Priority encoder Overview Priority encoder theoretic view Other











































")



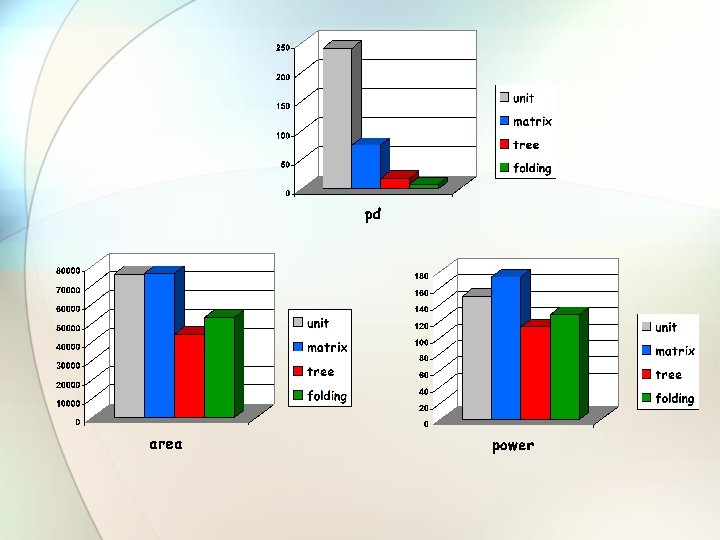
![Compare table unit matrix tree folding Area [mm²] 0. 076 0. 043 0. 053](https://slidetodoc.com/presentation_image/4e7f0a026ec58b2702b479ef4ea22d9f/image-49.jpg "Compare table unit matrix tree folding Area [mm²] 0. 076 0. 043 0. 053")

- Slides: 51
Priority encoder
Overview • Priority encoder- theoretic view • Other implementations • The chosen implementationsimulations • Calculations and comparisons
The target of the project Building priority encoder using the multilevel lookahead and folding techniques
Uses of priority encoding • INR - interconnection network router • design of SAE – sequential address encoder of a content associate memory (CAM) • microcontroller and microprocessor (incrementer / decrementer)
basic concepts of priority encoders • The i-th output bit EPi = Di * Pi Di- the input data Pi- the priority token passed into this bit • the relationship between Pi and Pi-1 Pi = Di-1 * Pi-1 • the generated EPi is EPi = Di * Di-1 * Di-2 … D 1 * D 0
Different implementations For 4 bit priority encoder
matrix Sum of minterms, the straight-forward implementation Because of a minimal distance needed between the lines the layout is large and complicated.
Basic units The structure is build from equal units. Each unit calculates yi and xpi for the i-th bit
Then, by chaining the units we construct the output In this implementation we save silicon area, but pay in propagation delay
tree Tree of multiplexers implemented by butterflies Efficient implementation in area and power, has longer propagation the folding technique
the multilevel lookahead structure The output third-level lookahead signal of the ith 8 -bit macro is: LA 3 i|i=0~n-1 = D 8 i+7 + D 8 i+6 + D 8 i+5 + D 8 i+4 + D 8 i+3 + D 8 i+2 + D 8 i+1 + D 8 i + LA 3 i-1 LA 3 -1 = 0 n = N/8 N – number of input bits The ith 4 -bit sub macros LA 2 i = D 8 i+3+D 8 i+2+D 8 i+1+D 8 i+LA 3 i-1
The 8 -bit macro formulas EP 8 i = EP 8 i+1 EP 8 i+2 EP 8 i+3 EP 8 i+4 EP 8 i+5 EP 8 i+6 EP 8 i+7 D 8 i * LA 3 i-1 = D 8 i+1 * D 8 i * = D 8 i+2 * D 8 i+1 = D 8 i+3 * D 8 i+2 = D 8 i+4 * LA 2 i = D 8 i+5 * D 8 i+4 = D 8 i+6 * D 8 i+5 = D 8 i+7 * D 8 i+6 LA 3 i-1 * D 8 i * LA 3 i-1 * D 8 i+1 * D 8 i * LA 3 i-1 * LA 2 i * D 8 i+4 * LA 2 i * D 8 i+5 * D 8 i+4 * LA 2 i
8 -bit macro cell
Diagram of 32 -bit chain designed encoder
The folding techniquefirst level folding • The LA 3 i that generated by the macro with the higher priority can be connected to other macros with lower priority. • Such connection can make the critical path shorter • In this connection we’ll lose the advantage in layout arrangement and wiring complexity
Folding - implementation • We’ll connect LA 30 to the second and the fourth macros (not to the third) and we’ll get 2 x 2 matrix • in this way the fourth macro is connected to 2 neighboring macros • the number of gate delays is reduced to 4 (<log 232 )
Block diagram of a 32 -bit priority encoder with folding
64 bit priority encoder with first level folding
Multilevel folding • In order to reduce the gate delay to be less then log 2 N in grater priority encoders, we can apply the folding technique again & again for example : N=128 • • • First-Level folding : 8 gate delay Second-Level folding : 7 gate delay Third-Level folding : <7 gate delay
64 -bit priority encoder with 2 levels of folding
For 256 -bit priority encoder the new design can achieve about 10 times performance while spending ½ power consumption.
The implementation We decided to implement the project using bottom up architecture, starting with a 1 bit unit. Each stage will be checked separately. Moving to the next stage is only after the previous stage is finished
1 bit unit At first we implemented 1 bit unit and checked it. The circuit:
The output ahead it he put he ock The simulation:
The 4 – bit unit The 4 bit unit circuit:
The input signals:
The outputs: Lookahead outputs When the lookahead high all the outputs equals zero
The 8 -bit unit
The output signals v 3 v 0 Not valid
The next lookahead v 7 v 4
The 32 -bit chain encoder
The results
The problem we encountered “glitches”
The “glitch” the glitch starts after clock rising
The widest glitch comes at higher bits clock Bit #60
32 bit-folding
64 bit first level folding
64 bit second level folding
64 bit second level folding with one critical path
Propagation delay - reduction To minimize the propagation delay of the EP we made the following changes : - Reduced the clock period from 200 ns to 20 ns. - Divide the clock pulse to different periods for low time and high time. Those changes made under the constrains of : - Keeping the high pulse length 80% of the base pulse. - Making sure all the requested changes and currents are stable before clock raising. - The optimum result we conclude for the clock period: 5 ns for low time and 15 ns high time.
Results – 32 bit
Results – 64 bit
Results – 64 bit (high)
80% high pulse
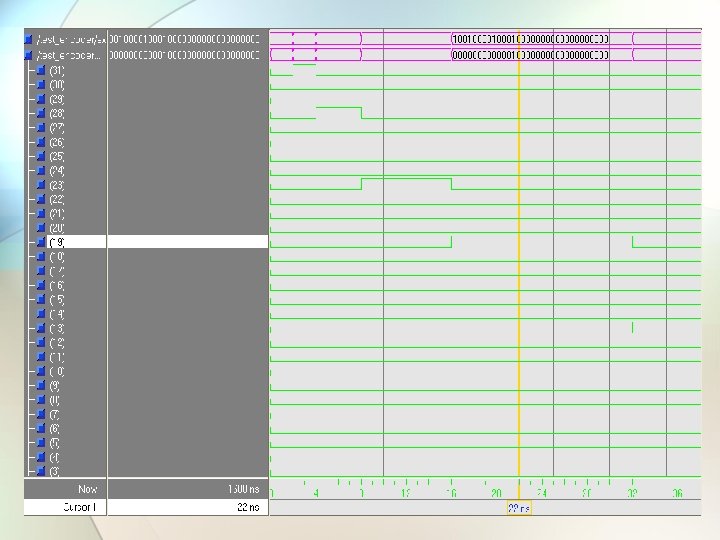
The vhdl simulation
The vhdl simulation of a 32 bit priority encoder Here the lsb of input changes from 0 to 1, and the output changes
Compare table unit matrix tree folding Area [mm²] 0. 076 0. 043 0. 053 Power 149. 6 173. 4 112. 8 127. 5 Time [ns] 241. 2 75 18 8 [10^-11 fw]