Predicting cellular localization and membrane topology Bioe 190

Predicting cellular localization and membrane topology Bioe 190: Intro to Data Science Fall 2016

References for this lecture • “State-of-the-art in membrane protein prediction” Chen & Rost – Applied Bioinformatics, 2002 • “Predicting transmembrane protein topology with a hidden Markov model: application to complete genomes” Krogh et al, Jnl of Mol. Biol. 2001 (The algorithm behind the TMHMM server. ) Anders Krogh Postdoc with David Haussler, and 1 st author on the original HMM papers from UCSC Burkhard Rost Erik Sonnhammer “Theoretical physicist trapped in molecular biology by the bright colours of life” The senior author of In. Paranoid Gunnar von Heijne and a leader of the Quest for “Positive Inside Rule” Orthologs consortium, Pfam. Leader in experimental investigation of membrane proteins Protein 2 D and 3 D structure prediction (among many other bioinformatics methods)

Many different types of membrane proteins http: //withfriendship. com/user/sathvi/membrane-protein. php

http: //www. bch. msu. edu/faculty/garavito/omp_porins. html

Globular, fibrous and membrane structures

Challenge: bioinformatics methods to predict the membrane topology* are quite rough Reported accuracy (by method developers) has been overestimated due to limited/skewed benchmark data *labelling of protein: which parts are in the membrane, which parts are cytoplasmic, which parts are extracellular
")
Case study #1: IFITM 3 (IFITM: Interferon-inducible transmembrane)

Uni. Prot record

Uni. Prot topology annotation for IFM 3_HUMAN

TMHMM predicts a different topology
 http: //www. nature. com/articles/srep 24029")
Experimental investigation of IFITM 3 (IFM 3_HUMAN) http: //www. nature. com/articles/srep 24029

3 topology models evaluated Test your comprehension: Which topology does Swiss. Prot predict? Which topology does TMHMM predict?

Experimental data supports…

Prediction method 1: subcellular localization and topology by homology • Subcellular localization can often be assigned by searching for homologous sequences whose subcellular location is known. • The principle used is that evolution conserves function, and that the membrane localization and orientation/topology are key components of protein function

Prediction method 2: analysis of sequence properties • First attempts to classify proteins with respect to cellular localization based on amino acid sequence properties Nishikawa and Ooi (J. Biochem. 1982) – amino acid composition, disulphide bonds, the secondary structural class related to function and localization – Early results were promising, but based on a small sample. http: //mendel. imp. univie. ac. at/CELL_LOC/

Extracting information from sequence • Signal peptides: short sequences in the protein used to target the protein for specific cellular compartments. • Signal patches (clusters of amino acids in close proximity in 3 D structure, but distant in primary sequence) are also found • Examination of amino acids at structure surface can be particularly helpful; subtle preferences of different amino acids for different environments

Prediction by signal peptide detection • Some proteins have sequence signals that determine their translocation to organelles or outside the cell – Claros et al. Curr. Op. Struct. Biol. (1997). • These patterns are not clear cut, especially for the intracellular organelle targeting peptides; – prediction accuracy is limited – Nielsen et al. Prot. Eng. (1997) v. 10, 1 • Combinations of compositional and signal sequence analyses have been used in expert systems for the prediction of cellular localization – Nakai & Kanehisa Genomics (1992); – In general: not systematic and not rigorously tested http: //mendel. imp. univie. ac. at/CELL_LOC/

TM/Signal Peptide/Localization prediction servers • Phobius: http: //phobius. sbc. su. se -combined topology and signal peptide prediction • TMHMM: http: //www. cbs. dtk. dk/services/TMHMM/ -TM helix prediction • Target. P: http: //www. cbs. dtu. dk/services/Target. P/ -subcellular localization of eukaryotic proteins • Signal. P: http: //www. cbs. dtu. dk/services/Target. P/ -predicts the presence and location of signal peptide cleavage sites

Signal. P and Target. P http: //www. cbs. dtu. dk/services/Signal. P/

Transmembrane helix prediction
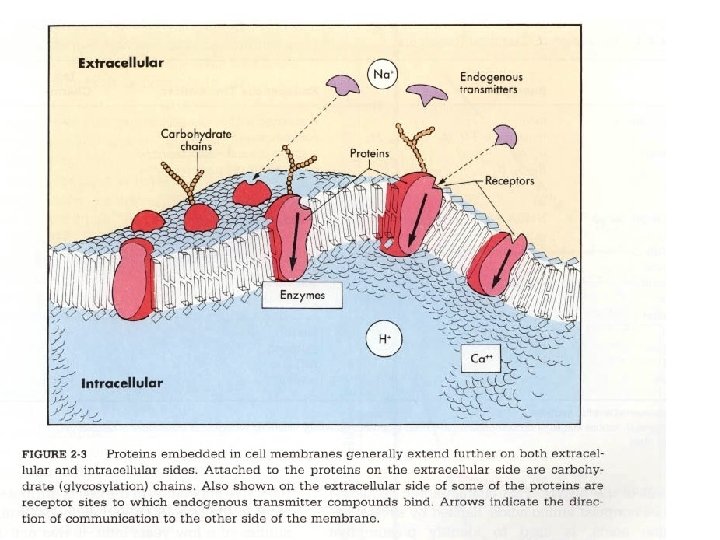

Helical membrane proteins • Key components in cell-cell signalling • Mediate transport of ions and solutes across membrane • Crucial for recognition of self • Major class of drug targets – More than 50% of prescription drugs act on GPCRs (G-protein coupled receptors) – Multi-billion dollar industry

Many predicted; few known • Solved structures available for very few membrane proteins • Predicted 7 -10 K helical membrane proteins in human genome (~25% of genome!) Chen and Rost, 2002

Helical membrane proteins challenge bioinformatics • Very little info about 3 D structures – Very hard to crystallize – Hardly traceable by nuclear magnetic resonance (NMR) spectroscopy • Relatively easy to identify (rough) location of helices through low-resolution experiments – C-terminal fusion with indicator proteins – Antibody binding Chen and Rost, 2002

Concepts for predicting TM helix location and topology • Hydrophobicity scales provide simple criteria for prediction • TM helices are predominantly non-polar • TM helix length between 12 -35 aa • Globular regions between membrane helices typically shorter than 60 aa • “Positive inside rule” von Heijne – Connecting loop regions on inside have more positive charge than loop regions on outside Chen and Rost, 2002
 – Hydropathy scale, moving window")
Hydrophobicity scales • Kyte and Doolittle (20 yrs ago) – Hydropathy scale, moving window approach – Window of 19 residues discriminated best between membrane and globular • Other work equally successful • Drawback: methods fail to discriminate between membrane regions and highly hydrophobic globular segments Chen and Rost, 2002

Other clues • Amino acid preferences for membrane and non-membrane proteins – Training data for methods derived from proteins identified as containing TM helices, as well as other secondary structure types – Higher accuracy Chen and Rost, 2002
 – Topology prediction, using hydrophobicity")
Including topology helps • Top. Pred (von Heijne, 1992) – Topology prediction, using hydrophobicity analysis, possible topologies ranked by positive-inside rule • SOSUI (Hirokawa et al, 1998) – Combined KD hydropathy, amphiphilicity, relative and net charges, protein length Chen and Rost, 2002

Including homology helps • Alignment of homologs known to help secondary structure prediction (Rost and Sander, 1993) • Note: for 20 -30% of proteins in any genome, no identifiable homologs can be found! • PHDhtm first method using homology info for membrane prediction – Uses neural networks, DP, multiple alignment – “one of the most accurate prediction methods” Chen and Rost, 2002
 – Derived amino acid propensities")
Including homology helps • TMAP (Persson and Argos, 1996) – Derived amino acid propensities from known TMs • • 4 -residue caps of membrane helices 21 residue TM segments Found at outside of membrane: N D G F P W Y V Found mostly inside: A R C K – Used these propensities to improve prediction Chen and Rost, 2002

Grammatical rules • TMHMM pioneered building models of predicted membrane proteins in one consistent methodology – Sonnhammer et al 1998, Krogh et al 2001 • Similar concept implemented in HMMTOP – Tusnady and Simon, 1998 • MEMSAT similar to HMMTOP – Jones et al, 1994 Chen and Rost, 2002

Topology questions • The topology of a TM protein indicates its orientation with respect to the membrane: – which regions are outside (extracellular) and which are cytoplasmic • Predicted topologies turn out to be wrong roughly as often as they’re correct… Chen and Rost, 2002
 • “Positive inside")
Sequence information aiding TM recognition • Hydrophobic stretches (for lipid bilayer) • “Positive inside rule” – Von Heijne 1986, 1994 – Abundance of positively charged residues • Improved predictions through use of: – sliding windows – Multiple alignment – Neural networks Chen and Rost, 2002
 • Over-prediction (False positive) • False")
Errors in TM prediction • Under-prediction (False negative) • Over-prediction (False positive) • False merge – two adjacent helices predicted to be one helix • False split – One long helix predicted to be two • Inexact placement of helices Chen and Rost, 2002
 • Performance accuracy overestimated significantly! – “developers have overrated their methods")
Prediction accuracy (1) • Performance accuracy overestimated significantly! – “developers have overrated their methods by 15 -50%” Chen et al, unpublished • Why do developers overestimate their method accuracy? – Validation performed on proteins closely related to training sequences (and thus not indicative of performance on novel sequences) Chen and Rost, 2002
 • “Membrane helices are not entirely conserved across species” – Implies")
Prediction accuracy (2) • “Membrane helices are not entirely conserved across species” – Implies that even related proteins may have different topologies (# TM helices, orientation) and perform different cellular functions • Measures of accuracy of prediction not comparable across methods, due to lack of standard benchmark • Benchmark dataset now available at EBI Chen and Rost, 2002

Chen et al findings • Most TM methods get the number of helices right for most membrane proteins • 86% of TMH residues predicted by best methods • 70 -75% of proteins get all TM helices predicted correctly by top methods • Topology correct for only half of all proteins Chen and Rost, 2002
 • Some papers have claimed that simple hydrophobicity scales are as")
Prediction accuracy (4) • Some papers have claimed that simple hydrophobicity scales are as accurate as more sophisticated methods – Chen et al disagree Chen and Rost, 2002
 • All methods confuse membrane helices with signal peptides – Best")
Prediction accuracy (5) • All methods confuse membrane helices with signal peptides – Best separation provided by ALOM 2 (Nakai and Kanehisa) • Optimized to sort proteins into classes of subcellular localization Since Rost’s paper, the Phobius server was developed to integrate TM and signal peptide prediction http: //www. ebi. ac. uk/Tools/phobius/index. html Chen and Rost, 2002
 • Most methods wrongly predict membrane helices in globular proteins –")
Prediction accuracy (6) • Most methods wrongly predict membrane helices in globular proteins – Most methods overestimate their ability to distinguish between globular and membrane proteins Chen and Rost, 2002

Emerging and future developments • Improved prediction by averaging over many methods (I. e. , consensus approaches) – Promponas and colleagues: Co. Pre. THi combined 7 methods, requiring 3 to agree – Nilsson et al, 2000, used 5 methods – Accuracy correlated with number of methods agreeing Chen and Rost, 2002
 alpha helix")
Chen and Rost, 2002 Emerging and future developments • Amphiphilic (aka amphipathic) alpha helix identification can improve prediction • Helical-membrane and signal peptide predictions must be combined explicitly – Best signal peptide prediction tool is Signal. P (Nielsen et al 1997) – PSORT, HMMTOP and THHMM integrate these predictions – More thorough combination is still missing Except, of course, for Phobius, released since this paper

Emerging and future developments • Databases of TM proteins being produced and curated • Membrane-specific substitution matrices improve database search for TM proteins – Current substitution matrices based on globular proteins – Henikoff and Henikoff have membrane-helix-specific substitution matrix PHAT Chen and Rost, 2002

Sequence conservation in TM domains • Residues on helix-helix interface tend to be more conserved than those facing the lipid bilayer • Conservation in TM helices greater than structurally variable regions but not as significant as enzyme active sites and other functionally critical regions (KS observation)

More data from structural studies of TM proteins • Solved membrane protein structures have also shown that helical propensities are different in the membrane. • Glycine and proline, which are thought to be helix-breakers in soluble proteins, occur in the transmembrane helices of cytochrome c oxidase – [Tsukihara et al, 1995]. • Studying known structures has revealed that aromatic residues are often in the bilayer interface, possibly anchoring the transmembrane helix in the bilayer – [Pawagi et al, 1994].

More data from structural studies • Serine and threonine can satisfy hydrogen bond donors and acceptors by hydrogen bonding to backbone carbonyls, making membrane localization favorable (Engelman et al 1986) • Analysis of solved membrane proteins show TM length ranges from 14 -36 aa (varying due to variations in lipid bilayer width) • Canonical alpha helix prediction methods derived from soluble proteins are not as effective at predicting TM-located helices

Summary points • Protein localization is a critical aspect of protein function • Methods for predicting localization can overestimate their expected accuracy (expect errors) • Recall basic division into 3 classes: globular, fibrous and membrane structures • Datasets used in validation typically differ from one method to the next, so results are not comparable • Consensus prediction using various types of information and predictions are your best bet for improving accuracy

Supplementary slides

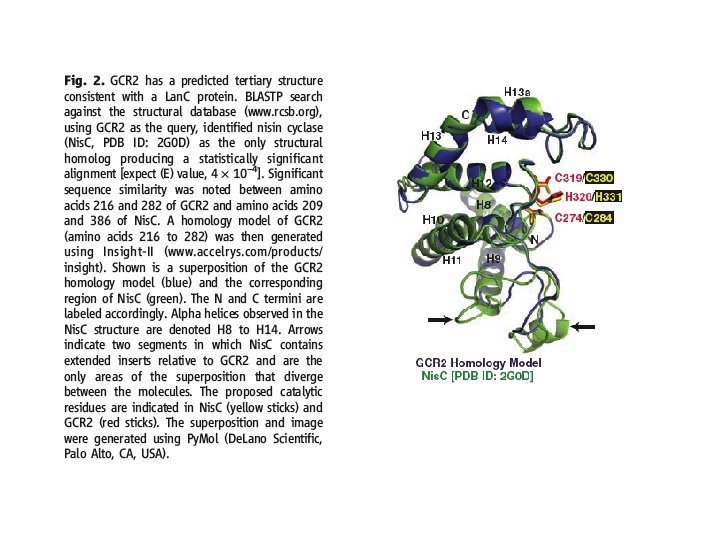
A plant GPCR? ? Arabidopsis Thaliana GCR 2
 has been characterized in plants (17–")
“only one Arabidopsis putative GPCR protein (GCR 1) has been characterized in plants (17– 20), and no ligand has been defined for any plant GPCR”

Bioinformatics search and experimental support

At 1 g 52920. 1 >tr|F 4 IEM 5_ARATH G protein coupled receptor OS=Arabidopsis thaliana GN=GPCR PE=2 SV=1 MGERFFRNEMPEFVPEDLSGEEETVTECKDSLTKLLSLPYKSFSEKLHRYALSIK DKVVW ETWERSGKRVRDYNLYTGVLGTAYLLFKSYQVTRNEDDLKLCLENVEACDVASR DSERVT FICGYAGVCALGAVAAKCLGDDQLYDRYLARFRGIRLPSDLPYELLYGRAGYLW ACLFLN KHIGQESISSERMRSVVEEIFRAGRQLGNKGTCPLMYEWHGKRYWGAAHGLAG IMNVLMH TELEPDEIKDVKGTLSYMIQNRFPSGNYLSSEGSKSDRLVHWCHGAPGVALTLV KAAQVY NTKEFVEAAMEAGEVVWSRGLLKRVGICHGISGNTYVFLSLYRLTRNPKYLYRAK AFASF LLDKSEKLISEGQMHGGDRPFSLFEGIGGMAYMLLDMNDPTQALFPGYEL

“Transmembrane structure prediction suggests that GCR 2 is a membrane protein with seven transmembrane helices” -Despite bold claim of 7 TM GPCR, only two prediction servers used, no confidence values indicated, and figure ended up in Supplemental Material! DAS TMPred

, using the")
“Liu et al predicted GCR 2 as a seven-transmembrane protein (7 TM), using the TMpred and DAS programs, but did not report score thresholds to evaluate the confidence of these predictions. TMpred and DAS are known to erroneously predict transmembrane helices within soluble proteins (55% and 83% false positive rates, respectively)” GCR 2 alignment with Lan. C superfamily (non 7 -TM GPCR)


“We initially predicted that GCR 2 was a seventransmembrane protein using TMpred and DAS software programs (2). We further used 12 distinct software programs to predict the topological structure of GCR 2 and found that 9 of them (TMHMM, SOUSI, and DAS TMfilter excluded) showed that GCR 2 is a transmembrane protein with various numbers of transmembrane domains. TMHMM has underpredicted transmembrane domains in many instances (3), and the only other reported GPCR in Arabidopsis, GCR 1 (4), was predicted to be a three-transmembrane protein by SOSUI. In addition, about 14% of known transmembrane proteins (established by crystal structure or biochemical evidence) cannot be correctly predicted by available software (3). Thus, computational prediction of membrane proteins is not yet a mature science and mainly serves to generate hypotheses for experimental testing”

My personal analysis of “GCR 1” • BLAST vs PDB – are there any globular proteins that match the full GCR 2 structure? • If yes, the 3 -fold division of proteins into globular, fibrous and membrane means that GCR 2 cannot be membrane.
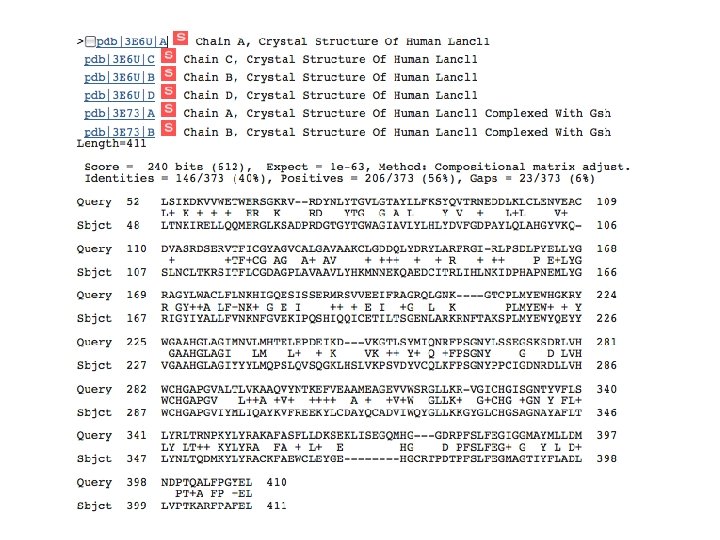
 3 e 6")
BLAST vs PDB 3 T 33 (PDB structure for GCR 2) 3 e 6 u chain A (39% identical)

VAST structural alignment shows high superposability
 protein?")
Is GCR 2 a GPCR or a globular (soluble) protein?

K+ channels example http: //www. ks. uiuc. edu/Research/kvchannel/

Example analysis: KCNA 2_RAT >sp|P 63142|KCNA 2_RAT Potassium voltage-gated channel subfamily A member 2 OS=Rattus norvegicus GN=Kcna 2 PE=1 SV=1 MTVATGDPVDEAAALPGHPQDTYDPEADHECCERVVINISGLRFETQLKTLAQFPETLLG DPKKRMRYFDPLRNEYFFDRNRPSFDAILYYYQSGGRLRRPVNVPLDIFSEEIRFYELGE EAMEMFREDEGYIKEEERPLPENEFQRQVWLLFEYPESSGPARIIAIVSVMVILISIVSF CLETLPIFRDENEDMHGGGVTFHTYSNSTIGYQQSTSFTDPFFIVETLCIIWFSFEFLVR FFACPSKAGFFTNIMNIIDIVAIIPYFITLGTELAEKPEDAQQGQQAMSLAILRVIRLVR VFRIFKLSRHSKGLQILGQTLKASMRELGLLIFFLFIGVILFSSAVYFAEADERDSQFPS IPDAFWWAVVSMTTVGYGDMVPTTIGGKIVGSLCAIAGVLTIALPVPVIVSNFNYFYHRE TEGEEQAQYLQVTSCPKIPSSPDLKKSRSASTISKSDYMEIQEGVNNSNEDFREENLKTA NCTLANTNYVNITKMLTDV


")
BLAST vs PDB (interesting homology relationships, including bacterial proteins)
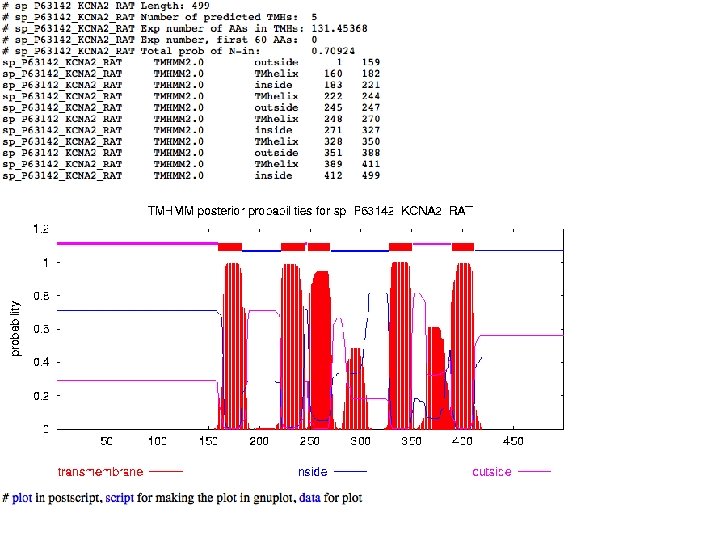

Missed by TMHMM!

TMHMM data in S 4 region

Signal peptide prediction


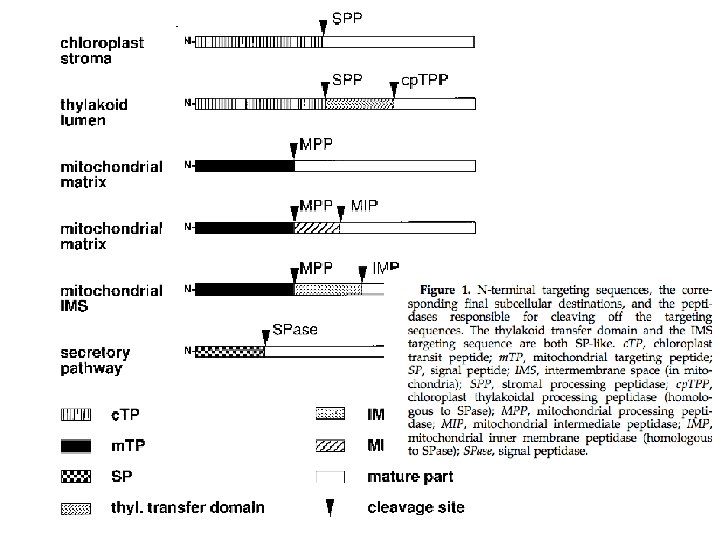

Chloroplast transit peptides are hard to detect
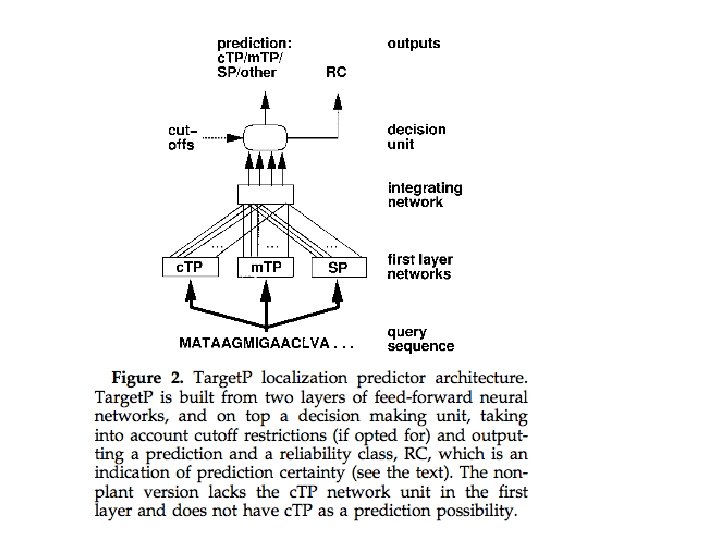
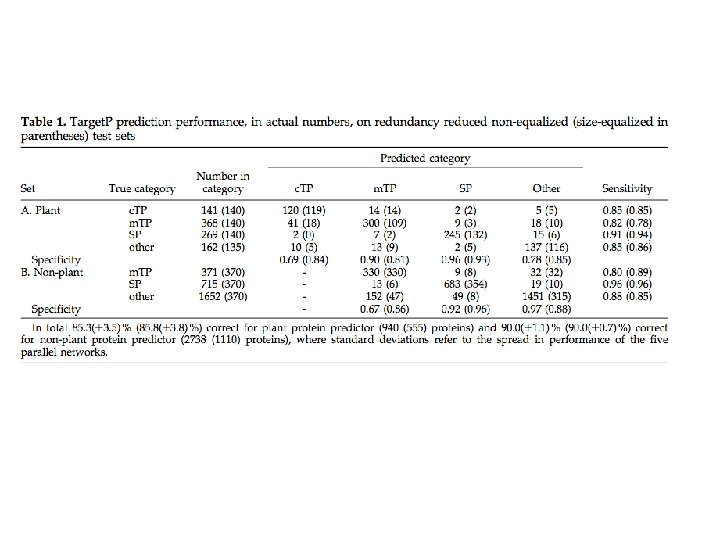

TMHMM provides a grammar to parse sequences into subregions

Training data

Discussion of the TMHMM model and training • Imprecise TM boundaries are handled by a fuzzy labelling procedure for training data, followed by model training and then redefinition • Sub-optimal alignments explored • Predicted TM helix is considered correct if overlap of 5 aa with a “true” helix • False positive issues with signal peptides handled with secondary analysis using Signal. P • No problems discriminating between helical membrane proteins and porins • Training data correlation not discussed in detail (160 “non-homologous”, but further clustering based on >25% sequence identity in cross-validation…)

TMHMM author findings • • • TMHMM correctly predicts 97– 98 % of the transmembrane helices. TMHMM can discriminate between soluble and membrane proteins with both specificity and sensitivity better than 99% – although the accuracy drops when signal peptides are present This high degree of accuracy allowed authors to predict reliably integral membrane proteins in a large collection of genomes. Based on these predictions, authors estimate that 20– 30 % of all genes in most genomes encode membrane proteins – which is in agreement with previous estimates. Proteins with Nin-Cin topologies are strongly preferred in all examined organisms – except Caenorhabditis elegans, where the large number of 7 TM receptors increases the counts for Nout-Cin topologies. Insights into evolution of TM proteins using “helical hairpins” (two TM helices connected by an extra-cytoplasmic loop)
- Slides: 83