Progress and Challenges in Automatic Speech Recognition Douglas

 - a pattern recognition task • Review: relevant")


:")
 to each input utterance •")





")
 • memory limitations •")




 • pitch")
 requires")

 estimation • Often, errors in weak speech and in transitions between")
 coefficients • 1)")

 • C")
 • As in analysis of variance (ANOVA),")
: • speech")


 partition")



 approach • Maximizing total ASR likelihood: “optimal” in that all")
 =")




 Memory Block Structure")



 • fast matrix and vector multiplications")



- Slides: 56
Progress and Challenges in Automatic Speech Recognition Douglas O'Shaughnessy
Overview • Automatic speech recognition (ASR) - a pattern recognition task • Review: relevant aspects of human speech production and perception • Acoustic-phonetic principles • Digital analysis methods • Parameterization and feature extraction • Training and adaptation of models • Overview of ASR approaches • Practical techniques: Hidden Markov Models, Deep Neural Networks • Acoustic and Language Models • Cognitive and statistical ASR
Pattern Recognition • Need to map a data point in Ndimensional space to a label • Input data: samples in time • Output: Text for a word/sentence • Assumption: signals for similar words cluster in the space • Problem: how to process speech signal into suitable features
Simplistic approach • Store all possible speech signals with their corresponding texts • Then, just need a table look-up • Moore's Law will solve ASR problem? • storage doubling every year • computation power doubling every 1. 5 years
Why not? • Short utterance of 1 s and coding rate 1 kbps (kilobit/second): • 25 frames/s, 10 coefficients a frame, 4 bits/coefficient -> 21000 signals • Suppose each person spoke 1 word every second for 1000 hours: • about 1017 short utterances • Well beyond near-term capability
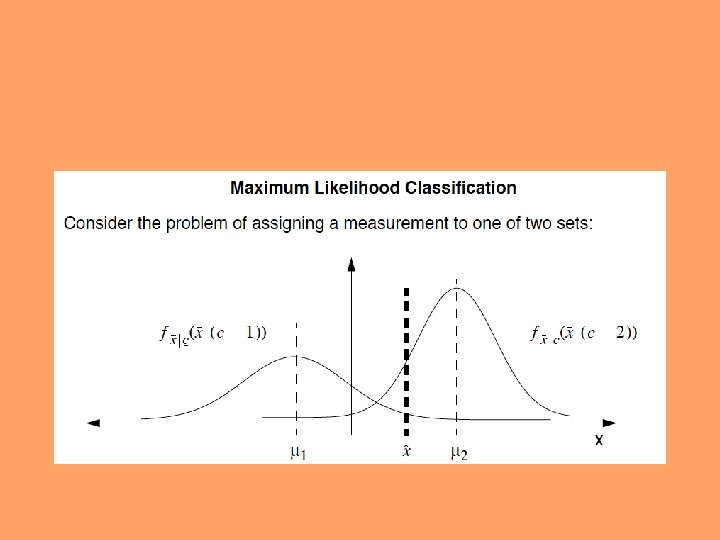
N-dimensional pattern space • ASR assigns a label (text) to each input utterance • Similar speech is assumed to cluster in the feature space • Often use simple distance to measure similarity between input and centroids of trained models • This assumes that perceptual and/or production similarity correlates with distance in the feature space – often, not the case unless features are well chosen
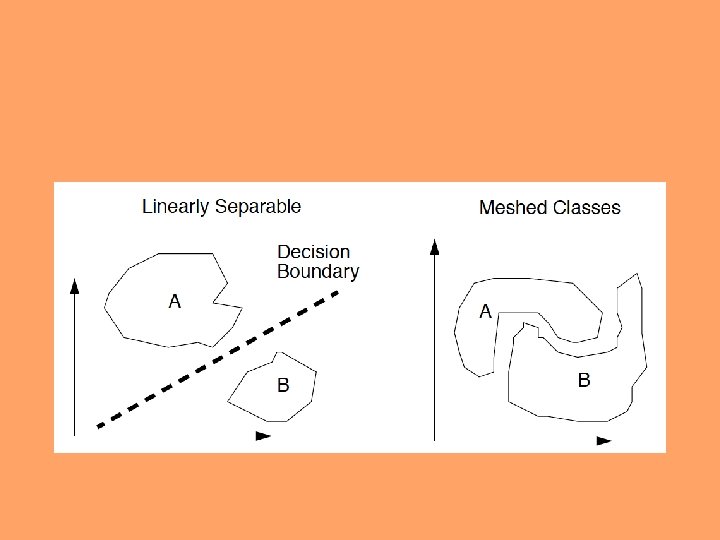
Similarity Measures • representation of a frame of speech: Ndimensional vector (point in N-dimensional space), N = number of parameters or features • if features well chosen (similar values for different versions of same phonetic segment, and distinct values for segments that differ phonetically), then separate regions can be readily established in the feature space for each segment.
Distance measures • Must focus any comparison measure on relevant spectral aspects of the speech units • Euclidean distance measure: simple • Itakura-Saito measure: used with LPC • Maximizing probability in stochastic approaches
Distance Measures • If N dimensions and W = weighting matrix:
Signal processing • not only to reduce costs • mostly to focus analysis on important aspects of the signal (thus raising accuracy) • use the same analysis to create model and to test it • not done in some recent end-to-end ASR; however, most ASR uses either MFCC or log spectral filterbank energies • otherwise, feature space is far too complex
Possible ASR approaches • emulate how humans interpret speech • treat simply as a pattern recognition problem • exploit power of computers • expert-system methods • stochastic methods
System Overview Courtesy of Bin Ma (2015)
System limitations inadequate training data (in speaker-dependent systems: user fatigue) • memory limitations • computation (searching among many possible texts) • inadequate models (poor assumptions made to reduce computation and memory, at the cost of reduced accuracy) • hard to train model parameters
Speech production • Speech: not an arbitrary signal • source of input to ASR: human vocal tract • data compression should take account of the human source • precision of representation: not exceed ability to control speech
Free variation • Aspects of speech that speakers do not directly control are free variation • Can be treated as distortion (noise, other sounds, reverberation) • Puts limits on accuracy needed • Creates mismatch between trained models and any new input • Intra-speaker: people never say the same exact utterance twice • Inter-speaker: everyone is different (size, gender, dialect, …) • Environment: SNR, microphone placement, … • Compare to vision PR: changes in lighting, shadows, obscuring objects, viewing angle, focus • Vocal-tract length normalization (VTLN); noise suppression
• Speaker controls: amplitude, pitch, formants, voicing, speaking rate • Mapping from word (and phoneme) concepts in the brain to the acoustic output is complex • Trying to decipher speech is more complex than identifying objects in a visual scene • Vision: edges, texture, coloring, orientation, motion • Speech: indirect; not observing the vocal tract
Cues from perception • Auditory system sensitive to: dynamic positions of spectral peaks, durations (relative to speaking rate), fundamental frequency (F 0) patterns • Important: where and when energy occurs • Less relevant: overall spectral slope, bandwidths, absence of energy • Formant tracking: algorithms err in transitions; not directly used in ASR for many years
Speech Signal Analysis • distribution of speech energy in frequency (spectral amplitude) • pitch period estimation • sampling rate typically: • 8 000/sec for telephone speech • 10 000 - 16 000/sec otherwise • usually 16 bits/sample • 8 -bit mu-law log. PCM (in the telephone network)
Short-time spectral analysis • Feature determination (e. g. , formant frequencies, F 0) requires error-prone methods • So, automatic methods (parameters) preferred: • FFT (fast Fourier transform) • LPC (linear predictive coding) • MFCC (mel-frequency cepstral coefficients) • RASTA-PLP • Log spectral (filter-bank) energies
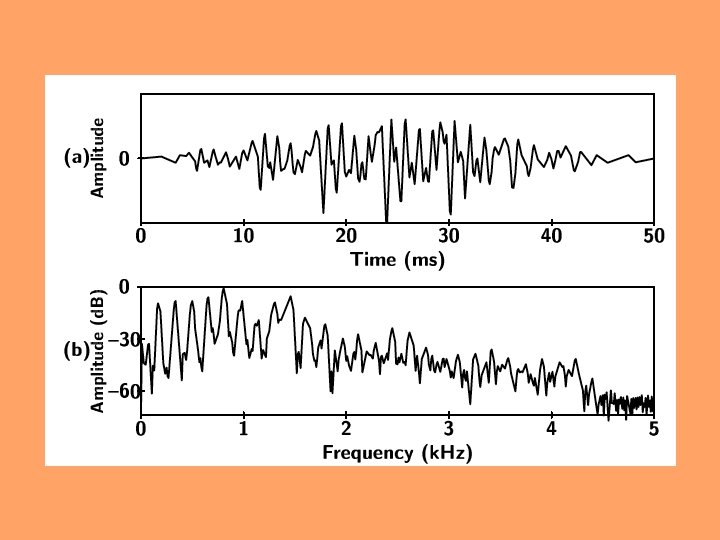
Pitch (F 0) estimation • Often, errors in weak speech and in transitions between voiced and unvoiced speech (e. g. , doubling or halving F 0) • peak-pick the time signal (look for energy increase at each closure of vocal cords) • usually first filter out energy above 1000 Hz (retain strong harmonics in F 1 region) • often use autocorrelation to eliminate phase effects • often not done in ASR, due to the difficulty of exploiting F 0 in its complex role of signaling different aspects of speech communication
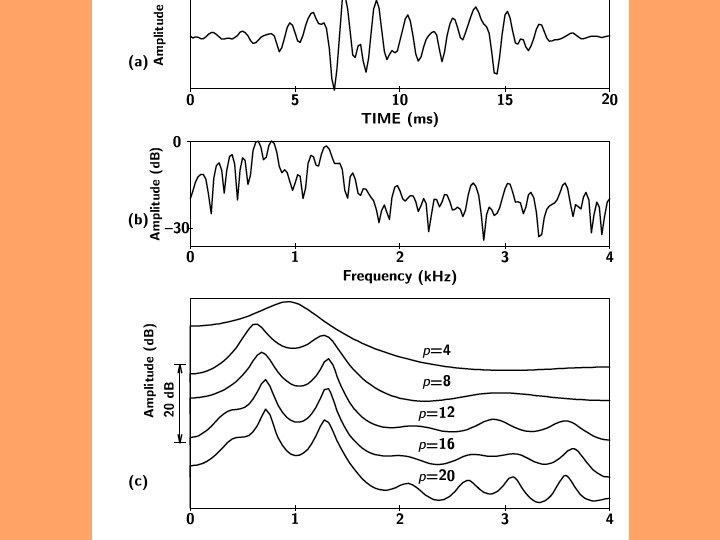
Parameterization • Objective: model speech spectral envelope with few (8 -16) coefficients • 1) Linear predictive coding (LPC) analysis: standard spectral method for low-rate speech coding • 2) Cepstral processing: common in ASR; also can exploit some auditory effects • 3) Vector Quantization (VQ): reduces transmission rate (but also ASR accuracy)
Cepstral processing • Cepstrum: inverse FFT of the log-amplitude FFT of the speech • small set of parameters (often 10 -13) as LPC, but allows warping of frequency to match hearing • inverse DFT orthogonalizes • gross spectral detail in low-order values, finer detail in higher coefficients • C 0: total speech energy (often discarded)
Cepstral coefficients • C 1: balance of energy (low vs. high frequency) • C 2, . . . C 13 encode increasingly fine details about the spectrum (e. g. , resolution to 100 Hz) • Mel cepstral coefficients (MFCCs) • model low frequencies linearly; above 1000 Hz logarithmically
Feature Transforms • Linear discriminant analysis (LDA) • As in analysis of variance (ANOVA), regression analysis and principal component analysis (PCA), LDA finds a linear combination of features to separate pattern classes • Maximum likelihood linear transforms • Speaker Adaptive Transforms • Map sets of features (e. g. , MFCC, Spectral energies) to a smaller, more efficient set
Major issues in ASR • Segmenting speech spoken without pauses (continuous speech): • speech unit boundaries are not easily found automatically (vs. , e. g. , Text-To-Speech) • Variability in speech: different speakers, contexts, styles, channels • Factors: real-time; telephone; hesitations; restarts; filled pauses; other sounds (noise, etc)
Comparing ASR tasks • speaker dependence • size of vocabulary • small (< 100 words) • medium (100 -1000 words) • large (1 -20 K words) • very large (> 20 K words) • complexity of vocabulary words • alphabet (difficult) • digits (easy)
Comparing ASR - 2 • allowed sequences of words - perplexity: mean # of words to consider - language models • style of speech: isolated words or continuous speech; how many words/utterance? • recording environment - quiet (> 30 d. B SNR) - noisy (< 15 d. B) - noise-cancelling microphone - telephone • real-time? feedback (rejection)? • type of error criterion • costs of errors
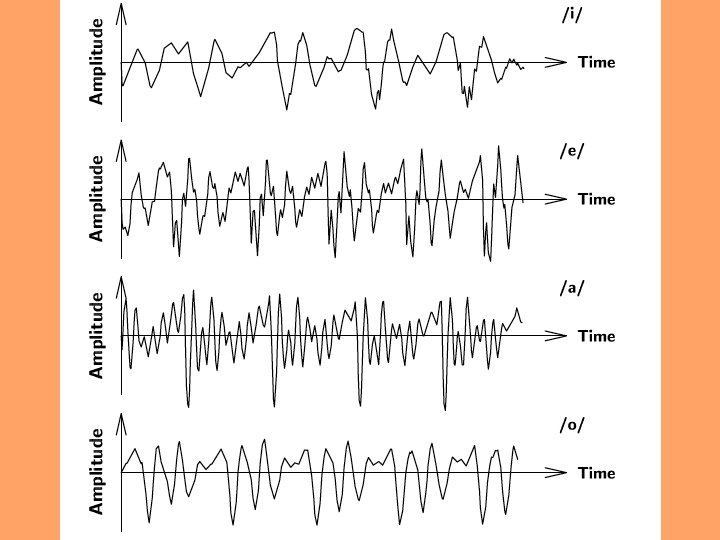
Possible ASR features • formants (e. g. , F 1 and F 2) partition the vowels in the vowel triangle well (using F 3 further minimizes overlap) • pitch (F 0) • features are less commonly used in most ASR, owing to ASR to their complexity and difficulty of reliable estimation • Automatically determined bottleneck features in DNN • MFCC
ASR Thresholds • Thresholds: optional; to raise a ASR accuracy; cost = a delay • speaker allowed to repeat an utterance IF the best candidate has provided a poor match. • feasible for interactive ASR: immediate feedback or action. • balance ASR error rate and the “false rejection” rate (rejecting an otherwise correct response)
Temporal variability • Linear time alignment: simple mapping of long and short templates by linear compression or interpolation • Dynamic Time Warping: - more costly method - to accommodate natural timing variations in ordinary speech - still used in some systems • Network methods: most widespread for the last 30 years
Dynamic Time Warping • Very popular in the 1970 s • Compares exemplar patterns, with timing flexibility to handle speaking rate variations • No assumption of similarity across patterns for the same utterance • Thus, no way to generalize • Very poor to formulate efficient models
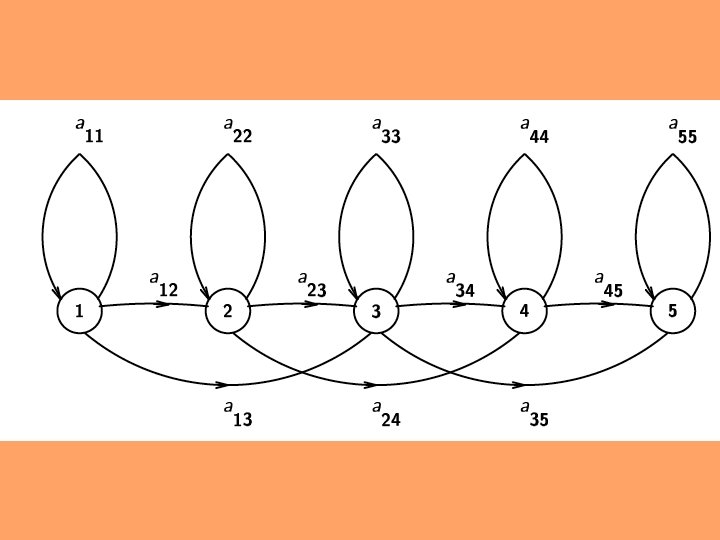
Hidden Markov Model (HMM) approach • Maximizing total ASR likelihood: “optimal” in that all input information is considered before global recognition decision made • Word-based HMMs: small-vocabulary applications • Phone-based HMMs: needed for largevocabulary applications, due to difficulty of training, cost of computation and memory
HMM stochastic model • Bayes rule maximizes over possible {T}: • max P(T|S) = max[P(T)P(S|T)]/P(S) • Weight the decision by the a priori likelihood of text T being spoken (the Language Model) • Acoustic models P(S|T) for different speech units (words, phonemes, allophones)
Combining probabilities • For T frames, a = transitions, O = observations, i = states, b = state pdf’s:
• for observation probabilities, usually Gaussian pdf's, • due to the simplicity of model, using only a mean and a variance • (in M dimensions, need a mean for each parameter, and • a Mx. M covariance matrix, noting the correlations between parameters)
Improving HMMs • major difficulty: first-order frame-independence assumption • use of delta coefficients over several frames (e. g. , 50 ms) helps to include timing information, but is inefficient • stochastic trajectory models and trended HMMs are examples of ways to improve timing modeling • higher-order Markov models are too computationally complex • incorporate more information about speech production and perception into the HMM architecture?
Neural Networks
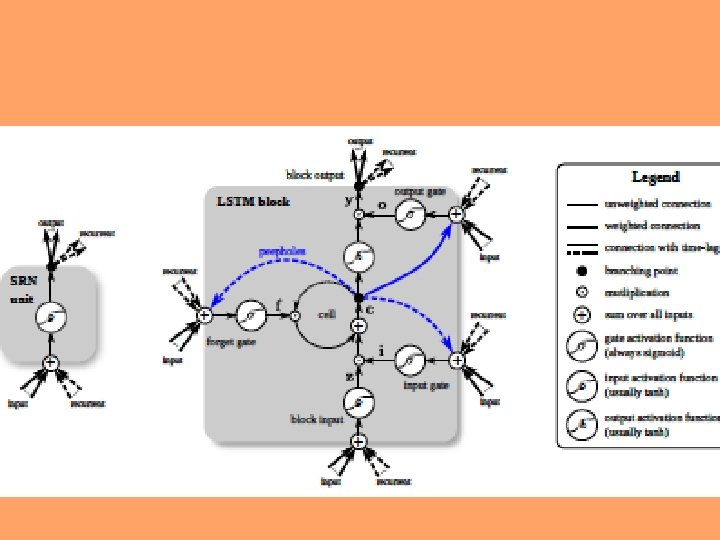
Long Short-Term Memory (LSTM) Memory Block Structure
Back-propagation in Time
Connectionist Temporal Classification • Can handle unaligned speech input • Adds extra layer to RNN to allow “end-to -end” ASR
Fast Graphics Processing Units (GPUs) • fast matrix and vector multiplications
Deep Neural Networks • Recurrent artificial NN’s are now dominating ASR • Basic perceptron: each node in a layer outputs 0 or 1 as input to the next layer, based on a weighted linear combination from the layer beneath • 3 layers: adequate to handle all volumes in Ndimensional space • Steepest-gradient back propagation training • Advances due to big data and massive power • End-to-end DNN or DNN/GMM ASR
DNN training issues • Still using stochastic gradient as the main way to set the net weights • Set learning step size for efficient updates • Momentum: to avoid traps in local minima • Same criterion as in codebook design for speech coding
Recent new ideas in ASR • Conditional random field acoustic models • Boosting probabilities • Support vector machines (SVM): good for binary classifications • Machine learning