Processus ponctuels Caractristiques et Modles de rpartitions spatiales











![Loi de probabilité diffuse ● Rappel : Loi uniforme sur [0, 1] – –](https://slidetodoc.com/presentation_image/40af71cf4ab87326f1dc687e1f47bedf/image-13.jpg "Loi de probabilité diffuse ● Rappel : Loi uniforme sur [0, 1] – –")


 définie sur")












![Processus markoviens ● Rappel – On considère la loi uniforme sur [0, 1] –](https://slidetodoc.com/presentation_image/40af71cf4ab87326f1dc687e1f47bedf/image-29.jpg "Processus markoviens ● Rappel – On considère la loi uniforme sur [0, 1] –")







 est la probabilité d’avoir un point à")
 estimé en choisissant une grille fixe")







- Slides: 45
Processus ponctuels Caractéristiques et Modèles de répartitions spatiales
Un exemple de répartition spatiale
Objectifs ● ● ● Décrire la répartition de points sur un plan, qualitativement et quantitativement Construire des modèles aléatoires de répartition d'un ensemble de points dans une surface finie Définir une collection de modèles suffisamment riche pour correspondre aux différentes situations
Visualisation des données
Visualisation des données
Caractéristiques qualitatives ● ● Abondance ou rareté des points Présence notable de groupes de points ou dispersion régulière
Typologie des répartitions
Caractéristiques quantitatives ● Agrégation – On calcule le nombre de voisins de chacun des points dans un cercle de rayon r. On fait varier r. (statistique de Ripley)
Quels modèles? ● ● Descriptifs ou explicatifs? Déterministes ou aléatoires?
Modèles aléatoires de répartition spatiale Processus ponctuels
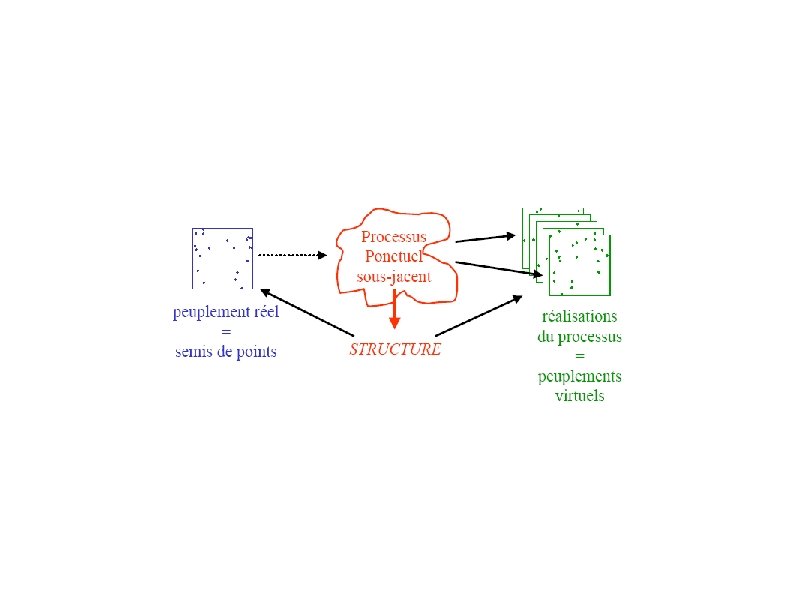
Processus ponctuels ● ● ● On considère que le semis de points observé est le résultat d'un tirage aléatoire selon une certaine loi de probabilité Le tirage aléatoire concerne le semis dans son ensemble et non chaque point du semis individuellement La construction de la loi de probabilité constitue le modèle
Loi de probabilité diffuse ● Rappel : Loi uniforme sur [0, 1] – – ● La probabilité de tirer une valeur particulière X=0, 3 est toujours nulle On définit la loi de probabilité en fixant la probabilité que x appartienne à un sous-intervalle [a, b] P(X [a, b])=b-a. La loi de probabilité du processus ponctuel est diffuse – – La probabilité associée à un semis fixé est nulle On définit la loi de probabilité du processus en fixant la probabilité d'ensembles de semis particuliers analogues des intervalles
Construction de la probabilité ● Ensemble de semis – – – ● Pour chaque partition finie en rectangles (Bi) du rectangle A Pour chaque suite d'entiers (ni) correspondant aux (Bi) On définit S l'ensemble des semis comportant ni points dans Bi Définition de la loi de probabilité – – On définit P(S) comme fonction des (Bi, ni). Cette fonction doit être cohérente avec la définition des probabilités L'ensemble I des semis ayant une infinité de points a une probabilité nulle
Processus ponctuels indépendants ● ● Processus de Poisson homogène Processus de Poisson inhomogène
Processus de Poisson homogène ● Rappel : Loi de Poisson P( ) définie sur N – ● Exercice : Montrer que la somme de deux variables de Poisson est une variable de Poisson Processus de Poisson homogène d'intensité – – Pour tout rectangle B dans A, le nombre de points dans B suit une loi de Poisson de paramètre a(B) où a(B) est l'aire de B. Si B et C sont deux rectangles sans intersection, les nombres de points dans B et C sont deux variables indépendantes
Propriétés ● ● Si on réunit les semis obtenus à partir de deux processus de Poisson indépendants on obtient un processus de Poisson dont l'intensité est la somme des intensités deux processus d'origine Le processus de Poisson sert de référence aux autres processus, en tant que processus le plus aléatoire : les points du semis apparaissent de façon indépendante les uns des autres, et de façon uniforme sur A.
Simulation ● Le processus de Poisson homogène peut être simulé de la façon suivante – – On tire le nombre total N(A) de points du semis suivant une loi de Poisson de paramètre a(A) On tire successivement et indépendamment N(A) points suivant une loi de probabilité uniforme sur A ● Exercice : montrer qu'on obtient bien un processus de Poisson correspondant à la définition précédente
Processus de Poisson inhomogène ● ● Le processus inhomogène est une modification du processus homogène dans lequel les points apparaissent préférentiellement dans certaines zones de A. Soit (x) une fonction intégrable définie sur A. Processus de Poisson inhomogène d'intensité – – Pour tout rectangle B dans A, le nombre de points dans B suit une loi de Poisson de paramètre (B) où (B) est l'intégrale de la fonction sur B. Si B et C sont deux rectangles sans intersection, les nombres de points dans B et C sont deux variables indépendantes
Propriétés ● ● Si on réunit les semis obtenus à partir de deux processus de Poisson indépendants on obtient un processus de Poisson dont l'intensité est la somme des intensités deux processus d'origine Le processus de Poisson inhomogéne est tel que les points du semis apparaissent de façon indépendante les uns des autres, mais pas de façon uniforme sur A. On voit apparaître des agrégats de points dans les zones où la fonction d'intensité est grande.
Simulation ● Le processus de Poisson inhomogène peut être simulé de la façon suivante – – On tire le nombre total N(A) de points du semis suivant une loi de Poisson de paramètre (A) On tire successivement et indépendamment N(A) points suivant une loi de probabilité de densité (x)/ (A) sur A
Conclusion sur les processus de Poisson ● ● Ces processus sont à la base de la construction de la plupart des processus ponctuels Ils présentent des agrégats (pr. inhomogène) ou pas (pr. homogène) La position des agrégats est fixe et dépend de la fonction d'intensité Dans ces modèles individus représentés par les points n'interagissent pas ; ils ignorent la position de leurs voisins
Processus ponctuels dépendants ● ● ● Processus de Neymann Scott Processus de Cox Processus markoviens
Processus de Neyman-Scott ● Le processus de Neyman-Scott est défini en deux étapes indépendantes – – On tire un semis selon un processus de Poisson homogène Autour de chaque point obtenu yi, on tire selon un processus de Poisson inhomogène d'intensité f(x-yi)
Remarques ● ● Les points centres sont effacés du semis final Le deuxième tirage n'est pas nécessairement un processus de Poisson : – – on choisit une loi discrète quelconque pour tirer le nombre de points on tire les points indépendamment selon une loi de distribution identique autour de chacun des centres.
Propriétés ● ● Les points ne sont plus indépendants, les points issus d'un même centre sont plus rapprochés Les agrégats apparaissent naturellement Leur position est évidemment aléatoire Le processus dans son ensemble est homogène : aucune zone de A ne voit apparaître plus de points en moyenne
Processus de Cox ● Les processus de Cox sont également générés en deux étapes – – On tire une fonction (x) définie sur A par un tirage aléatoire On tire un Poisson inhomogène d'intensité (x)
Remarque ● ● La vraie difficulté consiste en la première étape. Exemple – – – On tire un processus de Poisson sur A et pour chaque point yi obtenu on définit une fonction f(x-yi) autour du point. On somme toutes les fonctions pour obtenir la fonction g(x). On effectue un tirage de Poisson inhomogène d'intensité g(x). On obtient le processus de Neyman-Scott précédent.
Processus markoviens ● Rappel – On considère la loi uniforme sur [0, 1] – On choisit une fonction f d'intégrale 1. On définit une nouvelle loi de probabilité par – La fonction f appelée densité de Y par rapport à X introduit une déformation de la loi uniforme. Les intervalle où f est grande ont une probabilité plus forte
Principe ● ● ● On veut déformer la loi de probabilité du processus de Poisson homogène pour favoriser les agrégats On se fixe une fonction de densité f définie sur un semis S par est une fonction d'interaction entre deux points, elle peut être répulsive ou attractive selon les distances entre les points
Exemples ● Processus de Strauss répulsif – – ● <1 et R est le rayon d'interaction Les semis où deux points sont plus proches que R sont plus rares Processus hardcore – Les semis où deux points sont plus proches que R sont interdits
Exemples ● Processus hardcore attractif – – – d>1 et R 1<R 2 Les semis où deux points sont plus proches que R 1 sont interdits. Les semis où deux points sont à distance r telle que R 1<r<R 2 sont favorisés
Conclusion sur les processus dépendants ● Classes de modèle plus riches, générant des agrégats selon différents principes : – – – Neyman-Scott : principe de semis Cox : principe d'environnement aléatoire Markov : principe de compétition/coopération entre individus
Caractéristiques quantitatives Statistiques définies à partir des données
Abondance/ Rareté • Caractérisée par le nombre moyen de points par unité de surface • • soit globalement (cas homogène) soit localement (cas inhomogène) : choix d’un voisinage ou d’une fonction de lissage
Agrégats • Caractérisée par le nombre de voisins de chaque point de l’ensemble • • Fonction de vide Nombre de voisins
Fonction de vide • • • F(r) est la probabilité d’avoir un point à une distance inférieure à r de l’origine. G(r) est l’espérance pour un point du semis d’avoir un voisin à une distance inférieure à r. J(r) = (1 - F(r))/ (1 - G(r)) • • est égale à 1 pour un processus de Poisson homogène <1 si dispersion, >1 si agrégation
Statistique de fonction de vide • • F(r) estimé en choisissant une grille fixe de points et en calculant la proportion de points de la grille ayant un point du semis à une distance inférieure à r. G(r) estimé en comptant la proportion de points du semis ayant un point du semis à une distance inférieure à r.
Statistique de Ripley ● On suppose connue la fonction d'intensité du processus. Pour chaque distance r, on définit la statistique K de Ripley par – La statistique compte le nombre de couples de points à distance inférieure àr
Processus de Poisson homogène ● ● ● Dans ce cas, on peut calculer l'espérance de la statistique de Ripley L'espérance du nombre de voision à distance r est égale à l'espérance du nombre de point dans un disque de rayon r : il n'y a pas d'effet de la présence du point au centre du cercle Pour les représentations graphiques, on définit
Interprétation graphique
Conclusion ● ● ● La statistique de Ripley permet de mesurer un écart entre les données issues du modèle de Poisson homogène et les données examinées On connaît mal sa distribution pour un r fixé (on peut calculer sa variance) et on sait que les résultats pour différentes valeurs de r sont très dépendantes : difficile de construire un test Si le processus est agrégé, elle ne distingue pas entre un effet sur la moyenne de nombre de points (processus inhomogène) ou un effet de dépendance entre les points (Neyman-Scott, Cox, Markov)
Problème de la correction de bords ● Si r est grand par rapport aux dimensions de A
Choix d'une fenêtre plus petite
Cas de deux peuplements