Taverna first released 2004. • Current versions 1. 7. 2 and Taverna 2. 1. 2 • Currently 1500 + users per month, 350+ organizations, ~40 countries, 80000+ downloads across versions Availability • Freely available, open source LGPL • On Windows, Mac OS, and Linux platforms Resources • http: //www. taverna. org. uk, http: //www. mygrid. org. uk • User and developer workshops, documentation, email help desk • Collaborations with numerous groups including NCI’s cancer biomedical informatics grid (ca. BIG), EMBL-EBI, NCBI, Concept Web Alliance, Bio 2 RDF

my. Experiment • A Web 2. 0 community for sharing, discovering and reusing workflows and other scientific methods. • A platform for launching workflows • Launched late 2007. • Currently: 3272 members, 223 groups, 1024 workflows, 306 files and 97 packs, 56 different countries. • 10+ workflow systems: Taverna, Pipeline pilot, Bio. Extract, Kepler • ~ 3000 unique hits per month REST APIs Linked Open Data Software Open source BSD

Systems Biology and my. Grid Sys. MO-SEEK ONDEX • e-Laboratory for interlinking and sharing data, models, SOPS and workflows for Systems Biology in Europe • ISA-TAB & SBML/MIRIAM compliant • Network based analysis environment for Systems Biology • Uses Taverna workflows and text mining http: //www. sysmo-db. org/ http: //www. ondex. org/
 Calculate")
Performing Taverna KDA and Pathways pipeline • • A demonstration Taverna Pipeline (workflow) Calculate a differentially expressed genes in a TCGA dataset Perform KDA using a Sage breast cancer network model and the gene list from the differentially expressed genes Reformats the KDA output for Cytoscape Launches Cytoscape to visualize the results Extracts gene names from TCGA dataset Finds pathways for these genes in KEGG using workflow deposited in my. Experiment.

Taverna pathway pipeline demo

Cytoscape Workflow

Cytoscape is an open source software platform for Cytoscape is a collaboration between integrating, visualizing, and analyzing measurement data in the context of networks University of California, San Diego Institute for Systems Biology Memorial Sloan-Kettering Cancer Center Institute Pasteur Agilent Technologies University of Toronto Gladstone Institute for Cardiovascular Disease University of California, San Francisco Unilever National Center for Integrative Biomedical Informatics Free from: http: //www. cytoscape. org • 60, 000+ downloads for 2. x release; 27, 000 downloads in the last year; 2, 300/month • 340+ published articles citing Cytoscape; 135 articles in the last year • 50+ registered plugins, developed by leading research groups

Applications of Networks in Disease Identification of disease subnetworks – identification of disease subnetworks that are transcriptionally active in disease Agilent Literature Search Mondrian, MSKCC Subnetwork-based diagnosis – source of biomarkers for disease classification, identify interconnected genes whose aggregate expression levels are predictive of disease state Network-based gene association – map common pathway mechanisms affected by collection of genotypes (SNP, CNV) Pinnacle. Z, UCSD

Cytoscape Plugin Open API Web interface Cytoscape plugin

Connecting to Your Memory
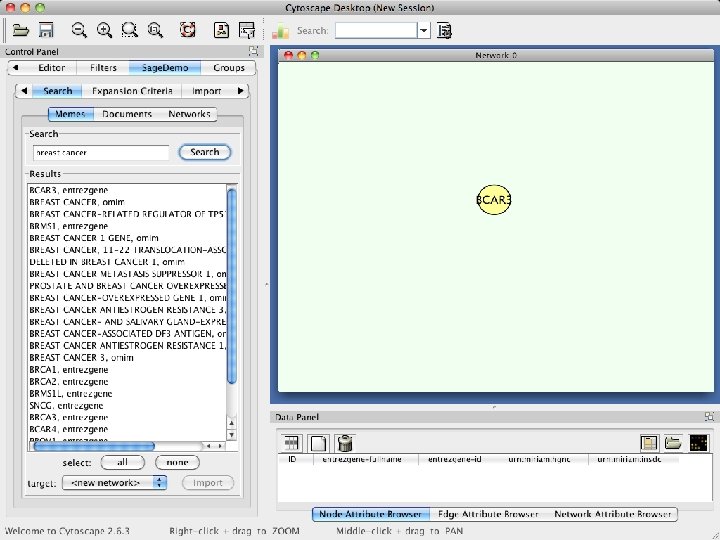
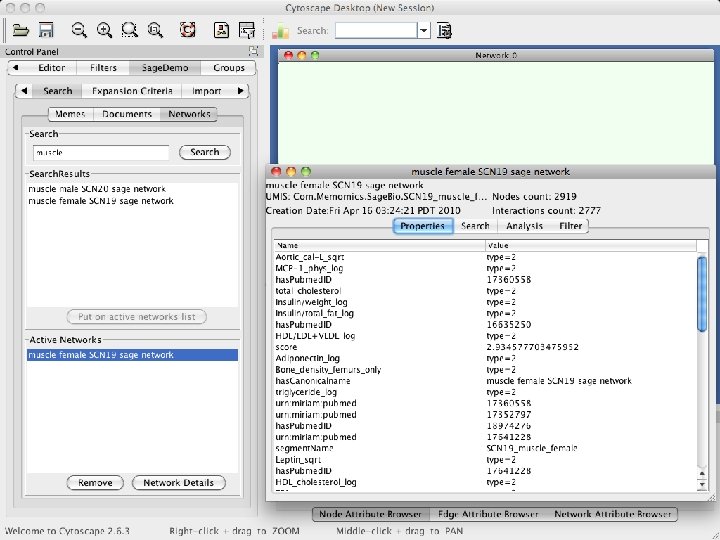
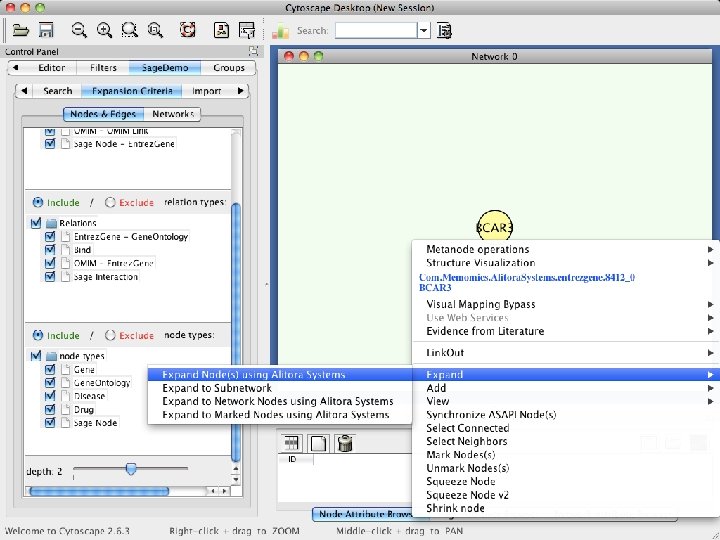

KDA Plugin

Tools Afternoon Session • Review of developments to date – – – Creating Semantic Model for Sage Networks Storing Sage Networks with Alitora for Search & Visualization Performing Key Driver Analysis with Gene. Pattern Taverna workflow for annotating and analyzing the network model Working with Sage Networks in Cytoscape • Other network model tools – Additional tool providers discuss integrating with Sage • Looking forward – open questions and gaps – breakout sessions

SCF/SWAN Tim Clark Instructor in Neurology, Harvard Medical School Director of Informatics, Mass. General Institute for Neurodegenerative Disease Core Member, Harvard Initiative in Innovative Computing

Bio 2 RDF Michel Dumontier Associate Professor Department of Biology School of Computer Science Institute of Biochemistry University of Carleston, Canada

Tools Afternoon Session • Review of developments to date – – – Creating Semantic Model for Sage Networks Storing Sage Networks with Alitora for Search & Visualization Performing Key Driver Analysis with Gene. Pattern Taverna workflow for annotating and analyzing the network model Working with Sage Networks in Cytoscape • Other network model tools – Additional tool providers discuss integrating with Sage • Looking forward – open questions and gaps – breakout sessions

Implications for Sage infrastructure Lessons Learned: Formats 1. Standard network & gene list file formats are critical to the success of infrastructure tools. 2. Current dataset and network repositories fall short of providing a Identifiers Services community resource with adequate standards and extensible tools. Map to standards Appropriate interfaces Challenges Ahead: 1. Preparing for increasing scale and scope of data 2. Preparing for future data types and analyses

Semantics Syntax Domain Semantics Ontologies Custom Data Objects Information models Syntax Configuration Invocation model Interface Data format Data identity Data Identity

Keep It Simple. Open Source.

1. 2. 3. 4. 5. 6. 7. 8. Web 2. 0 Development Patterns The Long Tail Leverage scientist-self service to reach out to the long tail Users Add Value Involve colleagues and other scientists, both implicitly and explicitly, in adding value to your application. Network Effects by Default Set inclusive defaults for aggregating user data as a side-effect of their use of the application. Perpetual Beta Don't package up new features into monolithic releases. Add them on a regular basis as part of the normal user experience. Cooperate, Don't Control Design for mash ups. Offer web services interfaces and content syndication, and re-use the services of others. Some Rights Reserved. Benefits come from collective adoption. Make sure that barriers to adoption are low. Follow existing standards. Use licenses with as few restrictions as possible. Design for "hackability" and "remixability. " Data is the Next Intel Inside Applications are increasingly data-driven. For competitive advantage, seek to own a unique, hard-to-recreate source of data – workflows are data and data sources. Software Above the Level of a Single Device Design your application from the get-go to integrate and launch services across any interface. Adapted from Tim O’Reilly’s Web 2. 0

This afternoon • Drill down into demos and experiences • Guests – Tim Clark – SWAN, Web 3. 0, neurodegeneration – Michel Dumontier – Bio 2 RDF • Audience participation! – Opportunities, Barriers and Incentives – Platforms, datasets, services and tools – Technologies and Standards – Directions for Sage Bionetworks

Questions for Afternoon 1. Are there specific gene list and network model databases, tools and platforms that we want to integrate with the Sage Data? • e. g. MSig. DB gene lists 2. What form of integrated analysis would be most useful for finding new biological insights using the Sage models and KDA? • e. g. Would we like to be able to create lists of mutations from TCGA to use as inputs to KDA and the Sage models? • What model annotations are necessary to make this useful – context?

Questions for Afternoon 1. Provenance - what is needed at Sage to ensure provenance of network models is preserved for future reference? E. g. do models need unique, persistent, referencable identifiers? Will they be versioned? If models change due to new data, or updated algorithms, how can we easily rerun analyses? What privacy software do we need and could leverage? 2. Will Sage. Commons need to be ‘replicable’ at other sites to support privacy - e. g. Pharma and Biotech who do not want their use of the models to be potentially snooped on the ‘net?

Audit of Tools
- Slides: 74