Pipelining Instruction pipelining Instruction pipelining is a technique





 stage is responsible for obtaining the requested")
 stage is responsible for decoding the instruction")
 stage is where any calculations are performed. The main")
 stage is responsible for storing")
 stage is responsible for writing the result")






 – true dependency • A")

 – anti-dependency • A Hazard")









- Slides: 33
Pipelining
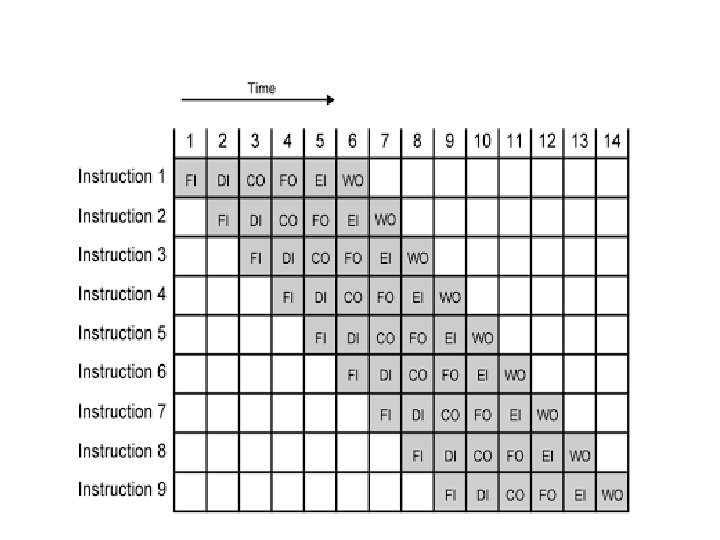
Instruction pipelining • Instruction pipelining is a technique that implements a form of parallelism called instruction-level parallelism within a single processor. • It therefore allows faster CPU throughput (the number of instructions that can be executed in a unit of time). • The basic instruction cycle is broken up into a series called a pipeline. • Rather than processing each instruction sequentially (finishing one instruction before starting the next), each instruction is split up into a sequence of steps so different steps can be executed in parallel and instructions can be processed concurrently
What is Pipelining • A technique used in advanced microprocessors where the microprocessor begins executing a second instruction before the first has been completed. - A Pipeline is a series of stages, where some work is done at each stage. The work is not finished until it has passed through all stages. • With pipelining, the computer architecture allows the next instructions to be fetched while the processor is performing arithmetic operations, holding them in a buffer close to the processor until each instruction operation can performed.
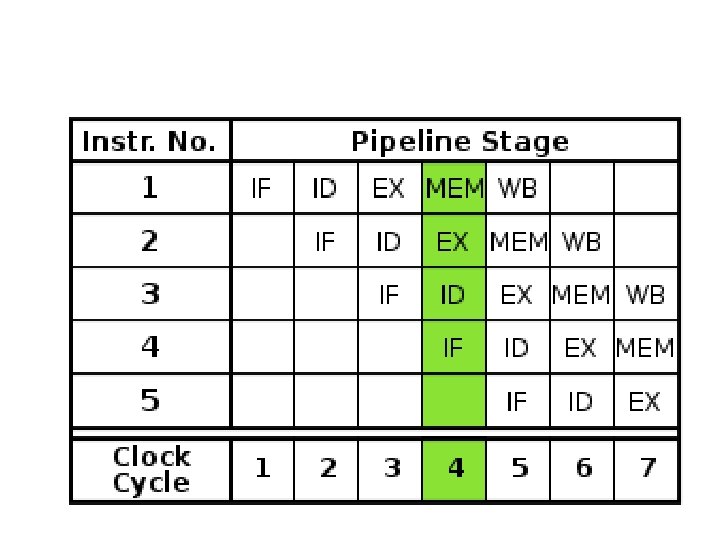
How Pipelines Works • The pipeline is divided into segments and each segment can execute it operation concurrently with the other segments. Once a segment completes an operations, it passes the result to the next segment in the pipeline and fetches the next operations from the preceding segment.
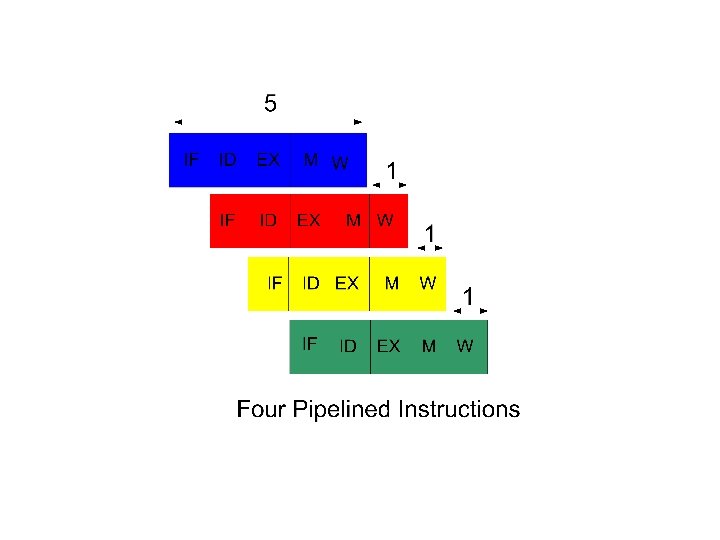
Example
Instructions Fetch • The instruction Fetch (IF) stage is responsible for obtaining the requested instruction from memory. The instruction and the program counter (which is incremented to the next instruction) are stored in the IF/ID pipeline register as temporary storage so that may be used in the next stage at the start of the next clock cycle.
Instruction Decode • The Instruction Decode (ID) stage is responsible for decoding the instruction and sending out the various control lines to the other parts of the processor. • The instruction is sent to the control unit where it is decoded and the registers are fetched from the register file.
Execution • The Execution (EX) stage is where any calculations are performed. The main component in this stage is the ALU. The ALU is made up of arithmetic, logic and capabilities.
Memory and IO • The Memory and IO (MEM) stage is responsible for storing and loading values to and from memory. • It also responsible for input or output from the processor. • If the current instruction is not of Memory or IO type than the result from the ALU is passed through to the write back stage.
Write Back • The Write Back (WB) stage is responsible for writing the result of a calculation, memory access or input into the register file.
Operation Timings • Estimated timings for each of the stages: Instruction Fetch Instruction Decode Execution 2 ns 1 ns 2 ns Memory 2 ns and IO Write Back 1 ns
Advantages/Disadvantages Advantages: • More efficient use of processor • Quicker time of execution of large number of instructions Disadvantages: • Pipelining involves adding hardware to the chip • Inability to continuously run the pipeline at full speed because of pipeline hazards which disrupt the smooth execution of the pipeline.
Pipeline Hazards • Data Hazards – an instruction uses the result of the previous instruction. • A hazard occurs exactly when an instruction tries to read a register in its ID stage that an earlier instruction intends to write in its WB stage. • Control Hazards – control means here program control goes from one point to another. i. e. when we used branch instruction. PC contents will be changed at each time when branching occurs. the location of next instruction depends on previous instruction. • Structural Hazards – two instructions need to access the same resource. Ex. Memory , I/O ports etc • Like if two instructions are accessing same memory location.
Structural Hazards Structural hazards occur when instruction in the pipeline need the same resource: • Memory • CPU • Etc.
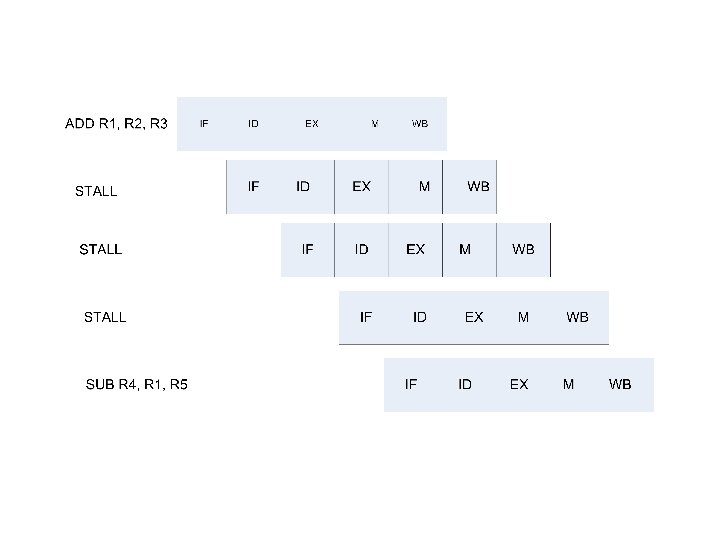
Example: Resource Hazard Fetch of I 3 has to stall for memory access of I 1 operand.
Data Hazards occur when there is a conflict in the access of: • a memory location or • a register
Types of Data Hazards • Read after Write (RAW) – true dependency • A Hazard occurs if the Read occurs before the Write is complete • Write after Read (WAR) – anti-dependency • A Hazard occurs if the Write occurs before the Read happens • Write after Write (WAW) – output dependency • A Hazard occurs if the two Writes occur in the reverse order than intended
Example: RAW Data Hazard The second instruction needs to stall for EAC to be written by the first instruction before fetching it. Is there a way of stalling one cycle instead of two?
The Other Data Hazards • Write after Read (WAR) – anti-dependency • A Hazard occurs if the Write occurs before the Read happens • Example? • Write after Write (WAW) – output dependency • A Hazard occurs if the two Writes occur in the reverse order than intended • Example?
Data Hazards
Stalling • Stalling involves halting the flow of instructions until the required result is ready to be used. • However stalling wastes processor time by doing nothing while waiting for the result.
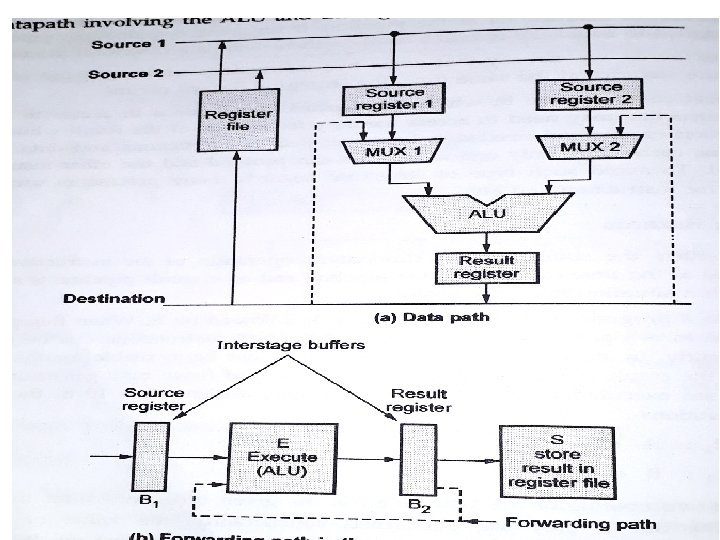
Solution to data hazard: operand forwarding • Simple hardware technique which can handle data hazard is called operand forwarding or register by passing. • In this tech ALU results are fed back as ALU inputs • When forwarding logic detects the previous ALU has the operand for current instruction , it forwards ALU output instead of register file.
Pipeline Flowchart for Branches
• Dealing with Branches
Multiple Streams • Have two pipelines • Prefetch each branch into a separate pipeline • Use appropriate pipeline Challenges: • Leads to bus & register contention • Multiple branches lead to further pipelines being needed
Prefetch Branch Target • Target of branch is prefetched in addition to instructions following branch • Keep target until branch is executed
Using a Loop Buffer Have a small fast memory to hold the past n instructions – perhaps already decoded This likely contains loops that are executed repeatedly
Branch Prediction • Predict branch never taken • Predict branch always taken • Predict by opcode • Use Predict branch taken/not taken switch • Maintain branch history table • Get help from Compiler