Predicting phonotactic difficulty in second language acquisition Katarzyna



 with the following L")




 9")



 ≥ NAD (C 2, V) Ø")


, r")















 - NAD(CC)")










- Slides: 43
Predicting phonotactic difficulty in second language acquisition Katarzyna Dziubalska-Kołaczyk Adam Mickiewicz University, Poznań ifa. amu. edu. pl
Predicting phonotactic difficulty in second language acquisition Katarzyna Dziubalska-Kołaczyk Grzegorz Krynicki Adam Mickiewicz University, Poznań dkasia@ifa. amu. edu. pl krynicki@ifa. amu. edu. pl
Aim of the paper to demonstrate that Øuniversal phonotactic preferences guide the acquisition of consonant clusters in a second language 3
Empirical evidence Ø young learners of English (L 2 English) with the following L 1’s: – independent: Japanese, Korean, Vietnamese – Sino-Tibetan: Chinese – Austronesian: Kosraean, Marshallese, Palauan, Ponapean, Samoan, Tagalog, Trukese, Visayan – Dravidian: Tamil – Polish 4
Outline of the talk 1. 2. 3. 4. 5. 6. Hypothesis Description of the experiment Introduction to B&B phonotactics Phonotactic calculator Analysis of the selected data Preliminary conclusions 5
1. Hypothesis 1. a degree of difficulty in pronouncing L 2 clusters would correlate with the universal characteristics of a given consonantal cluster 2. the more preferred a cluster, the easier and less susceptible to modifications it is expected to be 3. NAD is expected to be a universal criterion, underlying the performance of all subjects, and surpassing other relevant factors, such as the structure of the subjects’ mother tongue, their experience with English or their other capacities and motivations Ø degree of preference is measured by the NAD Principle 6
2. Description of the experiment Ø 53 subjects; 15 subjects analysed here Ø aged 11 -13 Ø native speakers of 15 various languages; 10 here Ø recorded reading 83 times an English carrier sentence I haven’t seen a xxx before! each time containing a different bi-syllabic nonce word Ø each word contained just one double or triple consonant cluster Ø all positions (initial, medial and final) and representative combinations were covered 7
Text for subjects Ø Read the following sentences aloud: – I haven’t seen a kyati before! – I haven’t seen a shwepy before! – I haven’t seen a chluppy before! – I haven’t seen a katewt before! – I haven’t seen a petewm before! –… 8
a sound file demo Ø a Ponapean speaker (Micronesia) 9
3. B&B phonotactics Ø a universal model of phonotactics within Beats & Binding Phonology (Dziubalska. Kołaczyk 2002) – a syllable-less theory of phonology embedded in Natural Phonology Ø intersegmental cohesion determines syllable structure, rather than being determined by it (if one insists on the notion of the ”syllable”) 10
B&B phonotactics Ø the phonotactic preferences specify the universally required distances between segments within clusters which guarantee, if respected, preservation of clusters (cf. intersegmental cohesion) Ø clusters, in order to survive, must be sustained by some force counteracting the overwhelming tendency to reduce towards CV's (CV preference) Ø this force is a perceptual contrast defined as NAD Principle (cf. Dziubalska-Kołaczyk 2002, 2003, Dressler & Dziubalska-Kołaczyk 2007, in press, Dziubalska. Kołaczyk & Krynicki 2007, Bertinetto et al. 2007) 11
B&B phonotactics Ø the universal preferences specify the optimal shape of a particular cluster in a given position by referring to the Net Auditory Distance Principle (NAD Principle) NAD = |MOA| + |POA| + |Lx| Ø whereby MOA, POA and LX are the absolute values of differences in the Manner of Articulation, Place of Articulation and Voicing of the neighbouring sounds respectively 12
B&B phonotactics Example: NAD (C 1, C 2) ≥ NAD (C 2, V) Ø In word-initial double clusters, the net auditory distance (NAD) between the two consonants should be greater than or equal to the net auditory distance between a vowel and a consonant neighbouring on it. 13
Table of consonants 4 3 2 obstruent stop fricative sonorant stop 0 approximant semi. V V sonorant affrica te 1 labial 1 coronal 2 dorsal 3 radical 4 laryngeal (glottal) 5 14
B&B phonotactics Ø consider the preference for initial double clusters Ø NAD (C 1, C 2) ≥ NAD (C 2, V) Ø let us now define two Net Auditory Distances between the sounds (C 1, C 2) and (C 2, V) where Ø C 1 Ø C 2 ØV (MOA 1, POA 1, Lx 1) (MOA 2, POA 2, Lx 2) (MOA 3, Lx 3) Ø in terms of the following metric for (C 1, C 2) cluster & Ø |MOA 1 - MOA 2| + |POA 1 - POA 2| + |Lx 1 - Lx 2| Ø |MOA 2 – MOA 3| + |Lx 2 – Lx 3| Ø for (C 2, V) cluster 15
B&B phonotactics Example: in CCV in E. try t = (4, 2, 0), r = (1, 2, 1), V = (0, 0, 1) NAD (C 1, C 2) = |4 -1| + |2 -2| + |0 -1| = 3+0+1=4 NAD (C 2, V) = |1 -0| + |1 -1| = 1+0=1 thus, the preference NAD (C 1, C 2) ≥ NAD (C 2, V) is observed because 4 > 1 Ø NAD Principle makes finer predictions than the ones based exclusively on sonority: pr. V > tr. V, kr. V > tr. V, tr. V > dr. V, etc. 16
B&B phonotactics Ø the universal NAD Principle leads to predictions about language-specific phonotactics, its acquisition and change Ø specifically, it also allows to predict and explain the order of difficulty in the acquisition of second language phonotactics which appears to be universally valid and as such calls for similar remedies across languages 17
English frequent initial doubles according to NAD Principle 18
Selected Polish clusters according to NAD Principle 19
4. Phonotactic calculator Ø for the purposes of B&B phonotactics, Krynicki developed the phonotactic calculator Ø its purpose is to enable fine-tuning and developing theory by statistical analysis of phonetic dictionaries and phonetically annotated corpora from various languages 20
Phonotactic Calculator - requirements Ø various cluster lengths at all word positions Ø formulating phonotactic hypotheses Ø feedback on predictability of a phonotactic hypothesis Ø choice or customization of Ø available phone sets, features of each phone and scores for each feature Ø available phonetic dictionaries and languages (Pol. Synt, Festvox, Festival) Ø metrics used for calculating distances between phones (taxicab, euclidean) Ø accepted phonetic alphabets (IPA, SAMPA) 21
22
23
24
5. Analysis of the selected data Ø a total of 1245 utterances Ø produced by 15 children Ø each reading 83 sentences containing a nonsense word with a 2 - or 3 -consonant cluster Ø in 767 of these utterances (61, 6%) the speakers modified or avoided the cluster that was assumed to be the correct pronunciation of the nonsense word 25
Error types number of errors in the corpus error description symbol vowel insertion between the elements of a consonant cluster or at the end of a cluster that was expected to be pronunced word-finally 234 @ reducing the number of consonants in the cluster (from 3 to 2 or 1 and from 2 to 1) 218 $ unintelligible pronunciation 154 ? substitution of consonant in a cluster by consonants not present in the expected cluster 152 # substantial mispronunciations 119 % 24 . deletion of the cluster 4 ∅ omission of the word 2 omitted 26 pause insertion between the elements of a consonant cluster or at the end of a cluster that was expected to be pronunced word-finally total 907
Summary statistics for six preferences number of clusters that apply to a given that follow the preference percentage preference number 1 17 17 100% 2 13 13 100% 3 38 27 71% 4 5 3 60% 5 5 3 60% 6 5 2 40% 27
Part 1 of the hypothesis A degree of difficulty in pronouncing L 2 clusters correlates with the universal characteristics of a given consonantal cluster. Ø To a certain degree the amount of correlation between the number of errors students make when producing a cluster and the NAD parameters between the components of that cluster can be illustrated by means of cluster ranking in terms of their NAD differences and their difficulty. Ø Ranking of clusters can be performed first with respect to the NAD criterion and then with respect to linearly scaled percentage of clusters in which speakers made errors. Ø Although statistically not significant, the trend line indicates the expected direction of change and degree of slope between difficulty and NAD measure for finals. 28
correlation for final double clusters
Part 2 of the hypothesis: Linear Regression The more preferred a cluster, the easier and less susceptible to modifications it is. Ø The error of complex mispronunciation annotated in the corpus involved combination of other various errors, epenthesis, substitution, metathesis and other. Ø There is a significant correlation between the NAD differences in a word-medial cluster and the frequency of the complex mispronunciation errors made in it by the speakers (P-value in the ANOVA = 0, 0282; R-squared = 11, 2148%). 31
mispronunciation & medial clusters 32
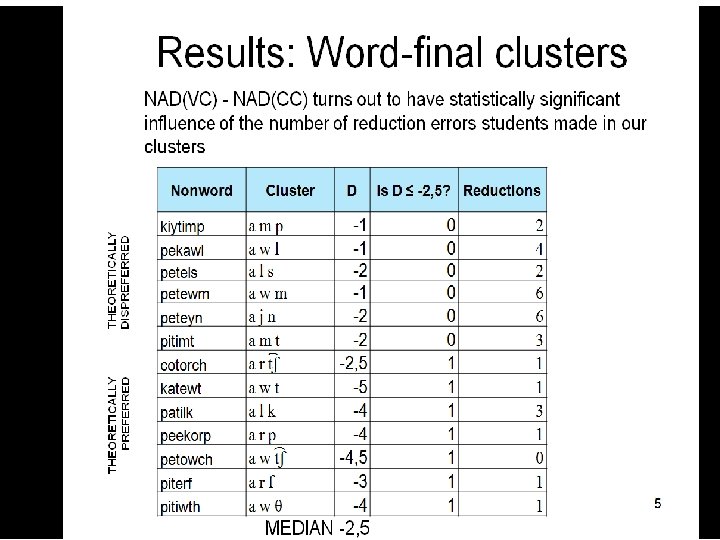
Part 2 of the hypothesis: Analysis of variance and median • NAD(VC) - NAD(CC) turns out to have statistically significant influence on the number of reduction errors students made in word-final clusters
reduction & word-final clusters Preference↘ ANOVA F=11. 86, p=0. 006 Kruskal-Wallis T=7, 46, p=0, 006 Difference↗ 34
Part 3 of the hypothesis NAD is expected to be a universal criterion, underlying the performance of all subjects. Ø If a child produces a consonant cluster different from the expected one, this new cluster will usually follow phonotactic preferences (grand mean of 79. 7% compared to 78. 3% for expected clusters). 35
The number of all expected consonant clusters all initials 83 22 medials 43 78, 3 % finals 18 90, 9 % The number of expected consonant clusters that followed phonotactic preferences 65 20 29 16 Total number of elicited consonant clusters 158 22 43 18 Total number of elicited consonant clusters that followed phonotactic preferences 79, 7 % 126 53, 6 % 12 88, 9 % 67, 4 % 58, 3 % 60, 1 % 26 11 The number of cases when there was a 0 in the expected cluster but more than 0 in the elicited cluster 10 0 The number of cases when both the expected and the elicited cluster were a 1 37 9 20 8 The number of cases when both the expected and the elicited cluster were a 0 7 0 22 10 14 8 The number of clusters for which no speaker produced an qualifiable utterance.
Ø This suggests that phonotactic preferences underlie the performance of the subjects of various linguistic backgrounds and may be universal. Ø More research is necessary to show whether the speakers of different languages displayed significant differences in their following of the preferences.
6. Preliminary conclusions Ø universal phonotactic preferences guide speakers in producing SL clusters Ø the scale of preference in the acquisition of a given type of cluster allows for fine-tuning of SL learning/teaching materials Ø many aspects of the analysis remain to be continued – comparison with the L 1’s of the subjects – data from further subjects – detailed analysis of the errors: which types of improvements are preferred 38
• f j a h l a t ʃ j a t ʃ w a k j a k r a p l a p w a ʃ w a k m a m j a t l a t ʃ l a s r a l j a mwa tna • f j a h l a t ʃ w a p w a ʃ w a t n a k j a k m a t ʃ j a t ʃ l a m w a t l a s r a l j a m j a pla kra
correlation for initial double and triple clusters 41
correlation for initial double clusters
correlation for medial double clusters