Procesory 5 a 7 generace Procesory 5 generace












. Je povolena aktivace přerušovacích bodů nastavených registry DR")
. Je-li úroveň H, je")


 FIP - Ukazatel instrukce (Floating-point Instruction Pointer) je 32")
 je 16 bitový a je v")
 je 16")
 je 16 bitový a obsahuje")




. Při úrovni L přechází procesor do")
. Na činnost procesoru nemá vliv. BE")


 má na starosti vnější rozhraní čipu, kontroluje")
 čte kódy instrukcí z IVP")



 Jednotka IVP je rozdělena na dvě části po 8 k.")
,")

")
 je dokonalejší než u procesoru")
, kdy pracuje")

 ve které jak již název")

. V této fázi jsou určovány adresy operandů uložených")




 obsahuje jeden čtecí buffer. To z toho důvodu, že")




 maximálně s 256 položkami.")
 Jednotka výpočtů v pohyblivé řádové čárce se")
 – pracuje jednotka předvýběru")












 patří mezi základní módy tohoto procesoru. Umožňuje")







 byla vytvořena za účelem zvýšení")




 je vlastně modernizací technologie MMX. Obsahuje 70 nových")

 Rychlost vzhledem k procesoru Technologie")
 je 64 bitový procesor na rozhraní mezi CISC")



 je kombinací 3 technik : · předpovědi skoku ·")

, které se dělí do")

, které")

.")












 rozšiřující technologii MMX (všechny registry")


 umožňující vykonání několika instrukcí paralelně. ·")
")



,")


- Slides: 120
Procesory 5. až 7. generace
Procesory 5. generace Jedná se o procesory 5. generace, které byly firmou Intel z komerčních důvodů nazvány Pentium.
Procesory Pentium 1. a 2. generace Procesorů Pentium je celá řada a na základě technologie a dalších podstatných změn v konstrukci se zařazují do dalších generací. Procesory Pentium v těchto generacích lze dělit podle následujících znaků na : · Procesory 1. generace s pracovní frekvencí 60 MHz a 66 MHz, s napájením 5 V, při čemž jejich pracovní frekvence byla shodná s pracovní frekvenci základní desky a jichž se týká dále uvedený popis. Výběr frekvence byl určen procesorem, generátorem hodin a čipsetem AGP.
· Procesory 2. generace s pracovní frekvencí 75 MHz až 200 MHz, s napájením 3, 3 V, které mají oproti výše zmiňovaným procesorům i obvody APIC (Advanced Programmable Interrupt Controler) a rozhraní pro 2 procesory. Řadič APIC a rozhraní umožňovaly paralelní chod dvou procesorů na jedné základní desce. Tyto procesory však nepracovaly na frekvenci základní desky. Například základní deska pracovala na frekvenci 66 MHz a procesor na frekvenci 200 MHz. Poměr frekvence základní desky a procesoru je řízen 2 vývody procesoru BF 1 a BF 2. Jejich kombinací (kombinací příslušných L a H) se nastavuje pracovní frekvence procesoru.
Procesor Pentium
Procesor 80586 nazvaný Pentium byl sice jako prvý, ale nepravý 64 bitový procesor typu CISC se superskalární architekturou uveden firmou Intel na trh v květnu 1993. Pracoval na frekvencích 60 MHz a 66 MHz. Byl pokračovatelem řady 286, 386, 486. Nemá žádné další programovatelné registry. Navíc obsahuje jen několik rozšířených instrukcí. Vnější datová sběrnice jak bylo uvedeno je 64 bitová, adresová sběrnice je 32 bitová. Obsahuje dvojitou IVP (cache) v členění 8 k. B data a 8 k. B instrukce. Stupeň jeho zřetězení je dvojitý a proto umožňuje zpracovávat více instrukcí najednou.
Obsahuje 3 100 000 tranzistorů a tomu odpovídá i jeho ohřev. Procesor se zahřívá na teploty 70° C a jeho příkon je 13 W při normální činnosti a 16 W ve špičce. Je to v současné době nejrychlejší procesor pro PC a pracuje tak rychle, že je problém ho "nasytit". Procesor má realizovanou řadu vylepšení, které zvyšují jeho výkon a to : · superskalární architekturu - takže procesor obsahuje alespoň dvojí zřetězení (pipelining), které umožňuje provést více než 1 instrukci na 1 hodinový cyklus, · úprava FPU (Floating Point Unit - jednotka výpočtů v pohyblivé řádové čárce) přinášející až 5 násobné zrychlení matematických operací v plovoucí řádové čárce,
· detekce chyb tj. interním vyhodnocováním parity, kde každý byte datové je zajištěn paritním bitem, rovněž u adresové sběrnice je zajištění paritním bitem (lichá parita), · větší paměťové stránky (4 k. B a 4 MB), · dvojitá IVP (cache) pro odložený zápis (data, instrukce) dovolující zpracovávat data a provádět operace I/O, · 3 cestný řadič dat optimalizující výměnu dat mezi CPU, pamětí a sběrnicí PC,
· mechanizmus předvídání skoků, který zjišťuje kam mohou směřovat skokové instrukce, · zřetězení adres (address pipelining) umožňuje současný průběh dvou sběrnicových cyklů - lze zahájit dekódování adresy v době, kdy probíhá předcházející cyklus.
Registry Procesor obsahuje původní všeobecné registry.
Dále původní segmentové registry a segmentové selektory.
Oproti procesoru 80486 obsahuje procesor Pentium nové registry, a některé ze starých registrů jsou rozšířené. Registr CR 4 je nový a obsahuje 6 položek : MCE - Povolení kontroly strojových chyb (Machine Check Enable). Bit se nastavuje při chybě parity čtených dat nebo chybě sběrnice pro nastavení hodnot do registru adresy a typu strojové chyby. Generuje přerušení 18. PSE - Rozšíření velikosti stránky (Page Size Extenzion). Při zapnutém stránkování je při úrovni L - velikost stránky 4 k. B H - velikost stránky 4 MB
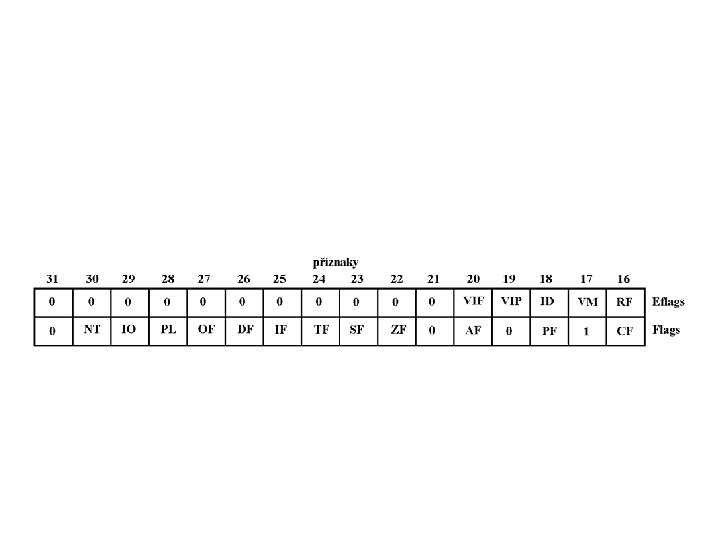
DE - Rozšíření trasování (Debugging Extenzion). Je povolena aktivace přerušovacích bodů nastavených registry DR 0 – DR 3 též pro instrukce I/O. Je-li úroveň L jsou kontrolní body aktivní jen při práci s pamětí. TSD - Blokování časových značek (Time Stamp Disable). Při úrovni H se stane instrukce čtení čítače časových značek privilegovanou a lze provádět jen s úrovní 0. PVI - Povolení virtuálního přerušení v módu chráněném módu (Protected mode Virtual Interrupts Enable). Při úrovni H je povolena podpora virtuálního přerušení VIF registru příznaků v chráněném módu.
VME - Rozšíření módu V 86 (Virtual 8086 Mode Extenzion). Je-li úroveň H, je povolena podpora virtuálního příznaku přerušení VIF registru příznaků v V 86.
Registr příznaků je rozšířen o další 3 příznaky a to : ID - Identifikace (Identifikation flag). Indikuje možnost procesoru provádět identifikace procesoru. VIP - Podpora virtuálního povolení přerušení (Virtual Interrupt Pending Flag). Nastavením tohoto bitu na úroveň H je povolena činnost virtuálního příznaku povolení přerušení VIF - Virtuální povolení přerušení (Virtual Interrupt Flag). Virtuální příznak povolení přerušení, který je aktivován příznakem VIP. Po aktivaci má stejný význam jako příznak IF.
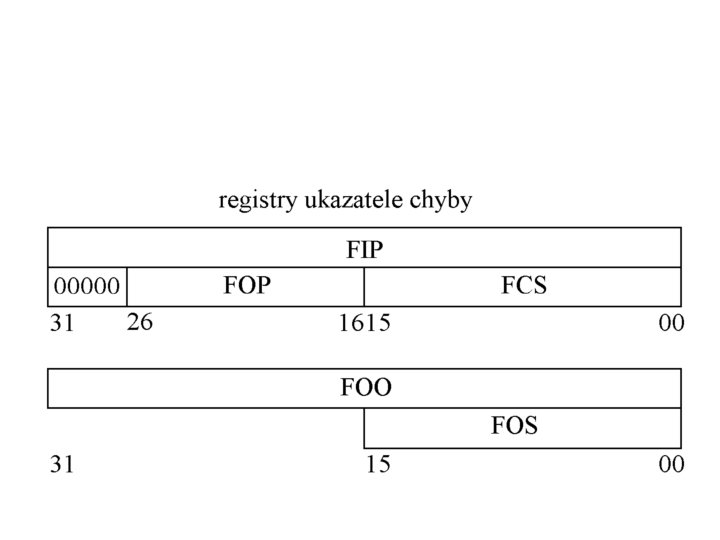
Registry ukazatele chyby (Error pointers) FIP - Ukazatel instrukce (Floating-point Instruction Pointer) je 32 bitový registr. Při zahájení pracování instrukce je naplněn obsahem registru CS. FCS - Registr segmentu programu (Floating-point Code Segment) je 16 bitový a je naplněn obsahem registru CS (selektorem) FOP - Registr operačního kódu instrukce (Floating-point Opcode) je 16 bitový. Nejvyšších odpovídá operačnímu kódu ESC (11011 B) a zbývající bity určují typ této instrukce. FOO - Registr ofsetu operandu (Floating-point Operand Offset) je 32 bitový a obsahuje ofset operandu jen v tom případě, že instrukce pracuje s operandem v paměti.
FOS - Registr segmentu operandu (Floating-point Operand Segment) je 16 bitový a je v něm zapsán obsah segmentového registru (programátorsky přístupné pole selektoru) použitého při určení adresy operandu instrukce v paměti.
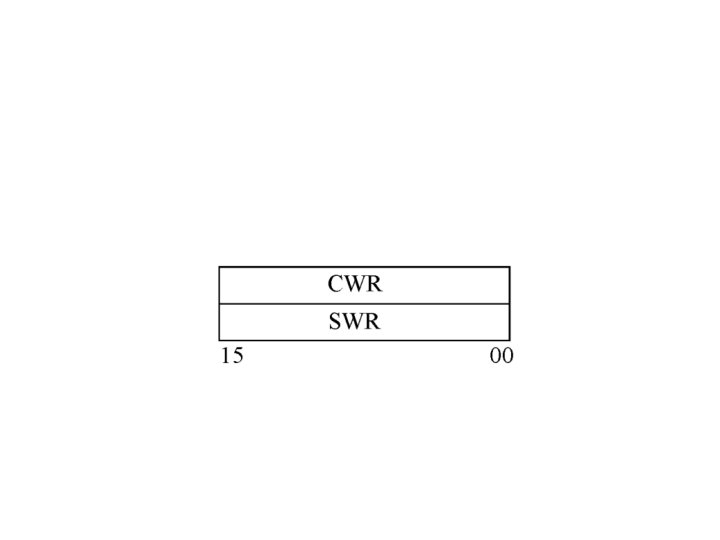
Řídící a stavové registry · CWR - Řídící registr (Command Word Register) je 16 bitový (významných je jen 10 bitů). Při inicializaci je nastaven na hodnotu 40 H. Nastavením jeho jednotlivých bitů jsou nastavovány parametry určující činnost FPU jako : ü zaokrouhlování ü řízení přesnosti výpočtu ü maska přesnosti ü maska přeplnění ü maska dělení 0 ü maska chybné operace ü maska nenormalizovaného operandu
· SWR - Stavový registr FPU (Status Word Registr) je 16 bitový a obsahuje řadu příznaků indikujících stav FPU jako : ü koprocesor pracuje ü vrchol zásobníku ü chyba při nestandardním ukončení ü chyba zásobníku ü chyba přesnosti ü přetečení ü podtečení ü dělení 0 ü nenormalizovaný operand ü chybná operace
Dále jako nové to jsou registry adresy strojové chyby a typu strojové chyby
V nezměněné podobě též ladící registry
A jako poslední v nezměněné podobě registry FPU
Signály, které se nevyskytují u procesoru 80486, nebo mají jiný význam : BUSCHK - Chyba sběrnice (Bus Check). Je-li úroveň L, znamená to, že cyklus sběrnice nebyl úspěšně dokončen. Procesor uchová adresu a informace o řídících signálech v registru strojových chyb. Je-li nastaven bit MCE v CR 4, pak dochází k přerušení typu 18. R/S - Běh/stop (Run/Stop). Úrovní L se po dokončení instrukce zastaví činnost procesoru a procesor je uveden do stavu IDDLE. Úrovní H se opět obnoví normální činnost procesoru.
SMI - Přerušení správy systému (Systém Management Interrupt). Při úrovni L přechází procesor do módu správy systému. Uchová obsah všech registrů a začne provádět obsluhu správy paměti. INIT - Inicializace (Inicialization). Je to stav blízký stavu Reset. Nedochází však k vyprázdnění IVP ani bufferů zápisu. Dochází k přepnutí do reálného stavu. AP - Parita adresy (Address Parity). Signál je nastavován na sudou paritu bitů A 31 až A 5. Chyba parity nemá vliv na činnost procesoru.
APCHK - Chyba parity paměti (Address Parity Check). Na činnost procesoru nemá vliv. BE 0 -BE 7 - Aktivace bytu 0 až 7 (Byte Enable). Určuje, kterých 8 bytů požaduje procesor, nebo které budou zapsány do paměti nebo periferních zařízení.
Režimy Režim reálný, chráněný i režim virtuální 86 se oproti procesoru 80486 změnily jen málo. Ačkoliv je vnější sběrnice 64 bitová, pak vnitřně má procesor opět 32 bitovou architekturu s univerzálními registry, adresováním a celočíselnými operacemi v rozsahu 32 bitů. Jako nový mód je zde mód správy systému, který umožňuje přejít systému do energeticky úsporného režimu v době, kdy není tento systém využíván.
Stránkování Mechanizmus segmentace vychází opět z procesoru 80486. V reálném režimu používá 16 bitové segmentové registry a v chráněném režimu pak tytéž registry jako 16 bitové selektorové registry. Nově je umožněn přístup k datům, které mají větší rozsah než má operační paměť. Pak je část dat uložena v operační paměti a část ve vnější paměti (nejčastěji na HD). Mechanismus stránkování dovoluje používat stránky velikosti : · 4 k. B (jako u 80486) · 4 MB
Jednotka styku se sběrnicí BU (Bus Unit) má na starosti vnější rozhraní čipu, kontroluje tok dat mezi externími zařízeními a Pentiem po 64 bitové datové sběrnici a 32 bitové adresové sběrnici. Vnitřně je tato jednotka připojena na obě IVP ale řídí a kontroluje parity adres, dat i přenosy v dávkovém režimu (burst). Má schopnost číst a zapisovat do externích pamětí v dávkovém režimu, při čemž maximální tok dat dosahuje 528 MB/s při 66 MHz. Velikost přenášených datových bloků odpovídá velikosti vnitřní paměti IVP t. j. 256 bitů (32 B). Načítání jednotlivých bloků paměti označované plnění (fills) a zpětné zápisy modifikovaných bloků se provádějí jako přenosy v dávkovém režimu.
Jednotka načtení instrukcí Jednotka, která řídí načtení instrukcí (prefetch) čte kódy instrukcí z IVP pro instrukce a ukládá je do svých vyrovnávacích pamětí (Prefetch Buffer). Odtud pak posílá instrukce do jednotky pro dekódování instrukcí. Tento postup zajišťuje trvalé zaplnění obou instrukčních řetězců a tím zajišťuje plynulý chod čtením z instrukční IVP po datové sběrnici se šířkou 256 bit (32 B). V rámci vlastního načítání instrukcí se čtou vždy dva 32 B bloky IVP bezprostředně za sebou. Pokud se instrukce nenachází v IVP, nastane výpadek bloku a blok musí být přenesen z operační paměti.
Aritmetickologická jednotka Pro urychlení se používá separátní dekódování instrukcí pro každý instrukční řetězec. Pro dekódování jsou brány instrukce z fronty načtených instrukcí. Provádí se dekódování a převod do formátu se kterým pracuje jednotka zajišťující výkonnou fázi. Takto zpracovaná instrukce obsahuje operátory pro ALU, počáteční adresy mikroprogramů pro výkonovou fázi, odkazy na operandy a datové typy. Dekodéry instrukcí pracují dvoufázově (fáze D 1, D 2) takže :
· během prvé fáze D 1 přebírá dekodér instrukcí od jednotky pro načítání instrukci a rozhoduje se zda se může tato právě dekódovaná instrukce provádět současně s jinou instrukcí. Současně se provádí kontrola na použití registrů. Následuje generování řídícího slova určeného k řízení obou řetězců. Tím je určen průchod instrukcí instrukčním řetězcem. · během druhé fáze D 2 je řídící slovo dekódováno a jsou vypočteny adresy paměťových operandů pro potřebu výkonné jednotky (EU), která řídí i zpětné zápisy (WB) pro celý instrukční řetězec. V cyklu zpětného zápisu se výsledky zapisují zpět do paměti či do registru procesoru a kontroluje se správnost předpovědi podmíněných skoků.
Výkonná jednotka je rozčleněna na řídící sekce, dvě jednotky ALU, pole registrů, obvody pro dělení, násobení a posuvný registr. Výkonná fáze pak uskutečňuje operace v ALU a zajišťuje přístup datům do paměti IVP.
Vnitřní vyrovnávací paměť (IVP) Jednotka IVP je rozdělena na dvě části po 8 k. B a to pro instrukce a data. Každá část má jiné provedení. Díky tomuto rozdělení pak jednotka načítání instrukcí pracuje podstatně výkonněji. Každá z pamětí je realizována bloky asociativních pamětí o velikosti 256 bitů (32 B) a jejich naplňování je prováděno dávkovým způsobem. Datová IVP je realizována jako 2 bránová, to z důvodu umožnění přístupu obou výkonných jednotek. To znamená, že paměť IVP pro data je propojena dvěmi 32 bitovými sběrnicemi s řetězci U a V. Pokud jsou však předávána data jednotce FPU, pak jsou oba řetězce spojeny paralelně a předávají data 64 bitovou datovou cestou. Paměť pro instrukce je připojena k paměti načítání instrukcí sběrnicí o šíři 256 bitů.
U Pentií od Pentium PRO pak obě části IVP pracují s protokolem MESI (Modified/Exclusive/Shared/Invalid), který je určen k zabezpečení konzistence dat, tj. souhlasnosti dat v paměti cache a v operační paměti. Každá položka vyrovnávací paměti je označena jedním písmenem ze zkratky MESI a tím je určen její stav: Modified - data na určité adrese byla přepsána novými daty (modifikována) pouze v paměti cache Exclusive - (výhradní) data v paměti IVP i EVP jsou stejná jako v operační paměti
Shared - sdílená data na příslušné adrese jsou i jinde než v této vyrovnávací paměti a operační paměti (jsou příkladně ještě i v jiné vyrovnávací paměti), přepisování novými daty (modifikování) musí být v módu Write through, tj. současně ve vyrovnávací i operační paměti (předpokládá se, že další paměťové obvody se o aktualizaci svých dat postarají samy) Invalidate - neplatná
Pro vyrovnávací paměť instrukcí přicházejí v úvahu pouze dva stavy, a to S (Shared) a I (Invalidate). Obě části paměti IVP jsou vybaveny TLB pro překlad lineární adresy na adresu fyzickou. Pole příznaků je 3 bránové, aby bylo umožněn i současný přístup při dotazovacím cyklu sběrnice.
Superskalární architektura Zřetězené, nebo též proudové zpracování instrukcí (pipelining) je dokonalejší než u procesoru 80486. Je založeno na dvou řetězcích rozpracovaných instrukcí z čehož vyplývá možnost dokončit více než 1 instrukci za 1 hodinový cyklus i když pro každou část instrukčního cyklu je potřeby větší počet hodinových cyklů (obr. 165). Pro představu je třeba následujících cyklů : · PF - načtení instrukce z paměti (Prefetch) - pracuje jednotka předvýběru a fronta instrukcí · D 1 - dekódování instrukce (Dekode 1 - instruction decode) - pracuje dekodér instrukce
· D 2 - generování adres (Dekode 2 - address generation), kdy pracuje adresovací jednotka · EX - výkonná fáze (Execute) - pracuje ALU · WB - zpětný zápis výsledků operace (Write Back), kdy pracuje adresovací jednotka
Jednotka předvýběru instrukcí načítává instrukce buď z IVP nebo operační paměti a ukládá je do fronty instrukcí. Fronta instrukcí má délku 64 B. Plní se z IVP vždy jen celou řádkou 32 B (256 bitů). Jednotka předvýběru spolupracuje s jednotkou předvídání skoků BPU, takže může připravovat v případě větvení 2 nezávislé položky. Řídící ROM řídí činnost obou výkonných jednotek a obsahuje sadu mikroprogramů potřebných k provedení složitějších instrukcí. Tyto instrukce jsou implementovány mikroprogramově. Většina instrukcí je však prováděna hardwarově.
Další fází zpracování instrukce je dekódování instrukce (D 1) ve které jak již název napovídá probíhá dekódování instrukce. Zde se určuje, zda po sobě jdoucí instrukce se mohou zpracovávat paralelně v řetězci U a V či musí být zpracovány postupně. Je zde však problém při současném zpracování více instrukcí. Je to vzájemná závislost na datech (procedurální závislost). To znamená, že na příklad druhá větev (vstupní data) je závislá na výsledcích větve prvé (výstupní data) a tak dochází k závislosti. Další závislost je v rozdělení na příklad registrů, které chtějí používat obě instrukce ve stejný čas. Proto musí procesor včas identifikovat a určit pořadí tak, aby jedna větev dokončila výkonnou fázi dříve než začne provádět druhou instrukci.
Opět pro příklad procesor vyšle do řetězce U první instrukci a druhou současně s třetí instrukcí pošle do obou řetězců. Řetězce ale nejsou stejné a zaměnitelné. Řetězec U provádí instrukce v celočíselné aritmetice i v pohyblivé řádové čárce. Řetězec V pak jen jednoduché celočíselné instrukce a instrukce pro výměnu obsahů registrů pro pohyblivou řádovou čárku. Pořadí průchodu instrukcí v řetězcích odpovídá pořadí v programu. Pokud vstupují 2 instrukce do obou větví, pak rychlejší fáze 1. instrukce v jedné větvi počká na druhou instrukci a společně vstupují do další fáze v rámci svého řetězce. Takové uspořádání bylo nazváno jako " silně uspořádaný model ".
Následuje fáze generování adres (D 2). V této fázi jsou určovány adresy operandů uložených v paměti, což se provede v průběhu jedné periody hodin ačkoliv se adresa skládá ze dvou částí (báze + offset nebo báze + index atd. ). Ve čtvrté fázi se prostřednictvím dvou ALU provede vlastní instrukce a to buď softwarově, nebo hardwarově. Při této činnosti se provádí též kontrola na podmíněný skok. Protože jsou k dispozici dvě ALU, pak na 1 hodinový impuls mohou být provedeny až 2 instrukce.
Aby to bylo možné, musí být splněny následující požadavky : · nesmí to být instrukce závislé · instrukce s prefixem mohou být zpracovány jen v jednotce U · obě instrukce, které jsou prováděny hardwarově (nikoliv mikroprogramově jako rotace a pod. ) musí být jednoduché, to je instrukce MOV, INC, DEC, PUSH, POP, JMP, CALL, NOP, podmíněné skoky a aritmetické operace.
Poslední fází je pak zápis výsledku. Instrukce modifikují stav procesoru a výsledek je uložen na požadované místo. Navíc jsou instrukce podle skoků kontrolovány na správnost předpovědi cílové adresy. Každý řetězec má k dispozici zápisový buffer o šíři 64 bitů, čímž je dosaženo toho, že při po sobě jdoucích instrukcích se nemusí čekat až se provede zápis do paměti. Při požadavku na zápis mají nejmenší prioritu (viz dále). Protože jsou dvě, pak jejich priorita závisí na tom, který z nich byl zaplněn dříve. Pokud budou naplněny ve stejný okamžik má větší prioritu zápisový buffer řetězce U.
Mimo těchto bufferů má procesor k dispozici ještě 3 buffery zpětného zápisu, kde každý má kapacitu 32 B (jeden řádek IVP). Každý z těchto bufferů je určen pro jinou práci : 1. je určen pro zpětné zápisy vyvolané dotazovacím cyklem sběrnice, který zasáhl modifikovanou položku IVP. Má největší prioritu při požadavcích o zápis. 2. je určen pro zápis modifikovaných položek IVP, které nebyly dosud zkopírovány do paměti. Má druhou největší prioritu při požadavcích o zápis. 3. je určen pro položku, která byla modifikována a proto musí být zapsána do operační paměti. Má nejmenší prioritu.
Každá IVP (instrukcí a dat) obsahuje jeden čtecí buffer. To z toho důvodu, že pokud není potřebných posledních 8 B jsou informace do tohoto bufferu zapsány dříve než do příslušné paměti IVP. Co se týče datové IVP, pak je v případě přepsání modifikované položky ji nutno nejprve zapsat do bufferu zpětného zápisu. Teprve pak je možno provést přepsání dat. Data ze čtecího bufferu jsou však k dispozici ihned po jejich načtení z paměti.
Při požadavku na vnější přerušení je obecný postup následující : · požadavky na přerušení jsou testovány vždy po dokončení instrukce · je-li vstup požadavku aktivní, zruší se okamžitě provádění rozpracovaných instrukcí a provede se přechod na obsluhu tohoto požadavku. · priorita vnějších přerušení je : 0 – BUSCHK 1 - R/S 2 – FLUSH 3 - SMI 4 – INIT 5 - NMI 6 - INTR Vnitřní přerušení mají vyšší prioritu než přerušení vnější. Jsou obsluhována podobně jako vnější přerušení.
Předvídání skoků Zpomalení procesoru nastává při vyvolání skoků na mnoho různých adres. Proto byla vyvinuta technika předvídání skoků, která zvyšuje výkon procesoru až o 25%. To z toho důvodu, že by procesor musel vyprázdnit oba instrukční řetězce, což vzhledem k " proudovému " zpracování instrukcí není jednoduché a poté by je musel naplnit novými instrukcemi.
Skoková instrukce jsou však podmíněné a nepodmíněné. Nepodmíněné instrukce jsou jednoduché, protože jsou pevně dané. U podmíněných skokových instrukcí je možnost měnit tok instrukcí v závislosti na výsledku porovnání. Pokud ke skoku dojde a je úspěšný, je vše v pořádku. Pokud však k podmíněnému skoku nedojde, pokračuje se v provádění instrukcí za skokovou instrukcí. Při tom podmíněné instrukce skoku tvoří až 20% a nepodmíněné až 10% celého programu.
Dobrý systém dokáže vybrat cílovou adresu až s 80% účinností. Tato jednotka předvídání skoků BPU (Branch Prediction Unit) sleduje kódy instrukcí v řetězci, prohlíží je ve fázi načítání z paměti a dojde-li k detekci skoku, pak je to signalizováno jednotce PU (Prefetch Unit), která načítává instrukce z paměti a BPU požaduje na PU instrukci z předpokládané cílové adresy. Pokud se předpověď nevyplní, musí se řetězec vyprázdnit a naplnit již správnou cílovou adresou. Pokud však k podmíněnému skoku nedojde, postup načítání z paměti se nemění.
K předvídání skoků se používá paměť BTB (Branch Target Buffer) maximálně s 256 položkami. Každá položka má 3 části : · adresu skokové instrukce · cílovou adresu skoku · 2 bity vyjadřující historii skoku informující o tom * zda se tato instrukce již vyskytla * zda se předcházející předpověď skokové instrukce povedla či nikoliv
Jednotka operací v pohyblivé řádové čárce (FPU) Jednotka výpočtů v pohyblivé řádové čárce se nazývá FPU. Pracuje na principu zřetězení a používá některé prvky z architektury RISC. V této jednotce se provádí též převod dat do požadovaného formátu a jejich zápis nebo čtení z paměti nebo registrů. Je výkonnější než u procesoru 80486, protože u ní byl podstatně vylepšen mikrokód a je schopna při každé periodě hodin převzít 1 instrukci v plovoucí řádové čárce. Instrukce v plovoucí řádové čárce nemohou být párovány s celočíselnými instrukcemi. Provedení instrukce probíhá v 8 fázích z nichž prvých 5 je společných s celočíselnou výkonnou jednotkou.
Tyto fáze jsou : · PF - Čtení instrukce (Prefetch) – pracuje jednotka předvýběru spolu s frontou instrukcí. · D 1 - Dekódování instrukce (Decode 1 – instruction dekode) – pracuje dekodér instrukce. · D 2 - Generování adres (Decode 2 – address generation) – pracuje adresovací jednotka. · EX - Provedení (Execute) – provádí se převod dat do požadovaného formátu a jejich zápis nebo čtení z paměti nebo registrů. · X 1 - První fáze výpočtu v plovoucí řádové čárce (Floating Point execute stage 1) – provádí převod dat do vnitřního formátu numerické jednotky včetně zápisu.
· X 2 - Druhá fáze výpočtu v plovoucí řádové čárce (Floating Point execute stage 2) – vlastní výpočet. · WF - Zápis výsledku (Write floating point result) – provádí se zaokrouhlení a uložení do registru numerické jednotky. · ER - Chybové hlášení/nastavení stavového slova (Error reporting/update status word).
Při zpracování posloupnosti se ve fázi X 1 určuje bezpečnost instrukce. To znamená, že se zkoumá, zda bude instrukce generovat chybu podtečení, přetečení či ztrátu přesnosti. Pokud tomu tak není, znamená to že není třeba použít mikroprogram na zpracování takovýchto dat a pak fáze EX následující instrukce bude následovat okamžitě po fázi EX této instrukce. Pokud je zapotřebí použít zmiňovaný mikroprogram, pak je zpracování fáze EX další instrukce zpožděno o 4 hodinové pulsy.
Reálný režim je podobný jako u procesoru 80486 a nastává automaticky po inicializaci či RESETu, to znamená rozsah adresace 1 MB pomocí 20 bitové adresy. Z registru EIP se používá jen 16 bitů (IP) a registry CR 0 až CR 3 a GDTR lze používat jen jako pomocné registry pro odkládání operandů. I tento procesor opět pracuje se segmenty paměti o velikosti 64 k. B. Adresa je dána bázovou adresou a offsetem. Současně je možno pracovat se 6 segmenty - CS, SS, DS, ES, FS a GS.
Přerušovací systém Pro každý typ přerušení může být definována jiná obslužná rutina. Umístění a velikost tabulky vektoru přerušení lze měnit změnou obsahu registru IDTR. Tabulku je možno umístit na adrese dělitelné 4. Jedná se o následující přerušení : 0 - chyba dělení 1 - ladící přerušení 2 - NMI 3 - ladící bod 4 - přeplnění 5 - kontrola mezí 6 - chybný op. kód 7 - emulace koprocesoru 8 - překročení tabulky vektorů přerušení 12 - výpadek segmentu zásobníku 13 - překročení hranic segmentu 16 - chyba koprocesoru 18 - strojová chyba 9 - 11, 14, 15, 19 - 31 - rezervováno 32 - 255 - uživatelské vektory Přerušení typu 18 je určeno pro obsluhu systémových chyb.
Práce s periferiemi Pro isolovaný adresový prostor I/O platí následující. Při práci s periferními zařízeními je rozsah adresací 64 k. B. V tom případě je pro adresaci třeba 16 bitů. Běžně se využívá přímých 8 bitových adres, z čehož vyplývá možnost adresace až 256 periferních zařízení. Pro nepřímé adresování se používá 16 bitů, které se ukládají v registru DX.
Chráněný režim Pro procesor Pentium jsou zde dvě novinky : · rozšíření paměti · multitasking (možnost současného běhu více programů) Pro adresaci se mohou opět používat mechanismy segmentace i stránkování, kde stránkování je volitelné. Virtuální adresový prostor může mít velikost až 64 TB. Z toho vyplývá, že lokální adresový prostor i globální adresový prostor mohou mít po 32 TB.
Multitasking bude podrobně probrán v kapitole operační systémy. Zde je jen pohled na ochranu dat a programů z hlediska multitaskingu. Procesoru je umožněno současné zpracování více úloh najednou. Proto je třeba zabezpečení úloh před vzájemným poškozením. To znamená následující : · nedostupnost dat jinými úlohami, což je splněno oddělením adresových prostorů jednotlivých úloh · úloha nemá možnost přístupu mimo paměť, která ji byla přidělena · několikastupňová kontrola oprávněnosti přístupu, kdy je porovnáván offset operandu s délkou segmentu proto, aby žádný byte neležel mimo definovaný rozsah segmentu
Správa virtuální paměti V systému je řada tabulek lokálních deskriptorů. Je jich tolik, kolik je zpracovávaných úloh. Registr LDTR je však pouze jeden. Proto je nutné, aby byly někde uloženy základní informace o všech tabulkách lokálních deskriptorů. Proto jsou tabulky lokálních deskriptorů považovány za speciální globální segmenty a informace o nich jsou v tabulce globálních deskriptorů.
Práce s periferiemi Protože při multitáskové činnosti nemohou úkoly některá periferní zařízení sdílet, jsou instrukce I/O včetně instrukcí povolení a zakázání požadavku maskovatelného zařízení instrukcemi privilegovanými. To znamená, že součástí registru příznaků je i registr IOPL který říká s jakou úrovní privilegovanosti lze tyto instrukce provádět. Proto musí být úroveň privilegovanosti CPL nejméně stejná, nebo vyšší než úroveň privilegovanosti příznaku IOPL (ta může být pro každou úroveň úkolu jiná). Obdobně jako u předchozích procesorů zde funguje i bitová mapa periferních zařízení coby sekundární ochranný mechanismus.
Přerušovací systém Je obdobný jako u procesoru 80486. Je zde však rozšířena tabulka vyhrazených přerušení. Jedná se o následující přerušení : 0 - chyba dělení 1 - ladící bod 2 - NMI 3 - ladící bod 4 - přeplnění 5 - kontrola mezí 6 - chybný operační kód 7 - emulace koprocesoru 8 - dvojitá chyba (přerušení typu Abort) 10 - chybný TSS 11 - segment nepřítomen 12 - výpadek segmentu zásobníku 13 - porušení ochrany paměti 14 - chyba stránkování 16 - chyba numerické jednotky 17 - kontrola zarovnání 18 - strojová chyba 9, 19 - 31 – rezervováno 32 - 255 - uživatelské vektory přerušení
Režim V 86 Proces má pro svou činnost přidělen 1 MB fyzické adresy. Pokud je použito stránkování, může být tento lineární adresový prostor kdekoliv v celém rozsahu fyzické paměti a může běžet i více úloh současně. Ochrana paměti je vyřazena z činnosti. Je zde využit příznak IOPL, protože při použití některých instrukcí by mohlo dojít k nechtěným situacím. Proto je hodnota IOPL kontrolována při provádění instrukcí CLI, STI, PUSHF, POPF, INT a IRET. Protože některé z programů pracují v reálném režimu s těmito instrukcemi, byl tento režim doplněn o virtuální příznak přerušení VIF. Virtuální příznak IF je realizován jako bit VIF v registru příznaků. Jeho použití je povolováno bitem VME v řídícím registru CR 4.
Instrukce s tímto virtuálním příznakem přerušení mohou pracovat jako s příznakem IF. Mechanismus přerušení je ale takový, že se při aktivaci přepne z režimu V 86 do režimu chráněného. Zpět do režimu V 86 se přepne instrukcí IRET, která ukončí obslužnou rutinu přerušení. Operace I/O nejsou ovlivňovány hodnotou příznaku IUOPL, řídí se jen bitovou mapou. Je-li pro příslušný bit nastavena úroveň H, je operace zablokována a je vyvoláno přerušení.
Mód správy systému SMM (Systém Management Mode) patří mezi základní módy tohoto procesoru. Umožňuje přejít systému do energeticky úsporného režimu v době, kdy není tento systém využíván. Do tohoto módu lze přejít kdykoliv a to aktivací externího signálu SMI. Návrat do původního stavu se provede instrukcí RSM. Při spuštění SMM je uchován obsah registrů procesoru a po ukončení je opět jejich obsah obnoven. Tento mód pracuje oddělen od základní paměti a proto jsou zablokována přerušení vynulováním příznaků TF a IF a ladícího registru DR 7. Výjimkou je zde signál Flush. Požadavky na NMI a INIT jsou uschovány a obslouženy po návratu do pracovního stavu.
Procesor dále vynuluje bity PE a PG v registru CR 0 a zahájí svou činnost od adresy 38000 H. Všechny segmenty mají nastavenu délku 4 GB. Poté začne pracovat v jiném adresovém prostoru. Pro tento mód je nutné nové nastavení vektorů přerušení a též vyprázdnění IVP před přechodem do SMM a to pomocí signálu Flush současně s SMI. Instrukce RSM obnoví obsah registrů a vrátí řízení přerušenému programu.
Testování paritou Pro omezení vnitřních chyb se provádí testování prostřednictvím vyhodnocování parity a to u těchto jednotek : · IVP pro data i instrukce · příznaky IVP · tabulky TLB (Translation Lookaside Buffers) · paměť ROM s mikroprogramy · paměť cílových adres skoků
Mimo to : · vnější datové vodiče · vnější adresové vodiče Tím je vytvořena soustava, která je relativně odolná chybám.
Procesory Pentium 3. generace
Technologie MMX Procesory 5. generace se vyznačují technologií MMX, která zde byla prvně zavedena. Označení MMX je vysvětlováno různými způsoby, nejčastěji jako Multi. Media e. Xtenzion. Tato technologie usnadňuje práci s obrazem, operace I/O a kompresi a dekompresi videa. Navíc jsou zde aplikovány dvě vylepšení architektury : · mají větší IVP (cache L 1), · procesor umožňuje práci v SIMD (Single Instruction Multiple Data – Jeden tok instrukcí a vícenásobný tok dat). Z toho vyplývá že je umožněna realizace jedné instrukce na několika množinách dat. Nevýhodou je, že může pracovat jen v pevné řádové čárce.
Procesory Pentium MMX mají klasickou výše popsanou výstavbu s přidáním nové větve s jednotkou MMX a zvětšenou IVP na kapacitu 16 k. B. Procesor obsahuje 57 nových instrukcí. Běžné napájení je 2, 8 V a pro přenosné počítače pak 1, 8 V.
Procesory 6. generace Nová řešení a nové části oproti prvému Pentiu jsou : · architektura DIB, · dynamické vykonávání instrukcí, · vylepšená superskalární architektura, · podpora víceprocesorového systému, · rozšířená detekce chyb s vylepšenými možnostmi oprav, · optimalizace pro 32 bitový software, · jednotky vhodné proudové zpracování dat, čímž se procesor typu CISC začíná podobat procesoru RISC, · u některých procesorů též technologie SSE, · 36 bitová adresová sběrnice umožňující adresovat až 64 GB.
Architektura DIB (Dual Independent Bus – dvojitá nezávislá sběrnice) byla vytvořena za účelem zvýšení propustnosti sběrnice procesoru. Ta se zvýšila použitím dvou sběrnic a to : · jedna sběrnice jen pro přístup k EVP (cache L 2), díky níž může paměť pracovat s vysokou frekvencí a podávat vysoký výkon · druhá sběrnice pro komunikaci procesoru s operační pamětí. Takovéto řešení bylo možné jen v případě, že EVP byla umístěna do pouzdra procesoru. Výsledkem je 3 x větší propustnost, než u procesoru s jedinou sběrnicí.
Dynamické vykonávání instrukcí Hlavní části dynamického vykonávání instrukcí jsou : · vícenásobné předvídání větvení umožňující předvídat chod programu několika větvemi (vylepšené předvídání skoků) · analýza toku dat, kdy instrukce jsou vykonány nezávisle na pořadí původního instrukčního souboru · spekulativní vykonávání instrukcí, které zrychluje činnost tím, že se procesor snaží vyhledávat a vykonávat instrukce, které by mohly být v nejbližších okamžicích zapotřebí.
Předvídání vícenásobného větvení bylo dříve používáno jen u velmi výkonných sálových počítačů a prvně pokusně použito u prvých typů Pentia. Tímto způsobem bylo možno procesor průběžně a neustále zásobovat nepřetržitým tokem instrukcí. Předvídání větvení realizuje jednotka, která v instrukčním toku dat vyhledává ty instrukce, kde může dojít k větvení programu. Větvení je způsobené množstvím úrovní volání programů, podprogramů a jejich návratů.
Vylepšená superskalární architektura Za pomoci analýzy dat specializovaná jednotka procesoru vyhledává určité instrukce ve fázi načítání instrukce z paměti (Prefetch) programu a pokud je nalezne, pak umožní jejich vykonání tak, aby bylo optimální vzhledem k ostatním superskalárním jednotkám vykonávajícím instrukce. Z toho vyplývá, že takováto instrukce bude vykonána ve chvíli, kdy procesor čeká na výsledky načítání dat pro jiné instrukce, nebo když nejsou ve vyrovnávací paměti dostupné okamžitě další instrukce.
Spekulativní vykonávání instrukcí znamená, že procesor vykoná vybranou instrukci dříve, než na ní přijde řada. Jednotka spekulativního vykonávání instrukcí, jak bylo již výše řečeno analyzuje instrukce ve frontě instrukcí a uloží výsledky analýzy do dočasných registrů. Další jednotka tyto instrukce vybírá pokud jsou již vykonány, nebo nepotřebují pro své provedení další instrukce. Poté je provede a výsledky předá do paměti v tom pořadí v jakém byly tyto instrukce původně zadány v programu. Poté jsou vybrané instrukce odstraněny z fronty instrukcí.
Technologie SSE (Streaming SIMD e. Xtension) je vlastně modernizací technologie MMX. Obsahuje 70 nových instrukcí pro práci se zvukem a grafikou. Umožňuje již i práci v plovoucí řádové čárce avšak jen v jednoduché přesnosti. Je zabudována ve speciální jednotce procesoru. Má následující výhody : · snížení zátěže procesoru, vyšší přesnost a kratší čas při rozpoznávání řeči, · vyšší rozlišení a vyšší kvalitu při práci s grafikou, · vyšší kvalitu při přehrávání videa (MPEG 2) a zvuku
· umožňuje provedení až 4 operací v plovoucí řádové čárce během jednoho cyklu (tj. zpracovat několik sad dat při stejné operaci). Například „packed byte“ je 8 nezávislých bytů v 64 bitech. Instrukce sčítání pak provede 8 součtů naráz, čímž se zrychlí řada operací jako jsou operace s maticemi jakožto základ řady grafických algoritmů, · umožňuje softwarové dekódování MPEG 2 při plné rychlosti, · zlepšené načítání dat do vyrovnávací paměti, kdy se tam data umisťují dříve, než jsou potřeba.
Typy procesorů 6. generace Typ Velikost EVP (L 2) Rychlost vzhledem k procesoru Technologie SSE 256 k. B, 512 k. B, 1 MB plná ne Pentium II 512 k. B poloviční ne Pentium. II Xeon Celeron 512 k. B, 1 MB, 2 MB 0 plná ne Celeron A 128 k. B plná (u jádra) Pentium III 512 k. B poloviční ano Pentium. III Xeon 512 k. B, 1 MB, 2 MB plná ano Pentium Pro
Procesor Pentium Pro (pracovně P 6) je 64 bitový procesor na rozhraní mezi CISC a RISC se superskalární architekturou. Je pokračovatelem Procesoru Pentium. Byl uveden na trh firmou Intel v roce 1995. Komunikace s okolím probíhá přes 64 bitové rozhraní. Má realizovanou architekturu tak, aby neblokovala procesor. Proto může pracovat až na 200 MHz. Proto aby byla možná komunikace bez větších časových ztrát na frekvencích větších než 133 MHz, musí mít blízko EVP L 2. Z tohoto důvodu má v pouzdře dva systémy a to vlastní procesor a EVP L 2 s kapacitou ve 3 možných velikostech (250 k. B, 500 k. B a 1 MB) propojené zvláštní sběrnicí (architektura DIB).
Procesor je orientován na zpracování 32 b aplikací. Obsahuje dvojitou IVP v členění 16 k. B to je : · 8 k. B 2 cestné asociativní paměti pro data, · 8 k. B 4 cestné asociativní paměti pro instrukce.
Obsahuje 5 500 000 tranzistorů. Procesor má celou řadu vylepšení, které zvyšují jeho výkon a to : · superskalární architekturu, která zvládne až 3 instrukce na jeden hodinový puls · používá zřetězeného zpracování instrukcí · provádí komunikaci s okolím v různých časových okamžicích vůči svým vnitřním hodinkám · v pouzdře jsou umístěny dva čipy : * vlastní procesor * EVP L 2
· je orientován na zpracování 32 b aplikací, při 16 b aplikacích je pomalý, · provádí spekulativní operace, · připravuje instrukce mimo pořadí, · dynamické vykonávání činnosti.
Dynamické vykonávání činnosti (Dynamic execution) je kombinací 3 technik : · předpovědi skoku · analýzy toku dat - zkoumá v předstihu závislost na výsledcích a datech · spekulativní operace - je to provádění instrukcí mimo pořadí v závislosti na čase tak, aby byl procesor co nejvíce vytížen
Superskalární architektura Zvýšení výkonu u tohoto procesoru se děje jednak zvyšováním hodinové frekvence a jednak využitím paralelního zpracování. Paralelní zpracování je podstatně rozšířeno, takže se v každé části vykonává méně práce a pracuje podstatně menší část hardware. Uvnitř procesoru jsou 3 kanály oproti dvěma u Pentia. Z toho vyplývá možnost současného vykonání až 3 instrukcí.
V každém kanále se činnost rozkládá na 14 fází (stavů), které se dělí do 3 sekcí : · prvá sekce je tvořena 8 stavy a provádí se v ní dekódování · druhá sekce je tvořena 3 stavy při nichž se instrukce vykonává · třetí sekce je tvořena opět 3 stavy při nichž se výsledek ukládá
Spekulativní operace Procesor převádí instrukce na mikrooperace, které se vyhýbají takovému stavu, který by omezoval činnost Pentia Pro. Tyto mikrooperace jsou určeny pro zpracování instrukcí mimo pořadí.
Napájecí napětí je určeno 4 vývody VID 0 – VID 3 (Voltage Identification), které umožňují automatický výběr napájecího napětí. Z toho vyplývá, že na základní desce nemusí být obvody regulátoru. Podle kombinací těchto 4 vývodů (v H a L) je definováno napájecí napětí.
Procesor Pentium II byl uveden na trh v květnu 1997 a byl shodný s Pentiem Pro k němuž byla přidána technologie MMX. Z toho pak vyplynulo zdvojnásobení paměti IVP (cache L 1) a dalších 57 instrukcí. Navíc došlo k některým úpravám procesoru (technologie 0, 25 mikronu).
Vlastní procesor je umístěn na destičce, kde je umístěna i EVP (cache L 2). Pracovní frekvence procesorů byla od 233 MHz do 450 MHz, IVP měla velikost 2 x 16 k. B a EVP byla o velikosti 512 k. B. Součástí EVP je i speciální čip, ve kterém se vytvářejí návěstí odkazující na 512 MB operační paměti (u některých typů až 4 GB v závislosti na rychlosti procesoru). Rychlost EVP byla snížena na na poloviční rychlost procesoru, ale její velikost byla oproti Pentiu Pro dvojnásobná.
Systémová sběrnice je navržena tak, aby byl umožněn : · přenos dvou paritních bitů adresy pro zajištění zvýšení spolehlivosti, · paralelní činnost dvou procesorů na základní desce, · pracovní frekvence 66 nebo 100 MHz. Adresová sběrnice je rozšířena na 36 bitů, při čemž 3 spodní bity jsou vyvedeny jako dekódované signály BE 0 až BE 7.
Mimo paritního zabezpečení datové sběrnice je pro každý byte ještě jeden bit zabezpečení ECC (Error Correcting Code – kód pro opravu chyb). Napájení je opět určeno vývody VID 0 – VID 3 procesoru. Jejich kombinací lze nastavit napájecí napětí od 1, 3 V do 3, 5 V po 50 m. V.
Procesor Pentium II Xeon se od standardního provedení Pentia II liší v následujících bodech : · typem pouzdra · pracovní frekvencí · velikostí EVP (256 k. B – 2 MB) pracující s frekvencí procesoru a s možností odkazu až na 64 GB operační paměti.
Procesor Celeron měl jádro shodné nejprve s procesorem Pentium II a později s procesorem Pentium III. Jeho základní vlastnosti pro frekvence 300 MHz a vyšší jsou : · EVP o velikosti 128 k. B umístěné u jádra procesoru umožňující uchování odkazů až na 4 GB operační paměti, · aplikace kódu pro opravu chyb (ECC), · aplikace dynamického vykonávání instrukcí, · aplikace technologie MMX, · pro frekvence 533 MHz a vyšší používá technologie SSE,
· IVP o velikosti 32 k. B z toho 16 k. B pro data a 16 k. B pro instrukce, · čidlo pro sledování teploty procesoru.
Procesor Pentium III byl uveden na trh v únoru 1999. Má použitu technologii SSE zavádějící 128 bitové registry MMX a k dispozici je 70 nových instrukcí zvyšujících výkon procesoru při práci s obrazem, zvukem a videem. Pracuje na frekvencích 450 – 1000 MHz, systémová sběrnice pak na frekvenci 100 nebo 133 MHz. IVP (L 1) má 16 k. B pro data a 16 k. B pro instrukce. Velikost EVP byla 256 k. B nebo 512 k. B pracující na frekvenci procesoru se schopností udržovat odkazy až na 4 GB operační paměti. Paměť podporuje kód pro opravu chyb (ECC).
Hlavní použité novinky jsou : · aplikace technologie SSE, · ochrana proti přetaktování, · výrobní číslo procesoru (jedinečné číslo pro zabezpečení informačních technologií).
Procesor Pentium III Xeon O tomto procesoru platí, že se od standardního provedení liší : · typem pouzdra, · pracovní frekvencí, · velikostí EVP (256 k. B – 2 MB) pracující s frekvencí procesoru a s možností odkazu až na 64 GB operační paměti.
Procesor Pentium 4 má oproti Pentium III s architekturou P 6 přebudované jádro. Používá architektury Net Burst která využívá jak náběžnou, tak i sestupnou hranu. Jedná se zejména o tyto výrazné změny : • díky technologii hyper pipeline se dosahuje vyšších frekvencí jádra, • rychlá výkonná jednotka („rapid execution engine“) umožňuje práci obou ALU aby pracovaly na frekvenci, která je dvojnásobkem frekvence jádra. Tím je umožněno vykonání řady instrukcí za ½ hodinového cyklu,
• vyrovnávacích pamětí, které zůstávají zachovány je zde další IVP pro instrukce (Execution Trace Cache – dékódované makroinstrukce označované μops ), která uchovává přibližně 12 K mikroinstrukcí, • datová IVP o velikosti 8 k. B s 4 cestným 64 bitovým propojením s jádrem, • 8 cestná EVP (cache L 2) o velikosti 256 k. B se zvýšenou propustností, • prohledávání všech vyrovnávacích pamětí zároveň. Jde o podstatnou změnu, neb až do Pentia III byly vyrovnávací paměti prohledávány postupně.
Pentium 4
Oproti předchozím typům která přenášela data 1 x za hodinový cyklus, Pentium 4 je přenáší 4 x za hodinový cyklus. Spolu s datovou sběrnicí (označovanou 4 X datová sběrnice) může adresová sběrnice dodávat adresy 2 x za hodinový cyklus a proto se nazývá dvojhodinová nebo též 2 X adresová sběrnice. Tato kombinace poskytuje šíři pásma datové sběrnice až 3, 2 GB/s.
Pracuje s technologií SSE 2 (Streaming SIMD Extension 2) rozšiřující technologii MMX (všechny registry jsou 128 bitové) a přidává 144 nových instrukcí, které mají zryhlit výpočty v plovoucí řádové čárce. Procesor je navržen technologií 0, 18 μm a již existuje i technologie 0, 13 μm.
Procesory 7. generace
Procesor Itanium Jedná se o prvý skutečný 64 bitový procesor navržený podle standardu IA-64 (Intel Architecture 64 bits) s názvem Itanium. Používá : · velmi dlouhá instrukční slova (VLIW). Šíře slova je 128 bitů. Slovo obsahuje i přidané bity umožňující adresovat jednak více registrů a jednak identifikovat instrukce, které lze paralelně vykonat. · předvídání instrukcí · eliminaci podmíněných skoků a volání · spekulativní načítání
· architekturu EPIC (Explicitly Parallel Instruction Computing) umožňující vykonání několika instrukcí paralelně. · 3úrovňovou rychlou vyrovnávací paměť : ü L 1 je propojena s výkonnou jednotkou, ü L 2 je umístěna v jádře procesoru, ü L 3 má kapacitu několik MB.
Modul mx 2 se dvěma ITANII (označovaný jako HONDO)
Z výše uvedeného vyplývá, že procesor Itanium podporuje následující činnosti : · podpora připojení dalších procesorů stejného typu (multiprocesorový systém), · podpora práce několika instrukčních větví uvnitř čipu · vytvoření prostředí pro paralelní zpracování instrukcí v několika procesorech
Poznámky k některým vlastnostem procesorů Pentium
Napájecí napětí procesorů řady Pentium Po dlouhou dobu tj. až do vývoje procesorů Pentium pro přenosné počítače a Pentium MMX pro stolní i přenosné počítače byla používána jen jedna napěťová úroveň (Ucc). To znamená, že stejné napájecí napětí bylo použito jak pro vlastní jádro procesoru, tak i pro obvody I/O. Při vývoji Pentia pro přenosné počítače kvůli snížení spotřeby energie bylo použito 2 napájecích napětí. Jádro má nižší napětí (úspora energie) a obvody I/O kvůli kompatibilitě pak napětí vyšší. Příkladně procesor Pentium III má jádro napájecí napětí 1, 6 V a obvody I/O napětí 3, 3 V.
První procesory Pentium přešly na napájení 3, 3 V, které je nazýváno STD (Standard), některé pak vyžadovaly napětí 3, 465 V označované VRE (Voltage Reduced Extended), případně napětí s menší povolenou tolerancí (3, 3 V – 3, 465 V) označované VR (Voltage Reduced).
Chyby procesorů a aktualizace mikrokódu Složité procesory mohou být i při sebepečlivějším návrhu vyrobeny s chybami, které se nepodařilo odhalit při simulaci navrhovaného procesoru. Firma Intel přišla s návrhem, že tyto chyby lze řešit pomocí speciálního software a hardware. Od té doby na svých webových stránkách uvádí příručku oprav ke každému svému procesoru (Specification Update), kde jsou chyby dokumentovány.
U procesorů Pentium Pro a Pentium II pak přišla firma Intel s možností aktualizace mikrokódu. Mikrokód je vlastně sada instrukcí a tabulek obsažených v procesoru, které řídí práci procesoru. Proto nové procesory podporují programovatelný mikrokód pomocí něhož lze chyby odstranit. Aktualizace mikrokódu je uložena v paměti ROM systémového BIOSu. Po zapnutí počítače v průběhu testu (Power-On Self Test – POST) je provedeno nahrátí mikrokódu do procesoru.